









版权声明:本文为博主原创文章,未经博主允许不得转载。
未见过类别
未见过类别或者叫不知道类别。简单来说,如我们定义类别{苹果,香蕉} 且其数据集为D,那么定义一个二分类器C,将D分割为训练集和测试集,那么训练出的分类器只能区分两个类别。假设我们拥有数据Dx,其中拥有的分类为{小狗,小猫},这个时候将Dx混入D的测试集,二分类器C如何分类Dx中的数据?这时我们将Dx包含的数据类别叫未见过类别。也就是分类器从未见过的类别,即该类别未在训练集中定义,区别于未见过的数据。
更形式化的定义为:对于学习算法,其只在训练集中训练,且训练集包含的定义类别数为K,测试集定义类别数为N,且测试集中至少有一个类别是训练集中未定义的类别,我们把训练集与测试集定义类别的差集定义为未见过类别。
一个简单的例子是:我们训练一个mnist分类器,有10个类别分别是{0,1,2,... ,9},如果我们给这个mnist分类器猫的图片,它会分类为什么?这个猫的图片对于mnist分类器就是未见过类别。
PAC辨识
PAC辨识(PAC Identify):对,所有
和分布D,若存在学习算法
,其输出假设
满足:
,
则称学习算法能从假设空间H中PAC辨识概念类C[1]。
PAC可学习
PAC可学习性(PAC Learnable):令m表示从分布D中独立同分布采样得到的样例数目,,对所有分布D,若存在学习算法
和多项式函数
,使得对于任何
,
能从假设空间H中PAC辨识概念类C,则称概念类C对假设空间H而言是PAC可学习的,有时也简称概念类C是PAC可学习的[1]。
测试域分类完全性
即:存在学习算法,使任意的概念C在训练域(空间)中是PAC可学习的,且测试域的任意概念X也属于训练域,那么对于测试域,算法
在其域内是分类完全的。
对分类器算法而言,测试域分类完全性指分类器的分类数大于或等于测试域中类别数量和测试域中类别包含于分类器类别,且分类器的所有类别概念需要满足训练域中PAC可学习。以下如不特别说明分类器的所有类别概念都满足训练域的PAC可学习。
如:分类器类别{苹果,香蕉,西瓜},测试域中类别{苹果,香蕉,西瓜},分类完全
分类器类别{苹果,香蕉,西瓜},测试域中类别{苹果,西瓜},分类完全
分类器类别{苹果,香蕉,西瓜},测试域中类别{苹果,西瓜,李子},分类不完全
分类器类别{苹果,香蕉},测试域中类别{苹果,西瓜,李子},分类不完全
......
真实应用中分类完全的例子:
垃圾邮件分类中,而训练域和测试域类别一般都为:垃圾邮件和非垃圾邮件,即二个分类。而我们常用的分类器NaiveBayes,SVM等等,都可以作为二分类器,也就是说这些二分类器在垃圾邮件分类中是分类完全的。
真实应用中分类不完全的例子:
实际上,在真实世界中类别是非常大的,如在图像分类中,分类可以成千上万,从大分类(水果,蔬菜等)到具体分类(苹果,香蕉),因为从属关系,具体分类搞定了,大分类就搞定了,所以我们一般直接考虑具体分类问题,如在ImageNet图像识别竞赛中分类数大约为1000,如果我们将测试域设置为仅仅在ImageNet竞赛数据这个域中,训练分类器的类别为1000(类别一一对应)那么分类是完全的,如果将测试域设定为真实世界,那么实际上1000个分类相对于真实世界非常小,也就是分类不完全的。
在这里我们可以得出一个结论:如果分类器在测试域中不是分类完全的,那么分类器在测试域中未定义的类别,如果被强制分类那么一定会被错分。
我们知道人对于任意概念如果知道其类别那么将其分类,如果不知道其类别那么分类为"未见过类别"。所以我们引申出一个问题,对于算法,任意的概念C在训练域中是PAC可学习的,且测试域的某些概念X不属于训练域,也就是训练域中没有关于概念X的数据,在训练域中训练出的算法
如何将概念X分类为"未见过类别"?
