







TransMix: Attend to Mix for Vision Transformers

本文 “TransMix: Attend to Mix for Vision Transformers” 提出 TransMix,一种用于视觉 Transformer(ViT)的数据增强技术。它基于 ViT 的注意力图混合标签,解决了以往 mixup 方法中输入与标签空间不一致的问题。无需引入额外参数和计算量,就能提升多种 ViT 模型在 ImageNet 分类任务的准确率,如使 DeiT-S 和 XCiT-L 的 Top-1 准确率均提高 0.9%。经 TransMix 预训练的模型在语义分割、目标检测等下游任务中表现更优,且在多个基准测试中展现出更强的鲁棒性。
摘要-Abstract
Mixup-based augmentation has been found to be effective for generalizing models during training, especially for Vision Transformers (ViTs) since they can easily overfit. However, previous mixup-based methods have an underlying prior knowledge that the linearly interpolated ratio of targets should be kept the same as the ratio proposed in input interpolation. This may lead to a strange phenomenon that sometimes there is no valid object in the mixed image due to the random process in augmentation but there is still response in the label space. To bridge such gap between the input and label spaces, we propose TransMix, which mixes labels based on the attention maps of Vision Transformers. The confidence of the label will be larger if the corresponding input image is weighted higher by the attention map. TransMix is embarrassingly simple and can be implemented in just a few lines of code without introducing any extra parameters and FLOPs to ViT-based models. Experimental results show that our method can consistently improve various ViT-based models at scales on ImageNet classification. After pre-trained with TransMix on ImageNet, the ViT-based models also demonstrate better transferability to semantic segmentation, object detection and instance segmentation. TransMix also exhibits to be more robust when evaluating on 4 different benchmarks.
基于 Mixup 的数据增强方法已被证实,在训练过程中对模型的泛化十分有效,尤其是对于视觉 Transformer(ViT)模型,因为这类模型很容易过拟合。然而,以往基于 Mixup 的方法存在一个潜在的先验假设,即目标的线性插值比例应与输入插值中设定的比例保持一致。这可能会导致一种奇怪的现象:由于增强过程中的随机操作,混合图像中有时不存在有效的物体,但在标签空间中却仍有响应。
