







大家好,这里是编程Cookbook。本文详细介绍计算机网络中的HTTP协议相关的内容,包括单不限于HTTP各个版本及其优势、请求和响应、HTTPS等。

关注公众号「编程Cookbook」,获取更多编程学习/面试资料!
HTTP 是无状态协议,如何实现有状态的会话管理?
HTTP 是无状态协议,意味着服务器不会保留客户端请求之间的状态信息。为了实现有状态的会话管理(如用户登录状态、购物车信息等),通常通过 Cookie、Session、Token、URL 重写 和 隐藏表单字段 等技术实现。
1. Cookie
Cookie 是由服务器在客户端(通常是浏览器)上存储的一小段数据,它可以用于记录用户信息,并在同一站点的不同页面之间或跨会话维持状态。
Cookie 的特点
- 存储位置:存储在客户端(浏览器)。
- 数据大小:通常限制为 4KB 左右。
- 数据格式:键值对(
key=value)。 - 生命周期:
- 会话 Cookie(Session Cookie):浏览器关闭后自动删除。
- 持久 Cookie(Persistent Cookie):有
Expires或Max-Age设定过期时间,可存储更久。
- 安全性:
- 默认情况下 Cookie 以纯文本存储,容易被篡改或窃取(可使用
HttpOnly和Secure提高安全性)。 - 可使用
SameSite限制跨站点发送 Cookie。
- 默认情况下 Cookie 以纯文本存储,容易被篡改或窃取(可使用
Cookie 的使用
Cookie 主要用于:
- 用户身份识别(如存储
session_id)。 - 用户偏好设置(如网站的语言、主题)。
- 跨页面状态管理(如购物车信息)。
2. Session
Session(会话)是一种服务器端的状态管理机制,用于在同一用户的多个请求之间保持状态。Session 数据通常存储在服务器的内存、数据库或缓存(如 Redis)中。
关注公众号「编程Cookbook」,获取更多编程学习/面试资料!
Session 的特点
- 存储位置:存储在服务器端。
- 数据大小:理论上不受浏览器限制。
- 数据格式:通常是对象或键值对。
- 生命周期:
- Session 默认在用户关闭浏览器或一段时间未活动时失效。
- 服务器可以配置 Session 的过期时间,如 30 分钟。
- 安全性:
- Session 数据存储在服务器端,相对 Cookie 更安全。
- 但仍需通过
session_id进行身份验证,session_id可能存储在 Cookie 中,因此仍需防范 XSS 和 CSRF 攻击。
Session 的使用
Session 主要用于:
- 用户身份认证(存储用户登录信息)。
- 购物车管理(存储用户的购物车内容)。
- 跨页面数据共享。
Session 工作流程
- 用户登录,服务器创建 Session,并生成一个
session_id。 - 服务器通过
Set-Cookie发送session_id给客户端。 - 客户端的后续请求会自动携带
session_id,服务器通过它查找 Session 数据。
3. Token
Token(令牌)是一种 无状态(stateless) 的身份认证机制,通常用于 API 认证和分布式系统中。常见的 Token 形式包括:
- JWT(JSON Web Token)
- OAuth 令牌
- API Key
Token 的特点
- 存储位置:客户端(浏览器、移动端、应用)。
- 数据大小:比 Cookie 略大,但仍需尽量保持简短(JWT 通常约 1KB)。
- 数据格式:JWT 格式通常为
header.payload.signature。 - 生命周期:
- 令牌可设置过期时间(如 1 小时)。
- 需要定期刷新(如使用
refresh_token)。
- 安全性:
- 需要加密签名防篡改(JWT 采用 HMAC 或 RSA 签名)。
- 如果存储在 Cookie 里仍需防范 XSS 和 CSRF。
- 如果存储在
localStorage或sessionStorage,需防范 XSS。
Token 的使用
Token 主要用于:
- API 认证(如 OAuth、JWT)。
- 移动端和前后端分离应用(前端通过 Token 访问后端 API)。
- 无状态认证(服务端无需存储用户状态)。
工作流程
- 用户登录,服务器验证身份后生成 Token,并返回给客户端。
- 客户端在每次请求时将 Token 放入
Authorization头中。 - 服务器验证 Token,若有效,则返回请求的数据。
Cookie、Session、Token 对比
Cookie VS Session
| 对比项 | Cookie | Session |
|---|---|---|
| 存储位置 | 客户端(浏览器) | 服务器 |
| 数据存储方式 | 以键值对存储在浏览器 | 服务器端内存、数据库、Redis 等 |
| 生命周期 | 可设置过期时间(默认关闭浏览器失效) | 默认会话级别(关闭浏览器即失效),但可持久化存储 |
| 存储数据大小 | 4KB 以内 | 无限制,服务器可扩展,存储量大 |
| 安全性 | 易被窃取、篡改(存储在客户端,需加密) | 相对安全(数据存储在服务器) |
| 访问方式 | 每次请求都会自动携带到服务器(Cookie: key=value) | 需通过 Session ID 关联,通常存储在 Cookie 中 |
| 服务器压力 | 无压力(数据存储在客户端) | 占用服务器资源(大量用户可能影响性能) |
| 跨域支持 | 只能在同源域名下使用(可通过 domain、path 进行设置) | 不支持跨域,Session ID 需手动传递 |
| 适用场景 | 适用于存储无需保密的用户偏好数据(如 记住密码、主题设置) | 适用于存储敏感信息(如登录状态、用户信息) |
Cookie VS Token
| 对比项 | Cookie | Token |
|---|---|---|
| 存储位置 | 客户端浏览器(本地存储) | 客户端(浏览器、移动端、第三方应用等) |
| 安全性 | 易被窃取(可能被 XSS 攻击利用) | 更安全(JWT 可加密、签名验证) |
| 认证方式 | 基于 Session(服务器存储 Session) | 无状态认证(Token 本身包含身份信息) |
| 跨域支持 | 受 Same-Origin Policy 限制 | 更易跨域(适用于 RESTful API) |
| 服务器存储 | 服务器端需要存储Session | 无需存储,服务器只需验证 Token |
| 传输方式 | 自动附加到请求头(Cookie: key=value) | 需要前端手动添加到 Authorization 头或请求参数 |
| 适用场景 | 浏览器端会话管理(如用户登录) | 分布式、移动端、微服务(如 JWT 认证) |
关注公众号「编程Cookbook」,获取更多编程学习/面试资料!
