







HTTP协议
文章目录
认识HTTP协议
HTTP协议全称是超文本传输协议,是应用层协议,作用是将客户端/服务器应用层数据打包,当服务器/客户端接收到应用层数据包之后可以正确的解析出来。
文本就是文件中不只有文本,还可以通过超链接的方式获取到其他页面中的信息,或者图片,视频,音频等资源。
HTTP协议是一个一问一答通信模式的协议
客户端和服务器之间的通信的几种方式:
1️⃣一问一答:一个请求返回一个响应
2️⃣一问多答:一个请求返回多个响应
3️⃣多问一答:多个请求返回一个响应
4️⃣多问多答:多个请求返回多个响应
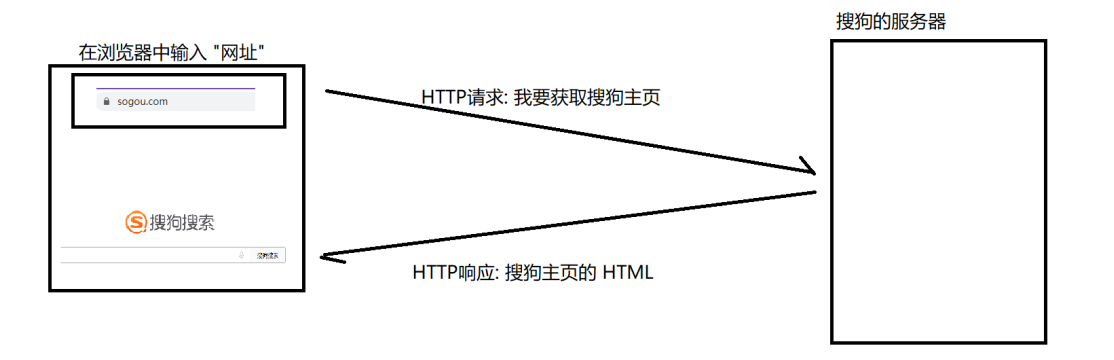
当在浏览器中输入一个网址,或者点击网页上的一个链接,浏览器就会根据应用层协议(比如HTTP协议)先对请求进行打包,然后经网络层传输层等封装,经网络传输给服务器,然后服务器再一级一级分用,最后服务器进程拿到HTTP数据报,对报文解析,根据解析结果返回一个响应。