










一、虚拟机VS容器

一)虚拟机的缺点及容器为何产生
- 资源占用多
- 冗余步骤多,繁琐
- 启动慢
因为虚拟机存在上面的缺点,于是Linux发展出了另一种虚拟化技术:Linux容器(Linux container,缩写为LXC)。
Linux容器不是模拟一个完整的操作系统 ,而是对进程进行隔离。
有了容器,就可以将软件运行所需要的所有资料打包到一个隔离的容器中。容器与虚拟机不同,不需要捆绑一整套操作系统,只需要软件工作所需要的库资源和设置。
二)docker和虚拟机之间的不同之处
1、传统虚拟机
传统虚拟机技术是虚拟出一整套硬件后,在其上运行一个完整的操作系统,在该系统上再运行所需要的应用进程
1、主要是因为每个虚拟机需要运行自己的一组系统进程,这就产生了除组件进程外消耗以外的额外计算资源损耗。 2、不同虚拟机它拥有了完全不同的操作系统 3、在虚拟机之下是宿主机的操作系统与一个管理程序,它将物理硬件资源分成较小部分的虚拟硬件资源,从而被每个虚拟机里的操作系统使用。 注意:存在两种类型的管理程序:第一种类型的管理程序不会使用宿主机OS,而第二种类型会
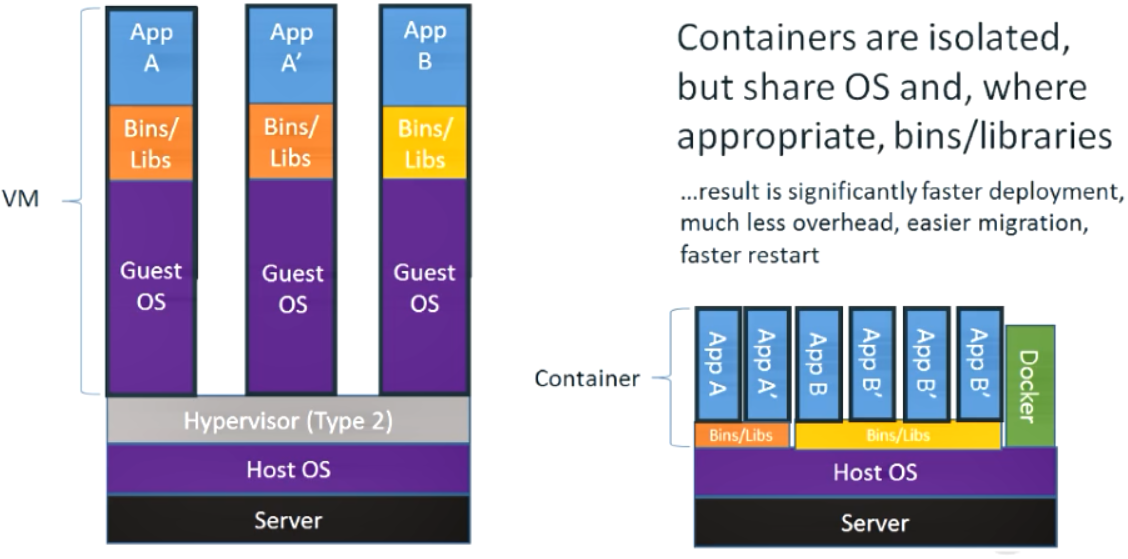
2、容器
容器内的应用进程直接运行在宿主机的内核,容器内没有自己的内核,而且也没有进行硬件虚拟 。因此容器要比传统虚拟机更为轻便。
每个容器之间互相隔离,每个容器有自己的文件系统,容器之间进程不会互相影响,能区分计算资源,耦合度低。
Docker 安装时会自动在 host 上创建三个网络:bridge、host和none
-
- none 网络就是什么都没有的网络。挂在这个网络下的容器除了 lo,没有其他任何网卡。容器创建时,可以通过 --network=none 指定使用 none 网络。
- 连接到 host 网络的容器共享 Docker host 的网络栈,容器的网络配置与 host 完全一样。可以通过 --network=host 指定使用 host 网络。
- docker host的网络最大的好处就是性能,若容器对网络传输效率有较高要求,则可以选择host网络
- Docker 安装时会创建一个 命名为 docker0 的 linux bridge。如果不指定--network,创建的容器默认都会挂到 docker0 上。
- 使用brctl show显示出来
容器更加轻量级,它允许在相同的硬件上运行更多数量的组件。 一个容器仅仅是运行在宿主机上被隔离的单个进程,仅消耗应用容器消耗的资源,不会消耗其他进程的开销 多个容器则会完全执行运行在宿主机上的同一个内核的系统调用,此内核是唯一一个在宿主机操作系统上执行x86指令的内核。CPU也不需要再做任何对虚拟机能做那样的虚拟化。
1)启动时间
docker启动是秒级的,传统虚拟机启动是分钟级的;另外docker是一个精简版、高度浓缩的小型Linux系统。
- docker通过类似Git设计理念的操作来方便用户获取、分发和更新应用镜像,存储复用,增量更新
- docker通过dockerfile支持灵活的自动化创建和部署机制,提高工作效率,使流程标准化
2)运行在不同环境的应用
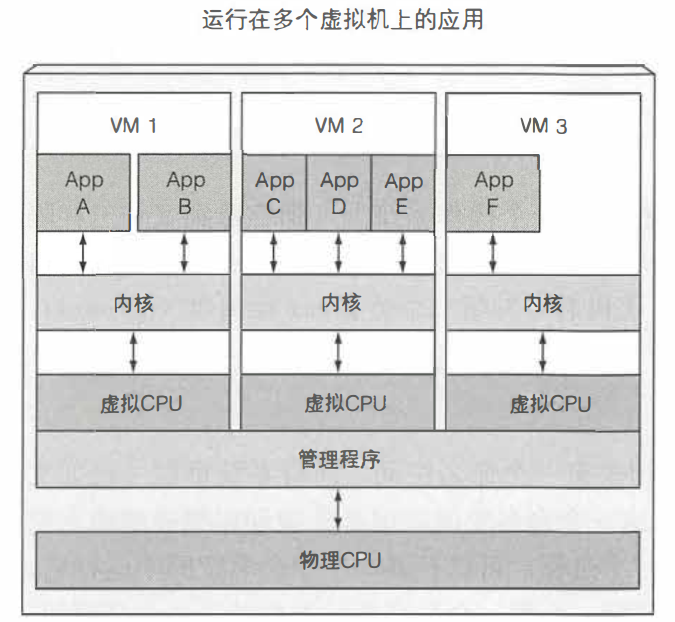

3、docker容器技术与传统虚拟机技术比较
| 特性 | 容器 | 虚拟机 |
| 启动速度 | 快,秒级 | 慢,分钟级 |
| 性能 | 接近原生 | 较弱 |
| 内存代价 | 很小 | 较多 |
| 占用磁盘空间 | 小,一般为MB | 非常大,一般为GB |
| 运行密度 | 单机支持上千个容器 | 一般几十个 |
| 运行状态 | 直接运行在宿主机的内核上,不同容器共享同一个Linux内核 | 运行于Hypervisor上 |
| 隔离性 | 完全隔离 | 完全隔离 |
| 迁移性 | 优秀 | 一般 |
| 资源利用率 | 高 | 低 |
隔离的内容:文件系统、网络、PID、etc、usr、UTS(UTS命名空间是Linux内核Namespace(命名空间)的一个子系统,主要用来完成对容器HOSTNAME和domain的隔离,同时保存内核名称、版本、以及底层体系结构类型等信息)
虚拟机的好处:它提供的是完全的隔离的环境,因为每个虚拟机运行在它自己的内核上;
容器:它都是调用一个内核,这存在安全隐患
建议:
- 若你的硬件资源有限,那当你有少量进程需要隔离时,虚拟机就可以成为一个选项
- 为了在同一台机器上运行大量被隔离的进程,容器因它的低消耗而成为一个更好的选择
4、为什么docker比虚拟机快?
