









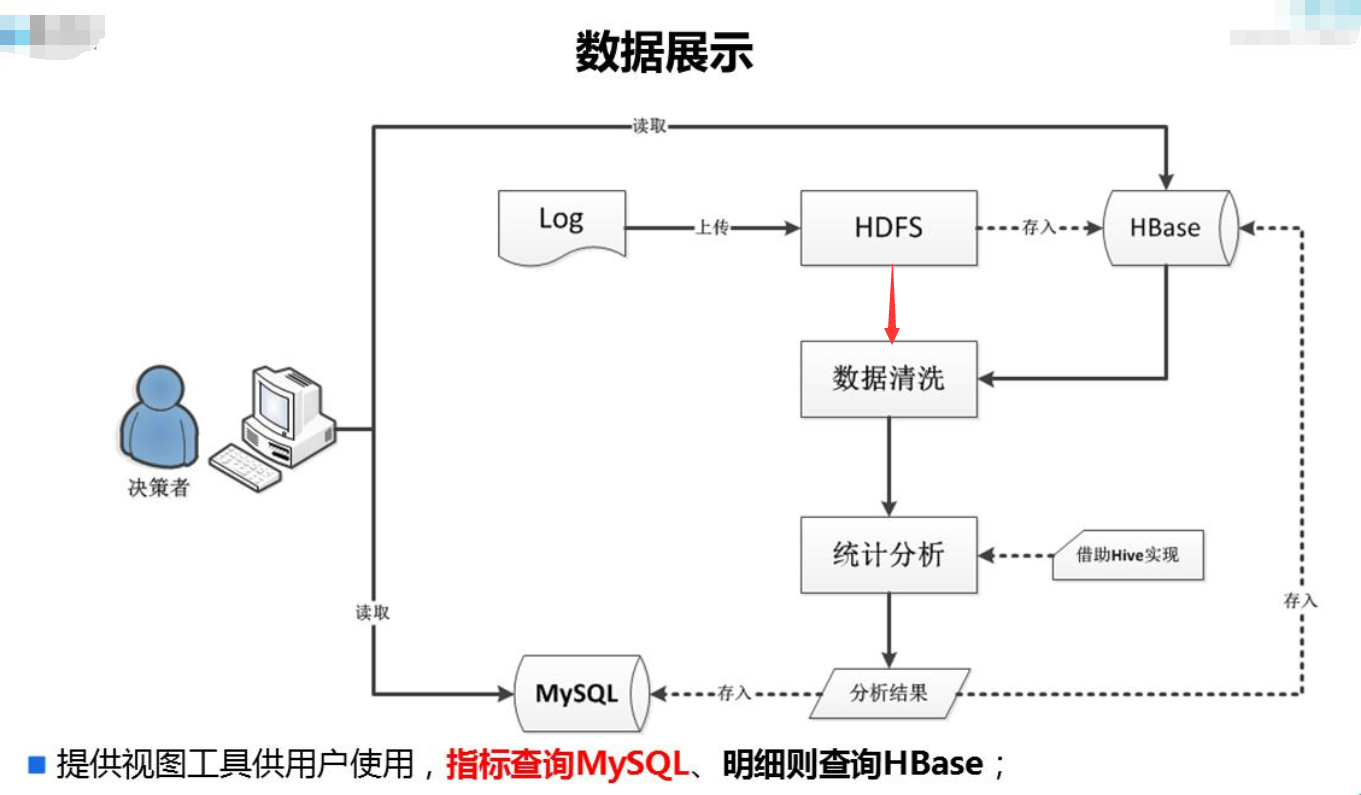
数据分析流程
- 上传文件
- 把日志数据上传到HDFS中进行处理,可以分为以下几种情况:
- 如果是日志服务器数据较小、压力较小,可以直接使用shell命令把数据上传到HDFS中;
- 如果是日志服务器数据较大、压力较大,使用NFS在另一台服务器上上传数据;
- 如果日志服务器非常多、数据量大,使用flume进行数据处理;
- 把日志数据上传到HDFS中进行处理,可以分为以下几种情况:
- 数据清洗
- 使用Mapreduce对HDFS中的原始数据进行清洗,以便后续进行统计分析;
- 统计分析
- 使用Hive对清洗后的数据进行统计分析;
- 导出结果
- 使用Sqoop把Hive产生的统计结果导出到MySQL中;



数据样式
27.19.74.143 - - [30/Oct/2016:17:38:20 +0800] “GET /static/image/common/faq.gif HTTP/1.1” 200 1127
上述的数据实际上对应的是【七个】字段,每个字段之间使用【space】分割的。前期工作
- 在根目录下专门创建一个文件夹由于存放脚本:mkdir weblogs
创建:vi log_case.sh - 创建数据目录[beifeng@hadoop-senior01 /]$ sudo mkdir -p datas/weblogs
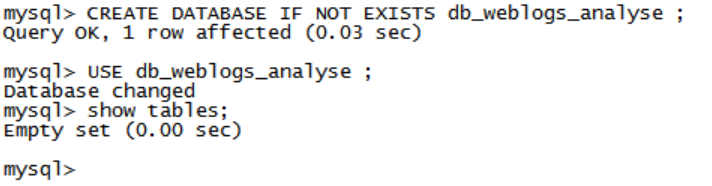
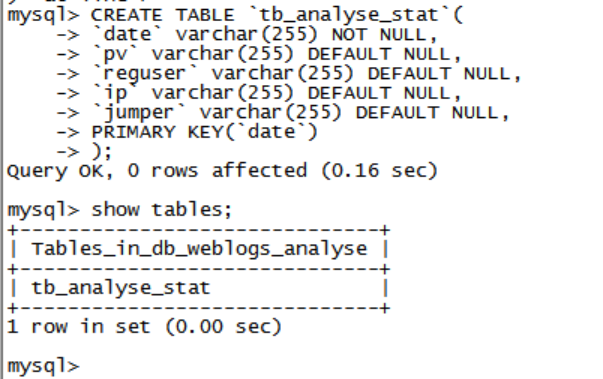
赋予权限:chmod u+x access_2016-11-27.log - MySQL需要创建相应的数据库与表:
mysql创建数据库
mysql创建表
- 在根目录下专门创建一个文件夹由于存放脚本:mkdir weblogs
log_case.sh解析
0. 基础配置
#!/bin/sh
#SYSTEM ENVIRONMENT VARIABLE
. /etc/profile
#get the yesterday date
yesterday=`date -d -1days '+%Y-%m-%d'`
echo "------ yesterday is ${yesterday} ------"
## HADOOP_HOME
HADOOP_HOME=/opt/cdh-5.3.6/hadoop-2.5.0-cdh5.3.6
## HIVE_HOME
HIVE_HOME=/opt/cdh-5.3.6/hive-0.13.1-cdh5.3.6