4. URL 重写
- 工作原理:
- 将会话 ID 附加到 URL 中(如
/path?sessionid=123)。 - 服务器通过 URL 中的会话 ID 识别客户端。
- 将会话 ID 附加到 URL 中(如
- 优点:
- 不需要 Cookie,适合禁用 Cookie 的场景。
- 缺点:
- URL 暴露会话 ID,安全性较低。
- 不适合复杂应用。
5. 隐藏表单字段
- 工作原理:
- 在 HTML 表单中隐藏会话 ID 字段。
- 客户端提交表单时将会话 ID 发送回服务器。
- 优点:
- 不需要 Cookie。
- 缺点:
- 仅适用于表单提交,局限性较大。
适用场景
- Cookie:适用于小型应用、传统网站的用户状态管理。
- Session:适用于服务器端身份管理,如企业后台、银行等安全要求高的场景。
- Token(JWT):适用于前后端分离、微服务、移动端、跨域 API 认证,尤其适合无状态认证。
WebSocket 与 HTTP 的区别
WebSocket 和 HTTP 是两种不同的通信协议,适用于不同的场景。以下是它们的主要区别:
WebSocket vs HTTP 区别总结
| 对比项 | WebSocket | HTTP |
|---|---|---|
| 协议类型 | 双向通信协议(全双工) | 请求-响应协议(半双工) |
| 通信方式 | 客户端 & 服务器可以主动发送消息 | 客户端请求,服务器响应(被动) |
| 报文大小 | 轻量级,无冗余头部,适合高频通信 | HTTP 头部信息较多,占用较大带宽 |
| 适用场景 | 实时应用(聊天、游戏、直播、股票行情推送) | 静态资源请求、API 交互 |
适用场景
WebSocket 适用于:
- 即时聊天应用(如微信 Web 版)
- 多人在线游戏(如 FPS、MMORPG)
- 实时股票/体育比分更新
- 协同办公(Google Docs 多人编辑)
HTTP 适用于:
- 普通网页请求(如 HTML、CSS、JS 资源加载)
- RESTful API 通信
- 静态资源加载
总结:WebSocket 适合长连接、高实时性的场景,而 HTTP 适用于短连接、请求-响应模式的场景。
HTTP请求方法
HTTP 常见方法及作用
| 方法 | 作用 | 使用场景 |
|---|---|---|
| GET | 获取资源 | 请求页面、查询数据(如搜索)。 |
| POST | 提交数据 | 提交表单、上传文件、创建资源。 |
| PUT | 更新或创建资源(全量更新) | 更新或创建指定资源(如更新用户信息)。 |
| PATCH | 部分更新资源 | 更新资源的某一部分(如修改用户邮箱)。 |
| DELETE | 删除资源 | 删除指定资源(如删除用户)。 |
| HEAD | 获取资源的元信息(不返回主体) | 检查资源是否存在或是否被修改。 |
| OPTIONS | 获取服务器支持的 HTTP 方法 | 检查服务器支持的请求方法。 |
| TRACE | 回显客户端的请求(用于调试) | 调试或诊断网络问题。 |
| CONNECT | 建立隧道(用于 HTTPS 代理) | 通过代理建立安全连接。 |
GET 和 POST 的区别
-
GET:
- 作用:请求获取资源,不修改服务器数据。
- 参数传递方式:URL。
- 幂等性:GET请求是幂等的,意味着多次相同请求返回结果相同。
- 缓存:可以被缓存。
- 数据大小:数据大小有限,通常受浏览器或服务器对URL长度的限制。
-
POST:
- 作用:用于提交数据到服务器,通常用于创建或更新资源。
- 参数传递方式:请求体。
- 幂等性:POST请求不是幂等的,意味着多次提交可能会产生不同的结果。
- 缓存:不应被缓存。
- 数据大小:数据量没有明确限制,适用于较大数据提交。
总结如下:
| 特性 | GET | POST |
|---|---|---|
数据位置 | 数据附加在 URL 中(查询参数)。 | 数据放在请求体中。 |
数据大小 | 受 URL 长度限制(通常 2048 字符)。 | 无限制(受服务器配置限制)。 |
安全性 | 数据暴露在 URL 中,不安全。 | 数据在请求体中,相对安全。 |
| 缓存 | 可被缓存。 | 默认不可缓存。 |
幂等性 | 幂等(多次请求结果相同)。 | 非幂等(多次请求可能产生不同结果)。 |
| 使用场景 | 获取数据(如搜索、查看页面)。 | 提交数据(如登录、上传文件)。 |
PUT 和 POST 的区别
PUT和POST都是给服务器发送新增资源,但他们的作用不同:
-
POST:
- 用途:用于提交数据,通常用于创建新资源。服务器根据请求体中的数据创建新资源,并返回资源的URL或ID。
- 幂等性:POST请求不是幂等的,可能产生不同的结果,如多次提交同一表单会创建多个资源。
- 场景:表单提交、上传文件等。
-
PUT:
- 用途:用于更新现有资源,或如果资源不存在,则创建资源。PUT请求会完全替换目标资源,必须提供完整的资源信息。
- 幂等性:PUT请求是幂等的,意味着多次相同请求会返回相同结果(同样的资源会被更新为相同的状态)。
- 场景:更新资源(如更新用户信息、文章内容等)。
关注公众号「编程Cookbook」,获取更多编程学习/面试资料!
