







Storm分布式计算结构称为topology(拓扑),由stream(数据流)、spout(数据流的生成者)、bolt(运算)组成。Strom的核心数据结构是tuple。tuple是包含了一个或多个键值对的列表,strom是由无限制的tuple组成的序列。spout代表了一个Strom topology的主要数据入口,充当采集器的角色,连接到数据源,将数据源转化为一个个tuple,并将tuple作为数据流进行发射。bolt可以理解为计算程序中的运算或者函数,将一个或者多个数据流作为输入,对数据实施运算后,选择性的输出一个或多个数据流。bolt可以订阅多个由spout或其他bolt发射的数据流。
HelloWord入门
首先编写数据源Spout,可以使用两种方式:
(1)实现IRichSpout接口。
(2)继承BaseRichSpout类。
需要对其中重点的几个方法进行重写或实现:open、nextTuple、declareOutputFields。
其次编写数据处理类Bolt,同样也有两种方式:
(1)实现RichBolt接口。
(2)继承BaseBasicBolt类。
需要对其中重点的几个方法进行重写或实现:execute、declareOutputFields。
最后编写主函数(Topology)进行提交任务,在使用Topoloty时,Storm提供了两种模式:本地模式和集群模式:
本地模式:无需Storm集群,直接在java中运行即可,一般用于开发和测试阶段。
集群模式:需要Storm集群,把实现的java程序打成jar包,然后使用storm命令把Topology提交到集群中去。
pom.xml文件,该文件中只需引入storm的核心文件即可,相关依赖会自动下载:
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>1.0.2</version>
</dependency>public class SentenceSpout extends BaseRichSpout {
private static final long serialVersionUID = 1L;
private SpoutOutputCollector collector;
private static final Map<Integer, String> sentences = new HashMap<Integer, String>();
static {
sentences.put(0, "my dog has fleas");
sentences.put(1, "i like cold beverages");
sentences.put(2, "the dog ate my homework");
sentences.put(3, "don't have a cow man");
sentences.put(4, "i don't think i like fleas");
}
public void open(Map map, TopologyContext context, SpoutOutputCollector collector) {
this.collector = collector;
}
public void nextTuple() {
final Random random = new Random();
int num = random.nextInt(5);
try {
Thread.sleep(500);
} catch (Exception e) {
e.printStackTrace();
}
collector.emit(new Values(sentences.get(num)));
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("sentences"));
}
}SplitSentenceBolt:
public class SplitSentenceBolt extends BaseBasicBolt {
private static final long serialVersionUID = 1L;
public void execute(Tuple tuple, BasicOutputCollector collector) {
String sentences = tuple.getStringByField("sentences");
String[] words = sentences.split(" ");
for(String word : words) {
collector.emit(new Values(word));
}
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}WordCountBolt:
public class WordCountBolt extends BaseBasicBolt {
private static final long serialVersionUID = 1L;
private Map<String, Integer> counts = null;
@Override
public void prepare(Map stormConf, TopologyContext context) {
super.prepare(stormConf, context);
