







一、java程序在jvm的执行过程
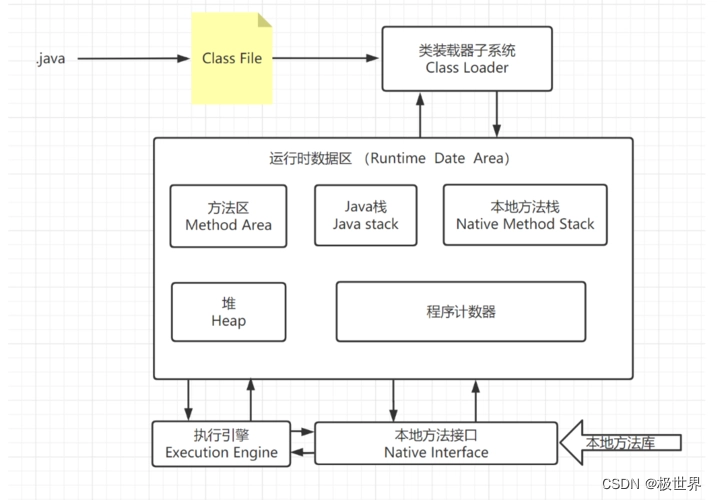
上图是我在百度找的一张简单的java程序执行过程。
1.首先编译器会把java程序进行编译形成.class文件
2.生成的.class文件会通过类加载器进入到运行数据区,这里是java程序运行的入口或者说开始。运行时数据区存储有java的类、方法、变量等相关信息。其中运行时数据区又分为方法区、栈、本地方法栈、堆、程序计数器。
3.方法区:静态变量、常量、类信息(构造方法,接口定义)、运行时的常量池储存在方法区中,但是对象实例中的变量信息存在堆中与方法区无关。
4.栈:
JVM 栈描述的是每个线程 Java 方法执行的内存模型:每个方法被执行的时候,JVM 会同步创建一个栈帧用于存储局部变量表、操作数栈、动态链接、方法出口 等信息。
栈是运行时单位,而堆是存储的单位,即栈解决的是运行问题,即程序如何执行,或者如何处理数据,功能类似于计算机硬件 PC寄存器。堆解决的是数据存储的问题,即数据怎么放、放哪儿。
栈主管程序运行,生命周期和线程同步,线程结束,栈内存就释放了。不存在垃圾回收问题
5.本地方法栈:与jvm中栈的区别不过是虚拟机栈为虚拟机执行Java方法(也就是字节码)服务,而本地方法栈则是为虚拟机使用到的Native方法服务。
二、双亲委派机制
理解双亲委派机制之前我们要理解下类加载器。
类加载器分为以下三种:
启动类(根)加载器
扩展类加载器
应用程序类加载器
这三个类加载器的执行顺序是这样的
根加载器(root)——>扩展类加载器(Ext)——>程序类加载器(app)
以下代码可以查看到几种类加载器的父子级别。
public class ClassLoaderTest {
public static void main(String[] args) {
ClassLoaderTest classLoaderTest = new ClassLoaderTest();
Class<? extends ClassLoaderTest> classloader1 = classLoaderTest.getClass();
ClassLoader classLoader = classloader1.getClassLoader();
System.out.println(classLoader);
System.out.println(classLoader.getParent());
System.out.println(classLoader.getParent().getParent());
}
}
执行结果:
