







相关系列文章
目录
1.前言
作为一个coder,设计出一个好的架构和写出一手高质量的代码,都是不可缺少的技能;在我理解,高质量的代码意味着代码具有比较强的扩展性、维护性,高内聚和低耦合和尽可能少的bug;函数是我们编码过程中使用频率比较高的不可缺少的步骤,如何写出高质量的函数?不仅要遵循编写函数的代码规范,而且还要遵循函数的一些设计技巧。
2.函数的编码规范
1.可重入函数使用局部变量;可重入函数使用全部变量需要保护。
2.防止将函数的参数作为工作变量。
3.函数的规模尽量限制在200行以内,不包括注释和空格行。
4.如果参数是指针,且仅作输入用,则应在类型前加 const,以防止该指针在函数体内被意外修改。
5.函数功能尽可能的单一,不要把没有关联的语句放到一个函数中。
6.如果输入参数是以值传递的方式传递对象,则宜改用“ const &”方式来 传递,这样可以省去临时对象的构造和析构过程,从而提高效率。
7.避免设计多参数函数,参数个数尽量控制在 5 个以内。如果参数太多,在使用时容易将参数类型或顺序搞错。
8.尽量不要使用类型和数目不确定的参数。
9.善于使用断言,检查参数非法性和避免错误情况,提高程序可测性。
说明:断言是对某种假设条件进行检查(可理解为若条件成立则无动作,否则应报告),它可以快速发现并定位软件问题,同时对系统错误进行自动报警。断言可以对在系统中隐藏很深,用其它手段极难发现的问题进行定位,从而缩短软件问题定位时间,提高系统的可测性。
10.循环体内工作量最小化,多重循环中,应将最忙的循环放在最内层。
3.函数设计技巧
1.在用C语言编写一个函数封装成dll,设置一个回调,dll有事件就调用回调,通知上层,函数设计为:
typedef void (*eventCallBack)(int x, int y, void* pParam);
void setEventCallBack(eventCallBack, void* pParam);这个参数void* pParam是关键,它可以把设置回调前的状态通过dll流入回调后,省去了程序自身保留状态的过程,简化了流程。举个例子,在C++中需要在类中调用这个函数,那就可以把这个函数和类的this关联起来,函数调用就比较顺手了,示例如下:
class MyTest
{
public:
explicit MyTest(){
setEventCallBack(&MyTest::_eventCallBack, this);
}
void event(int x, int y){
//...
}
private:
static void _eventCallBack(int x, int y, void* pParam);
};
void MyTest::_eventCallBack(int x, int y, void* pParam)
{
MyTest* pTest = static_cast<MyTest*>(pParam);
if (pTest ){
pTest->event(x, y);
}
}在构造函数把this指针通过函数setEventCallBack把回调函数_eventCallBack设置进去,事件通知的时候,又把void*转换为this指针,直接调用event函数。如果没有void*参数,需要事先保存MyTest*,有了viod*就省去这个步骤了。
2.设计函数通过两次调用获取返回值
在有些场景下,比如通过文章的id获取文章的内容,设计函数为:
int getBookContent(char* pContent, int& len);用户调用的时候,他不知道pContent需要开辟多大的空间,只能尽可能的把pContent弄大一些,尽管如此,但还是不一定能满足要求,怎么办呢?此时,就可以把函数设计分为两步:第一步获取内容的大小,第二步获取内容数据,当然也可以通过函数返回值来判断传入的pContent缓冲区是否满足要求,调用过程可以这样:
int getBookContent(char* pContent, int& len);
void test()
{
int len = 0;
int result = 0;
//[1] 第一步
result = getBookContent(null, len);
//[2] 第二步
std::unique_ptr<char[]> pContent(new char[len]);
result = getBookContent(pContent.get(), len);
}实际案例:windows系统函数GetAdaptersInfo,获取网卡配置信息
DWORD GetAdaptersInfo(
PIP_ADAPTER_INFO pAdapterInfo, //指向一个缓冲区,用来取得IP_ADAPTER_INFO结构列表
PULONG pOutBufLen //指定上面缓冲区大小,如果大小不够,此参数返回所需大小
)IP_ADAPTER_INFO结构包含了本地计算机网络适配器的信息
#include <iostream>
#include <windows.h>
#include <Iphlpapi.h>
#pragma comment(lib, "Iphlpapi.lib")
using namespace std;
BOOL GetNetworkAdapterInfo()
{
PIP_ADAPTER_INFO pIPAdapterInfo = nullptr;
ULONG size = sizeof(IP_ADAPTER_INFO);
//填充pIPadapterInfo变量,其中size既是一个输入量,也是一个输出量
int nRet = GetAdaptersInfo(null, &size);
//记录网卡数量
int netCarNum = 0;
if (ERROR_BUFFER_OVERFLOW == nRet)
{
//如果返回此参数,说明GetAdaptersInfo参数传递的内存空间大小不够,同时传出size表示需要的内存空间大小
//释放原来的内存空间
pIPAdapterInfo = (PIP_ADAPTER_INFO)new byte[size];
//再次调用GetAdaptersInfo填充结构体
nRet = GetAdaptersInfo(pIPAdapterInfo, &size);
}
if (ERROR_SUCCESS == nRet)
{
//...