总结如下:
| 特性 | PUT | POST |
|---|---|---|
| 作用 | 更新或创建指定资源(全量更新)。 | 创建新资源或提交数据。 |
幂等性 | 幂等(多次请求结果相同)。 | 非幂等(多次请求可能产生不同结果)。 |
| URI | URI 指向具体资源(如 /users/1)。 | URI 指向资源集合(如 /users)。 |
| 使用场景 | 更新或创建指定资源(如更新用户信息)。 | 创建新资源(如新增用户)。 |
PUT 和 PATCH 的区别
PUT和PATCH都是给服务器发送修改资源,但他们的作用不同:
-
PUT:
- 用途:更新指定资源的所有内容(全量更新)。如果资源不存在,可能会创建该资源。
- 请求体:提供资源的完整新版本。
- 幂等性:PUT请求是幂等的,多个相同的请求会产生相同的结果。
- 场景:完全替换现有资源,如更新某个对象的全部字段。
-
PATCH:
- 用途:部分修改指定资源(局部更新)。只发送需要修改的数据,而不是整个资源。
- 请求体:提供需要更新的字段。
- 幂等性:PATCH请求不一定是幂等的,但可以设计为幂等。
- 场景:更新资源的某一部分,如修改用户的部分信息(如只修改邮箱地址)。
总结如下:
| 特性 | PUT | PATCH |
|---|---|---|
| 作用 | 全量更新资源(替换整个资源)。 | 部分更新资源(仅修改指定字段)。 |
| 幂等性 | 幂等(多次请求结果相同)。 | 非幂等(多次请求可能产生不同结果)。 |
| 数据量 | 需要发送完整资源数据。 | 仅需发送需要修改的部分数据。 |
| 使用场景 | 更新整个资源(如替换用户信息)。 | 更新部分资源(如修改用户邮箱)。 |
GET 请求中 URL 编码的意义
- URL 编码(也称为百分号编码)是将 URL 中的特殊字符转换为
%后跟两位十六进制数的形式。 - 意义:
- 兼容性:URL 中只能包含 ASCII 字符,非 ASCII 字符(如中文)和特殊字符(如空格、
&、=)需要通过 URL 编码进行转换。 - 安全性:防止 URL 中的特殊字符被误解为控制字符(如
&被误解为参数分隔符)。 - 标准化:确保 URL 的唯一性和一致性。
- 兼容性:URL 中只能包含 ASCII 字符,非 ASCII 字符(如中文)和特殊字符(如空格、
- 示例:
- 空格编码为
%20。 - 中文字符
你编码为%E4%BD%A0。
- 空格编码为
URI、URL和URN的区别
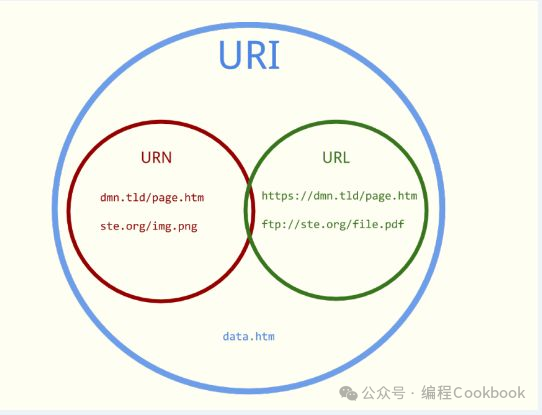
- URI 本身只是提供了对资源的标识,是一个总的概念,包含 URL 和 URN。
- URL 是带有定位信息的 URI,指定如何访问资源。
- URN 提供一个资源的唯一名称,但不关心资源的访问路径或位置。
三者区别如下:
| 特性 | URI | URL | URN |
|---|---|---|---|
| 定义 | 统一资源标识符,包含资源的标识,可以是 URL 或 URN。 | 统一资源定位符,指定如何定位和访问资源。 | 统一资源名称,只提供资源的标识,不涉及定位。 |
| 包含访问路径 | 可能包含,也可能不包含。 | 总是包含定位信息,如协议、主机和路径。 | 不包含定位信息,只包含资源的名称。 |
| 示例 | http://www.example.com 或 urn:isbn:0451450523 | https://www.example.com/index.html | urn:isbn:0451450523 |
| 主要用途 | 标识资源,无论是否涉及位置或访问方法。 | 标识并定位资源,通常包含访问路径。 | 唯一标识资源,常用于不依赖于位置的标识。 |
HTTP请求/响应报文
关注公众号「编程Cookbook」,获取更多编程学习/面试资料!