虚拟机运行它自己的一组系统服务,而容器则不会,因为他们都运行在同一个操作系统上。(运行一个容器不会像虚拟机那样开机,它的进程可以很快启动)
- docker有着比虚拟机更少的抽象层。由于docker不需要hypervisor实现硬件资源虚拟化,运行在docker容器上的程序直接使用的是实际物理机的硬件资源。因此在cpu、内存利用率上docker将会在效率上有明显的而优势;
- docker利用的是宿主机的内核,而不需要guest os。因此当建立一个容器时,docker不需要和虚拟机一样重新加载一个操作系统的内核。从而避免加载操作系统内核返回比较费时的资源过程,当新建一个虚拟机时,虚拟机软件需要加载guest os,返回新建过程是分钟级的。而docker由于直接利用宿主机的操作系统,则省略了加载过程,因此新建一个docker容器只需要几秒。
三)容器实现隔离机制
![]()
目录
1、限制
有两个机制可用: 第一个是 隔离:namespace命名空间, 它使每个进程只看到它自己的系统视图(文件、进程、网络接口、主机名等); 第二个是 限制:cgroups控制组 (control groups),它限制了进程能使用的资源量 (CPU、 内存、 网络带宽等)。
默认情况下,每个Linux系统最初仅有一个命名空间。所有系统资源(诸如文件系统、用户ID、网络接口等)属于这一个命名空间。但是你能创建额外的命名空间,以及在他们之间组织资源。对于一个进程,可以在一个命名空间中运行它。进程将只能看到同一个命名空间下的资源。当然,会存在多种类型的命令空间。所以一个进程不单单属于某一个命名空间,而属于每个类型的一个命名空间。
1)Linux内核里面实现了7种不同类型的命名空间
名称 宏定义(系统调用参数) 隔离内容 Cgroup CLONE_NEWCGROUP Cgroup root directory (since Linux 4.6) IPC CLONE_NEWIPC 信号量、消息队列和共享内存System V IPC, POSIX message queues (since Linux 2.6.19) Network CLONE_NEWNET 网络设备、网络栈、端口等Network devices, stacks, ports, etc. (since Linux 2.6.24) Mount CLONE_NEWNS 挂载点(文件系统)Mount points (since Linux 2.4.19) PID CLONE_NEWPID 进程编号Process IDs (since Linux 2.6.24) User CLONE_NEWUSER 用户和用户组User and group IDs (started in Linux 2.6.23 and completed in Linux 3.8) UTS CLONE_NEWUTS 主机名与域名Hostname and NIS domain name (since Linux 2.6.19)
不同类型的命名空间的作用
- mount(mnt):每个进程都存在于一个mount Namespace里面,mount Namespace为进程提供了一个文件层次视图。如果不设定这个flag,子进程和父进程将共享一个mount Namespace,其后子进程调用mount或umount将会影响到所有该Namespace内的进程。如果子进程在一个独立的mount Namespace里面,就可以调用mount或umount建立一份新的文件层次视图。
- process ID(pid):linux通过命名空间管理进程号,同一个进程,在不同的命名空间进程号不同!进程命名空间是一个父子结构,子空间对于父空间可见。
- network(net):Network Namespace为进程提供了一个完全独立的网络协议栈的视图。包括网络设备接口,IPv4和IPv6协议栈,IP路由表,防火墙规则,sockets等等。一个Network Namespace提供了一份独立的网络环境,就跟一个独立的系统一样
- inter-process communication(ipc):用于隔离进程间通讯所需的资源( System V IPC, POSIX message queues),PID命名空间和IPC命名空间可以组合起来用,同一个IPC名字空间内的进程可以彼此看见,允许进行交互,不同空间进程无法交互
- UTS:用于隔离主机名
- user ID(user):用于隔离用户
每种命名空间被用来隔离一组特定的资源。例如:UTS命名空间决定了运行在命名空间里的进程能看见哪些主机名和域名。通过分派两个不同的UTS命名空间给一对进程,能给他们看见不同的本地主机名。换句话说,这两个进程就好像正在两个不同的机器上运行一样(只是就主机名而言是这样的)
同样,一个进程属于什么network命名空间决定了运行在进程里的应用程序能看见什么网络接口。每个网络接口属于一个命名空间,但是可以从一个命名空间转移到另一个。每个容器都使用它自己的网络命名空间,因此每个容器仅能看见他自己的一组网络接口。
2、资源限制
对容器进行限制。防止容器无限制滥用甚至耗尽宿主机上的资源。而 Linux Cgroups 就是 Linux 内核中用来为进程设置资源限制的一个重要功能。
Linux Cgroups 的全称是 Linux Control Group。它最主要的作用,就是限制一个进程组能够使用的资源上限,包括 CPU、内存、磁盘、网络带宽等等。
在 Linux 中,Cgroups 给用户暴露出来的操作接口是文件系统,即它以文件和目录的方式组织在操作系统的 /sys/fs/cgroup 路径下。在 Ubuntu 16.04 机器里,我可以用 mount 指令把它们展示出来,这条命令是
mount -t cgroup cpuset on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset) cpu on /sys/fs/cgroup/cpu type cgroup (rw,nosuid,nodev,noexec,relatime,cpu)cpuacct on /sys/fs/cgroup/cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpuacct) blkio on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,blkio) memory on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory) ...
可以看到,在 /sys/fs/cgroup 下面有很多诸如 cpuset、cpu、 memory 这样的子目录,也叫子系统。这些都是我这台机器当前可以被 Cgroups 进行限制的资源种类。而在子系统对应的资源种类下,你就可以看到该类资源具体可以被限制的方法。比如,对 CPU 子系统来说,我们就可以看到如下几个配置文件,这个指令是:
ls /sys/fs/cgroup/cpu cgroup.clone_children cpu.cfs_period_us cpu.rt_period_us cpu.shares notify_on_releasecgroup.procs cpu.cfs_quota_us cpu.rt_runtime_us cpu.stat tasks
以上输出的关键文件 cfs_period和cfs_quota, 可以用来限制进程在长度为 cfs_period 的一段时间内,只能被分配到总量为 cfs_quota 的 CPU 时间。
而这样的配置文件又如何使用呢?