}
//释放分配的内存
if (pIPAdapterInfo)
delete pIPAdapterInfo;
return true;
}调用函数GetAdaptersInfo第一次传入null,获取到了电脑所有网络适配器数据占空间的总大小,第二次动态申请内存,获取所有的网络适配器真实数据。
3.实现链式表达式
就是为了后来函数调用者方便而设计的,这种方便的实现方法,看起来就是链子链在一起的,所以称为链式表达式;strcpy函数就是这样的典型:
char *strcpy(char *strDest, const char *strSrc);
{
assert((strDest!=NULL) && (strSrc !=NULL));
char *address = strDest;
while( (*strDest++ = * strSrc++) != ‘\0’ ) {;}
return address ;
}为什么要返回char*,就是为了实现链式表达式,实现如下面这样的调用:
int length = strlen( strcpy( strDest, “hello world”) );在我的另外一篇博客中提到的序列化类CDataStream就是链式表达式最好的示例,可自行阅读:
实际案例:C++标准库中的std::cout
std::cout类继承自ostream类,ostream(即basic_ostream)类继承自ios类,ios类继承自ios_base类,详细的继承关系如下图:
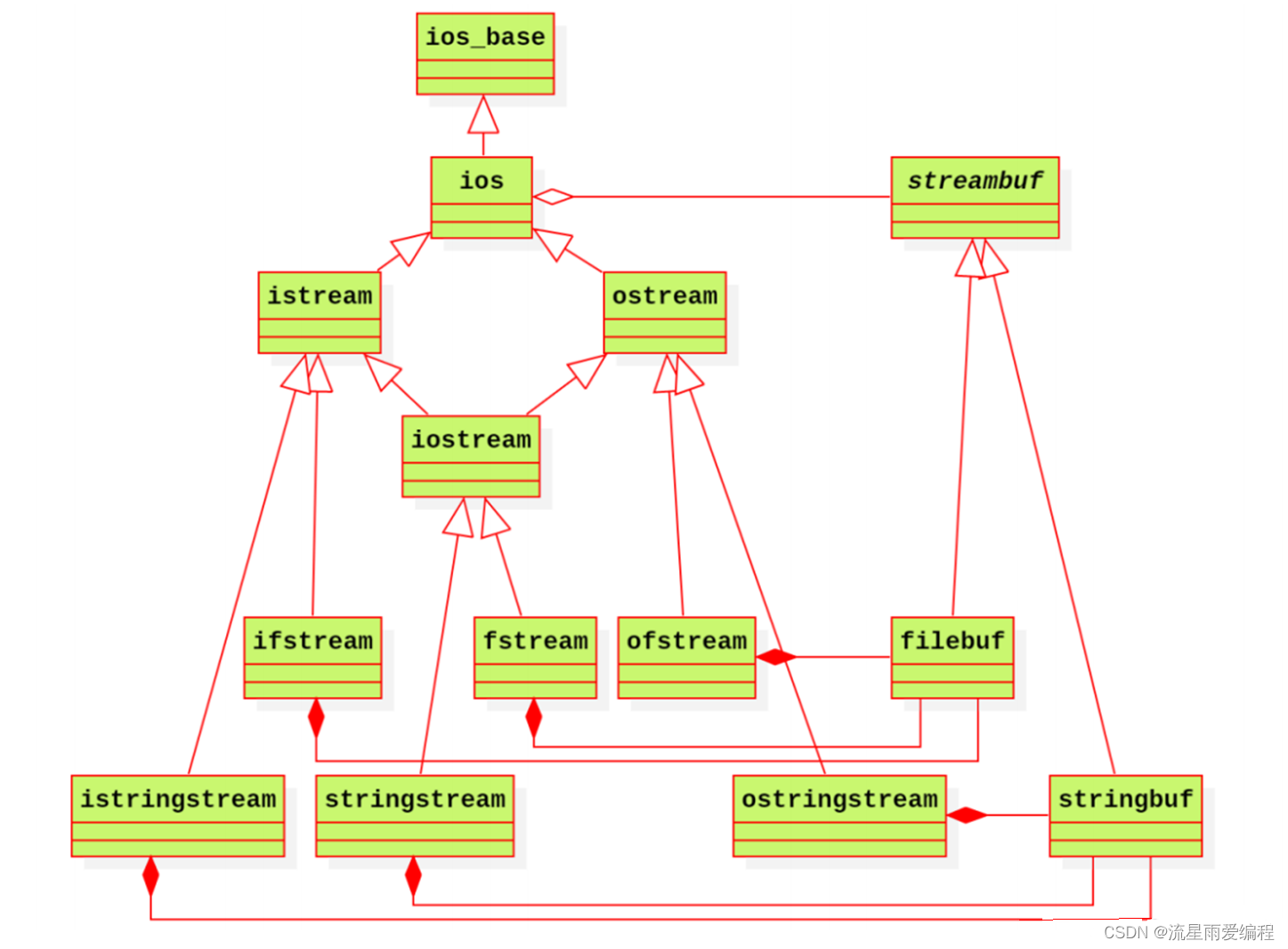
在basic_ostream类中详细实现了operator<<操作符
class basic_ostream : virtual public basic_ios<_Elem, _Traits> { // control insertions into a stream buffer
//...