为了弥合输入空间和标签空间之间的这种差距,我们提出了 TransMix 方法,它基于视觉Transformer 的注意力图来混合标签。如果注意力图对相应输入图像的加权更高,那么该标签的置信度就会更大。TransMix 非常简单,只需几行代码即可实现,并且不会给基于ViT 的模型引入任何额外的参数和计算量。实验结果表明,我们的方法能够在 ImageNet 分类任务中,稳定地提升各种基于 ViT 的模型的性能。在 ImageNet 上使用 TransMix 进行预训练后,基于 ViT 的模型在语义分割、目标检测和实例分割等任务中,也表现出了更好的迁移能力。此外,在 4 种不同的基准测试中,TransMix 也展现出了更强的鲁棒性。
引言-Introduction
这部分内容主要介绍了研究背景和提出 TransMix 的原因,具体内容如下:
- 研究背景:Transformer 在自然语言处理任务中占据主导地位,基于 Transformer 的架构如 Vision Transformer(ViT)被引入计算机视觉领域,并在图像分类、目标检测和图像分割等任务中展现出巨大潜力。然而,ViT 网络存在难以优化和易过拟合的问题,数据增强和正则化技术可缓解该问题,其中基于 mixup 的方法(如 Mixup 和 CutMix)对泛化 ViT 网络特别有帮助。
- 现有方法问题:Mixup 方法存在局限性,它假设特征向量的线性插值会导致相关目标的线性插值,但并非所有像素对标签的贡献都相同。背景像素与显著区域像素对标签空间的贡献不同,现有一些方法虽意识到此问题并在输入层面进行改进,但这些方法存在不足,如会缩小增强空间、增加参数数量或训练计算量。
- 提出 TransMix:本文聚焦于通过标签分配学习来缩小输入和标签空间的差距,利用 ViT 中自然生成的注意力图,根据注意力图对标签重新加权,而非像传统方法那样按输入混合比例线性插值标签。该方法简单且计算开销小,能有效提升多种任务和模型的性能,在 ImageNet 分类任务中,可显著提升模型的 Top-1 准确率,还能增强模型在下游任务中的迁移能力和鲁棒性。
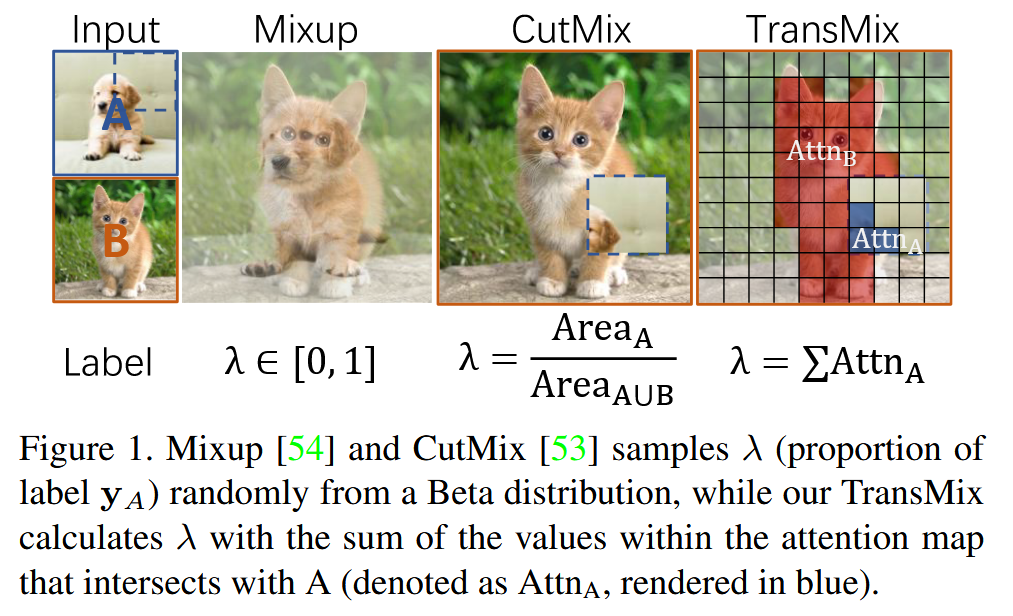
图1. Mixup 和 CutMix 从贝塔分布中随机采样
λ
λ
λ(标签
y
A
y_{A}
yA 的比例),而我们的 TransMix 则通过与 A 相交的注意力图(表示为 Attn
A