你需要在对应的子系统下面创建一个目录,比如,我们现在进入 /sys/fs/cgroup/cpu 目录下:
root@ubuntu:/sys/fs/cgroup/cpu$ mkdir container root@ubuntu:/sys/fs/cgroup/cpu$ ls container/ cgroup.clone_children cpu.cfs_period_us cpu.rt_period_us cpu.shares notify_on_releasecgroup.procs cpu.cfs_quota_us cpu.rt_runtime_us cpu.stat tasks
这个目录就称为一个“控制组”。你会发现,操作系统会在你新创建的 container 目录下,自动生成该子系统对应的资源限制文件。
现在,我们在后台执行这样一条脚本
$ while : ; do : ; done & [1] 226
显然,它执行了一个死循环,可以把计算机的 CPU 吃到 100%,根据它的输出,我们可以看到这个脚本在后台运行的进程号(PID)是 226。
这样,我们可以用 top 指令来确认一下 CPU 有没有被打满:
$ top %Cpu0 :100.0 us, 0.0 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
在输出里可以看到,CPU 的使用率已经 100% 了(%Cpu0 :100.0 us)。
而此时,我们可以通过查看 container 目录下的文件,看到 container 控制组里的 CPU quota 还没有任何限制(即:-1),CPU period 则是默认的 100 ms(100000 us):
$ cat /sys/fs/cgroup/cpu/container/cpu.cfs_quota_us -1 $ cat /sys/fs/cgroup/cpu/container/cpu.cfs_period_us 100000
接下来,我们可以通过修改这些文件的内容来设置限制。
比如,向 container 组里的 cfs_quota 文件写入 20 ms(20000 us):
$ echo 20000 > /sys/fs/cgroup/cpu/container/cpu.cfs_quota_us
结合前面的介绍,你应该能明白这个操作的含义,它意味着在每 100 ms 的时间里,被该控制组限制的进程只能使用 20 ms 的 CPU 时间,也就是说这个进程只能使用到 20% 的 CPU 带宽。
接下来,我们把被限制的进程的 PID 写入 container 组里的 tasks 文件,上面的设置就会对该进程生效了:
$ echo 226 > /sys/fs/cgroup/cpu/container/tasks
我们可以用 top 指令查看一下:
$ top %Cpu0 : 20.3 us, 0.0 sy, 0.0 ni, 79.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
可以看到,计算机的 CPU 使用率立刻降到了 20%(%Cpu0 : 20.3 us)。
除 CPU 子系统外,Cgroups 的每一项子系统都有其独有的资源限制能力,比如:
- blkio:为块设备设定I/O 限制,一般用于磁盘等设备
- cpuset:为进程分配单独的 CPU 核和对应的内存节点
- memory:为进程设定内存使用的限制
Linux Cgroups 的设计还是比较易用的,简单粗暴地理解呢,它就是一个子系统目录加上一组资源限制文件的组合。 对于 Docker 等 Linux 容器项目来说,它们只需要在每个子系统下面,为每个容器创建一个控制组(即创建一个新目录),然后在启动容器进程之后,把这个进程的 PID 填写到对应控制组的 tasks 文件中就可以了。
而至于在这些控制组下面的资源文件里填上什么值,就靠用户执行 docker run 时的参数指定了,比如这样一条命令:
$ docker run -it --cpu-period=100000 --cpu-quota=20000 ubuntu /bin/bash
在启动这个容器后,我们可以通过查看 Cgroups 文件系统下,CPU 子系统中,“docker”这个控制组里的资源限制文件的内容来确认:
$ cat /sys/fs/cgroup/cpu/docker/5d5c9f67d/cpu.cfs_period_us 100000 $ cat /sys/fs/cgroup/cpu/docker/5d5c9f67d/cpu.cfs_quota_us 20000
这就意味着这个 Docker 容器,只能使用到 20% 的 CPU 带
四)容器的创建
1、容器创建需要
- 内核
- runtime:容器真正运行的地方。runtime需要跟操作系统kernl紧密协作,为容器提供运行环境,lxc、runc和rkt是目前主流的三种容器runtime
- 管理工具:runc的管理工具是docker engine。docker engine包含后台deamon和cli两个部分。我们通常提到docker,一般指的docker engineZ
2、容器资源限制
#内存限制 docker run -it -m 200M --memory-swap=300M progrium/stress --vm 1 --vm-bytes 280M 1、-m 或 --memory:设置内存的使用限额,例如 100M, 2G。 2、--memory-swap:设置 内存+swap 的使用限额。 3、默认情况下,上面两组参数为 -1,即对容器内存和 swap 的使用没有限制 4、--vm 1:启动 1 个内存工作线程 5、--vm-bytes 280M:每个线程分配 280M 内存。 progrium/stress为镜像名称,如果--memory-swap不写,默认是memory的两倍 # CPU限制 Docker 可以通过 -c 或 --cpu-shares 设置容器使用 CPU 的权重。如果不指定,默认值为 1024。 与内存限额不同,通过 -c 设置的 cpu share 并不是 CPU 资源的绝对数量,而是一个相对的权重值。某个容器最终能分配到的 CPU 资源取决于它的 cpu share 占所有容器 cpu share 总和的比例 # block IO权重 Block IO 是另一种可以限制容器使用的资源。Block IO 指的是磁盘的读写,docker 可通过设置权重、限制 bps 和 iops 的方式控制容器读写磁盘的带宽 默认情况下,所有容器能平等地读写磁盘,可以通过设置 --blkio-weight 参数来改变容器 block IO 的优先级。 --blkio-weight 与 --cpu-shares 类似,设置的是相对权重值,默认为 500。在下面的例子中,container_A 读写磁盘的带宽是 container_B 的两倍。 # 限制 bps 和 iops bps 是 byte per second,每秒读写的数据量。 iops 是 io per second,每秒 IO 的次数。 可通过以下参数控制容器的 bps 和 iops: --device-read-bps,限制读某个设备的 bps。 --device-write-bps,限制写某个设备的 bps。 --device-read-iops,限制读某个设备的 iops。 --device-write-iops,限制写某个设备的 iops。