counts = new HashMap<String, Integer>();
}
public void execute(Tuple tuple, BasicOutputCollector collector) {
String word = tuple.getStringByField("word");
Integer count = counts.get(word);
if(count == null) {
count = 0;
}
count ++;
counts.put(word, count);
collector.emit(new Values(word, count));
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word", "count"));
}
}ReportBolt:
public class ReportBolt extends BaseBasicBolt {
private static final long serialVersionUID = 1L;
private Map<String, Integer> counts = null;
@Override
public void prepare(Map stormConf, TopologyContext context) {
super.prepare(stormConf, context);
counts = new HashMap<String, Integer>();
}
public void execute(Tuple tuple, BasicOutputCollector collector) {
String word = tuple.getStringByField("word");
Integer count = tuple.getIntegerByField("count");
counts.put(word, count);
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
@Override
public void cleanup() {
super.cleanup();
System.out.println("--- FINAL COUNTS ---");
List<String> keys = new ArrayList<String>();
keys.addAll(counts.keySet());
Collections.sort(keys);
for(String key : keys) {
System.out.println(key + ":" + counts.get(key));
}
System.out.println("--------------------");
}
}ReportBolt:
public class ReportBolt extends BaseBasicBolt {
private static final long serialVersionUID = 1L;
private Map<String, Integer> counts = null;
@Override
public void prepare(Map stormConf, TopologyContext context) {
super.prepare(stormConf, context);
counts = new HashMap<String, Integer>();
}
public void execute(Tuple tuple, BasicOutputCollector collector) {
String word = tuple.getStringByField("word");
Integer count = tuple.getIntegerByField("count");
counts.put(word, count);
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
@Override
public void cleanup() {
super.cleanup();
System.out.println("--- FINAL COUNTS ---");
List<String> keys = new ArrayList<String>();
keys.addAll(counts.keySet());
Collections.sort(keys);
for(String key : keys) {
System.out.println(key + ":" + counts.get(key));
}
System.out.println("--------------------");
}
}WordCountTopology:
public class WordCountTopology {
private static final String SENTENCE_SPOUT_ID = "sentence-spout";
private static final String SPLIT_BOLT_ID = "split-bolt";
private static final String COUNT_BOLT_ID = "count-bolt";
private static final String REPORT_BOLT_ID = "report-bolt";