_A
A,蓝色部分)内的值之和来计算
λ
λ
λ。
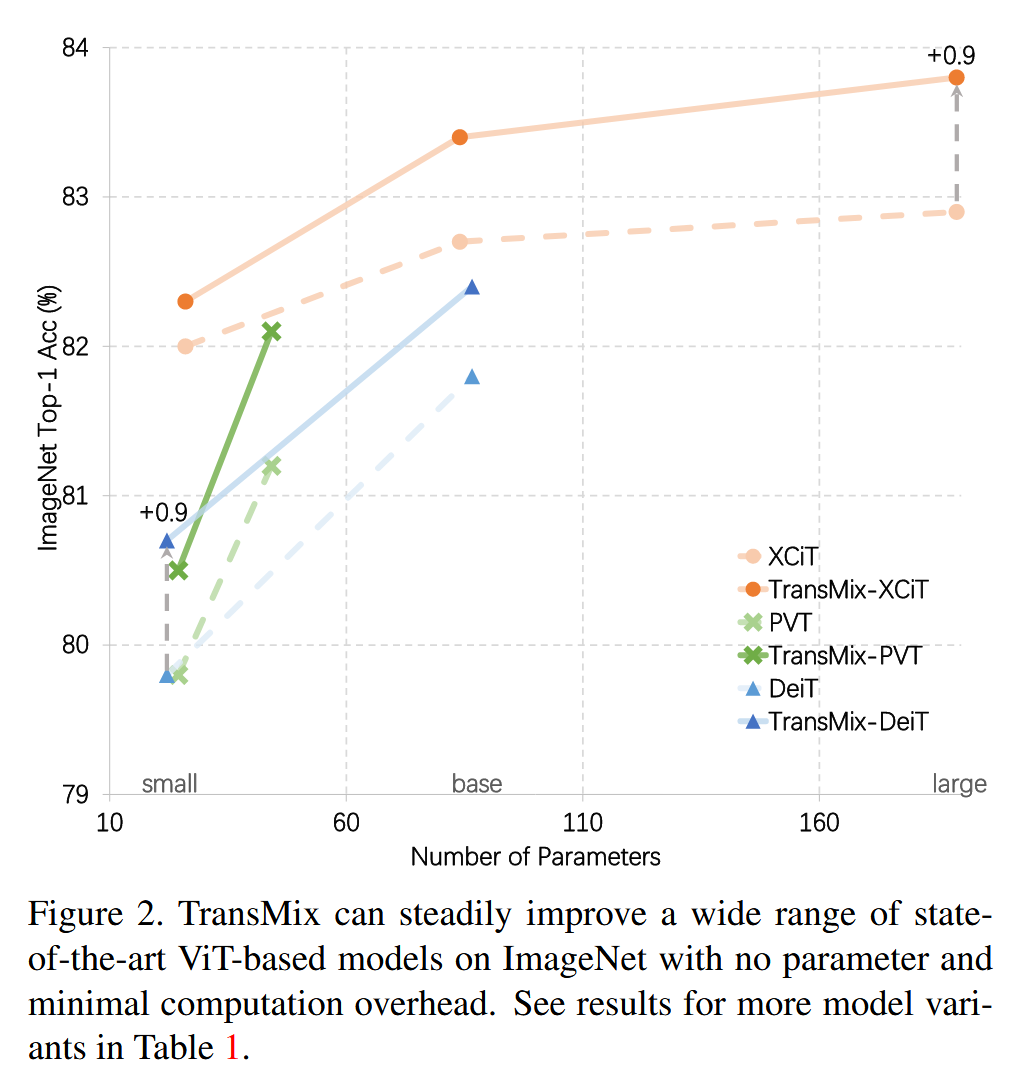
图2. TransMix 能够在不增加参数且计算开销极小的情况下,稳定提升多种基于视觉Transformer(ViT)的前沿模型在 ImageNet 数据集上的性能。更多模型变体的结果见表1。
相关工作-Related Work
这部分内容主要介绍了研究背景和提出 TransMix 的原因,具体内容如下:
- 研究背景:Transformer 在自然语言处理任务中占据主导地位,基于 Transformer 的架构如 Vision Transformer(ViT)被引入计算机视觉领域,并在图像分类、目标检测和图像分割等任务中展现出巨大潜力。然而,ViT 网络存在难以优化和易过拟合的问题,数据增强和正则化技术可缓解该问题,其中基于 mixup 的方法(如 Mixup 和 CutMix)对泛化 ViT 网络特别有帮助。
- 现有方法问题:Mixup 方法存在局限性,它假设特征向量的线性插值会导致相关目标的线性插值,但并非所有像素对标签的贡献都相同。背景像素与显著区域像素对标签空间的贡献不同,现有一些方法虽意识到此问题并在输入层面进行改进,但这些方法存在不足,如会缩小增强空间、增加参数数量或训练计算量。
- 提出 TransMix:本文聚焦于通过标签分配学习来缩小输入和标签空间的差距,利用 ViT 中自然生成的注意力图,根据注意力图对标签重新加权,而非像传统方法那样按输入混合比例线性插值标签。该方法简单且计算开销小,能有效提升多种任务和模型的性能,在ImageNet分类任务中,可显著提升模型的 Top-1 准确率,还能增强模型在下游任务中的迁移能力和鲁棒性。
TransMix
该部分详细介绍了 TransMix 方法,包括其基于的技术背景、具体操作方式以及伪代码实现,具体内容如下:
- Setup and Background:介绍了 CutMix 数据增强和自注意力机制。CutMix 结合两个输入-标签对生成新训练样本,通过随机采样区域替换的方式增强数据,混合标签比例 λ \lambda λ 等于裁剪区域面积比。自注意力机制对输入矩阵进行线性投影得到查询、键和值,计算注意力图并基于此对值进行加权求和得到输出,单头自注意力可扩展为多头自注意力。