分类,数据域描述,异常探测
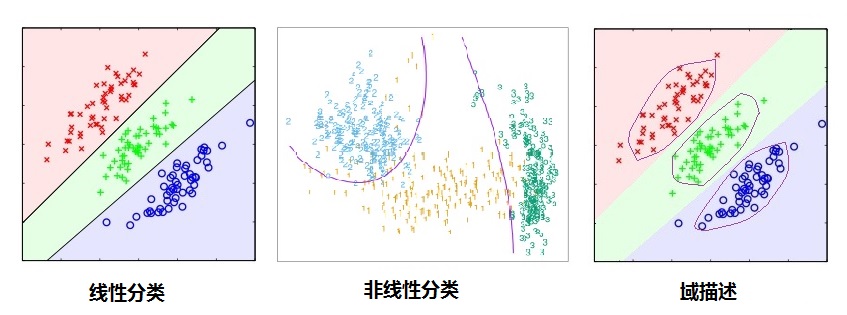
如上图所示,我们可以明显看到分类(判别)算法比数据域描述(data domain description)有更松弛的界(boundary),即分类只需要划类间的界限,只要分类算法达到小的分类误差就可以了,而没有具体的描述类别的边界,所以在未见过类别需要区别的时候,分类算法只能决策到已知类别(在低概率拒绝分类的决策分类算法仍然有较大的问题),所以很容易被愚弄[8],而域描述恰恰因为描述了类别的边界,所以能在界之内的数据点分类为已知类别标记,界之外的数据被分类为未见过类别。(不正式的说,在标记类别趋向于无穷大的时候分类算法的界收敛到域描述的界)。
还有像一个类别的分类问题(one class classification),即我们只有一个类别的数据,分类算法的最小区分单位为2,所以不适用,而域描述为区分单位为1,能解决一个类别的分类问题。本质上域描述和异常探测相似的,关于多类别的域描述分类算法参考[5-6]。由上域描述能够有效的降低模型结构风险,及更不容易受到对抗样本的干扰(因为他有更紧的界)。而且在数据不平衡问题上分类算法的缺陷比域描述更严重。
域描述算法与异常探测(anormaly detection/outlier detection)
svdd(Support vector domain description,支持向量域描述)算法[3-4],这里就不写具体公式了,有兴趣的查看参考文献。svdd本身可以用于异常探测,异常探测算法如elliptic envelope,Isolation Forest也算是域描述[7]。
判别模型与生成模型
判别模型(discriminative model),判别模型是直接学习p(y|x),即输入输出映射,我们通常的分类算法就是判别模型,如SVM,LR,NN...;
生成模型(generative model)是对p(x,y)进行学习,即学习p(y|x)和p(x),最后p(x,y)=p(y|x)p(x),可以认为p(y|x)为判别模型给出的后验概率,而p(x)为先验概率(也可以叫上下文或者熟悉度,比如是否是熟悉的输入,不熟悉[即不属于训练数据分布的数据] 有较小的p(x)值),而p(x,y)可以理解为给定 x 时 y 的综合置信度,所以生成模型更不容易像判别模型那样将未见过类别分类为错误类别[8]。
总结
未见过类别应该是真实应用中很常见的问题,比如对于人脸分类器,假如我们给它非人脸的图片会发生什么?不知道。所以很多时候我们就会去训练一个二分类器来先区分是否是人脸,当然会使用大量的非人脸数据。而非人脸数据是非常广域的且收集的非人脸数据不一定是完备的,非人脸数据要求包裹到人脸数据,这样才会使人脸的分类稳定。而人并不是这样做的,人是将其作为不熟悉的事物来处理,即仅依赖见过的类别来判断。
参考:
1. 周志华,机器学习
2. Data domain description using support vectors
3.Support vector domain description
4.One Class SVM, SVDD(Support Vector Domain Description)
5.Domain described support vector classifier for multi-classification problems
6.Combining one-class classifiers
7. Novelty and Outlier Detection















 6538
6538

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









