







这篇文章主要介绍了python爬虫开发之使用Python爬虫库requests多线程抓取猫眼电影TOP100实例,需要的朋友可以参考下
使用Python爬虫库requests多线程抓取猫眼电影TOP100思路:
查看网页源代码
抓取单页内容
正则表达式提取信息
猫眼TOP100所有信息写入文件
多线程抓取
运行平台:windows
Python版本:Python 3.7.
IDE:Sublime Text
浏览器:Chrome浏览器
1.查看猫眼电影TOP100网页原代码
按F12查看网页源代码发现每一个电影的信息都在“
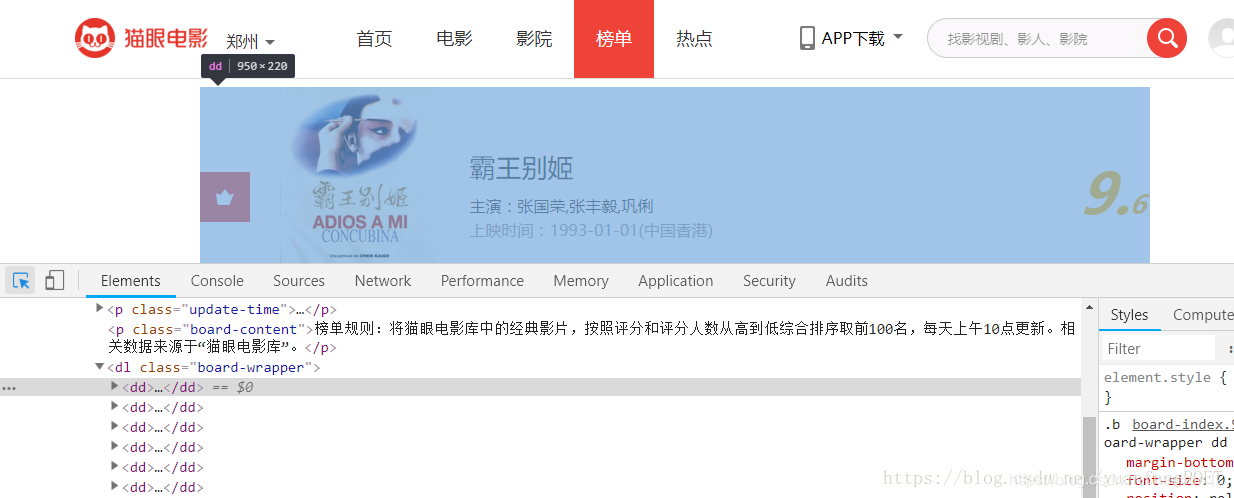
点开之后,信息如下:
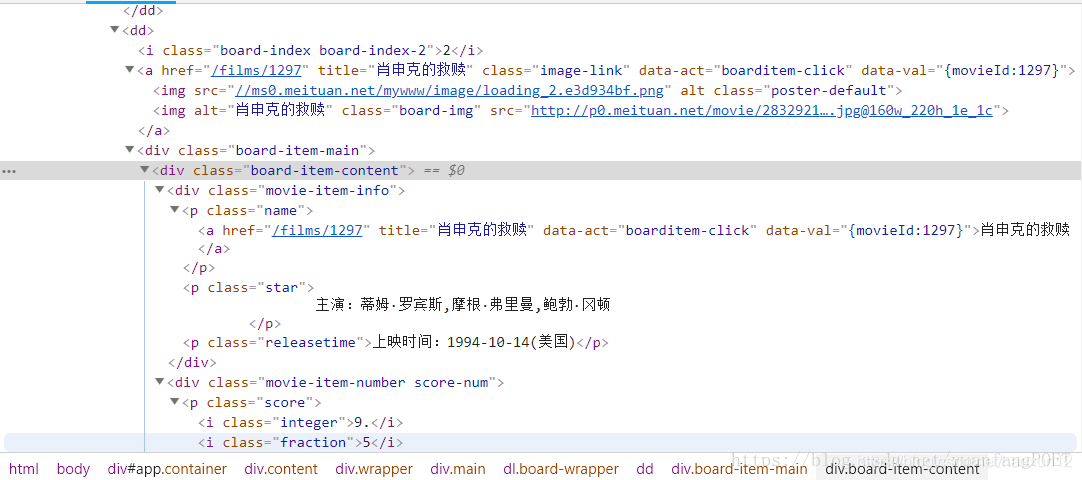
2.抓取单页内容
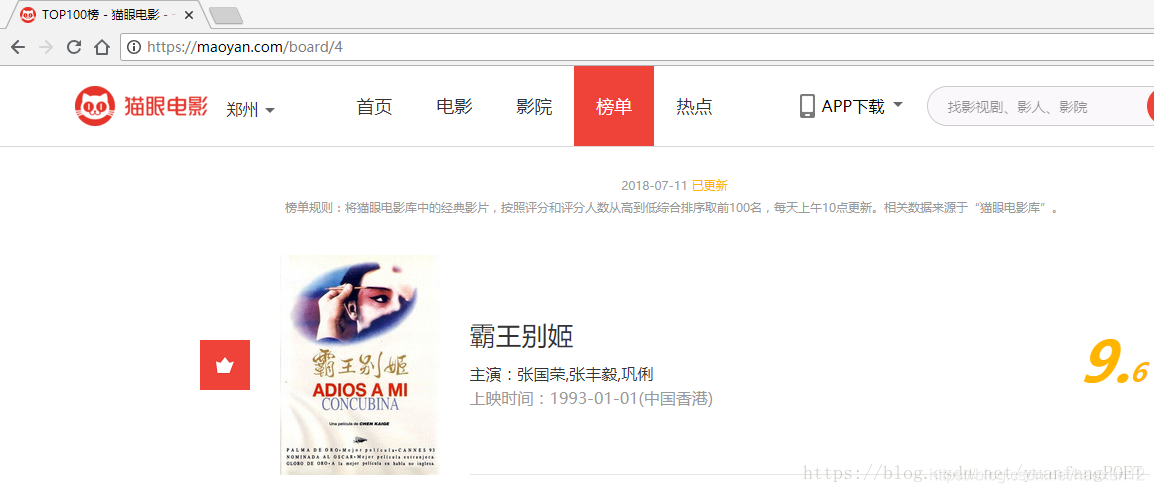
在浏览器中打开猫眼电影网站,点击“榜单”,再点击“TOP100榜”如下图:
接下来通过以下代码获取网页源代码:
#-*-coding:utf-8-*-
import requests
from requests.exceptions import RequestException
#猫眼电影网站有反爬虫措施,设置headers后可以爬取
headers = {
'Content-Type': 'text/plain; charset=UTF-8',
'Origin':'https://maoyan.com',
'Referer':'https://maoyan.com/board/4',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
#爬取网页源代码
def get_one_page(url,headers):
try:
response =requests.get(url,headers =headers)