二、docker与虚拟化
一)虚拟化概述
虚拟化技术是通用的概念,在不同的领域有不同的理解。在计算领域,一般是指计算虚拟化,或通常说的服务器虚拟化。
虚拟化是一种资源管理技术,是将计算机的各种实体资源,如服务器、网络、内存及存储等,予以抽象、转换后呈现出来,打破实体结构件的不可分割的障碍,使用户可以比原本的组态更好的方式来应用这些资源。
虚拟化的核心是对资源的抽象,目标往往是为了在同一个主机上同时运行多个系统或应用。从而提高资源的利用率,并带来降低成本、方便管理和容错容灾等好处。
二)虚拟化分类
https://www.cnblogs.com/sammyliu/articles/4389765.html
docker以及其他容器技术,都属于操作系统虚拟化这个范畴。操作系统虚拟化最大的特点是不需要额外的supervisor支持。
传统方式是在硬件层面实现虚拟化,需要有额外的虚拟机管理应用和虚拟机操作系统层。docker容器是在操作系统层面实现虚拟化,直接复用本地主机的操作系统,因此更加轻量级。
三、docker的关键知识点
一)docker的版本说明
docker版本的CE才是开源版,EE是企业版。
从2017年第一季度开始,docker版本号遵循YY.MM-xx格式,类似于Ubuntu等项目。例如 2018年6月第一次发布的社区版本为18.06.0-ce
二)docker容器本质
一个正在运行的 Docker 容器,其实就是一个启用了多个 Linux Namespace 的应用进程,而这个进程能够使用的资源量,则受 Cgroups 配置的限制。这也是容器技术中一个非常重要的概念,即:容器是一个“单进程”模型。
- 容器其实就是Linux下一个特殊的进程
- docker容器通过namespace实现进程隔离,通过cgroup实现资源限制
- docker镜像(rootfs)是一个操作系统的所有文件和目录而不包括内核,docker镜像是共享宿主机的内核的
- docker镜像是以主副方式挂载,所有的增删改都只会作用在容器层,但是相同的文件会覆盖掉下一层,这种方式也被称为“copy-on-wtite”
三)docker的三要素
1、镜像(image)
一个 只读 的模板。 镜像可以用来创建docker容器,一个镜像可以创建很多容器 。
镜像的特点: 镜像都是只读的。当容器启动时,一个新的可写层被加载到镜像的顶部。这一层被称为容器层,容器层之下的层都是镜像层。
2、容器(container)
独立运行的一个或者一组应用。容器是利用镜像创建的运行实例(相对于Python中的类和对象的概念)。
它可以被启动、开始、停止、删除。每个容器都是互相隔离的,保证安全的平台。
可以把容器看做是一个简易版的Linux环境 (包括root用户名权限、进程空间、用户空间和网络空间等)和运行在其中的应用程序。
容器的定义和镜像几乎是一模一样的,也是一堆层的统一视角, 唯一区别的是容器的最上面那一层是可读写的。
3、仓库(repository)
仓库(repository)和仓库注册服务器(registry)是有区别的。仓库注册服务器上往往放着很多个仓库,每个仓库中又包含了很多个镜像,每个镜像有不同的标签(tag)。
仓库分为公开仓库(public)和私有仓库(private)两种形式。
四)UnionFS(联合文件系统)
UnionFS(联合文件系统):union文件系统(unionFS)是一种分层、轻量级并且高性能的文件系统,它支持 对文件系统的修改作为一次提交来一层层的叠加 ,同时可以将不同的目录挂载到同一个虚拟文件系统下。
union文件系统是docker镜像的基础。镜像可以通过分层来进行继承。基于基础镜像(没有父镜像),可以制作各种的应用镜像。
特性:一次同时加载多个文件系统,但从外面看来,只能看到一个文件系统,联合加载会把各层文件系统叠加起来,这样最终的文件系统会包含所有底层的文件和目录
五)docker加载原理
docker的镜像实际上由一层一层的文件系统组成,这种层级的文件系统称为联合文件系统(unionFS)。
bootfs(boot file system)主要包含bootloader和kernel,bootloader主要是引导加载kernel,linux刚启动时会加载bootfs文件系统, 在docker镜像的最底层就是bootfs 。这一层与我们典型的linux/unix系统是一样的,包含boot加载器和内核。当boot加载完成之后,整个内核就都在内存中了。此时内存的使用权已由bootfs转交给内核,此时系统也会卸载bootfs。
rootfs(root file system),在bootfs之上,包含的就是典型的linux系统中的/dev/,/proc,/bin,/etc/等标准目录和文件。rootfs就是各种不同操作系统发行版,比如ubuntu,centos等。
六)docker的五种存储方式
-
AUFS
-
Device mapper
-
Btrfs
-
OverlayFS:Docker存储驱动之OverlayFS简介_fuse-overlayfs和overlayfs区别-CSDN博客
-
ZFS
详细内容见:https://www.cnblogs.com/fengjian2016/p/6638205.html
七)docker的四种网络模式
- host模式,使用--net=host指定。
- container模式,使用--net=container:NAME_or_ID指定。
- none模式,使用--net=none指定。
- bridge模式,使用--net=bridge指定,默认设置。
1、host模式
使用--net=host指定,容器和宿主机共享network namespace。容器将不会虚拟出自己的网卡,配置自己的IP等,而是使用宿主机的IP和端口。但是,容器的其他方面,如文件系统、进程列表等还是和宿主机隔离的。
使用host模式的容器可以直接使用宿主机的IP地址与外界通信,容器内部的服务端口也可以使用宿主机的端口,不需要进行NAT,host最大的优势就是网络性能比较好,但是docker host上已经使用的端口就不能再用了,网络的隔离性不好
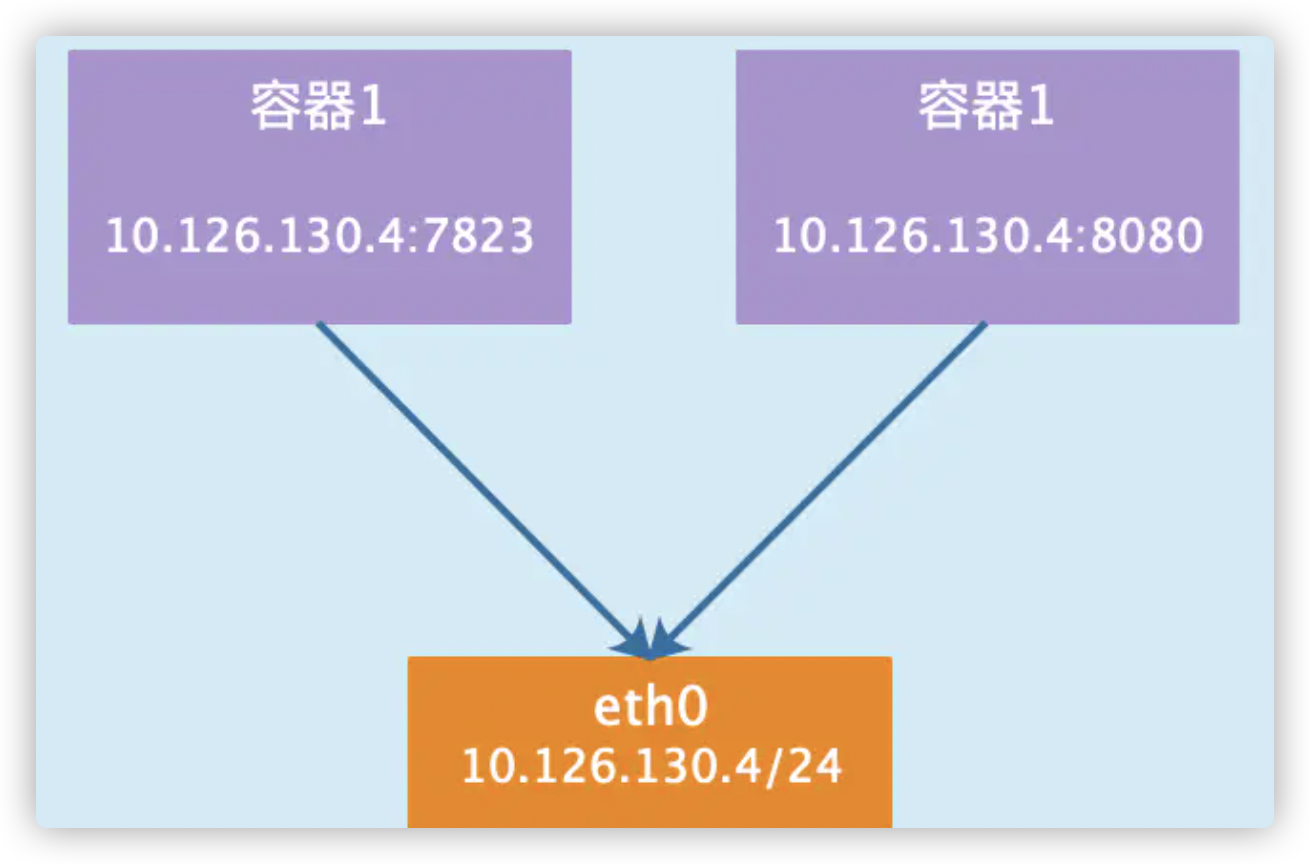
2、container模式
使用--net=container:NAME_or_ID指定,容器和另外一个容器共享Network namespace。 kubernetes中的pod就是多个容器共享一个Network namespace。
新创建的容器不会创建自己的网卡,配置自己的 IP,而是和一个指定的容器共享 IP、端口范围等。同样,两个容器除了网络方面,其他的如文件系统、进程列表等还是隔离的。两个容器的进程可以通过 lo 网卡设备通信
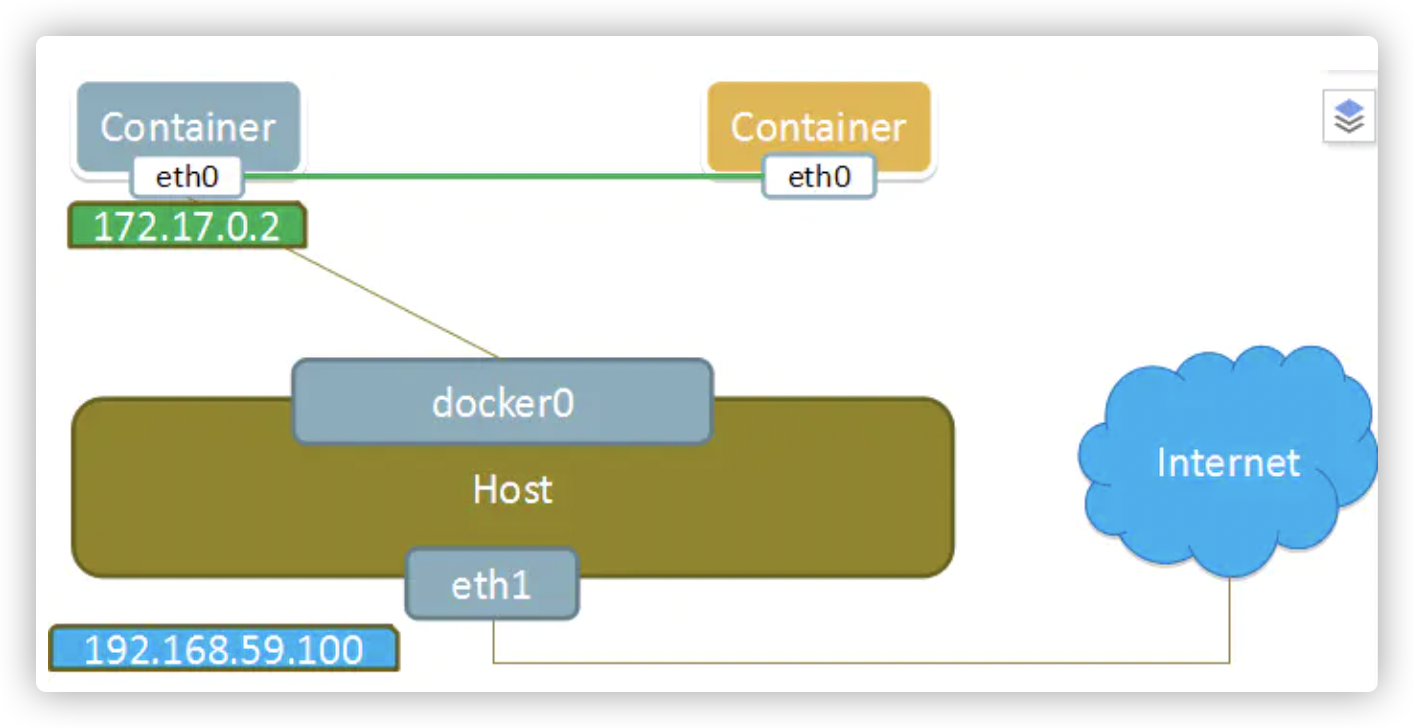
3、none模式
使用--net=none指定,容器有独立的Network namespace,但并没有对其进行任何网络设置,如分配veth pair 和网桥连接,配置IP等。也就是这个容器没有网卡、IP、路由等。需要我们自己为容器添加网卡、配置IP。
这种网络模式下容器只有lo回环网络,没有其他网卡。none模式可以在容器创建时通过--network=none来指定。优势:这种类型的网络没有办法联网,封闭的网络能很好的保证容器的安全性。
