






JVM
文章目录
java代码执行流程
我们写好的java代码(.java文件)首先需要被编译为字节码文件(.class文件),然后由JVM中的类加载器将字节码文件加载到内存中的运行时数据区,而字节码文件是JVM的一套规范指令,并不能直接交由CPU执行,需要先将字节码文件编译为底层系统指令,再交由CPU执行,(这个编译过程由特定的命令解析器执行引擎来完成),而这个过程需要调用其他语言的接口,本地接口库来完成。
JVM主要通过以上的四个部分来执行java程序的。
类加载器;运行时数据区;执行引擎;本地接口库
运行时数据区
运行时数据区主要分为以下几个部分:
1️⃣栈
2️⃣堆
3️⃣程序计数器
4️⃣方法区
栈
栈其实分为两部分:java虚拟机栈,本地方法栈,这两个部分现在已经合并了
java虚拟机栈是给Java代码使用的区域,本地方法栈是给JVM内部的c++代码使用的区域(也就是哪些native关键字修饰的方法)
栈中存储的最关键的数据:方法调用关系,局部变量,这两者都在函数栈桢中,其实每个方法在执行的同时都会在栈中创建一个与该方法对应的函数栈桢,函数栈桢中存储局部变量表,操作栈,动态连接,方法返回地址等信息,
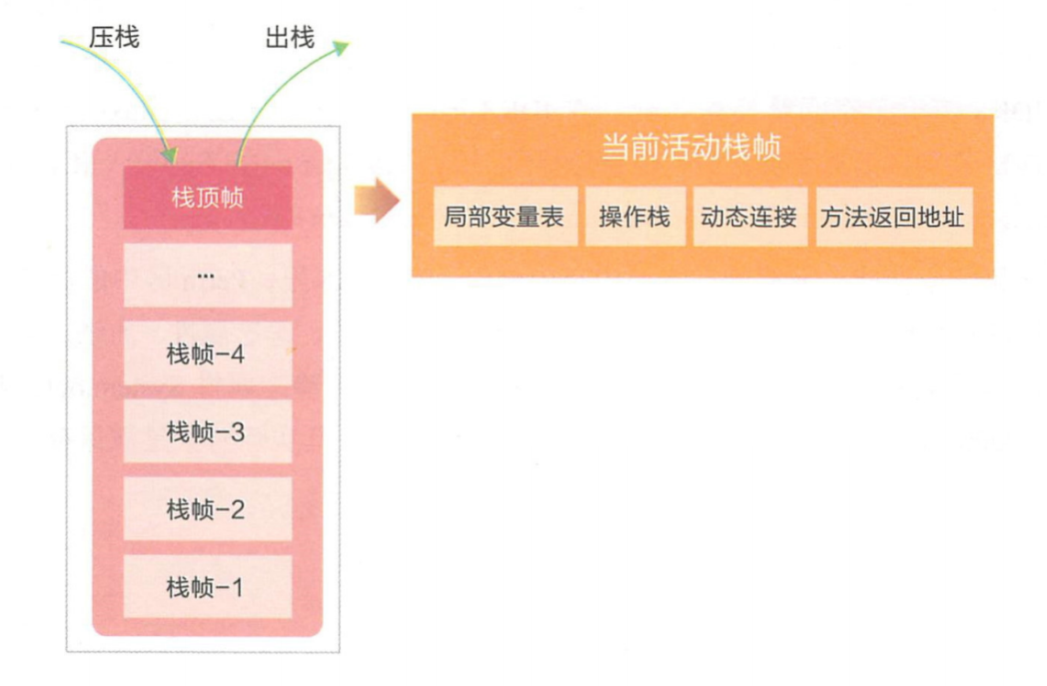
方法中的局部变量就是存在栈桢中的,也即是存在栈这个区域中的
堆
堆是java进程的内存中最大的一块区域,new出来的对象就是存放在堆中的,所以类中的实例成员变量就是在堆上的
方法区
方法区中有代码和静态变量
当.java文件被编译为.class文件后,JVM会加载.class文件到内存中构造出类对象,类对象包括的数据有:类的名字,继承自谁,实现了啥接口,有哪些属性,属性名,属性类型,属性访问权限,方法名,方法参数,返回值,方法访问权限,以及方法内部的指令。方法中的具体信息是在方法区中的,方法之间的调用关系是在栈中的。
静态成员变量也是在方法区中的。
程序计数器
程序计数器是占地最小的区域,存的是要执行的下一条指令的地址。
java代码是被加载到内存中的(类对象中),既然到了内存中,类对象中的每个指令都有自己的地址,程序计数器就存储了下一个要执行的指令的地址。
程序计数器也和线程调度有关,线程并不是完全执行完,而是在CPU上执行一会,休息一会,休息一会后从哪个指令接着执行呢,就得看程序计数器中存的是哪个指令了。