private static final String TOPOLOGY_NAME = "word-count-topology";
public static void main(String[] args) throws InterruptedException, InvalidTopologyException, AuthorizationException, AlreadyAliveException {
SentenceSpout spout = new SentenceSpout();
SplitSentenceBolt splitBolt = new SplitSentenceBolt();
WordCountBolt countBolt = new WordCountBolt();
ReportBolt reportBolt = new ReportBolt();
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout(SENTENCE_SPOUT_ID, spout, 2);
builder.setBolt(SPLIT_BOLT_ID, splitBolt, 2).setNumTasks(4).shuffleGrouping(SENTENCE_SPOUT_ID);
builder.setBolt(COUNT_BOLT_ID, countBolt, 4).fieldsGrouping(SPLIT_BOLT_ID, new Fields("word"));
builder.setBolt(REPORT_BOLT_ID, reportBolt).globalGrouping(COUNT_BOLT_ID);
Config config = new Config();
config.setNumWorkers(2);
/*LocalCluster cluster = new LocalCluster();
cluster.submitTopology(TOPOLOGY_NAME, config, builder.createTopology());
Thread.sleep(100000);
cluster.killTopology(TOPOLOGY_NAME);
cluster.shutdown();*/
StormSubmitter.submitTopology(TOPOLOGY_NAME, config, builder.createTopology());
}
}WordCountTopology的并发机制:
在没有配置topology的并发度之前,先来看一下默认配置下topology的执行过程。假设有一台服务器(node),为topology分配了一个worker,并且每个executor执行一个task:
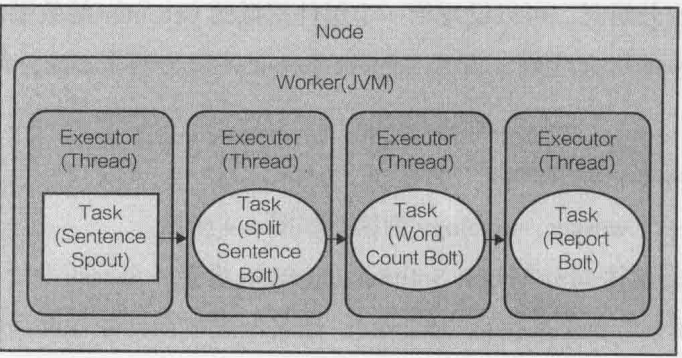
在上面的代码中使用config.setNumWorkers(2)为topology分配了两个worker。Storm给topology中定义的每个组件建立了一个task,默认情况下,每个task分配一个executor,在定义数据流分组时,可以设置给一个组件指派的executor的数量,允许设定每个task对应的executor个数和每个executor可执行的task的个数:builder.setSpout(SENTENCE_SPOUT_ID, spout, 2)。如果只是用一个worker,topology执行过程如下图:
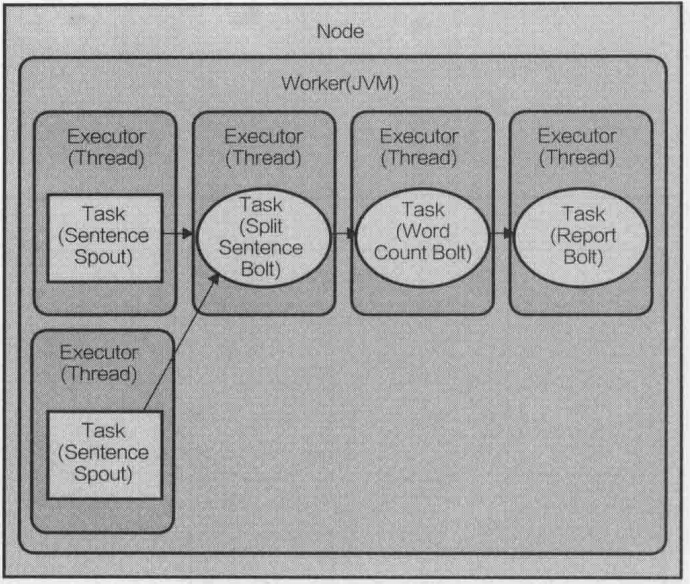
builder.setBolt(SPLIT_BOLT_ID, splitBolt, 2).setNumTasks(4).shuffleGrouping(SENTENCE_SPOUT_ID):设置了4个task和2个executor,每个executor线程指派了2个task来执行(4/2=2)。
builder.setBolt(COUNT_BOLT_ID, countBolt, 4).fieldsGrouping(SPLIT_BOLT_ID, new Fields("word")):设置4个executor,每个task由一个executor线程执行。
在2个worker下,topology执行过程如下图:
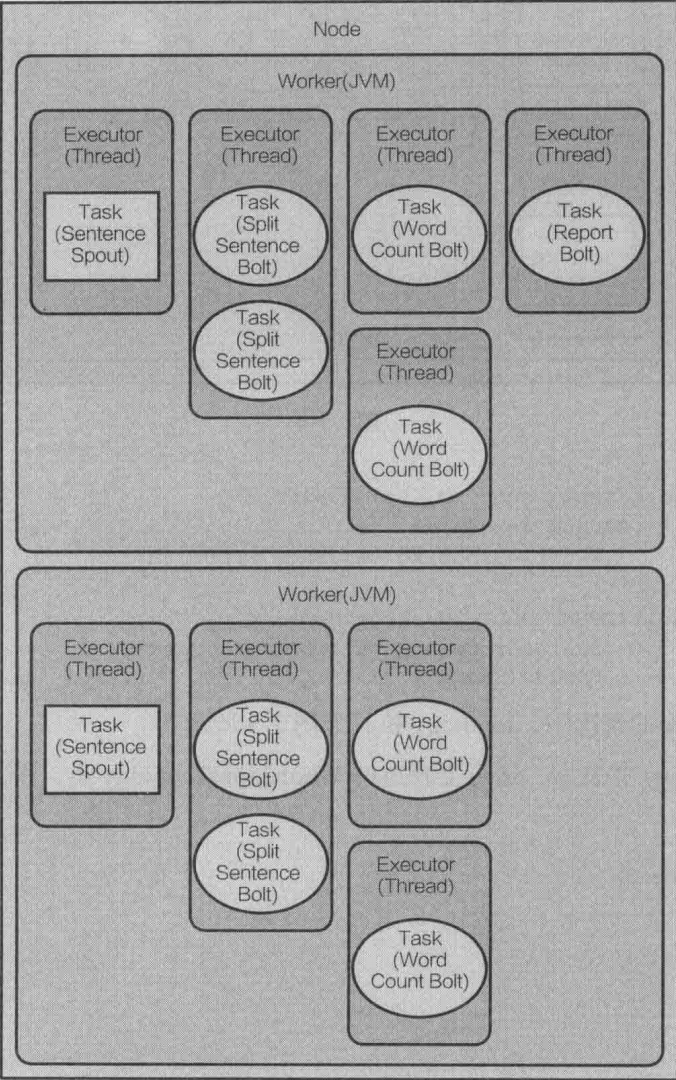
在实际开发中,重要的并不是逻辑代码的编写,而是worker、task、executor的配置。
数据流分组:
数据流分组定义了一个数据流中的tuple如何分发给topology中不同bolt的task。Storm中定义了7种内置数据流分组方式:
(1)Shuffle grouping(随机分组):这种方式会随机分发tuple给bolt的各个task,每个bolt实例接收到相同数量的tuple。
(2)Fields grouping(按字段分组):根据指定字段的值进行分组。
(3)All grouping(全复制分组):将所有的tuple复制后分发给所有的bolt task。每个订阅数据流的task都会接收到tuple的拷贝。
(4)Globle grouping(全局分组):这种分组方式将所有的tuples都路由到唯一一个task上。Storm按照最小的task ID来选取接收数据的task。注意,当使用全局分组方式时,设置bolt的task并发度是没有意义的,因为所有tuple都转发到同一个task上了。