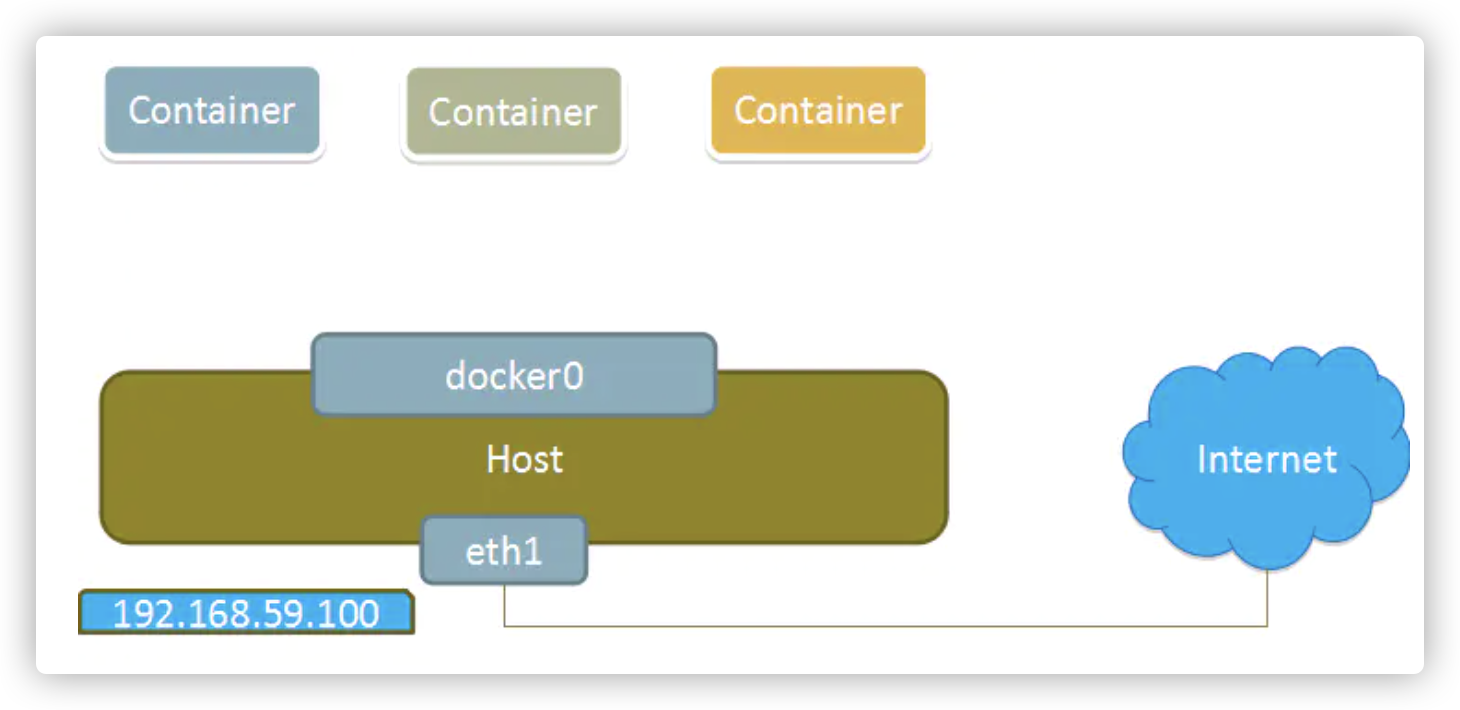
4、bridge模式
使用--net=bridge指定,默认设置。
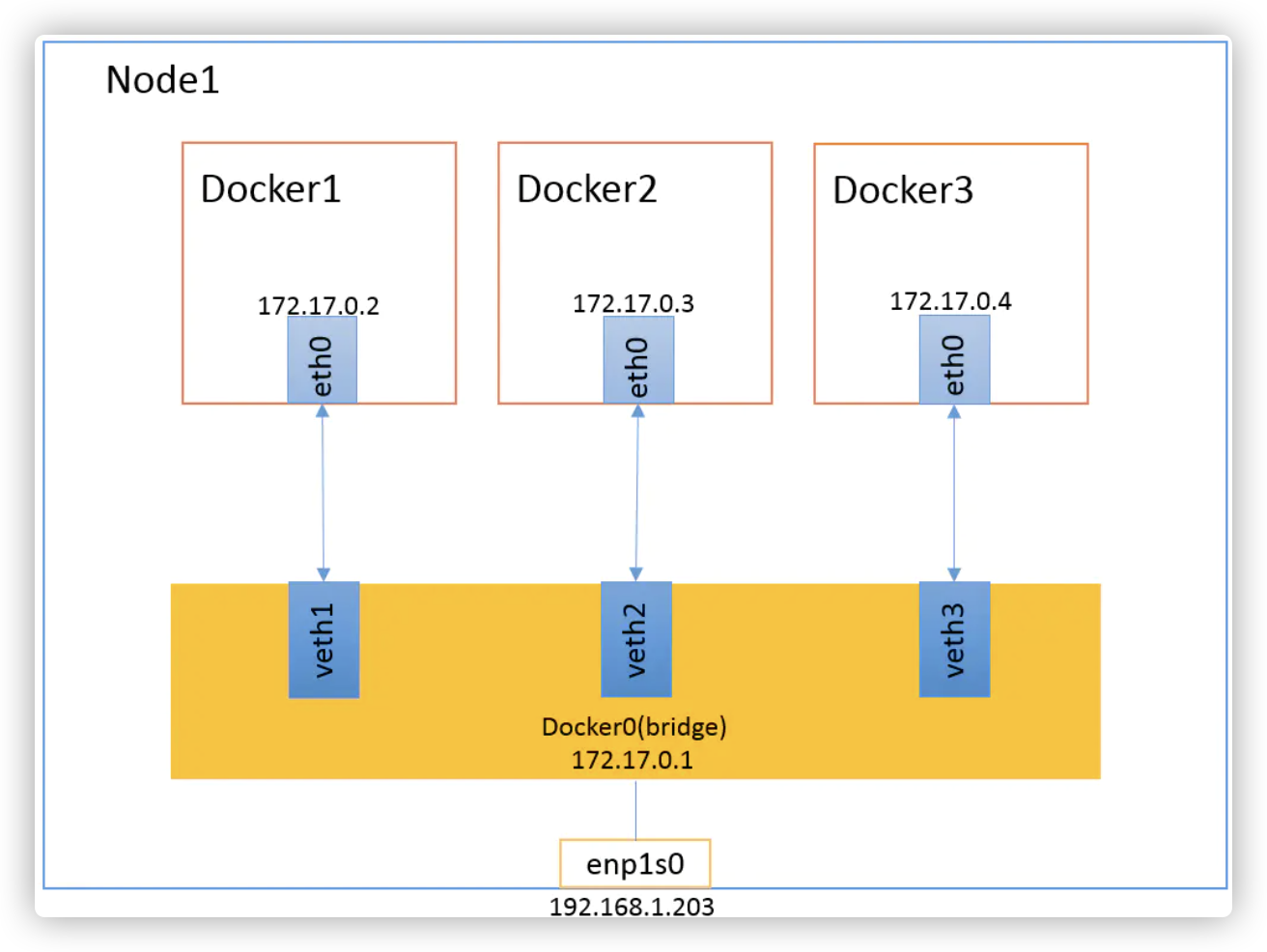
当docker启动后,会在主机上创建一个名为docker0的虚拟网桥,此主机上的docker容器会连接到这个虚拟网桥上。虚拟网桥的工作方式和物理交换机类似,这样主机上的所有容器就通过交换机连在了一个二层网络中。
从docker0子网中分批额一个IP给容器使用,并设置docker0的IP地址为容器的默认网关。在主机上创建一堆虚拟网卡veth pair设备,docker将veth pair设备的一端放在新创建的容器中,并命名为eth0(容器的网卡),另一端放在主机中,以vethxx这样的名字命名,并将这个网络设备加入到docker0网桥中。可以通过brctl show命令查看。
bridge模式是docker的默认网络模式,不写--net参数,就是bridge模式。使用docker run -p时,docker实际是在iptables做了DNAT规则,实现端口转发功能。可以使用iptables -t nat -vnL查看
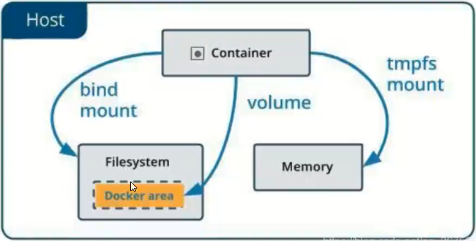
八)支持的三种数据持挂载方式
docker提供了三种不同的方式将数据从宿主机挂载到容器中,volume、bind mount、tmps mount
- bind mount:可以存储在宿主机系统的任意位置
-
- 例:docker run -v /opt/html:/usr/share/nginx/html -p 81:80 -d --name nginx_bind nginx:latest
- 缺点:被挂载的宿主机目录(或文件)不受保护,任何容器都可以取随意修改
- 注意:若使用bind mounts挂载宿主机目录到一个容器中的非空目录,那么此容器中的非空目录中的文件会被隐藏,容器只能访问到的文件均来自宿主机目录
- volume:docker管理宿主机文件系统的一部分(/var/lib/docker/volumes)
docker volume create nginx-volume docker volume ls docker run --mount type=volume,source=nginx-volume,destination=/usr/share/nginx/html,readonly -p 82:80 -d --name nginx_volume nginx:latest
若强制删除容器后,数据卷不会被删除,还是会保存在宿主机的docker/volumes目录下
- tmpfs mounts:挂载存储在宿主机系统的内存中,不会写入宿主机的文件系统
- docker run --mount type=tmpfs,destination=/usr/share/nginx/html -p 83:80 -d --name nginx_tmpfs nginx:latest
对比docker三种挂载方式
| bind(-v) | volume | tmpfs | |
| volume位置 | 可指定任意位子 | $(docker_data_dir)/docker/volumes/... | 宿主机内存中 |
| 对已有 mount point影响 | 隐藏并替换为volume | 原有数据复制到volume | |
| 是否支持单个文件 | 支持 | 不支持,只能是目录 | |
| 权限控制 | 可设置为只读,默认为读写权限 | 可设置为只读,默认为读写权限 | |
| 移植性 | 移植性弱,与host path绑定 | 移植性强,无须指定host目录 | |
| 是否支持持久化 | 支持 | 支持 | 不支持 |
| 应用场景 | 主机和容器共享配置文件(docker默认情况下,通过这种方式为容器提供DNS解析,将/etc/resolv.conf挂载到容器中) | 多个运行容器间共享数据 备份、恢复或将数据从一个docker迁移到另一个docker主机 | 既不想将数据存在宿主机中,也不想存于容器中(出于安全考虑,或当演员需要些大量非持久性的状态数据时为了保护容器的性能) |
Bind 模式无法很好地解决多跨宿主机共享存储的问题、Bind 模式的管理问题等。
提出 Volume 的最核心的目的是提升Docker对不同存储介质的支撑能力,这同时也可以减轻Docker本身的工作量。存储不仅有挂载在宿主机上的物理存储,还有网络存储,Docker 抽象出了存储启动(Sotroage Driver)来去解决对网络存储的读写问题
九)docker的应用场景
- web应用的自动化打包发布
- 自动化测试和持续集成、发布
- 在服务型环境中部署调整数据库或其他的后台应用
- 从头编译或扩展现有的OpenShift或cloud Foundry平台来搭建自己的PaaS环境
四、安装指定版本docker
1、查看系统要求 Docker 要求 CentOS 系统的内核版本高于 3.10 ,查看CentOS的内核版本。 uname -a 2、删除旧版本 yum remove docker docker-common docker-selinux docker-engine 3、安装需要的软件包 yum-util 提供yum-config-manager功能,另外两个是devicemapper驱动依赖的 sudo yum install -y yum-utils device-mapper-persistent-data lvm2 4、设置Docker yum源 sudo yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo 5、查看所有仓库中所有docker版本 可以查看所有仓库中所有docker版本,并选择特定的版本安装。 yum list docker-ce --showduplicates | sort -r 6、安装docker sudo yum install docker-ce 由于repo中默认只开启stable仓库,故这里安装的是最新稳18.03.0.ce-1.el7.centos。 如果要安装特定版本: sudo yum install docker-ce-18.06.1.ce 7、启动 设置为开机启动 systemctl enable docker 启动 systemctl start docker 查看启动状态 systemctl status docker 查看版本 docker version
五、docker相关命令
docker官方文档:https://docs.docker.com/engine/reference/run/

一)docker帮助命令
docker info #查看docker相关的信息 docker version #查看安装docker的版本信息 docker help #docker命令的帮助信息
二)docker 镜像相关的命令