- TransMix
- Multi-head Class Attention:ViT 将图像划分为 patch token 并嵌入,通过类 token 聚合全局信息。在 Transformer 有 9 个注意力头和输入 patch 嵌入 z z z 的情况下,使用投影矩阵 w q w_q wq、 w k w_k wk 参数化多头类注意力。类注意力通过类 token 与所有输入 token 计算得到,多个头时对其进行平均以获得最终的注意力图 A A A,且该注意力图可作为最后一个 Transformer 块的中间输出,无需修改架构。
- Mixing labels with the attention map A:遵循 CutMix 中输入混合的过程,利用注意力图 A A A 重新计算 λ \lambda λ(混合标签中 y A y_A yA 的比例)。通过最近邻插值下采样将 CutMix 中的掩码 M M M 转换为与注意力图 A A A 维度匹配,使网络能依据注意力图响应为每个数据点动态重新分配标签权重,注意力图更关注的输入在混合标签中被赋予更高的值。
- Pseudo-code:以类似 PyTorch 的风格给出了 TransMix 的伪代码。在代码中,先对小批量数据进行 CutMix 图像操作,生成掩码
M
M
M 并对图像进行相应替换;接着获取模型的注意力矩阵
A
A
A;然后根据注意力矩阵
A
A
A 和掩码
M
M
M 计算
λ
\lambda
λ,并据此混合标签;最后计算交叉熵损失并进行反向传播,展示了其在即插即用方式下提升性能的简单实现过程。

实验-Experiments
这部分主要通过一系列实验验证了 TransMix 的有效性、可迁移性、鲁棒性、泛化性等特性,并与其他方法进行对比,具体内容如下:
- ImageNet分类:基于 Timm 库,以 DeiT 训练方案为基础,在 ImageNet-1k 数据集上训练和评估多种基线 ViT 模型。结果表明,TransMix 能稳定提升所有模型的 Top-1 准确率,如使 DeiT-S 和 XCiT-L 的 Top-1 准确率均提高 0.9%,且相比模型结构修改,这种基于数据增强的改进效果显著。