(5)None grouping(不分组):在功能上与随机分组完全相同。
(6)Direct grouping(指向型分组):数据源会调用emitDirect()方法来判断一个tuple应该由哪个Storm组件来接收。只能在声明了是指向型的数据流上使用。
本地模式的话,直接Run as Java Application即可。
(7)Partial Key grouping(部分关键字分组):这种分组方式跟字段分组很相似,不同的是,这种方式会考虑下游bolt数据处理的均衡性问题,在输入数据源关键字不平衡时会有更好的性能。
(8)Local or Shuffle grouping(本地或随机分组):如果在源组件的worker进程里目标bolt有一个或更多的任务线程,元祖会被随机分配到那些同进程的任务中。
集群模式,进入项目目录,使用mvn package -DskipTests命令,将项目打成jar包。然后将jar包放入storm集群中nimbus所在的服务器,使用命令storm jar 项目.jar 全路径.main方法所在的类(比如:storm jar storm.jar com.hyy.PWTopology1)来提交topology。

查看任务命令:list

另外两个supervisor节点jps显示:
有保障机制的数据处理:
(1)spout的可靠性
在Storm中,可靠的消息处理机制是从spout开始的。一个提供了可靠的处理机制的spout需要记录它发射出去的tuple,当下游bolt处理tuple或者子tuple失败时,spout能够重新发射。
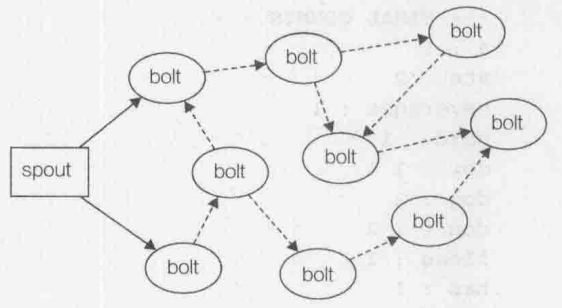
图中实线部分表示从spout发射的原始主干tuple,虚线部分表示的子tuple都是源自于原始tuple。这样产生的图形叫做tuple树。在有保障数据的处理过程中,bolt每收到一个tuple,都需要向上游确认应答(ask)或者报错(fail)。对主干tuple中的一个tuple,如果tuple树上的每个bolt进行了确认应答,spout会调用ask方法来标明这条消息已经完全处理了。如果树种任何一个bolt处理tuple报错,或者处理超时,spout会调用fail方法。
前面讲过,Storm通过调用spout的nextTuple()方法发送一个tuple。为了实现可靠的消息处理,首先要给每个发射的tuple带上唯一的ID,并且将ID作为参数传递给SpoutOutputCollector的emit方法。给tuple指定id是为了告诉Storm系统,无论执行成功还是失败,spout都要接收tuple树上所有节点返回的通知。
(2)bolt的可靠性
bolt要实现可靠的消息处理机制包含以下两个步骤:
①当发射衍生的tuple时,需要锚定读入的tuple。
②当处理消息成功或者失败时分别确认应答或者报错。
锚定tuple的意思是建立读入tuple和衍生tuple之间的对应关系,这样下游的bolt就可以通过应答确认、报错或者超时来加入到tuple树结构中。
接下来我们来看代码:
MessageSpout:
public class MessageSpout implements IRichSpout {
private static final long serialVersionUID = 1L;
private int index = 0;
private String[] subjects = new String[]{
"groovy,oeacnbase",
"openfire,restful",
"flume,activiti",
"hadoop,hbase",
"spark,sqoop"
};
private SpoutOutputCollector collector;
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.collector = collector;
}
@Override
public void nextTuple() {
if(index < subjects.length){
String sub = subjects[index];
//发送信息参数1 为数值, 参数2为msgId
collector.emit(new Values(sub), index);
index++;
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("subjects"));
}
@Override
public void ack(Object msgId) {
System.out.println("【消息发送成功!!!】 (msgId = " + msgId +")");
}
@Override
public void fail(Object msgId) {
System.out.println("【消息发送失败!!!】 (msgId = " + msgId +")");
System.out.println("【重发进行中...】");
collector.emit(new Values(subjects[(Integer) msgId]), msgId);
System.out.println("【重发成功!!!】");
}
@Override
public void close() {
}
@Override
public void activate() {
}
@Override
public void deactivate() {