docker images #列出本地的所有镜像 docker search imagesname/imageid #搜索镜像 注意,即使你配置了阿里云加速,docker search命令查找的网站默认还是 https://hub.docker.com。阿里云加速只是下载时才会被用到。 -s starts超过多少的镜像 docker pull imagesname/imageid #下载镜像 -s starts超过多少的镜像 docker rmi imagesname/imageid #删除镜像,默认基于这个镜像还有正在运行的镜像是删除不了的,需要加上-f参数强制删除 删除多个:docker rmi -f 镜像1:tag 镜像2:tag,不写tag,删除的就是latest 删除全部:docker rmi -f $(docker images -qa) docker save 命令可以将镜像保存为归档文件:docker save alpine | gzip > alpine-latest.tar.gz docker load 命令可以将保存的镜像加载到本地docker里面:docker load -i alpine-latest.tar.gz docker tag #给镜像打标签 docker tag mysql:5.7.22 docker-registry:5000/mysql:5.7.22
三)docker 容器相关的命令
1、以交互性启动容器:docker run -it
docker run -it --name='容器新名字':为容器指定一个别名; -d:后台运行容器,并返回容器ID,也就是启动守护式容器; -i:以交互式模式运行容器,通常与-t同时使用; -t:tty,为容器重新分配一个伪终端,通常与-i同时使用; -P:随机端口映射; -p:指定端口映射,有以下四种格式: -v /宿主机绝对路径目录:/容器内目录 镜像名
镜像添加存储卷
1、查看数据卷是否挂载成功
docker inspect 8ad4df9ec2fd
2、验证容器和宿主机之间数据共享
在/myDataVolume和/dataVolumeContainer上各创建文件,都能互相看到。
3、容器停止退出后,主机修改后数据是否同步
答案:还同步
4、带权限的数据卷
命令:docker run -it -v /宿主机绝对路径目录:/容器内目录:ro 镜像名
说明:-v是volume卷的意思
宿主机绝对目录和容器内目录都不用提前建立
ro:是read only的意思
2、查看容器运行情况:docker ps
参数
-a:列出当前所有正在运行的容器+历史上运行过的; -l:last,显示最近创建的容器; -n:显示最近n个创建的容器; -q:静默模式,只显示容器编号 --no-trunc:不截断输出 -d 以守护式方式启动的容器
3、查看容器日志
命令格式:docker logs -f -t --tail 容器id
参数说明:
-t是加入时间戳
-f是跟随最新的日志打印
--tail是Linux命令,表示显示最后多少条
docker logs -t --help
Usage: docker logs [OPTIONS] CONTAINER
Fetch the logs of a container
Options:
--details Show extra details provided to logs
-f, --follow Follow log output
--since string Show logs since timestamp (e.g. 2013-01-02T13:23:37) or relative (e.g. 42m for 42 minutes)
--tail string Number of lines to show from the end of the logs (default "all")
-t, --timestamps Show timestamps
--until string Show logs before a timestamp (e.g. 2013-01-02T13:23:37) or relative (e.g. 42m for 42 minutes)
4、查看容器内的进程
命令格式:docker top 容器id
5、查看容器内的细节
以json形式返回
命令格式:docker inspect 容器id
6、进入正在运行的容器并以命令行交互
以下两种方式
1 docker exec -it 容器id bash shell 2 docker attach 容器id
docker exec与docker attach的区别
- attach:直接进入容器启动命令的终端,不会启动新的进程;
- 当多个窗口同时用attach命令连到同一个容器的时候,所有窗口都会同步显示。当某个窗口因命令阻塞时,其他窗口也无法执行操作了。
- exec:是在容器中打开新的终端,并且可以启动新的进程。
- 通过指定-it参数来保持标准输入打开,并且分配一个伪终端。通过exec命令对容器进行操作是最推荐的方式。
7、从容器内拷贝文件到宿主机上
命令格式:docker cp 容器id或容器名:容器内路径 目的宿主机路径
应用场景:当我们以前台交互式方式运行容器后,如果在容器里面执行exit操作,容器就会停止,此时容器中运行的数据也就没有了。这时我们就需要把运行中的容器数据拷贝到宿主机上来保留。
8、从宿主机上拷贝文件到容器内
命令格式:docker cp 宿主机路径 容器id或容器名:容器内路径
9、容器生命周期管理
docker stop imagename/imageid #停止容器 docker start imagename/imageid #启动容器 docker restart imagename/imageid #重启容器 docker kill imagename/imageid #强制停止容器 docker rm imagename/imageid #删除容器 -f强制删除正在容器
10、批量操作容器和镜像
减少工作量,一劳永逸的方法就是将痛苦提前,先思考如何批量删除,以后就安装文本,直接操作。
可以知道删除 docker container 和 docker image 的关键都是找到准确的 ID。如果能批量提供 ID 号给删除命令,就能实现批量删除了。
批量获取容器和镜像的ID
批量获取容器的ID docker ps -a -q 或 docker container ls -aq 批量获取镜像的ID docker image ls -aq 7c03076402d9 7ae4e0670a3f
批量删除本机所有容器
docker rm -rf $(docker ps -aq) docker ps -a -q |xargs docker rm docker rm $(docker container ls -aq)
批量删除本机所有镜像
docker rmi $(docker image ls -aq) docker rmi $(docker images -q)
如果只想批量删除一部分容器或者镜像
将要删除的容器名写到一个文件中,然后根据提供的名字,再结合 grep 、awk 等命令,就可以轻松地获取准确的 ID 号了。只要获取了 ID 号,就可以用上面的方法将它们删除。
按条件删除镜像
没有打标签
docker rmi `docker images -q | awk '/^<none>/ { print $3 }'`
镜像名包含关键字
docker rmi --force `docker images | grep doss-api | awk '{print $3}'` //其中doss-api为关键字