响应可以是HTML页面,图片,视频,等各种资源。
理解应用层协议
我们之前学过网络层的TCP/UDP协议和传输层的IP协议,这两层协议分别通过端口号和IP地址,主要控制的是数据能从客户端进程经过网络正确无误的传输到服务器端进程,但是并不是直接把客户端的请求直接交给网络层来打包,而是把单纯的请求和响应通过应用层协议打包一层,打包其实就是组织数据,那所以应用层协议确定的是应用层数据的组织格式。
只有当客户端和服务器都使用同一个格式来组织数据,当双方拿到数据后,才能正确的解析出数据。
应用层协议不关系数据如何传输,只关心应用双方如何组织数据。
而HTTP协议就属于应用层协议中的一种。
抓包工具
我们通过抓包工具就可以获取到经过我们电脑的HTTP请求和HTTP响应(也就是一个HTTP报文),拿到一个HTTP报文,就可以看到HTTP协议具体是怎么组织应用层数据的。
使用开发者工具
使用开发者工具可以看到当前浏览器发出的请求以及接收到的响应。
Fiddler
使用Fiddler工具就可以获取到HTTP请求和响应。
Fiddler为啥可以获取到请求和响应呢?原因是Fiddler是一个代理:
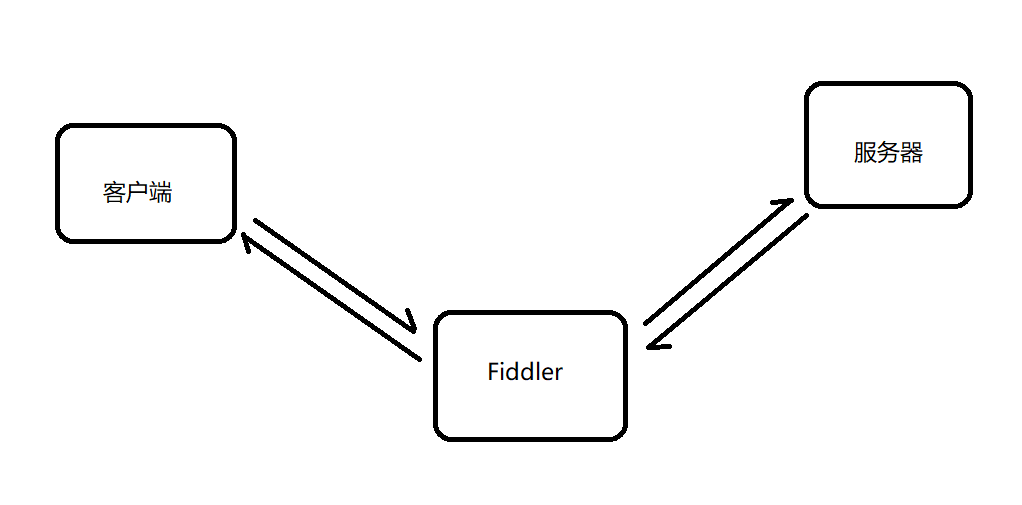
每次的请求和响应都要经过Fiddler中转,所以Fiddler可以获取到请求和响应。
比如看看教务系统的登录请求和及对应的响应,使用Fiddler抓包一下,获取到的结果:
请求:
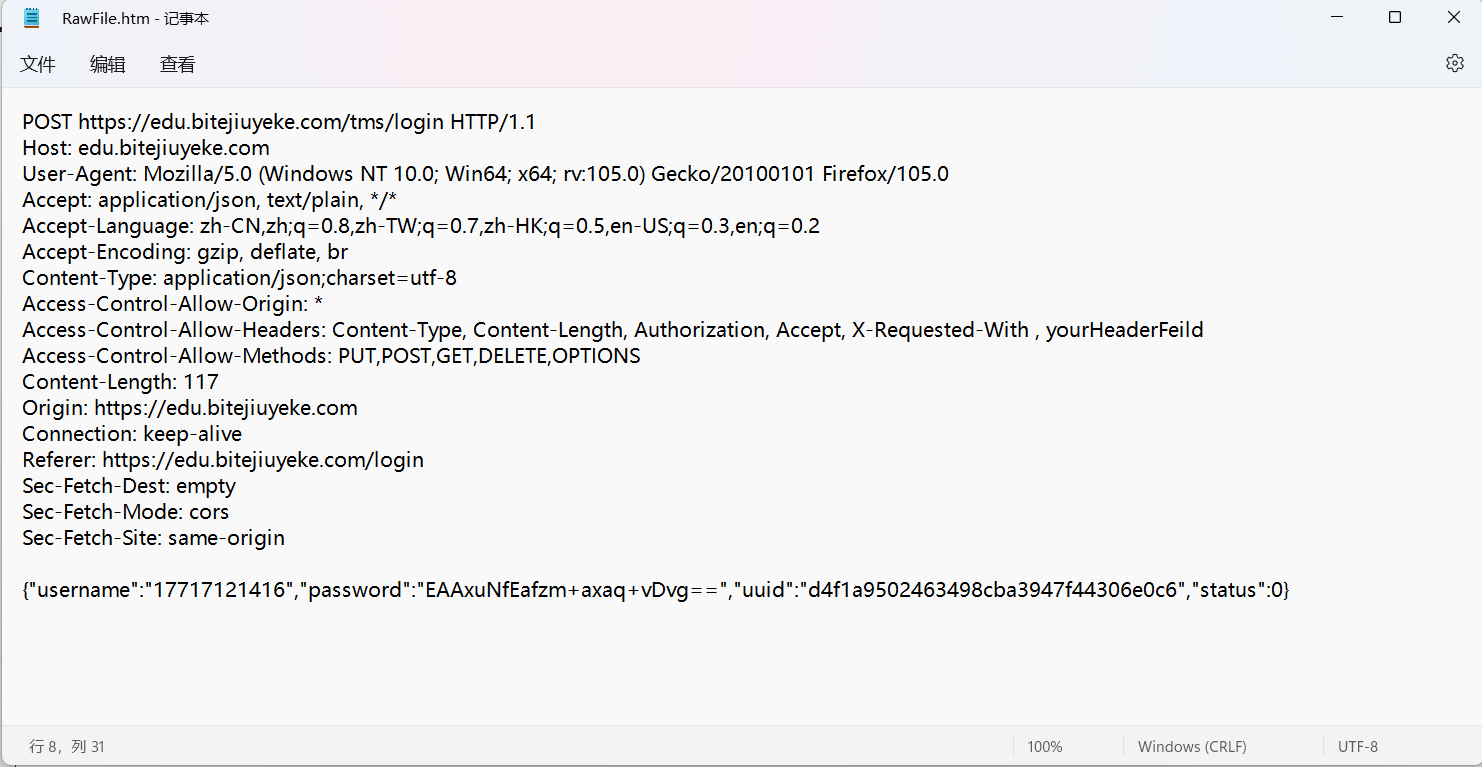
✅这里显示的就是最原始的http请求, 可以看到当使用记事本打开,可以看到具体信息,不是乱码,也就是http请求是文本数据,不是二进制数据。