## SQOOP_HOME
SQOOP_HOME=/opt/cdh-5.3.6/sqoop-1.4.5-cdh5.3.6
WEBLOG_DIR=/datas/weblogs
## access_2016-11-19.log
DAILY_FILE=access_${yesterday}.log
UPLOAD_HDFS_DIR=/user/hive/weblogs/src/${yesterday}
LOCAL_JAR_PATH=/home/beifeng/weblogs/weblogs-clean.jar
MAIN_CLASS= com.beifeng.bigdata.LogCleanMapReduce
CLEANED_OUTPUT_DIR=/user/hive/weblogs/cleaned/date=${yesterday}
SQL_SCRIPTS_DIR=/home/beifeng/weblogs
1. 加载数据到HDFS上
#1.DELETE UPLOAD DIR Date IF EXISTE >/dev/null 2>&1 错误输出到标准输出
${HADOOP_HOME}/bin/hdfs dfs -rm -R ${UPLOAD_HDFS_DIR} >/dev/null 2>&1
#2.CREATE UPLOAD DIR
${HADOOP_HOME}/bin/hdfs dfs -mkdir -p ${UPLOAD_HDFS_DIR}
#3.PUT THE DATA FILE TO HDFS
${HADOOP_HOME}/bin/hdfs dfs -put ${WEBLOG_DIR}/${DAILY_FILE} ${UPLOAD_HDFS_DIR}
echo " THE FILE [${DAILY_FILE}] IS PUT TO [${UPLOAD_HDFS_DIR}]"
2. 清洗数据
#1.DELETE MAPPEDUCE OUTPUT DIR IF EXISTE >/dev/null 2>&1 错误输出到标准输出
${HADOOP_HOME}/bin/hdfs dfs -rm -R ${CLEANED_OUTPUT_DIR} >/dev/null 2>&1
#2.RUNNING MAPPEDUCE PROGRAM DOING CLEANED
${HADOOP_HOME}/bin/yarn jar \
${LOCAL_JAR_PATH} \
${MAIN_CLASS} \
${UPLOAD_HDFS_DIR} \
${CLEANED_OUTPUT_DIR}
echo "THE FILE [${DAILY_FILE} IS CLEANED.............]"