在每个java进程中,堆和方法区只有一份,而栈和程序计数器每个线程都有自己独立的一份,因为每个线程是一个独立的执行流,都得记录自己执行到哪个指令了,以及自己的方法调用关系。
类加载机制
类加载:编译生成的.class文件,是在硬盘中的,类加载就是把.class文件读到内存中,并构造出类对象。
类加载过程:
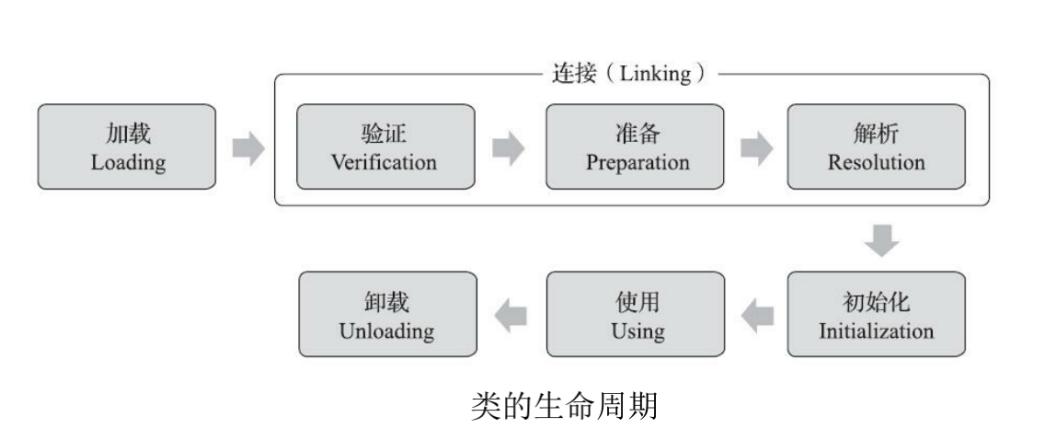
类加载过程主要有三个步骤:加载,连接,初始化。
==加载:==找到.class文件,打开文件,读取文件,在内存中创建空的类对象
链接:
- 验证:检查.class问价是否符合规范要求
- 准备:给静态变量分配内存空间,空间里填成0
- 解析:把字符串常量进行初始化,把符号引用替换成直接引用
==初始化:==针对类的静态成员进行初始化,执行静态代码块;如果这个类的父类还没加载,也要加载父类
双亲委派模型
双亲委派模型是类加载阶段的第一步,描述的是去哪些目录下加载文件
在JVM执行流程中提到,是类加载器负责把字节码文件加载到内存中,JVM中自带了三个类加载器:
BootStrapClassLoader:负责加载标准库中的类
ExtensionClassLoader:负责加载一些扩展的类
ApplicationClassLoader:负责加载自己写的类
在JVM中给这三个类加载器约定了一个父子关系,从上到下,依次是爷爷,父亲,儿子
双亲委派模型就是在这个体系下,展开的规则
比如要加载一个类,java.lang.String(标准库中的类),那JVM中会先调用儿子类去加载这个String类,但是儿子类不会先在自己的目录中找这个String类,而是先让父亲类去在目录中找这个类,而父亲也不找,而是让爷爷先找,爷爷一找,找到了String这个类,就结束了,父亲和儿子就不用找了
也就是要加载一个类,先让爷爷找,爷爷在自己的目录中没找到这个类,再让父亲找,父亲没找到再让儿子找,都没找到就会抛出ClassNotFoundException。这个过程就是双亲委派模型
GC垃圾回收机制
垃圾回收机制是回收内存中不会再使用的空间。比如之前C语言中malloc()函数开辟的内存,不用了必须free()释放掉,不然就会永久占用内存空间,直到程序结束,这就叫做内存泄漏。
但是在java中不用手动释放内存,因为JVM有垃圾回收机制,那垃圾回收机制主要回收内存中的哪些空间呢?