HTTP的请求报文
HTTP请求报文包括请求行、请求头、空行和请求体,其格式如下:
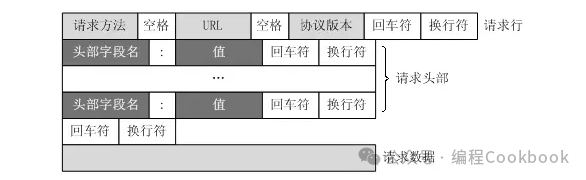
请求行
请求行包含三个部分:
- 请求方法(例如
GET、POST、PUT等) - 请求URL:请求资源的地址
- HTTP版本:如
HTTP/1.1
例子:
GET /index.html HTTP/1.1
请求头
请求头包含关于请求的各种信息(如主机、用户代理、接受类型等)。例如:
Host: www.example.com
User-Agent: Mozilla/5.0
Accept: text/html
空行
请求头和请求体之间必须有一个空行,标志着请求头的结束。
请求体
请求体包含要发送到服务器的数据。对于GET请求,请求体通常为空;对于POST、PUT等方法,请求体包含要发送的数据(如表单数据或JSON)。
HTTP的响应报文
HTTP响应报文包含响应行、响应头、空行、响应体,如下:

响应行
响应行包含三个部分:
- HTTP版本:如
HTTP/1.1 - 状态码:3位数字,如
200(成功)、404(未找到) - 状态码说明:简短的描述信息,如
OK、Not Found
例子:
HTTP/1.1 200 OK
响应头
响应头包含关于响应的各种信息(如服务器类型、内容类型、缓存控制等)。例如:
Content-Type: text/html
Content-Length: 1234
Server: Apache/2.4
空行
响应头和响应体之间必须有一个空行,标志着响应头的结束。
响应体
响应体包含服务器返回的实际数据(如HTML、JSON、图片等)。
HTTP报文常见字段
常见的HTTP请求和响应字段包括:
请求头常见字段
Host:请求的主机名User-Agent:客户端浏览器信息Accept:客户端能处理的响应内容类型Authorization:身份验证信息Cookie:客户端存储的Cookie信息
响应头常见字段
Content-Type:响应内容的类型Content-Length:响应体的长度Set-Cookie:服务器向客户端发送CookieCache-Control:缓存控制Location:重定向的URL
服务端是如何解析HTTP请求的数据
关注公众号「编程Cookbook」,获取更多编程学习/面试资料!
服务端解析HTTP请求时,通常按以下步骤处理:
- 解析请求行:从请求报文的开始处获取请求方法(如
GET)、URL路径、HTTP版本。 - 解析请求头:逐个解析请求头字段,如
Host、User-Agent、Accept等。 - 解析请求体:如果请求方法是
POST或PUT等,会包含请求体,服务端需要根据Content-Type解析请求体的数据(如表单数据、JSON等)。 - 处理请求:根据请求方法(如
GET、POST等)执行相应的操作,例如从数据库获取数据或处理表单数据。 - 生成响应报文:根据请求处理结果,生成HTTP响应报文并发送回客户端。
HTTP长连接(keep-alive)
什么是HTTP长连接?
HTTP长连接(Persistent Connection)是一种允许在同一个TCP连接上进行多个HTTP请求-响应对的技术,减少了重复建立和关闭TCP连接的开销,提高了请求效率。
在HTTP/1.1及更高版本中,长连接是默认启用的(除非客户端或服务器明确关闭它)。
为什么需要HTTP长连接?
在HTTP/1.0中,每次请求都会建立一个新的TCP连接,请求完成后立即关闭。这导致了以下问题:
- 连接建立开销大:每个请求都需要进行三次握手和四次挥手,增加了网络开销和延迟。
- 资源浪费:频繁的TCP连接建立和释放浪费了CPU、带宽、内存等资源。
解决方案:
-
在HTTP/1.1中,默认启用了长连接,即在同一个TCP连接上允许多个HTTP请求和响应的交互,避免了每次请求都建立新连接的开销。
-
在 HTTP/1.0 中,
keep-alive不是默认开启的,需要手动添加Connection: keep-alive头部。服务器可以设置Keep-Alive头字段来指定最大请求数和超时时间,如:Keep-Alive: timeout=10, max=100表示如果10秒内没有新的请求,或者达到100个请求,连接会被关闭。
长连接 vs 短连接
| 长连接(Persistent Connection) | 短连接(Non-Persistent Connection) | |
|---|---|---|
| 连接方式 | 复用同一个TCP连接 | 每次请求都重新建立TCP连接 |
| HTTP版本 | HTTP/1.1及以上默认支持 | HTTP/1.0默认是短连接 |
| 优点 | 减少连接建立的开销,减少延迟,提高性能 | 适用于单次请求的场景 |
| 缺点 | 可能会占用过多连接资源 | 每次请求的TCP握手和断开增加了延迟 |
| 适用场景 | 需要加载多个资源的网页、API请求、长时间交互 | 低频次的HTTP请求,如一次性API调用 |
使用场景
适合长连接的场景
- 网页加载:浏览器请求HTML页面后,还需要加载CSS、JS、图片等资源,长连接减少了重复建立连接的开销,提高了页面加载速度。
- RESTful API:如果一个客户端需要频繁向服务器发送API请求,使用长连接可以减少建立连接的消耗,提高吞吐量。
- WebSocket:WebSocket建立连接后,需要保持持久化通信,通常依赖长连接。
关注公众号「编程Cookbook」,获取更多编程学习/面试资料!