3. 使用Hive分析数据
${HIVE_HOME}/bin/hive \
--hiveconf DATE_PARAM=${yesterday} \
--hiveconf DATA_PATH_PARAM=${CLEANED_OUTPUT_DIR} \
-f ${SQL_SCRIPTS_DIR}/weblogs-analyse.sql
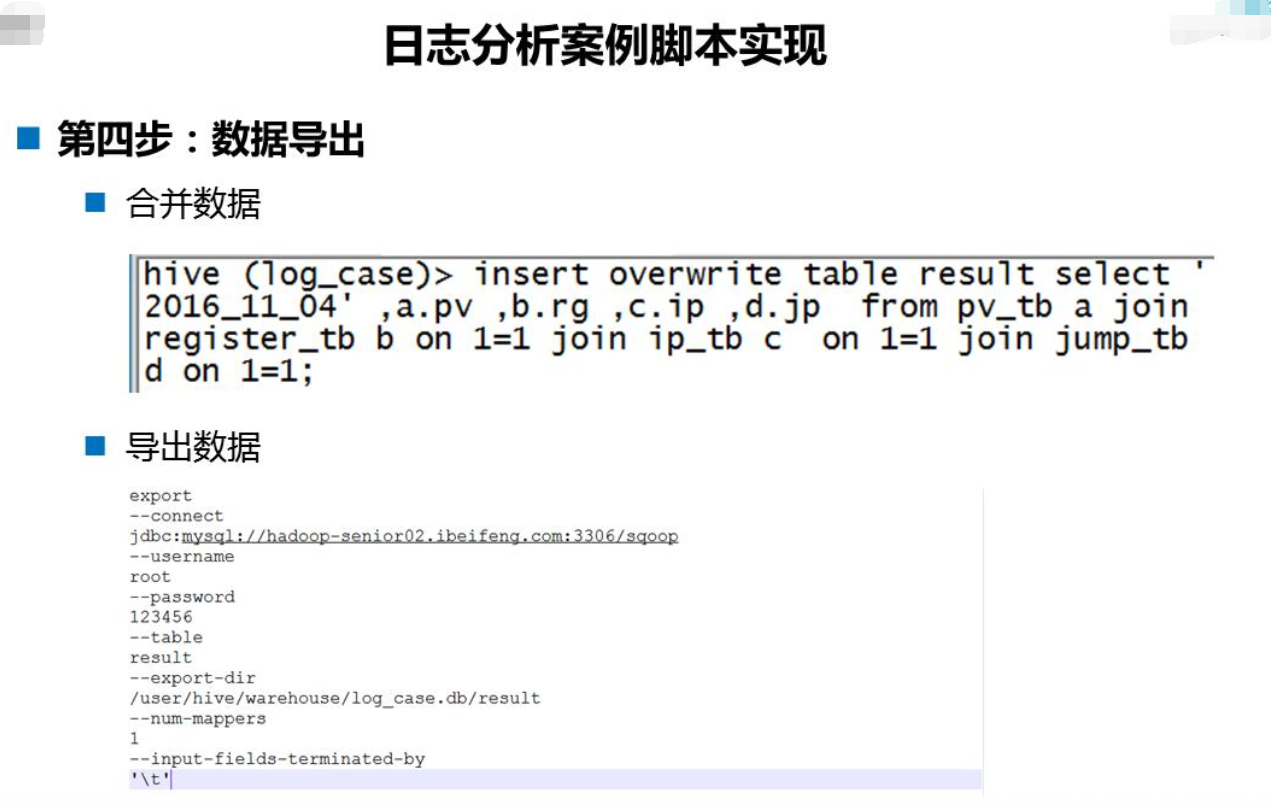
4. 使用Sqoop将Hive
export to mysql
${SQOOP_HOME}/bin/sqoop \
--options-file ${SQL_SCRIPTS_DIR}/export-weblogs-stat.sh

其中weblogs-clean.jar用于Mapreduce数据清洗;weblogs-analyse.sql用于Hive数据统计,包含建表语句与创建分区及加载数据;export-weblogs-stat.sh是使用Sqoop将数据导入Mysql的脚本。
export-weblogs-stat.sh代码解析
# Specifies the tool being invoked
export
# Connect parameter and value
--connect
jdbc:mysql://hadoop-senior01.ibeifeng.com:3306/db_weblogs_analyse
# Username parameter and value
--username
root
--password
123456
# RDBMS Table Name
--table
tb_analyse_stat
# Export Dir
--export-dir
/user/hive/warehouse/db_weblogs_analyse.db/tmp_analyse_stat
# Set Mapper Numbers
--num-mappers
1
--input-fields-terminated-by
"\001"
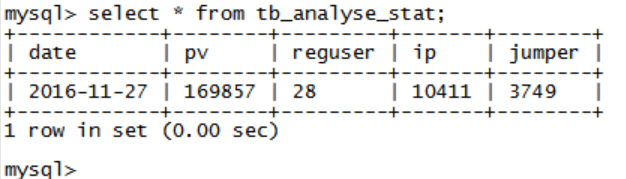
导入完成后查询结果:
优化:Hive中使用正则表达式创建表
CREATE TABLE weblogs_regex(
host STRING,
identity STRING,
user STRING,
time STRING,
request STRING,
status STRING,
size STRING
)
PARTITIONED BY (date string)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
"input.regex" = "([^ ]*) ([-|^ ]*) ([-|^ ]*) (-|\\[[^\\]]*\\]) ([^ \"]*|\"[^\"]*\") ([0-9]*) ([0-9]*)"
)
STORED AS TEXTFILE;UDF与UDTF
创建function
– 先在hive中添加jar包 add jar /home/beifeng/weblogs/senior-hive-udf.jar
– UDF
create function db_weblogs_analyse.date_transform as 'com.beifeng.bigdata.DateFormatUDF' ;– UDTF