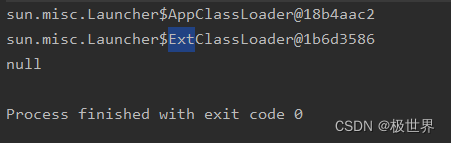
其中,null是表示根加载器,由于根加载器指向的指针为空所以返回null。
类加载器加载类的时候会先从root加载器中找是否在本地存在这个类,如果不存在则向下逐渐寻找。
如果加载器在本地找到了这个类那么就使用该级别的加载器。例如,我们自己写一个String类,然后在该类中写一个自定义方法,然后执行该方法。那么这个程序是跑不起来的。原因就是类加载器在APP这个加载器以上的加载器中已经找到了String类,执行的就是这个String类。而java中String类是没有我们自定义方法的,所以就会报错。
这样做的好处是什么呢?为了安全防止有人恶意篡改本地方法代码~
三、堆
一个jvm只有一个堆内存,堆内存的大小可以调节,平时我们所说的jvm调优其实就是调节方法区和堆内存的大小。
类加载器读取完class文件后一般会把类、对象、常量、变量的真实地址保存在堆中。堆还分为三个区域(新生区、养老区、元空间(永久区))。
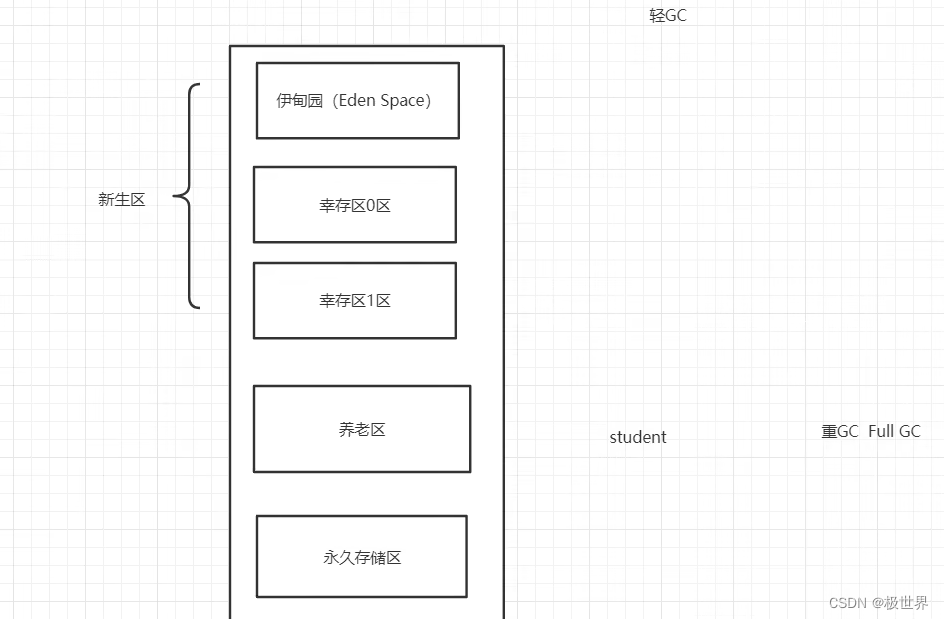
新生区执行的是轻GC垃圾回收的过程,在新生区中还存在伊甸园区还有两个幸存区。new出来的对象会在伊甸园区中,这个地方清理垃圾时会清理掉90%以上的对象,活的对象对被放入幸存区中。至于为什么是两个幸存区在垃圾回收算法中会说。
一般来说对象实例在新生区就已经被清理掉了,但是不保证总有一些顽强的对象活下来,在新生区活下来的对象会送到养老区执行重GC。jdk8以后永久区变成了元空间。
永久区是用来存放常驻内存的,这个地方不会发生GC。jdk8以后的方法区也在元空间中。严格意义上来说元空间不是在堆的范畴里面,所有通常这部分也叫非堆。
四、垃圾回收算法
标题1.标记–清除算法
执行步骤:
标记:遍历内存区域,对需要回收的对象打上标记。
清除:再次遍历内存,对已经标记过的内存进行回收。
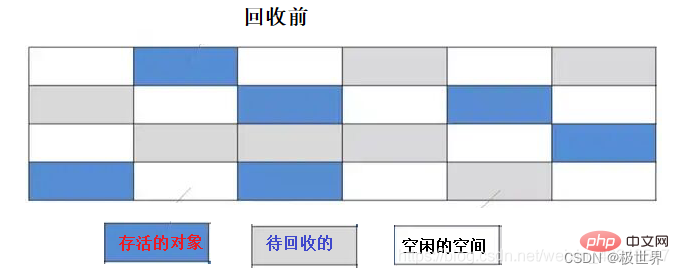
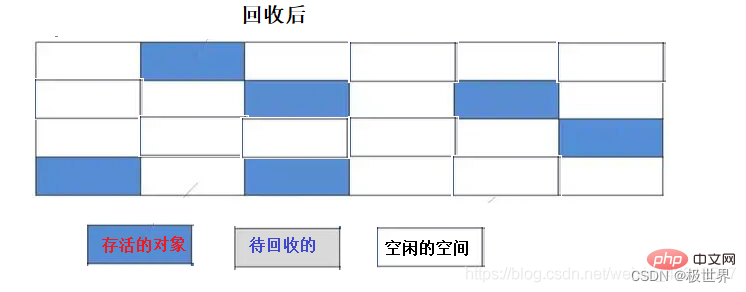
缺点:
效率问题:遍历了两次内存空间(第一次标记,第二次清除)。
空间问题:容易产生大量内存碎片,当再需要一块比较大的内存时,无法找到一块满足要求的,因而不得不再次出发GC。
2.复制算法
将内存划分为等大的两块,每次只使用其中的一块。当一块用完了,触发GC时,将该块中存活的对象复制到另一块区域,然后一次性清理掉这块没有用的内存。下次触发GC时将那块中存活的的又复制到这块,然后抹掉那块,循环往复。
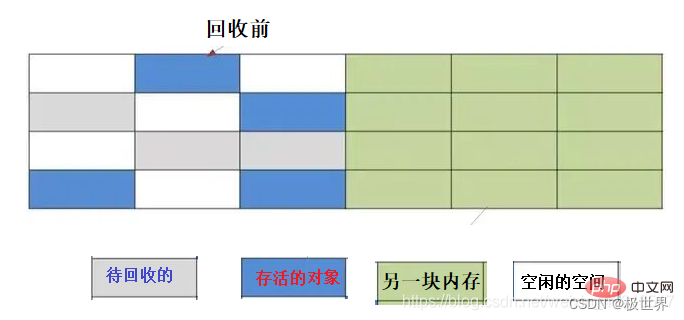