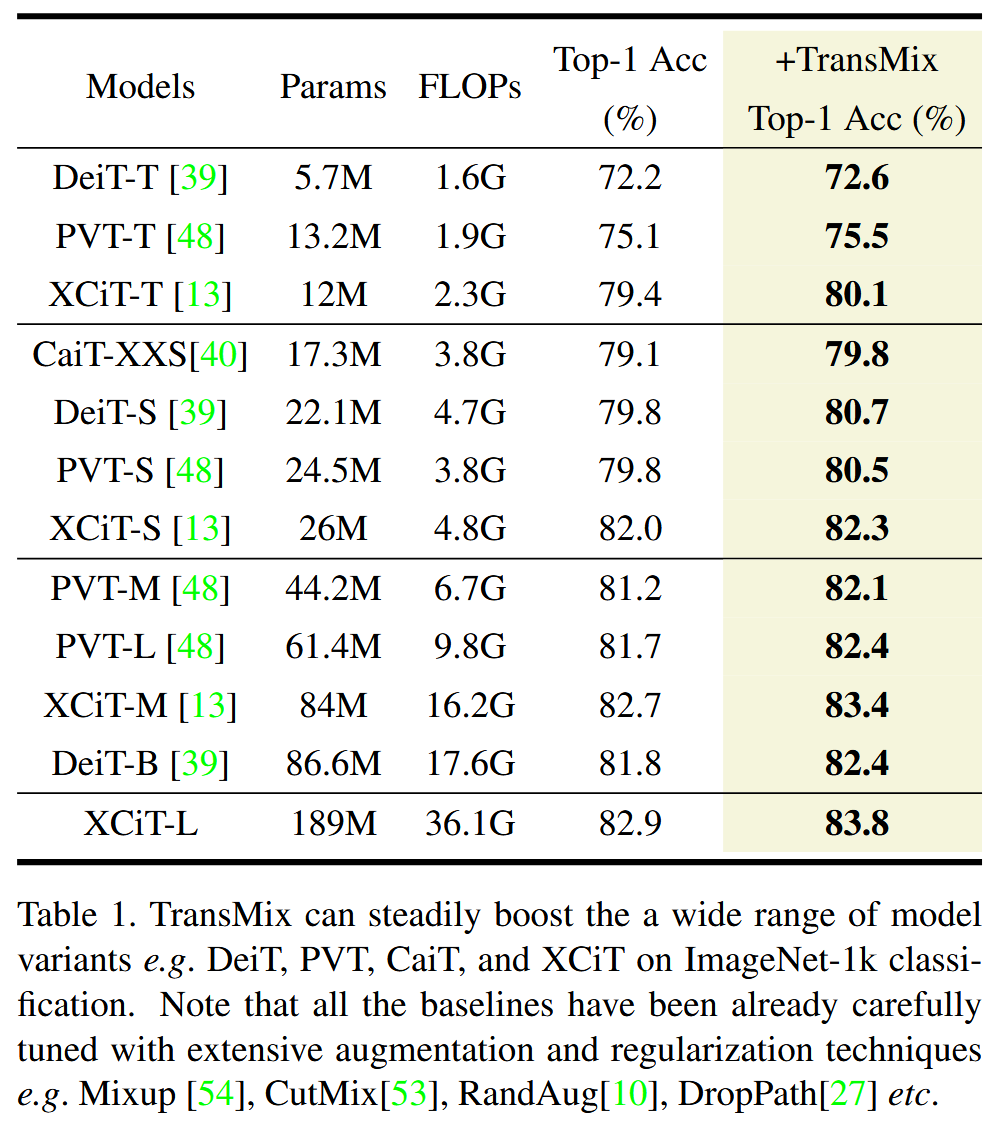
表1. 在 ImageNet-1k 分类任务上,TransMix 能够稳步提升多种模型变体的性能,如DeiT、PVT、CaiT 和 XCiT。请注意,所有基线模型都已经通过广泛的数据增强和正则化技术(如 Mixup、CutMix、RandAug、DropPath 等)进行了精心调整。 - 下游任务迁移:利用在 ImageNet 上预训练的模型权重初始化 Transformer 骨干网络,验证 TransMix 在下游任务中的迁移能力。在语义分割任务(Pascal Context数据集)中,基于 TransMix 预训练的 DeiT-S 模型,使用线性解码器和 Segmenter 解码器时, mIoU 分别提升 0.6% 和 0.9%;在目标检测和实例分割任务(COCO 2017数据集)中,使用 TransMix 预训练骨干网络的 Mask R-CNN 检测器,box AP 提升 0.5%,mask AP 提升 0.6%。

表2. TransMix 对基于 Pascal Context 数据集的下游语义分割任务迁移的无额外开销影响。(MS)表示多尺度测试。
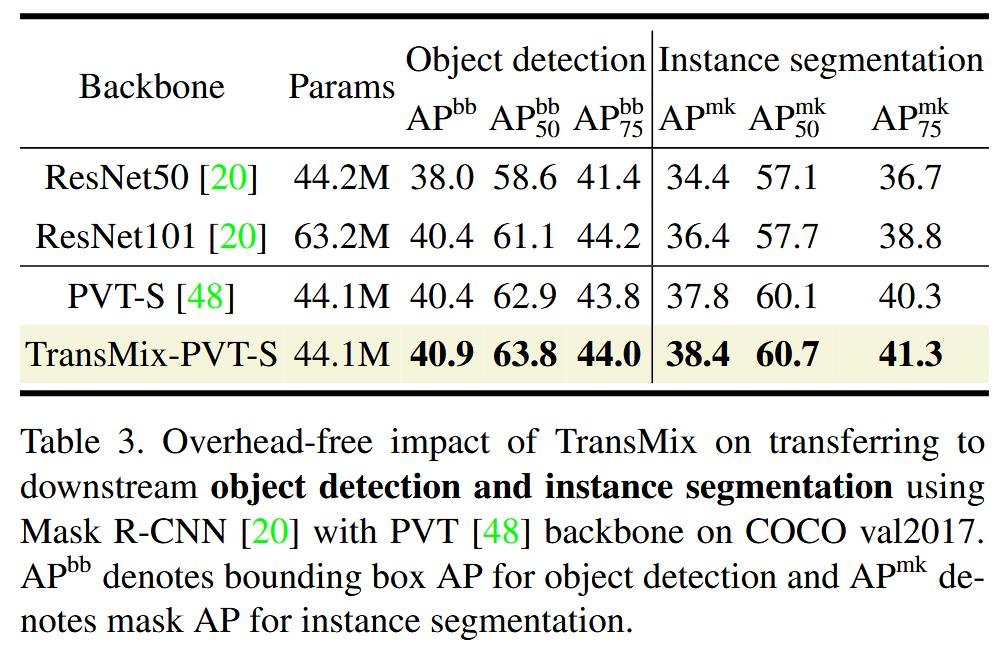
表3. 在 COCO 2017 验证集上,使用基于 PVT 骨干网络的 Mask R-CNN 进行下游目标检测和实例分割任务时,TransMix 的无额外开销影响。 A P b b AP^{bb} APbb 表示目标检测的边界框平均精度均值(Average Precision,AP),AP m k ^{mk} mk 表示实例分割的掩码AP。 - 鲁棒性分析:在四种场景下评估 TransMix 预训练模型的鲁棒性。在遮挡场景中,DeiT-S with TransMix 在不同遮挡设置下,尤其是极端遮挡时表现更优;对空间结构打乱的敏感度实验中,TransMix-DeiT-S 平均准确率比 DeiT-S 高4.2%;在自然对抗样本任务中,TransMix 训练的 DeiT-S 在多项指标上优于普通 DeiT-S;在分布外检测任务中,TransMix 训练的 DeiT-S 的 AUPR 比普通 DeiT-S 高1%。
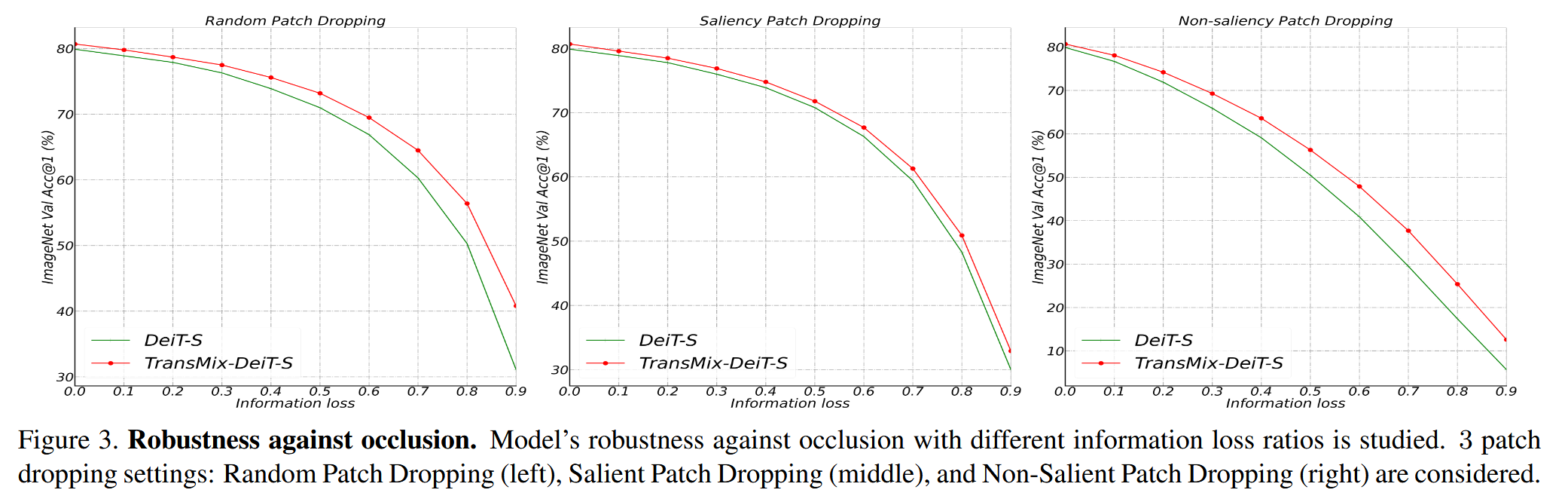