适合短连接的场景
- 一次性HTTP请求:如访问某个API接口,并且不会在短时间内再次请求。
- 资源受限的服务器:如果服务器资源有限,可能会关闭长连接,以便更快地释放资源。
- 安全性要求较高的环境:比如银行系统可能更倾向于短连接,以防止长时间的连接被劫持。
总结
- HTTP长连接允许多个请求共享一个TCP连接,减少了重复连接的开销,提高了性能。
keep-alive头字段用于维持长连接,减少TCP连接的重复建立和关闭。- HTTP/1.1默认支持长连接,HTTP/1.0需要手动指定
Connection: keep-alive。 - 短连接适用于低频请求或高安全性需求的环境,长连接适用于高频请求的场景(如网页加载、API请求)。
- HTTP/2 通过多路复用进一步优化了长连接,避免了HTTP/1.1的队头阻塞问题。
Forward(转发)和 Redirect(重定向)的区别
Forward(转发)
- 定义:
forward是服务器内部的操作,它将客户端请求转发给另一个资源(通常是同一服务器上的另一个页面或Servlet)。 - 特性:浏览器不知情,URL不变,客户端不会感知转发的发生。
- 使用场景:通常用于在后台处理一些逻辑,如从一个Servlet转发到另一个Servlet。
Redirect(重定向)
- 定义:
redirect是服务器向客户端发出的命令,指示浏览器重新发送请求到另一个URL。 - 特性:浏览器会看到新的URL,URL会发生改变。通常由HTTP响应中的
Location头指定重定向的目标。 - 使用场景:用于改变资源的位置,或者用于处理如登陆后的跳转等。
ForwardvsRedirect` 对比
| 对比项 | forward(请求转发) | redirect(重定向) |
|---|---|---|
| 服务器/客户端 | 服务器内部行为 | 客户端行为 |
| URL 变化 | 不变(地址栏不变) | 变化(地址栏变更) |
| 请求次数 | 1 次 | 2 次 |
| 数据传递 | 请求数据可传递(同一个 request) | 请求数据不能传递(新请求) |
| 适用范围 | 站内页面跳转 | 站内或站外跳转 |
| 性能 | 更高(只发生一次请求) | 略低(发生两次请求) |
总结:
- Forward:不改变URL,服务器内部操作,浏览器不可见。
- Redirect:改变URL,客户端(浏览器)可见,浏览器会发起新请求。
关注公众号「编程Cookbook」,获取更多编程学习/面试资料!
什么时候用 Forward,什么时候用 Redirect?
- 如果要在服务器内部跳转(且数据要保留)→ 用
forward。 - 如果要跳转到外部网站或让用户访问新URL → 用
redirect。 - 如果要避免表单重复提交(如提交后跳转到结果页)→ 用
redirect。
状态码
常见 HTTP 状态码及使用场景
HTTP 状态码分为 5 类:
- 1xx(信息性): 请求已收到,继续处理
- 2xx(成功): 请求成功
- 3xx(重定向): 需要额外操作完成请求
- 4xx(客户端错误): 请求有错误,客户端需修改请求
- 5xx(服务器错误): 服务器处理请求失败
1xx:信息性状态码
| 状态码 | 含义 | 使用场景 |
|---|---|---|
| 100 Continue | 服务器收到请求的头部,客户端可继续发送请求体 | 客户端发送大请求前先确认服务器是否愿意接受 |
| 101 Switching Protocols | 服务器同意客户端请求,切换协议 | WebSocket 连接的协议升级(HTTP → WebSocket) |
2xx:成功状态码
| 状态码 | 含义 | 使用场景 |
|---|---|---|
| 200 OK | 请求成功,服务器返回资源 | 正常的 GET/POST 请求 |
| 201 Created | 资源已成功创建 | API 创建新用户、上传文件 |
| 202 Accepted | 请求已接受,但未完成处理 | 异步任务提交成功(如消息队列) |
| 204 No Content | 请求成功,但无返回数据 | DELETE 操作成功,或无需返回内容 |
| 206 Partial Content | 服务器成功返回部分内容 | 断点续传、大文件下载(Range 请求) |
3xx:重定向状态码
| 状态码 | 含义 | 使用场景 |
|---|---|---|
| 301 Moved Permanently | 资源永久移动,使用新 URL | 旧网址跳转到新网址(SEO 友好) |
| 302 Found | 资源临时移动 | 需要跳转但 URL 可能会变(登录后跳转) |
| 303 See Other | 资源已找到,需用 GET 访问新地址 | POST 提交表单后跳转到新页面 |
| 304 Not Modified | 资源未修改,客户端可使用缓存 | 浏览器缓存机制(If-Modified-Since, ETag) |
| 307 Temporary Redirect | 资源临时移动,但必须使用相同的请求方法 | 用 POST 请求时,302 可能会改为 GET,而 307 不会 |
301 vs. 302 如何选?