HTTP协议其实是个文本协议,而TCP,UDP,IP则是二进制协议,以二进制的格式来组织数据,所以如果直接把TCP的数据报用记事本打开,就会是乱码。
响应:
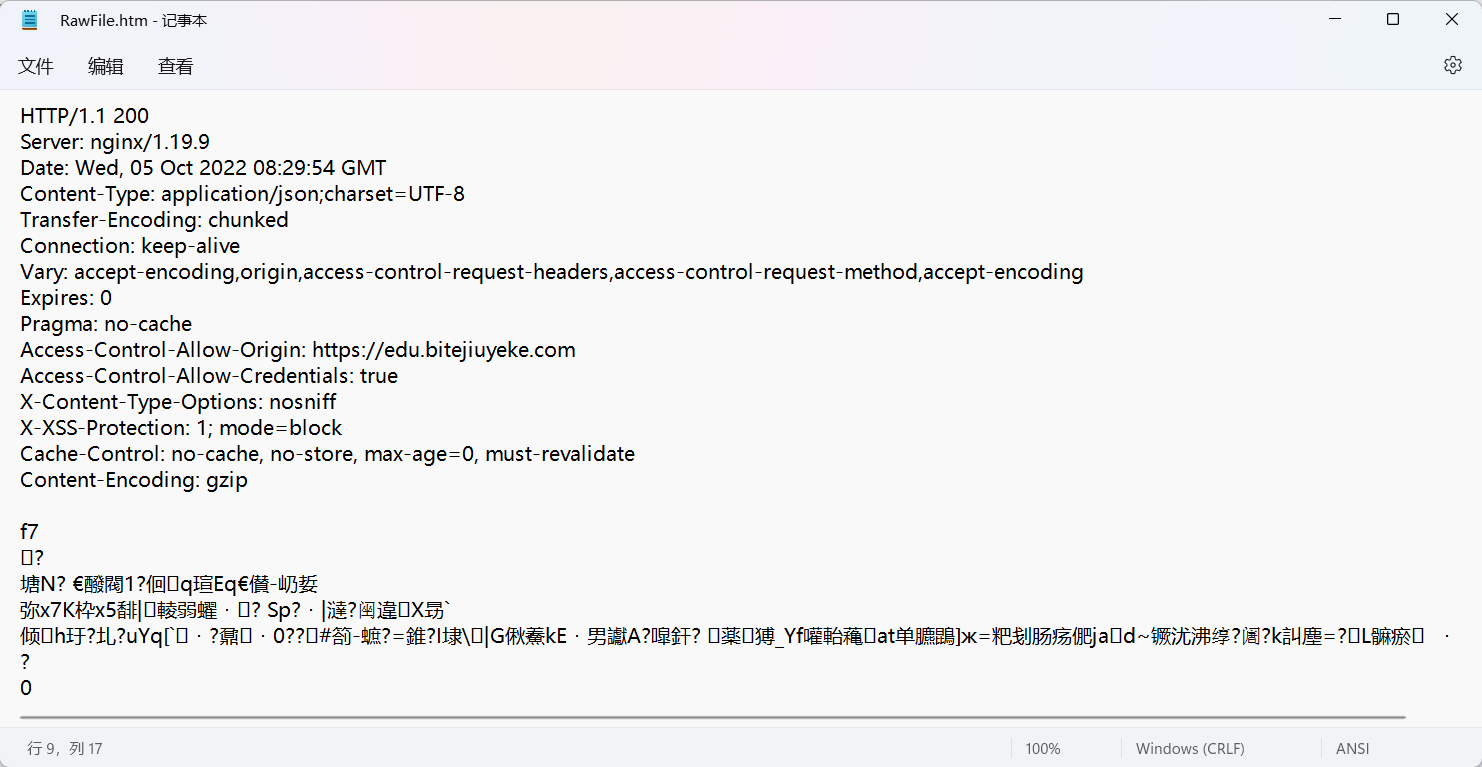
✅这个是上面的请求对应的响应。但是最下面出现了乱码,并不是因为这是二进制数据,而是因为这部分内容是压缩过的,可以看到乱码上一行:Content-Encoding: gzip(说明数据压缩过的,以gzip格式压缩),压缩是为了减小数据报大小,尽量降低网路带宽的占用,提高传输效率。
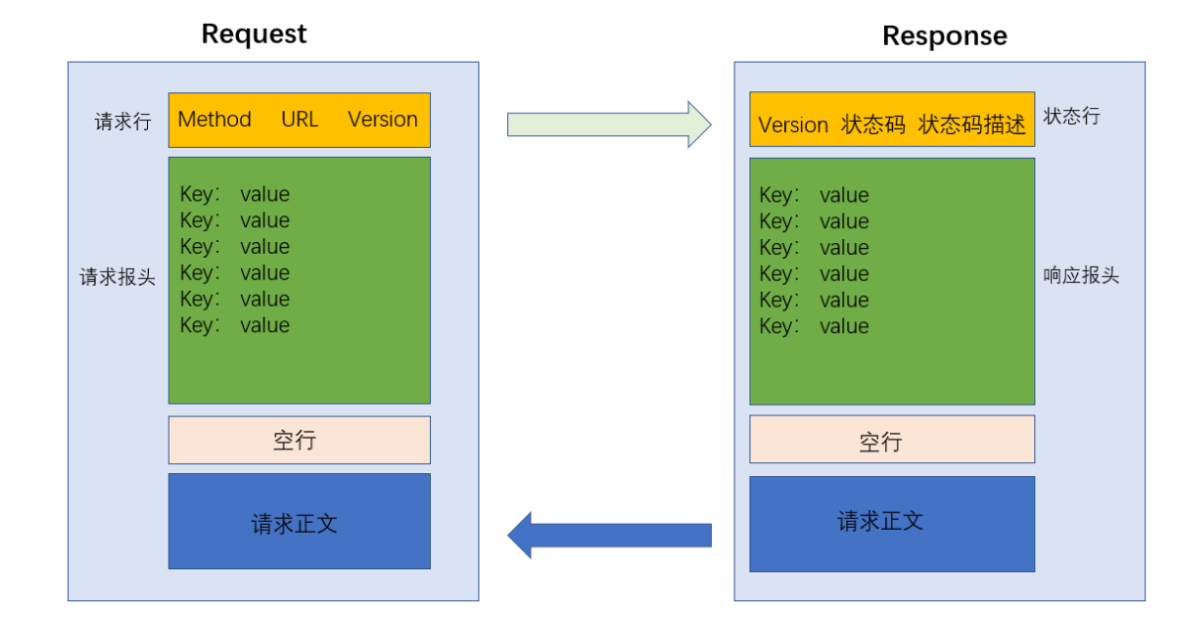
HTTP报文格式
HTTP请求:
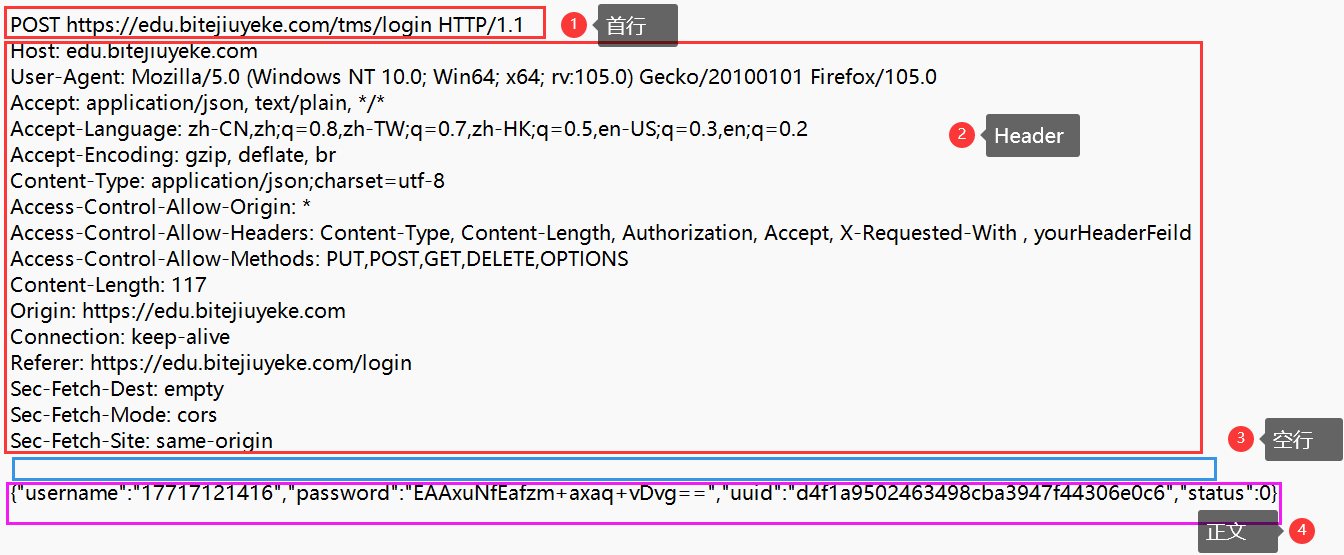
以上面获取到的这个HTTP请求为例:
1️⃣首行:
POST https://edu.bitejiuyeke.com/tms/login HTTP/1.1
总共有三部分内容:HTTP方法 + URL+ HTTP版本号
方法代表本次请求要干什么,URL代表要访问的资源,HTTP版本号代表当前使用的HTTP协议的版本。
2️⃣Header:这里面就是一些属性,以键值对来表示,每一行是一个键值对。
3️⃣空行:这是Header的结束标志,因为每次的请求Header有多少行是不固定的,所以用空行来作为结束标志。
4️⃣请求正文(body):正文以JSON格式来组织数据,并不是所有的请求都有正文。可以看到登录时的用户名和密码就是在body部分。
HTTP响应:
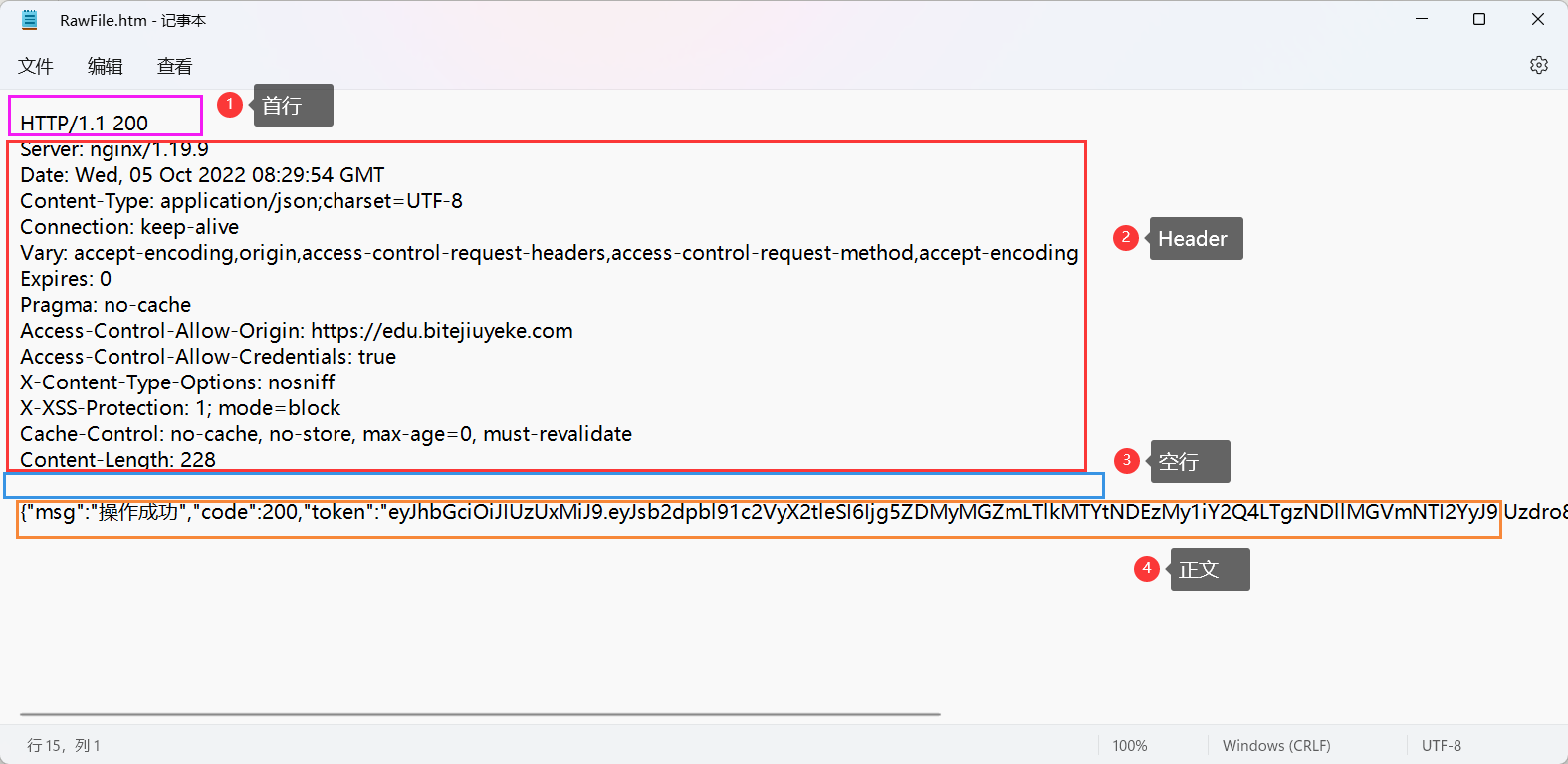
这个是教务系统登录的响应:
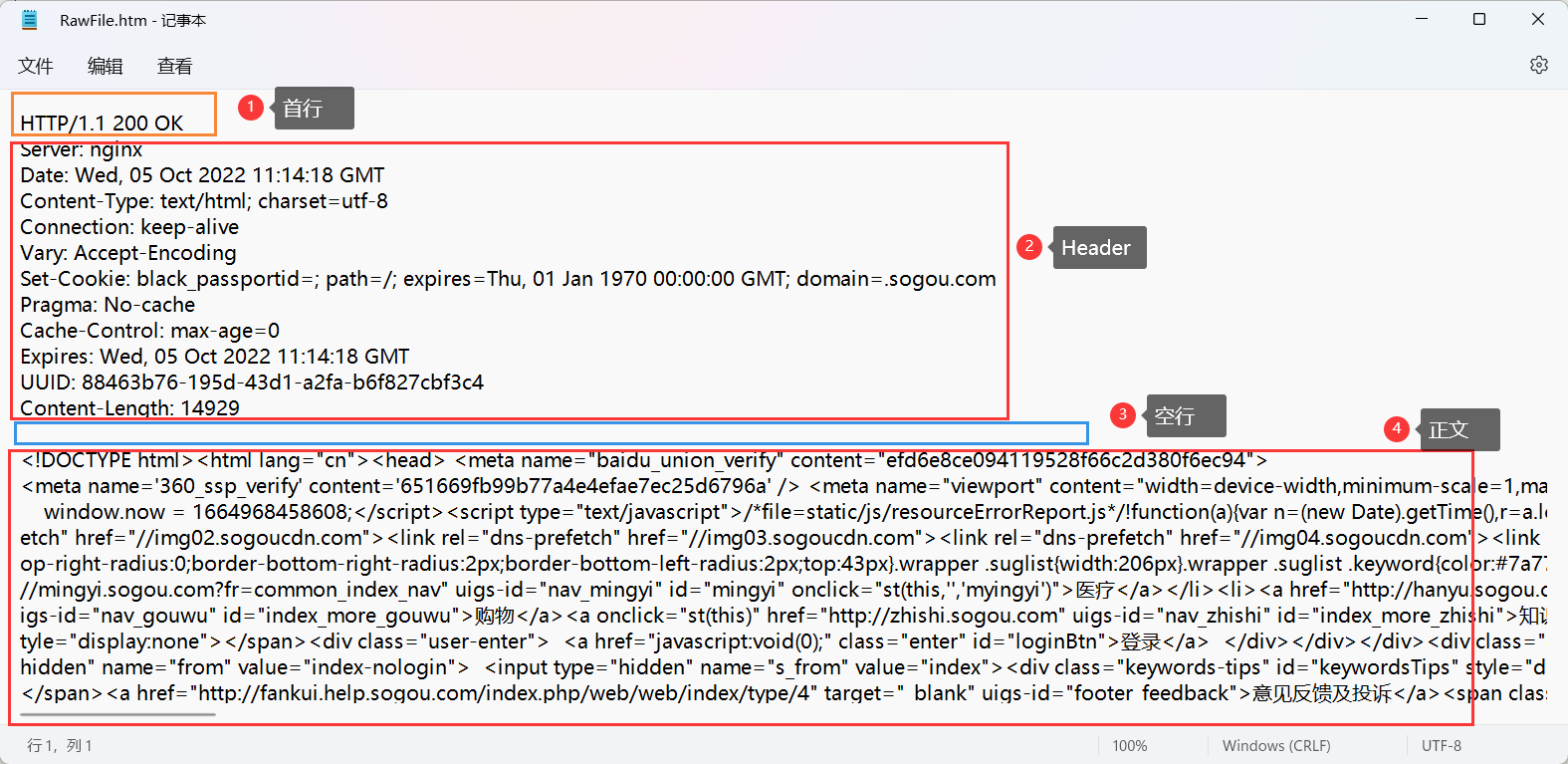
这个是访问搜狗主页的响应:
同样是四个部分组成:
1️⃣首行:HTTP版本号+状态码+状态码的描述(但是教务系统登录的响应好像没有这个描述)
2️⃣响应报头(Header):键值对,每行是一个键值对
3️⃣空行:响应报头的结束标志
4️⃣响应正文:可以是html,图片等
URL
认识URL
认识HTTP请求首行的URL:
URL:唯一资源定位符,用于定位一个资源在网络上的位置,俗称网址
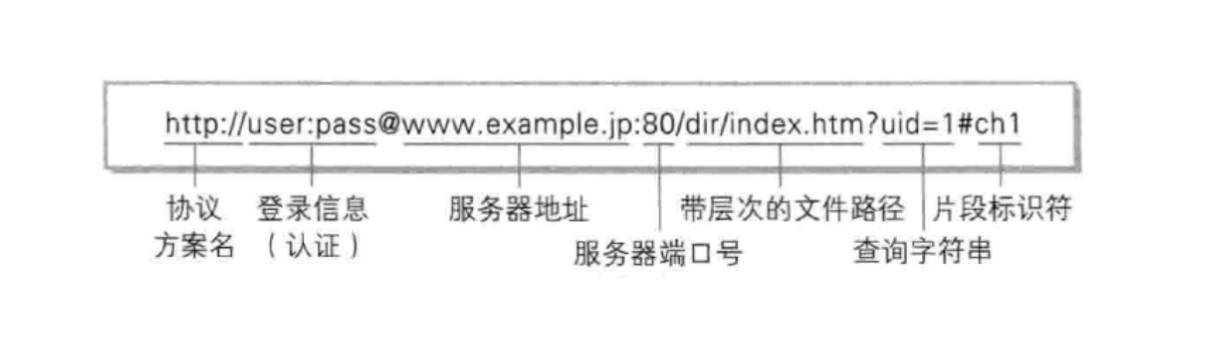
一个完整的URL由这几部分组成:
1️⃣协议名:代表这个URL给谁用的,URL不仅可以给HTTP使用,也可以给其他协议使用
2️⃣登录信息:这个信息现在的URL基本没有了,不再使用了
3️⃣服务器地址,代表了这个资源存于哪个服务器,这里的是域名,并没有用真正的IP地址。DNS会把这个域名解析成IP地址