图3. 抗遮挡鲁棒性。研究了模型在不同信息丢失率下的抗遮挡鲁棒性。考虑了3种 patch 丢弃设置:随机 patch 丢弃(左)、显著 patch 丢弃(中)和非显著 patch 丢弃(右)。
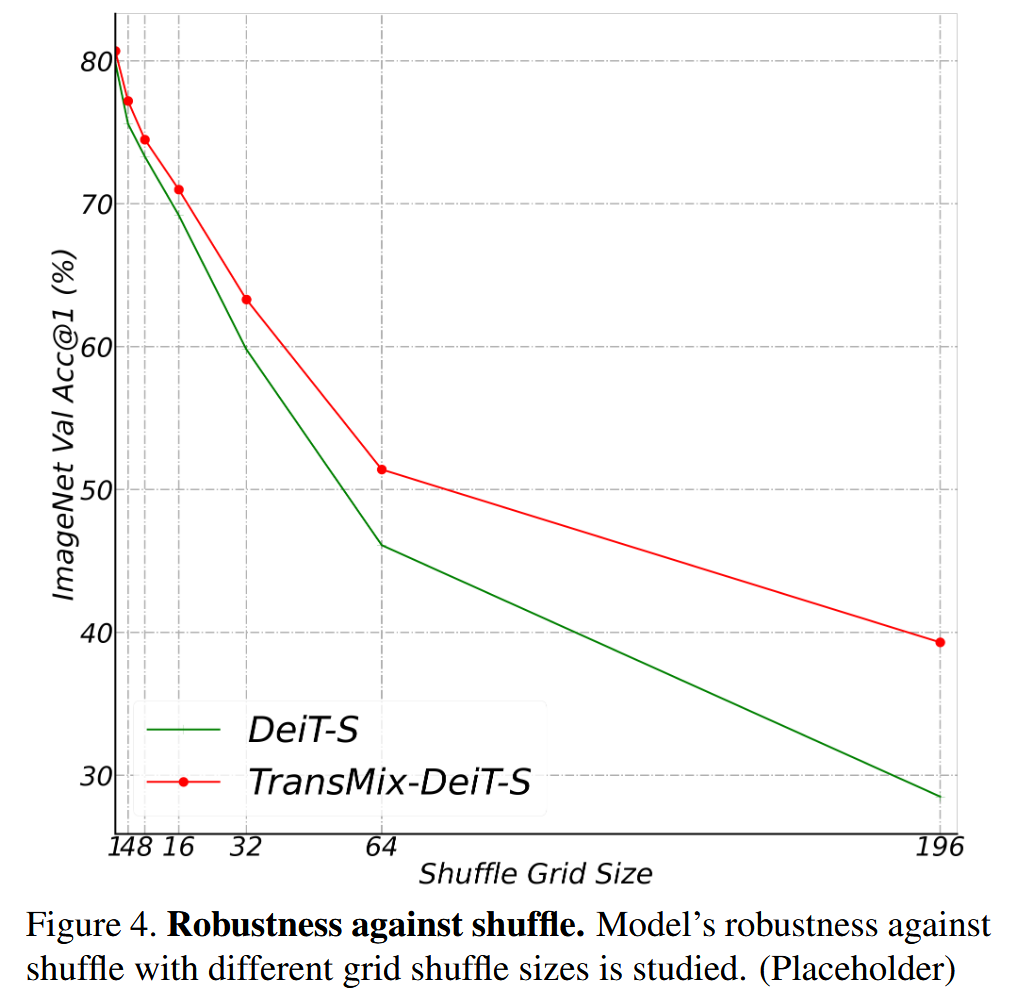
图4. 抗打乱鲁棒性。研究了模型在不同网格打乱大小下的抗打乱鲁棒性。
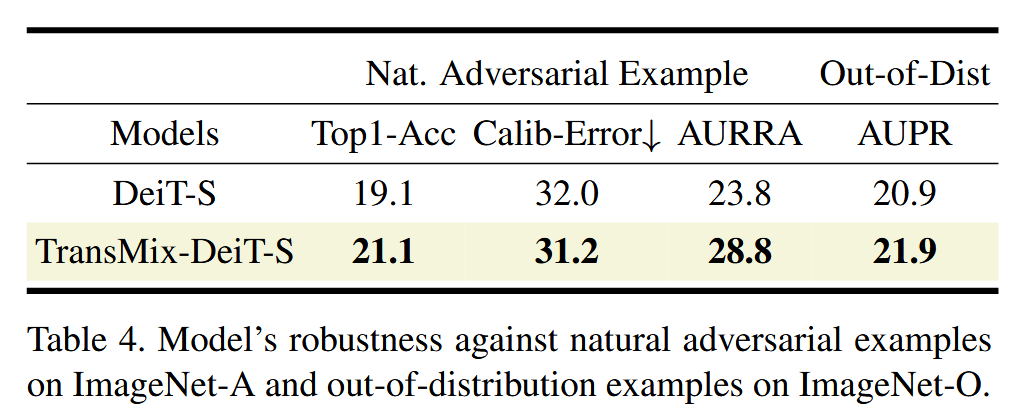
表4. 模型在 ImageNet-A 上对抗自然对抗样本以及在 ImageNet-O 上对抗分布外样本的鲁棒性。 - TransMix 与注意力的相互作用:评估发现 TransMix 有助于提升注意力图质量,在弱监督自动分割和弱监督目标定位任务中,TransMix-DeiT-S 生成的注意力掩码与真实情况匹配度更高。但实验结果表明,更好的注意力图不一定能促进 TransMix,使用外部参数冻结模型生成的注意力图替代原注意力图时,模型性能没有提升,这体现了 TransMix 的动态特性。

表5. 注意力图的定量评估。分割 JI 表示在 Pascal VOC 上进行弱监督分割的杰卡德指数,定位 mIoU 表示在 ImageNet1k 上进行弱监督目标定位的边界框平均交并比。

表6. 使用外部(参数冻结)模型生成注意力图,以替代 TransMix 中使用的原始注意力图 A。 - 泛化性研究:为将 TransMix 应用于无 class token 的 Swin Transformer,开发了 CA-Swin。在ImageNet-1k上的实验显示,TransMix-CA-Swin-T 的 Top-1 验证准确率比 Swin-T 高 0.5%,证明了 TransMix 的泛化性。
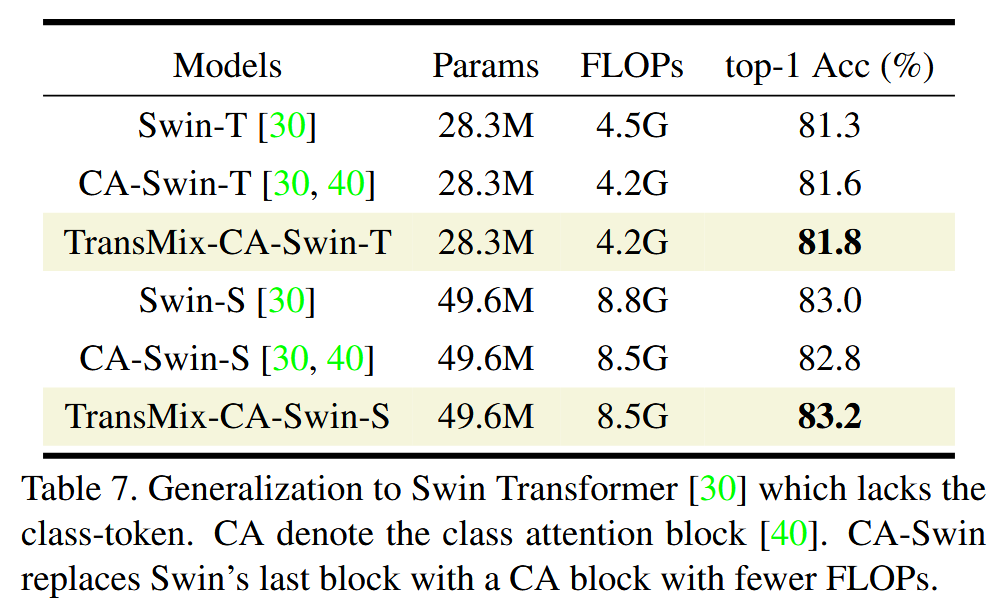
表7. 对缺少 class token 的 Swin Transformer 的泛化研究。CA表示类注意力模块。CA-Swin 用一个计算量更少的 CA 模块替换了 Swin 的最后一个模块。 - 与最先进的 Mixup 变体比较:在 ImageNet-1k 上与多种 Mixup 变体进行全面比较,结果表明 TransMix 在 Top-1 准确率上显著优于其他方法,训练速度最快且无参数增加。