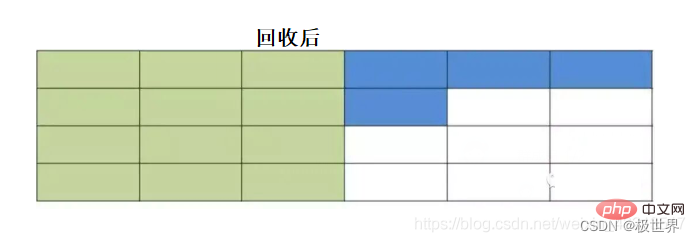
优点
相对于标记–清理算法解决了内存的碎片化问题。
效率更高(清理内存时,记住首尾地址,一次性抹掉)。
缺点:
内存利用率不高,每次只能使用一半内存。
改进
研究表明,新生代中的对象大都是“朝生夕死”的,即生命周期非常短而且对象活得越久则越难被回收。在发生GC时,需要回收的对象特别多,存活的特别少,因此需要搬移到另一块内存的对象非常少,所以不需要1:1划分内存空间。而是将整个新生代按照8 : 1 : 1的比例划分为三块,最大的称为Eden(伊甸园)区,较小的两块分别称为To Survivor和From Survivor。
首次GC时,只需要将Eden存活的对象复制到To。然后将Eden区整体回收。再次GC时,将Eden和To存活的复制到From,循环往复这个过程。这样每次新生代中可用的内存就占整个新生代的90%,大大提高了内存利用率。
但不能保证每次存活的对象就永远少于新生代整体的10%,此时复制过去是存不下的,因此这里会用到另一块内存,称为老年代,进行分配担保,将对象存储到老年代。若还不够,就会抛出OOM。
老年代:存放新生代中经过多次回收仍然存活的对象(默认15次)。
3. 标记–整理算法
因为前面的复制算法当对象的存活率比较高时,这样一直复制过来,复制过去,没啥意义,且浪费时间。所以针对老年代提出了“标记整理”算法。
执行步骤:
标记:对需要回收的进行标记
整理:让存活的对象,向内存的一端移动,然后直接清理掉没有用的内存。
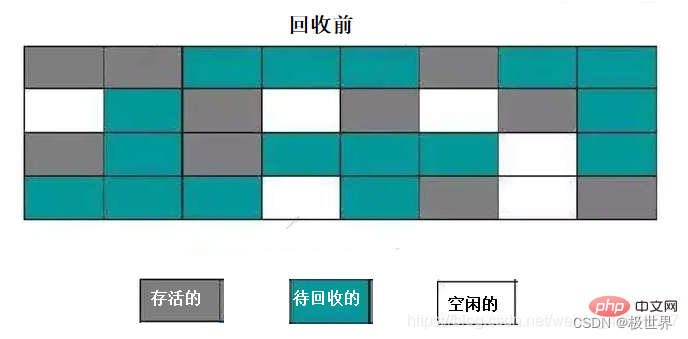
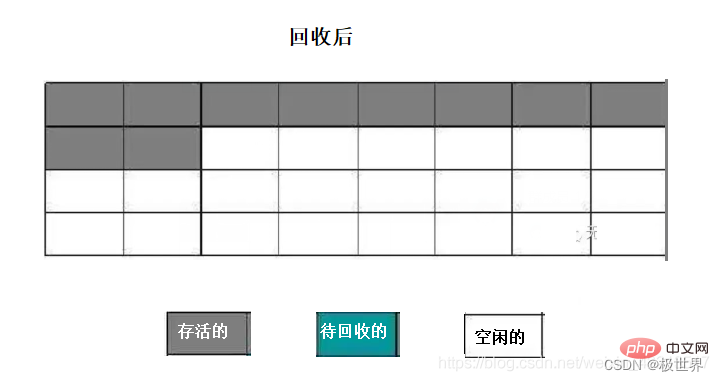
4. 分代收集算法
当前大多商用虚拟机都采用这种分代收集算法,这个算法并没有新的内容,只是根据对象的存活的时间的长短,将内存分为了新生代和老年代,这样就可以针对不同的区域,采取对应的算法。如:
新生代:每次都有大量对象死亡,有老年代作为内存担保,采取复制算法。
老年代:对象存活时间长,采用标记整理,或者标记清理算法都可。
MinorGC和FullGC的区别
MinorGC:发生在新生代的垃圾回收,因为新生代的特点,MinorGC非常频繁,且回收速度比较快,每次回收的量也很大。
FullGC:发生在老年代的垃圾回收,也称MajorGC,速度比较慢,相对于MinorGc慢10倍左右。进行一次FullGC通常会伴有多次多次MinorGC,。
















 618
618











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