- 永久变更用
301(例如:HTTP → HTTPS)。- 临时跳转用
302、303、307(例如:登录后跳转到首页)。
303、307、302 的区别
| 状态码 | 含义 | 请求方法变化 | 常见使用场景 |
|---|---|---|---|
| 302 | 临时重定向(Found) | 可能变化、慎用(浏览器可能把 POST 转为 GET) | 临时重定向,常用于用户登录后跳转首页等场景 |
| 303 | 临时重定向(See Other) | 强制转换为 GET | 表单提交后跳转到另一个页面,防止浏览器刷新时重复提交 |
| 307 | 临时重定向(Temporary Redirect) | 保持不变(POST 仍然是 POST) | RESTful API,确保请求方法保持一致(如 POST) |
总结要点:
- 302 是 HTTP/1.0 的旧版本,浏览器行为可能不一致,可能会把 POST 请求转换为 GET。
- 303 强制客户端使用 GET 请求访问新的 URL,通常用于表单提交后的重定向。
- 307 确保请求方法不变,适用于
RESTful API 场景,保证 POST 请求依然是 POST。
4xx:客户端错误状态码
| 状态码 | 含义 | 使用场景 |
|---|---|---|
| 400 Bad Request | 请求语法错误,服务器无法理解 | JSON 结构错误,参数缺失 |
| 401 Unauthorized | 未授权,需提供身份验证 | 需要登录或 Token 才能访问 |
| 403 Forbidden | 服务器拒绝请求,权限不足 | 用户无权限访问某个资源 |
| 404 Not Found | 资源不存在 | 访问错误的 URL |
| 405 Method Not Allowed | 请求方法不被允许 | 用 GET 访问需要 POST 的接口 |
| 408 Request Timeout | 请求超时 | 网络延迟或服务器等待超时 |
| 413 Payload Too Large | 请求体过大 | 上传文件超过服务器限制 |
5xx:服务器错误状态码
| 状态码 | 含义 | 常见原因 |
|---|---|---|
| 500 Internal Server Error | 服务器内部错误 | 代码报错(如空指针异常)、数据库崩溃、配置错误 |
| 502 Bad Gateway | 代理网关错误 | Nginx/Apache 连不上后端服务(如后端宕机、端口错误) |
| 503 Service Unavailable | 服务不可用 | 服务器过载、主动维护、资源不足 |
| 504 Gateway Timeout | 网关超时 | 代理等待后端响应超时(后端处理太慢或死锁) |
一句话记忆口诀:
🔴 500:服务器自己挂了
🟠 502:网关找不到后端
🟡 503:服务器忙或下线
🔵 504:网关等后端等到超时
关注公众号「编程Cookbook」,获取更多编程学习/面试资料!
最佳回答
- 200 OK(请求成功)
- 301 Moved Permanently(永久重定向)
- 302 Found(临时重定向)
- 403 Forbidden(权限不足)
- 404 Not Found(资源不存在)
- 500 Internal Server Error(服务器错误)
HTTPS
HTTP 和 HTTPS 的区别
HTTP 和 HTTPS 都是用于传输数据的协议:
- HTTP:用于一般的网页访问,不提供加密和安全验证。
- HTTPS:通过 SSL/TLS 加密,为数据提供安全性和完整性,并且通过证书验证服务器身份,确保数据的保密性、完整性和防篡改性。
它们之间有几个关键区别如下:
| 区别项 | HTTP | HTTPS |
|---|---|---|
| 全称 | HyperText Transfer Protocol | HyperText Transfer Protocol Secure |
加密 | 不加密,数据以明文形式传输 | 使用 SSL/TLS 加密协议,数据传输是加密的 |
端口号 | 默认端口:80 | 默认端口:443 |
安全性 | 数据以明文传输,容易被窃听和篡改 | 通过 SSL/TLS 协议加密,确保数据的保密性、完整性和身份验证 |
认证机制 | 无认证机制 | SSL/TLS 证书认证,确保服务器身份的真实性 |
| 性能 | 相较于 HTTPS,性能稍快(因为没有加密过程) | 相较于 HTTP,性能略低(因为加密和解密过程) |
| 常见使用场景 | 一般用于不需要安全性的普通网页访问 | 用于需要确保数据安全的场景,如网上银行、支付平台、登录页面等 |
为什么有了 HTTP 还需要 HTTPS?