-
程序计数器:这个空间每个线程只有一个,随线程销毁而销毁,不需要GC回收
-
栈:这里主要存的是局部变量,局部变量出了作用域直接回收,也不需要GC
-
方法区:这里存的是类对象,主要是类加载,把数据加载到内存中,很少会涉及到类卸载,所以需要GC,但是也不迫切
-
堆:这里是GC的主战场,new出来的对象如果不用了,GC就会自动释放掉对象所占用的空间
所以GC主要释放的是堆中的空间,并且以对象为单位释放,而不是以字节为单位。只有等一个对象完全不被使用了才会被释放。
引用计数
那如何判断一个对象是否是垃圾呢?
有以下两种方法:
1️⃣可达性分析
2️⃣引用计数
先看引用计数的方法:
引入一个计数器来表示当前有多少个引用引用了这个对象。
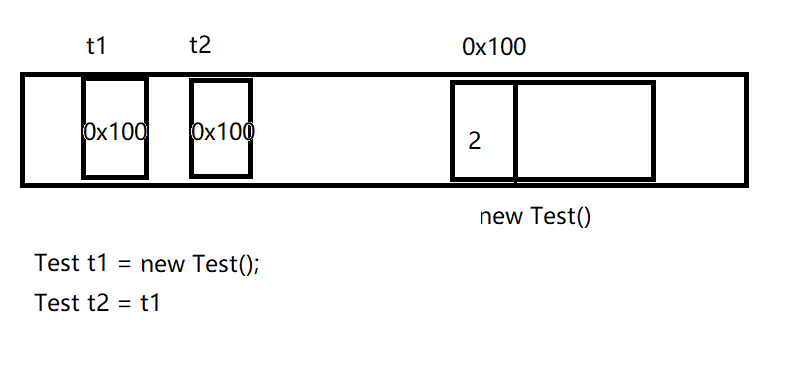
比如当前有两个引用引用了这个对象,那这个对象中的计数器中就是2。如果销毁引用t1,那计数器就更新为1,如果没有引用引用这个对象了,计数器就是0,那这时这个对象就可以判为垃圾,就可以回收掉。
这个方案可以解决问题,但是有缺陷:
- 多线程环境下,同时修改计数器,需要考虑线程安全问题
- 如果对象比较大,那还好,空间开销相对来说小点;如果对象比较小,再引入一个计数器,那就相当于空间开销相对来说比较大。
- 可能会带来循环引用问题,导致垃圾没法被回收
class Test{
Test next = null;
}
Test t1 = new Test();
Test t2 = new Test();
t1.next = t2;
t2.next = t1;
t1 = null;
t2 = null;
这样就会导致对象内部变量互相引用,但是没有外部对象互相引用,按理来说该被回收了,但是由于内部互相引用,计数不为0,没法回收,导致产生内存泄漏
可达性分析
在JVM中并没有采取引用计数的方法,采取的是可达性分析的方法。
可达性分析:从一些特殊变量出发,看看哪些对象能被访问到,哪些对象不能被访问到,不能被访问到的对象就是不可达。那就要回收该对象。
能被访问到就类似于一颗二叉树,从根节点出发,可以到达的节点就代表能访问到。假如A节点(根节点)的左孩子是B节点,然后A.left=null; 此时B就没法被访问到了,那B就要被回收
特殊对象包括:
- 栈中函数栈桢中的局部变量表中的引用(包括所有线程的栈中的所有函数栈桢中的局部变量表中的所有引用变量)
- 常量池中的变量
- 方法区中的静态引用类型成员
垃圾回收算法
标记-清除
先通过可达性分析,明确哪些对象时垃圾,然后把该对象做个标记,代表该对象所占用的空间可以被后续使用。当创建新对象时,就可以在被标记的空间上占用。