11、将容器打成新的镜像
docker commit -m "change somth" -a "somebody info" container_id(docker ps -a获取id) 新镜像名字
12、进入node容器可实时查看当前运行容器负载状态
docker stats ef6dceff2557| grep -viE "disk|oss|nas|csi|POD|kube|node-exporter"
四)docker save与docker export的区别
1、docker save
docker save是用来将一个或多个image打包保存的工具。
docker save -o images.tar postgres:9.6 mongo:3.4
docker save可以指定image,可以指定container,docker save将保存的是容器背后的image。
将打包的镜像导入,若本地存在同名的镜像会覆盖
docker load -i images.tar
应用场景:如果你的应用是使用docker-compose.yml编排的多个镜像组合,但你要部署的客户服务器并不能连外网。这时,你可以使用docker save将用到的镜像打个包,然后拷贝到客户服务器上使用docker load载入。
2、docker export
docker export是用来将container的文件系统进行打包的(只能指定container)
docker export -o postgres-export.tar postgres
将打包的container载入进来使用docker import,可以指定tag
docker import postgres-export.tar postgres:latest
注意:
- docker import将container导入后会成为一个image,而不是恢复为一个container。
- 如果本地镜像库中已经存在同名的镜像,则原有镜像的名称将会被剥夺,赋给新的镜像。原有镜像将成为孤魂野鬼,只能通过IMAGE ID进行操作。
docker export的应用场景主要用来制作基础镜像:比如你从一个ubuntu镜像启动一个容器,然后安装一些软件和进行一些设置后,使用docker export保存为一个基础镜像。然后,把这个镜像分发给其他人使用
3、docker save和docker export的区别
- docker save保存的是镜像(image),docker export保存的是容器(container);
- docker load用来载入镜像包,docker import用来载入容器包,但两者都会恢复为镜像;
- docker load不能对载入的镜像重命名,而docker import可以为镜像指定新名称。
五)docker 的prune清理资源
1、docker system df 查看资源信息,RECLAIMABLE是可回收比例
# docker system df TYPE TOTAL ACTIVE SIZE RECLAIMABLE Images 291 41 101.3GB 93.2GB (92%) Containers 194 65 5.274GB 5.257GB (99%) Local Volumes 1 1 0B 0B Build Cache 0 0 0B 0B
查看帮助信息
docker system df -h
Flag shorthand -h has been deprecated, please use --help
Usage: docker system df [OPTIONS]
Show docker disk usage
Options:
--format string Pretty-print images using a Go template
-v, --verbose Show detailed information on space usage ##查看详情
2、docker system prune
查看帮助信息
# docker system prune -h
Flag shorthand -h has been deprecated, please use --help
Usage: docker system prune [OPTIONS]
Remove unused data
Options:
-a, --all Remove all unused images not just dangling ones
--filter filter Provide filter values (e.g. 'label=<key>=<value>')
-f, --force Do not prompt for confirmation
--volumes Prune volumes
清理磁盘,删除关闭的容器、无用的数据卷和网络,以及旧的镜像(无tag的镜像) -f免交互
在 Docker 17.06.1 及更高版本中必须为 docker system prune 命令明确指定 --volumes 标志才会修剪卷。
]# docker system prune WARNING! This will remove: - all stopped containers - all networks not used by at least one container - all dangling images - all dangling build cache Are you sure you want to continue? [y/N]
清理得更加彻底,可以将没有容器使用Docker镜像都删掉
# docker system prune -a WARNING! This will remove: - all stopped containers - all networks not used by at least one container - all images without at least one container associated to them - all build cache Are you sure you want to continue? [y/N]
3、清理镜像
清理none镜像 Prune命令
none镜像的产生和困惑
我们偶尔会看到 none镜像(虚悬镜像),那是因为
- 构建镜像过程中因为脚本错误导致很多镜像构建终止,产生很多none标签的版本
- 手动构建镜像的时候没有进行提交,遗留来的垃圾镜像
- 这些镜像占据较大的存储空间,需要删除
清理none镜像(虚悬镜像)
命令: docker image prune 默认情况下,docker image prune 命令只会清理 虚无镜像(没被标记且没被其它任何镜像引用的镜像
清理无容器使用的镜像
命令: docker image prune -a
默认情况下,系统会提示是否继续。要绕过提示,请使用 -f 或 --force 标志。
4、清理容器
停止容器后不会自动删除这个容器,除非在启动容器的时候指定了 –rm 标志。使用 docker ps -a 命令查看 Docker 主机上包含停止的容器在内的所有容器。你可能会对存在这么多容器感到惊讶,尤其是在开发环境。停止状态的容器的可写层仍然占用磁盘空间。要清理掉这
docker images prune -h