if response.status_code == 200:
return response.text
return None
except RequestsException:
return None
def main():
url = "https://maoyan.com/board/4"
html = get_one_page(url,headers)
print(html)
if __name__ == '__main__':
main()
执行结果如下: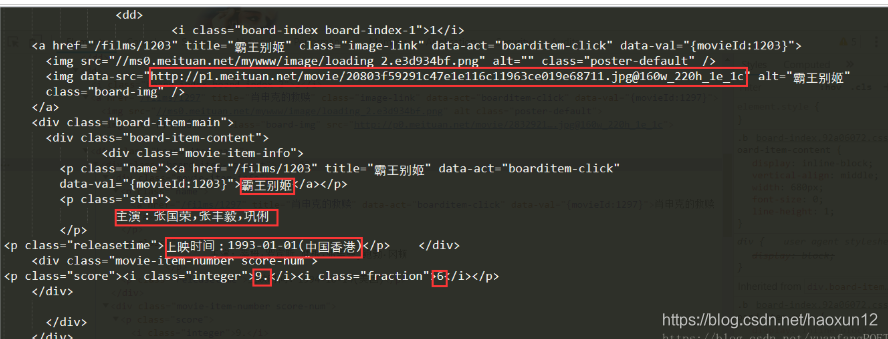
3.正则表达式提取信息
上图标示信息即为要提取的信息,代码实现如下:
#-*-coding:utf-8-*-
import requests
import re
from requests.exceptions import RequestException
#猫眼电影网站有反爬虫措施,设置headers后可以爬取
headers = {
'Content-Type': 'text/plain; charset=UTF-8',
'Origin':'https://maoyan.com',
'Referer':'https://maoyan.com/board/4',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
#爬取网页源代码
def get_one_page(url,headers):
try:
response =requests.get(url,headers  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 582
582











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