HTTP 是一个非常基础的协议,虽然它能够传输数据,但它存在以下问题,这也是 HTTPS 诞生的原因:
-
数据泄露:
- HTTP 在传输过程中不对数据进行加密,任何中间人(例如黑客、ISP 或路由器)都可以通过监听网络流量获取数据。这意味着敏感信息(如用户名、密码、银行卡信息等)在传输过程中可能被窃取。
- HTTPS 使用 SSL/TLS 加密协议,确保数据在传输过程中被加密,只有接收方能够解密。这样,即使数据被窃取,也无法读取其中的内容。
-
数据篡改:
- HTTP 数据是明文传输的,这使得黑客可以在传输过程中篡改数据。例如,黑客可以修改你访问的网页内容、发送给服务器的请求等。
- HTTPS 通过加密和数据完整性校验,确保传输过程中数据不会被篡改。每次数据传输都会有 消息验证码(MAC),以确保数据的完整性。
-
身份验证:
- 使用 HTTP,客户端无法验证与其通信的服务器是否真实合法,容易遭遇伪装成合法网站的攻击(例如中间人攻击)。
- HTTPS 使用 数字证书 来验证服务器身份。每个 HTTPS 网站都有一个 SSL/TLS 证书,它由受信任的证书颁发机构(CA)签发,确保客户端与服务器之间的连接是安全可靠的。
-
SEO 优势:
- 搜索引擎(如 Google)已经表示,HTTPS 是一个 排名因素,它在搜索引擎排名中有一定的加分作用。
- 使用 HTTPS 的网站能够提高访问者的信任感和浏览体验。
关注公众号「编程Cookbook」,获取更多编程学习/面试资料!
HTTPS 是如何保证通信安全的?
HTTPS(HyperText Transfer Protocol Secure)通过加密、身份验证、完整性保护来保障通信安全:
- 数据加密:防止数据被窃听(采用 对称加密 保护传输内容)。
- 身份认证:防止中间人攻击(使用 数字证书 验证服务器身份)。
- 数据完整性:防止数据被篡改(使用 MAC/HMAC 或 数字签名 确保数据完整)。
HTTPS 主要依赖 SSL/TLS(安全传输协议)来实现这些安全机制。
什么是数字证书(SSL/TLS 证书)?
数字证书(SSL/TLS 证书) 是用于验证网站服务器身份的一种凭证,由权威的 CA(证书颁发机构) 颁发,类似于网站的身份证。
数字证书包含的信息
- 网站的 公钥(用于加密通信)
- 证书持有者信息(如域名)
- 证书颁发机构(CA)信息
- 证书的有效期
- 数字签名(由 CA 使用私钥签名,确保证书的真实性)
工作方式
- 客户端访问 HTTPS 站点时,服务器提供 数字证书。
- 客户端验证证书是否被信任(检查是否由权威 CA 颁发)。
- 验证通过后,客户端与服务器建立安全通信。
对称加密 vs. 非对称加密
HTTPS 结合了对称加密和非对称加密,以兼顾安全性和性能。
| 加密方式 | 特点 | 应用场景 |
|---|---|---|
| 对称加密 🔑 | 同一个密钥 既用于加密也用于解密 | 速度快,适合数据传输加密(如 HTTPS) |
| 非对称加密 🔐 | 公钥加密,私钥解密 | 安全性高,适合身份认证、密钥交换(如 TLS 证书验证) |
HTTPS 的加密方式
- 非对称加密(RSA、ECDHE)—— 交换密钥(密钥协商)。
- 对称加密(AES、ChaCha20)—— 用于加密具体数据,提高效率。
HTTPS 工作原理
HTTPS 主要依赖 TLS(传输层安全协议),其工作原理如下:
- 客户端向服务器发送 HTTPS 请求。
- 服务器返回数字证书(含公钥)。
- 客户端验证证书(检查 CA 可信度、证书有效期等)。
- 客户端使用公钥加密
会话密钥,然后发送给服务器(使用非对称加密,服务器可用私钥解密)。 - 服务器使用私钥解密
会话密钥。 - 双方使用
会话密钥进行对称加密,之后的通信数据都是加密的。
HTTPS 过程(TLS 握手详解)
HTTPS 的安全通信过程由 TLS/SSL 握手 和 加密通信 两个部分组成。
1. TLS/SSL 握手过程
目标:建立安全连接,生成对称密钥。
-
客户端发起请求
- 客户端向服务器发送 “ClientHello” 消息。
- 指定支持的 TLS 版本(如 TLS 1.3)、加密算法(如 AES)等。
-
服务器响应
- 服务器返回 “ServerHello”,选择加密算法。
- 服务器发送 SSL 证书(含公钥)。
-
证书验证
- 客户端验证证书是否可信(检查 CA 签名、域名匹配)。
- 若证书不可信,则连接失败。
-
密钥交换
- RSA 方式(传统):客户端生成随机密钥,用公钥加密,服务器用私钥解密。
- ECDHE 方式(现代):使用 Diffie-Hellman 算法协商共享密钥,提高安全性。
-
生成对称密钥
- 双方计算出相同的 “会话密钥”(用于对称加密)。
- 服务器和客户端发送 Finished 消息,握手完成。
(2)加密通信过程
- 握手后,双方使用对称加密(如 AES)加密 HTTP 数据。
- 每次通信,数据都经过 HMAC 校验 以确保完整性。
关注公众号「编程Cookbook」,获取更多编程学习/面试资料!