相比之下,基于显著性的方法在视觉 Transformer 上无优势,如 Attentive-CutMix 存在时间和参数开销,Puzzle-Mix 训练速度最慢。此外,对 TransMix 进行消融研究,结果表明默认设置最佳,并提供了可视化结果展示其对标签分配的改进 。
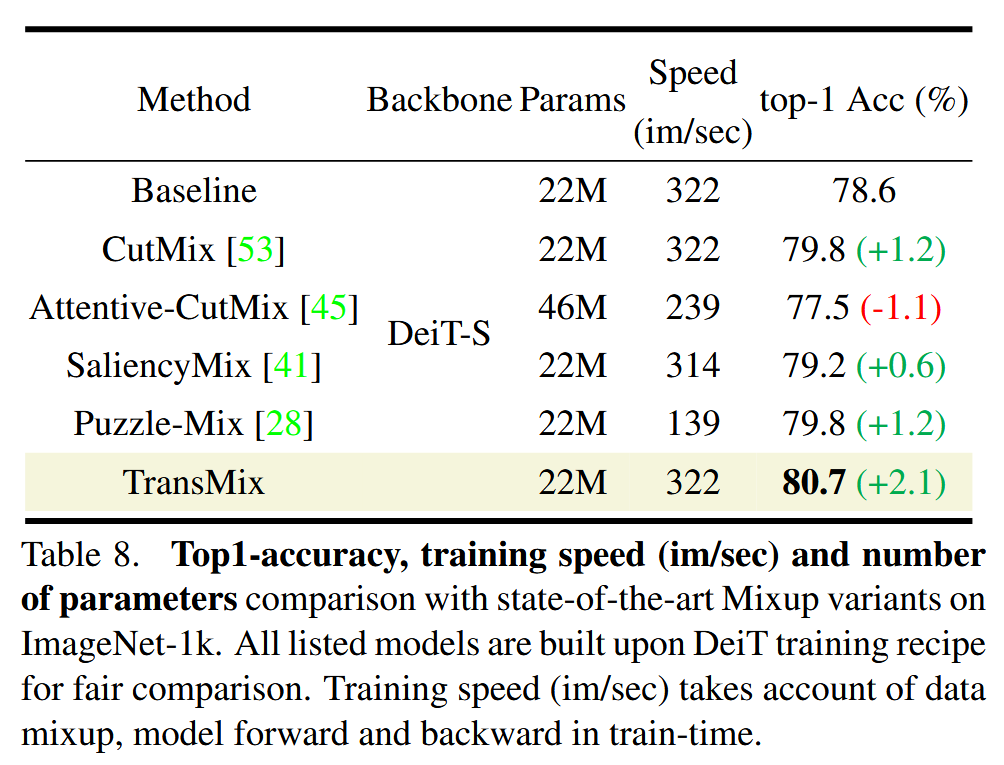
表8. 在 ImageNet-1k 上,TransMix 与最先进的 Mixup 变体在 Top1 准确率、训练速度(图像/秒)和参数数量方面的比较。所有列出的模型均基于 DeiT 训练方案构建,以确保比较的公平性。训练速度(图像/秒)考虑了训练时的数据混合、模型前向和反向传播。

图5. 可视化内容包括图像 A、图像 B、混合图像、输入混合图像时从 XCiT-L 获取的注意力图,以及相应的标签分配。标签分配同时包含旧的面积比分配方式和新的 TransMix 分配方式。
结论-Conclusion
这部分内容总结了 TransMix 的优势、局限性,并列出了研究的致谢与参考文献,具体内容如下:
- 研究成果总结:提出 TransMix,这是一种简单有效的数据增强技术,基于注意力指导为视觉 Transformer 分配 Mixup 标签。该方法利用 Transformer 的注意力图为混合目标分配置信度,在 ImageNet 分类任务上,能使 DeiT-S 和大型变体 XCiT-L 的 Top-1 准确率均提升 0.9%。通过在 10 个基准测试上进行广泛实验,验证了 TransMix 在有效性、可迁移性、鲁棒性和泛化性方面的优势。
- 研究局限性分析:一是依赖类注意力,对于没有 class token 的骨干网络处理效果不佳,虽然通过修改架构(如开发 CA-Swin)可在一定程度上缓解,但仍存在局限;二是注意力图需与输入在空间上对齐,与基于变形的 Transformer(如 PS-ViT、DeformDETR)兼容性较差,不过可通过利用变形偏移网格校准注意力图与输入空间位置来潜在解决这一问题。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