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}public class SpliterBolt implements IRichBolt {
private static final long serialVersionUID = 1L;
private OutputCollector collector;
@Override
public void prepare(Map config, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
private boolean flag = false;
@Override
public void execute(Tuple tuple) {
try {
String subjects = tuple.getStringByField("subjects");
//模拟出错
if(!flag && subjects.equals("flume,activiti")){
flag = true;
int a = 1/0;
}
String[] words = subjects.split(",");
for (String word : words) {
//注意这里循环发送消息,要携带tuple对象,用于处理异常时重发策略
collector.emit(tuple, new Values(word));
}
collector.ack(tuple);
} catch (Exception e) {
e.printStackTrace();
collector.fail(tuple);
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
@Override
public void cleanup() {
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}public class WriterBolt implements IRichBolt {
private static final long serialVersionUID = 1L;
private FileWriter writer;
private OutputCollector collector;
@Override
public void prepare(Map config, TopologyContext context, OutputCollector collector) {
this.collector = collector;
try {
writer = new FileWriter("d://message.txt");
} catch (IOException e) {
e.printStackTrace();
}
}
private boolean flag = false;
@Override
public void execute(Tuple tuple) {
String word = tuple.getString(0);
try {
if(!flag && word.equals("hadoop")){
flag = true;
int a = 1/0;
}
writer.write(word);
writer.write("\r\n");
writer.flush();
} catch (Exception e) {
e.printStackTrace();
collector.fail(tuple);
}
collector.emit(tuple, new Values(word));
collector.ack(tuple);
}
@Override
public void cleanup() {
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}public class MessageTopology {
public static void main(String[] args) throws Exception {
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("spout", new MessageSpout());
builder.setBolt("split-bolt", new SpliterBolt()).shuffleGrouping("spout");
builder.setBolt("write-bolt", new WriterBolt()).shuffleGrouping("split-bolt");
//本地配置
Config config = new Config();
config.setDebug(false);
LocalCluster cluster = new LocalCluster();
System.out.println(cluster);
cluster.submitTopology("message", config, builder.createTopology());
Thread.sleep(10000);
cluster.killTopology("message");
cluster.shutdown();
}
}Strom的DRPC:
Storm是一个分布式实时处理框架,它支持以DRPC方式调用.可以理解为Storm是一个集群,DRPC提供了集群中处理功能的访问接口。其实即使不通过DRPC,而是通过在Topoloye中的spout中建立一个TCP/HTTP监听来接收数据,在最后一个Bolt中将数据发送到指定位置也是可以的。这是后话,后面再进行介绍。而DPRC则是Storm提供的一套开发组建,使用DRPC可以极大的简化这一过程。Storm里面引入DRPC主要是利用storm的实时计算能力来并行化CPU intensive的计算。DRPC的storm topology以函数的参数流作为输入,而把这些函数调用的返回值作为topology的输出流。DRPC其实不能算是storm本身的一个特性, 它是通过组合storm的原语spout,bolt, topology而成的一种模式(pattern)。本来应该把DRPC单独打成一个包的, 但是DRPC实在是太有用了,所以我们我们把它和storm捆绑在一起。
DRPC工作流程:
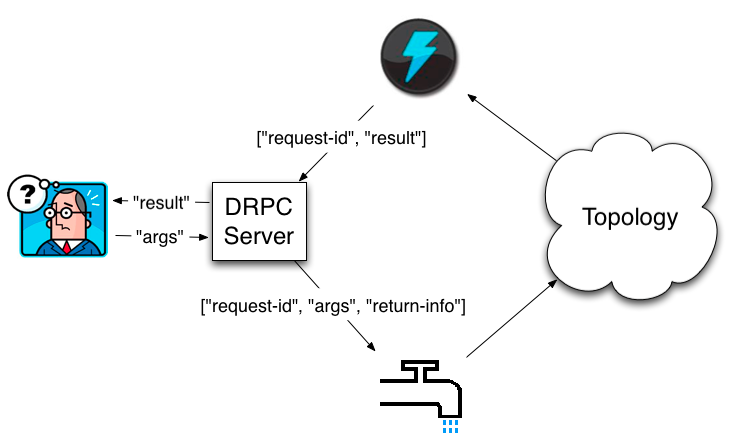
DRPC与一般的RPC没有区别,只不过它是分布式的。对于用户而言,他是向一个DRPC服务器发送请求,然后等待DRPC的返回结果。整个流程如下:
1、用户向DRPC服务器发送请求,请求内容主要包括请求的方法名以及请求的参数。
2、DRPC服务器接收到这个请求后,将请求发送到拓扑的spout。
3、拓扑计算完成后,将结果返回到DRPC服务器。结果是以请求参数作为key,计算结果作为value的一个tuple(即有2个域)。
4、DRPC服务器将结果返回用户。
简单的说,就是用户的请求作为spout的数据源。
对于高计算密度的RPC应用,DRPC可以将请求均匀的分布在整个storm集群进行计算。
在storm0.9以后,drpc都使用了trident的API来创建拓扑,不再使用原有API。
首先,修改Storm/conf/storm.yaml中的drpc server地址;需要注意的是:必须修改所有Nimbus和supervisor上的配置文件,设置drpc server地址。否则在运行过程中可能无法返回结果。
然后,通过 storm drpc命令启动drpc server。
RemoteDRPCDemo:
public class RemoteDRPCDemo {
public static void main(String[] args) throws InvalidTopologyException, AuthorizationException, AlreadyAliveException {
Config config = new Config();
config.setNumWorkers(2);
TridentTopology topology = new TridentTopology();
topology.newDRPCStream("exclaimation").each(new Fields("args"), new ExclaimBolt(), new Fields("words")).parallelismHint(5);
StormSubmitter.submitTopology("drpc-demo", config, topology.build());
}
}
class ExclaimBolt extends BaseFunction {
public void execute(TridentTuple tuple, TridentCollector collector) {
String input = tuple.getString(0);
collector.emit(new Values(input + "!"));
}
}public class DrpcExclam {
public static void main(String[] args) throws TException {
Config config = new Config();
config.setDebug(true);
config.put("storm.thrift.transport", "org.apache.storm.security.auth.SimpleTransportPlugin");
config.put(Config.STORM_NIMBUS_RETRY_TIMES, 3);
config.put(Config.STORM_NIMBUS_RETRY_INTERVAL, 10);
config.put(Config.STORM_NIMBUS_RETRY_INTERVAL_CEILING, 20);
config.put(Config.DRPC_MAX_BUFFER_SIZE, 5);
DRPCClient client = new DRPCClient(config, "192.168.3.58", 3772);
String ss = "the cow jumped over the moon";
for(String s :ss.split(" ")){
//返回结果是一个KV格式,KEY为请求的id, V为最后一个bolt的返回结果。被封装成一个2个值的tuple。
System.out.println(client.execute("exclaimation", s));
}
}
}














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