4️⃣服务器端口号:代表了具体访问的是服务器的哪个进程,如果URL里没有端口号,浏览器会根据协议给一个默认值,http协议默认值:80,https协议默认值:443。所以如果服务器用的是其他端口号,那URL中的端口号也得随之改变。
5️⃣带层次的文件路径:比如说百度或搜狗的服务器应用程序就管理了很多资源(很多html页面),那具体访问的是哪个资源,由文件路径决定。
6️⃣查询字符串:请求中带的参数,服务器根据查询字符串中的参数就知道具体返回什么内容。查询字符串以?符号作为起始标志,后面是查询字符串的本体,本体中就是一些键值对,键值对之间以&符号分隔。查询字符串的具体内容是程序员自己决定的。
7️⃣片段标识符:用于在页面内实现跳转,跳转到当前页面的某个章节。比如代码随想录中的:
https://programmercarl.com/0704.%E4%BA%8C%E5%88%86%E6%9F%A5%E6%89%BE.html#%E6%80%9D%E8%B7%AF
这个URL最后就有个#符号作为起始位置的字符串,这个就是片段标识符,前面的从https: 到.html都是当前页面,然后加上后面的#%E6%80%9D%E8%B7%AF(这就是一个片段标识符),在地址栏输入这个URL然后回车,就能跳转到这个页面的片段标识符的这个位置。所以用这个片段标识符,就可以给这个页面构成一个目录。然后实现当前页面内的跳转。
URL encode
在URL中有些字符已经有既定的含义了,所以如果在URL中需要带有这种字符,需要对字符转义
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 288
288











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