缺点:这种方式是把内存释放了,但是释放的空间不连续,会产生内存碎片,导致后续创建对象时如果对象比较大,这些碎片空间无法使用(因为对象空间是连续的),这样内存空间的利用率就降低了。
复制算法
为了解决内存碎片问题,引入复制算法:
把堆空间一分为二,先使用其中一半空间,然后垃圾回收器可达性分析找到垃圾,但是并不直接释放,而是将不是垃圾的对象拷贝到另一半空间,将这第一半空间全部释放。
这种方式不会产生内存碎片,但是可用空间少了一半,并且拷贝对象比较耗时。
标记-整理
标记整理是先找到垃圾对象,但是并不直接释放,而是移动有用的对象占用垃圾对象的空间
这样不会产生内存碎片,而且空间利用率不会降低
但是拷贝移动对象还是比较费时的。
分代回收
上述三种算法缺陷比较大,不能适用所有场景。
分代回收是综合了上述算法,这是JVM实际采用的算法,把上述方案综合一下,扬长避短。
首先给对象引入一个年龄:年龄是对象被GC扫描的轮次。当对象刚创建出来,还没经过GC扫描,年龄是0,经过一轮GC,年龄变为1。以后每经过一轮GC,年龄+1。根据年龄的大小,把对象分为两大类:新生代(年龄小的对象),老年代(年龄大的对象)。把这两类对象放到不用的内存区域中,使用不同的回收算法。但是至于多大年龄才是老年代,这个得看GC的实现,不同的GC这里的年龄界限不同。
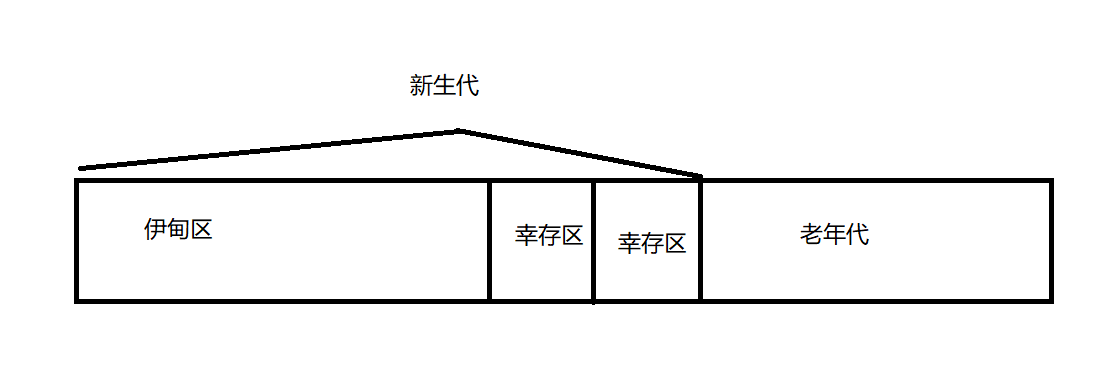
- 新创建的对象放到伊甸区
- 伊甸区的大部分对象都活不过一轮GC,称为朝生夕死。活过一轮GC的对象被移动到幸存区。从伊甸区到幸存区的这个过程相当于复制算法。由于在伊甸区中经过一轮GC存活的对象比较少,所以幸存区也不需要太大。
- 处于幸存区中的对象也不是就平安无事了,还是要经过GC,GC之后幸存的对象,会使用复制算法把对象移到另一个幸存区中。然后再一轮GC,淘汰一波对象,剩下的对象就会复制到另一个幸存区,就这样循环往复。
- 当对象在幸存区经过多轮GC,年龄比较大了,可以认为这个对象一时半会变不了垃圾,然后就使用复制算法把这个对象拷贝到老年代。
- 处于老年代的对象,也要经过GC,但是GC的频率会降低,因为认为处于老年代的对象一时半会变不了垃圾。当处于老年代的对象经GC视为垃圾后,会使用标记-整理算法清除垃圾对象。因为老年代中的GC频率较低,而且对象数量也只是一部分,所以标记-整理的时间开销就可以接受。
上述过程就是分代回收的过程。
还有一个例外:就是如果一个对象比较大,就直接放到老年代,不放到新生代。因为大对象在新生代中的复制算法中来回复制开销比较大。















 22万+
22万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