create function db_weblogs_analyse.parse_request as 'com.beifeng.bigdata.RequestUDTF' ;查看函数:show functions
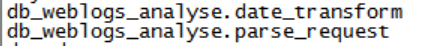
使用function
select parse_request(request) as (method, url, protocol) from weblogs_regex limit 5 ;
select parse_request(request) as (method, url, protocol) from weblogs_regex limit 5 ;
Hive中复杂类型使用
– HIVE复杂类型字段 主要是分隔符
-- 复杂类型字段(ARRAY,MAP,STRUCT)及自定义分隔符
CREATE TABLE employees_self(
name STRING,
salary FLOAT,
subordinates ARRAY<STRING>, -- 下属员工
deductions MAP<STRING, FLOAT>, -- 扣除金额: 项目 -> 金额
address STRUCT<street: STRING, city: STRING, state: STRING, zip: INT>
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
COLLECTION ITEMS TERMINATED BY '|'
MAP KEYS TERMINATED BY ':'
LINES TERMINATED BY '\n';
LOAD DATA LOCAL INPATH '/opt/datas/employee_self.input' INTO TABLE employees_self ;
桶表
CREATE TABLE IF NOT EXISTS emp_buckt(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int
)
CLUSTERED BY (deptno) INTO 4 BUCKETS
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE ;
– 强制HIVE为目标表的分桶初始化过程设置一个正确的reduce个数
set hive.enforce.bucketing = true;
INSERT OVERWRITE TABLE emp_buckt SELECT * FROM emp ;-- 桶表的优势:
-- 1,桶的数量是固定, 没有数据的波动
-- 2,桶对于抽样,非常合适,均匀
-- 3,分桶同时有利于执行高效的Map-Side JOIN
数据倾斜
解决方案
1. 参数调节
hive.map.aggr=true
hive.groupby.skewindata=true
2. SQL语句调节
small table join big table
big table join bing table
group by xx
count(distinct xx)















 737
737

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