//...
basic_ostream& __CLR_OR_THIS_CALL operator<<(
basic_ostream&(__cdecl* _Pfn)(basic_ostream&) );
basic_ostream& __CLR_OR_THIS_CALL operator<<(_Myios&(__cdecl* _Pfn)(_Myios&) );
basic_ostream& __CLR_OR_THIS_CALL operator<<(ios_base&(__cdecl* _Pfn)(ios_base&) );
basic_ostream& __CLR_OR_THIS_CALL operator<<(bool _Val);
basic_ostream& __CLR_OR_THIS_CALL operator<<(short _Val);
basic_ostream& __CLR_OR_THIS_CALL operator<<(unsigned short _Val);
basic_ostream& __CLR_OR_THIS_CALL operator<<(int _Val);
basic_ostream& __CLR_OR_THIS_CALL operator<<(unsigned int _Val);
basic_ostream& __CLR_OR_THIS_CALL operator<<(long _Val);
basic_ostream& __CLR_OR_THIS_CALL operator<<(unsigned long _Val);
basic_ostream& __CLR_OR_THIS_CALL operator<<(long long _Val);
basic_ostream& __CLR_OR_THIS_CALL operator<<(unsigned long long _Val);
basic_ostream& __CLR_OR_THIS_CALL operator<<(float _Val);
basic_ostream& __CLR_OR_THIS_CALL operator<<(double_Val);
basic_ostream& __CLR_OR_THIS_CALL operator<<(long double_Val);
basic_ostream& operator<<(nullptr_t);
basic_ostream& __CLR_OR_THIS_CALL operator<<(_Mysb* _Strbuf);
//...
};重载操作符<<,函数都是返回的basic_ostream&,就是为了实现链式表达式,完成如下的调用:
bool a = false;
int b = 100;
double c = 15.666
std::cout << a << b << c << "hello world" << std::endl;4.函数参数类型选择。
C++17增加了std::string_view,它在很多情况下会优于使用std::string 。
尤其是用做函数形参的时候,使用std::string_view基本一定优于老式的const std::string&这种写法。
C++17之前的写法:
void func(const std::string&s){
std::cout << s << '\n';
}C++17之后的写法:
void func(std::string_view s){
std::cout << s << '\n';
}std::string_view 只是一个视图,用来指代原字符串的,保有一个size和一个指针即可。比起std::string有一个构造的过程,要高效一些,更多详细的介绍可以参考 为什么C++17要引入std::string_view?-CSDN博客。
5.重载类型强制转换运算符
先看一下代码:
//【1】
namespace xyLinkCorePrivate {
template <typename T, typename Tag = void>
struct TCheck {
using type = T;
};
template <typename T>
struct TCheck < T, typename std::enable_if_t<!std::is_arithmetic_v<T> && !std::is_pointer_v<T>>> {
//除数值类型和指针除外
using type = const T&;
};
}
//【2】
template <typename T>
class ICloneable
{
public:
virtual T* clone() const = 0;
};
//【3】
class IMarshalData
{
public:
virtual CByteArray toByteArray() const = 0;
virtual bool parseData(const char* pData, PUInt64 len) = 0;
};
class IPersistData
{
public:
virtual std::string getPersistValue() const = 0;
virtual bool setPersistValue(const std::string& data) = 0;
};
class IMemoryData
{
public:
virtual bool setValue(const std::any& data) = 0;
virtual std::any value() const = 0;
};
class IParamField : public IMarshalData
, public IPersistData
, public IMemoryData
, public ICloneable<IParamField>
{
public:
virtual ~IParamField() {}
virtual IParamField* clone() const = 0;
};
template<typename T>
class CBasicParamFieldMemoryData : public IMemoryData
{
public:
explicit CBasicParamFieldMemoryData(typename xyLinkCorePrivate::TCheck<T>::type value) : m_value(value) {}
CBasicParamFieldMemoryData& operator=(typename xyLinkCorePrivate::TCheck<T>::type value) {
m_value = value;
return *this;
}
bool setValue(const std::any& data) override {
try
{
if (data.has_value()) {
m_value = std::any_cast<T>(data);
return true;
}
assert(false);
return false;
}
catch (std::bad_any_cast& e)
{
assert(false);
return false;
}
}
std::any value() const override {
return m_value;
}
private:
T m_value;
};
//T一定是基本类型参数
template<typename T, typename Y = void>
class CBasicParamField : public IParamField
{
public:
explicit CBasicParamField(const T value = 0) : m_value(value) {}
CByteArray toByteArray() const override {
CByteArray data;
CDataStream dataStream(&data);
const T temp = std::any_cast<const T>(m_value);
dataStream << temp;
return data;
}
bool parseData(const char* pData, PUInt64 len) override {
assert(len == sizeof(T));
CByteArray data(pData, len);
CDataStream dataStream(&data);
T temp;
dataStream >> temp;
m_value = temp;
return true;
}
IParamField* clone() const override {
//...