HTTPS 的安全特性
HTTPS 依赖 SSL/TLS 协议,提供以下安全保障:
- 加密(Encryption):防止数据被窃听。
- 认证(Authentication):通过数字证书验证服务器身份。
- 完整性(Integrity):防止数据被篡改(HMAC)。
消息验证码(MAC,Message Authentication Code)
消息验证码(MAC, Message Authentication Code) 是一种用于 验证数据完整性 和 消息真实性 的技术,广泛用于加密通信中,比如 HTTPS、TLS、VPN、JWT 等。
它的主要作用是确保:
- 数据完整性(Integrity):确保数据在传输过程中没有被篡改。
- 消息认证(Authentication):确保消息来源是可信的,而不是伪造的。
MAC 的基本工作原理
MAC 由消息数据和密钥共同计算得到,通常使用加密哈希算法(如 SHA-256)或块密码(如 AES)生成。计算出的 MAC 附加到数据包中,接收方使用相同的密钥计算 MAC,并与发送方的 MAC 进行比对,以确认数据是否被篡改。
MAC 生成和验证过程
-
发送端:
- 使用 MAC 算法(如 HMAC)对消息和密钥进行计算,得到 MAC 值。
- 发送 消息 + MAC 值 给接收方。
-
接收端:
- 使用相同的 MAC 算法 和 密钥 计算消息的 MAC 值。
- 将计算出的 MAC 值与接收到的 MAC 值进行比对:
- 匹配 ✅:消息完整、未被篡改。
- 不匹配 ❌:数据被篡改或来源不可信。
MAC 在 HTTPS 中的应用
在 HTTPS/TLS 传输过程中,数据需要保证完整性和真实性,常用 HMAC-SHA256 作为 MAC 算法:
- 服务器和客户端共享一个对称密钥。
- 服务器对每条 HTTP 响应数据计算 HMAC-SHA256 并附加。
- 客户端收到数据后,重新计算 HMAC-SHA256 并比对,确认数据完整无篡改。
MAC 和数字签名的区别
| 特性 | MAC(消息验证码) | 数字签名 |
|---|---|---|
| 密钥类型 | 对称密钥(Sender & Receiver 共享) | 非对称密钥(公钥 + 私钥) |
| 主要功能 | 用于验证消息的完整性和真实性,确保未被篡改且来自合法发送方 | 确保身份认证和不可抵赖性 |
| 加密方式 | 基于哈希函数或加密算法 | 基于公钥加密 |
| 适用场景 | HTTPS、VPN、API 认证等 | 数字证书、电子签名、SSL/TLS |
🔹 MAC 适用于对称密钥环境,快速高效。
🔹 数字签名适用于非对称密钥环境,提供更高的安全性。
HTTPS 的证书链是如何验证的?
HTTPS 的证书链验证是确保服务器证书可信的过程。以下是证书链验证的步骤:
1. 获取证书链
- 服务器在握手过程中会发送自己的证书以及中间证书(Intermediate Certificates)。
- 证书链通常包括:
- 服务器证书(Leaf Certificate)。
- 中间证书(Intermediate Certificates)。
- 根证书(Root Certificate,通常由客户端本地存储)。
2. 验证证书链
- 客户端会逐级验证证书链中的每个证书:
- 验证服务器证书:
- 检查服务器证书的有效期、域名是否匹配、是否被吊销(通过 CRL 或 OCSP)。
- 验证中间证书:
- 检查中间证书是否由可信的根证书签发。
- 检查中间证书的有效期和吊销状态。
- 验证根证书:
- 检查根证书是否在客户端的受信任根证书存储中。
- 验证服务器证书:
3. 验证签名
- 客户端使用上一级证书的公钥验证当前证书的签名。
- 例如,使用中间证书的公钥验证服务器证书的签名。
4. 完成验证
- 如果所有证书都验证通过,客户端认为服务器证书是可信的,可以继续建立安全连接。
什么是中间人攻击?HTTPS 如何防止中间人攻击?
什么是中间人攻击?
- 中间人攻击(Man-in-the-Middle Attack, MITM) 是指攻击者在客户端和服务器之间插入自己,窃取或篡改通信数据。
- 攻击方式:
- 攻击者伪装成服务器,与客户端建立连接。
- 攻击者伪装成客户端,与服务器建立连接。
- 攻击者可以窃取敏感信息(如密码、信用卡号)或篡改通信内容。
HTTPS 如何防止中间人攻击?
HTTPS 通过以下机制防止中间人攻击:
-
加密通信:
- HTTPS 使用 SSL/TLS 协议对通信数据进行加密,攻击者无法解密窃取的数据。
-
证书验证:
- 服务器在握手过程中会发送自己的证书,客户端会验证证书的真实性。
- 如果证书无效或不可信,客户端会终止连接。
-
公钥基础设施(PKI):
- HTTPS 依赖 PKI 体系,确保服务器证书由可信的证书颁发机构(CA)签发。
- 客户端会验证证书链,确保证书的真实性。
-
防止证书伪造:
- 攻击者无法伪造有效的服务器证书,因为证书需要由受信任的 CA 签发,并且包含服务器的公钥和签名。
-
HSTS(HTTP Strict Transport Security):
- HSTS 是一种安全策略,强制客户端使用 HTTPS 连接,防止攻击者通过 HTTP 进行中间人攻击。
关注公众号「编程Cookbook」,获取更多编程学习/面试资料!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