}
std::string getPersistValue() const override {
//...
}
bool setPersistValue(const std::string& data) override {
return true;
}
std::any value() const override {
return m_value.value();
}
bool setValue(const std::any& data) override {
return m_value.setValue(data);
}
private:
CBasicParamFieldMemoryData<T> m_value;
};CByteArray 和 CDataStream 的用法可参考:
在类 CBasicParamField 中 toByteArray() 函数使用了std::any_cast转化为 const T,如果使用了struct或class,必然有个拷贝构造的过程;parseData函数使用了 m_value = temp 同样也有赋值构造的过程,如果struct或class的构造函数比较复杂,那么这样代码编写的效率就比较低了,那怎么做才能避免这个拷贝的过程呢?
于是我们想到了重载 T& 这个强制转换运算符,在toByteArray() 和 parseData() 函数都使用这个引用,直接赋值,没有拷贝的过程,效率就提高了。
在类 CBasicParamFieldMemoryData 中增加两个重载引号转换运算符,代码如下:
//[1]
operator T& () {
return m_value;
}
//[2]
operator const T& () const {
return m_value;
}需要修改值的,调用2函数;不需要修改值的,调用1函数。
在使用的地方必须使用static_cast转换使用,如:
const T& temp = static_cast<const T&>(m_value);
T& temp = static_cast<T&>(m_value);上述代码经过优化后的如下:
template<typename T>
class CBasicParamFieldMemoryData : public IMemoryData
{
public:
explicit CBasicParamFieldMemoryData(typename xyLinkCorePrivate::TCheck<T>::type value) : m_value(value) {}
CBasicParamFieldMemoryData& operator=(typename xyLinkCorePrivate::TCheck<T>::type value) {
m_value = value;
return *this;
}
bool setValue(const std::any& data) override {
try
{
if (data.has_value()) {
m_value = std::any_cast<T>(data);
return true;
}
assert(false);
return false;
}
catch (std::bad_any_cast& e)
{
assert(false);
return false;
}
}
std::any value() const override {
return m_value;
}
operator T& () {
return m_value;
}
operator const T& () const {
return m_value;
}
private:
T m_value;
};
//T一定是基本类型参数
template<typename T, typename Y = void>
class CBasicParamField : public IParamField
{
public:
explicit CBasicParamField(const T value = 0) : m_value(value) {}
CByteArray toByteArray() const override {
CByteArray data;
CDataStream dataStream(&data);
const T& temp = static_cast<const T&>(m_value);
dataStream << temp;
return data;
}
bool parseData(const char* pData, PUInt64 len) override {
assert(len == sizeof(T));
CByteArray data(pData, len);
CDataStream dataStream(&data);
T& temp = static_cast<T&>(m_value);
dataStream >> temp;
return true;
}
IParamField* clone() const override {
//...
}
std::string getPersistValue() const override {
//...
}
bool setPersistValue(const std::string& data) override {
return true;
}
std::any value() const override {
return m_value.value();
}
bool setValue(const std::any& data) override {
return m_value.setValue(data);
}
private:
CBasicParamFieldMemoryData<T> m_value;
};6.未完待续。。。
你们知道还有哪些函数编程规范和实现技巧,欢迎在评论区留言讨论。
参考:















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