Flag shorthand -h has been deprecated, please use --help
Usage: docker images [OPTIONS] [REPOSITORY[:TAG]]
List images
Options:
-a, --all Show all images (default hides intermediate images)
--digests Show digests
-f, --filter filter Filter output based on conditions provided
--format string Pretty-print images using a Go template
--no-trunc Don't truncate output
-q, --quiet Only show numeric IDs
默认情况下,所有停止状态的容器会被删除。可以使用 --filter 标志来限制范围。例如,下面的命令只会删除 24 小时之前创建的停止状态的容器:
5、清理卷
# docker volume prune -h
Flag shorthand -h has been deprecated, please use --help
Usage: docker volume prune [OPTIONS]
Remove all unused local volumes
Options:
--filter filter Provide filter values (e.g. 'label=<label>')
-f, --force Do not prompt for confirmation
6、清理网络
Docker 网络不会占用太多磁盘空间,但是它们会创建 iptables 规则,桥接网络设备和路由表条目。要清理这些东西,可以使用 docker network prune 来清理没有被容器未使用的网络。
# docker network prune -h
Flag shorthand -h has been deprecated, please use --help
Usage: docker network prune [OPTIONS]
Remove all unused networks
Options:
--filter filter Provide filter values (e.g. 'until=<timestamp>')
-f, --force Do not prompt for confirmation
六、dockerfile保留字指令
http://blog.itpub.net/28916011/viewspace-2213324/
一)自定义镜像时,建议思考一下几点
- 精简镜像用途:尽量让每个镜像的用途比较集中、单一,避免构造大而复杂、多功能的镜像
- 选用合适的基础镜像:过大的基础镜像会造成生成臃肿的镜像,一般推荐较为小巧的debian镜像
- 提供足够清晰的命令注释和维护者信息:dockerfile也是一种代码,需要考虑方便后面扩展和他人使用
- 正确的使用版本号:使用版本号信息,如1.0,2.0,而非latest,将避免内容不一致可能引发的惨案
- 减少镜像层数:若希望所生成的镜像层数尽量少,则要尽量合并指令,例如多个RUN指令可以合并成一条
- 及时删除临时文件和缓存文件:特别是在执行apt-get指令后,/var/cache/apt下面会缓存一些安装包
- 提高生成速度:如合理使用缓存,减少内容目录下的文件,或使用.dockerignore文件指定等
- 调整合理的指令顺序:在开启缓存的情况下,内容不变的指令尽量放在前面,这样可以复用
- 减少外部源的干扰:若确认需要从外部引入数据,需要指定持久的地址,并带有版本信息,让他人可以重复而不出错
二)操作系统基础镜像
BusyBox、Alphine、Debian/Ubuntu、CentOS等
选择操作系统基础镜像需要注意:
- 官方镜像体积都比较小,之带有一些基本的组件。精简的系统有利于安全、稳定和高效运行,也适合进行定制
- 个别第三方镜像(如tutum,已被docker收购),质量也非常高。这些镜像通常针对于应用进行配置。
- 处于安全考虑,几乎所有官方制作的镜像几乎没有安装SSH服务,无法使用用户名和密码直接登录
注意点:
- Dockfile中可以有多个CMD指令,但只有最后一个生效。
- ADD与COPY的区别:本地目录为源目录
- ADD src可以为URL;若是tar文件,会自动解压到dest路径下
- COPY只是复制,推荐使用COPY
- HEALTHCHECK健康检查
- 使用.dockerignore文件来让docker忽略匹配模块路径下的目录和文件(每一行添加一条匹配模式)
七、容器在生产环境实践
注意:
- 若docker出现不可控的风险,是否考虑到了备选的解决方案
- 是否需要对docker容器进行资源限制,以及如何限制(如CPU、内存、网络、磁盘等)
- docker对容器的安全管理做的不够完善,在应用到生产环境之前可以使用第三方工具来加强容器的安全管理。如使用apparmor对容器的能力进行限制、使用更加严格的iptable规则、禁止root登录、限制普通用户权限以及做好系统日志的记录
- 公司内部私有仓库的管理、镜像的管理问题是否解决。目前官方提供的私有仓库管理工具功能并不十分完善。harbor了解一下
一)问题汇总
1、解决镜像无法删除的问题multiple repositories
Error response from daemon: conflict: unable to delete ea5f89e79b1e (must be forced) - image is referenced in multiple repositories 意思是说,存在镜像多个引用,即同一个image id有多个repo。需要注意,自己是否真的确定要删除! 可以通过docker rmi $REPO/$NAME:$VERSION方式删除。
二)扩展知识点
1、如何查看docker容器的启动命令
1.安装runlike
curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py
python get-pip.py # 运行安装脚本
pip install runlike 2.执行命令 runlike -p 容器ID
2、docker以root身份登录容器
# 前言
在部署服务的过程中,会遇到进到的容器内部,不是以root的身份,如果我们需要进行在容器内部执行命令,就会出现权限的问题,比如:如下显示
> bash-4.2$ cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
- cp: cannot create regular file ‘/etc/localtime’: Permission denied
#### 解决办法
以root身份进入容器内部,命令如下:
> docker exec --privileged -u root -it 容器名字/容器id /bin/bash{sh}(bash{sh})
3、 查看构建docker镜像的完整命令(dockerfile每个步骤内容)
# 查看构建镜像的完整命令 docker history centos:7 --no-trunc

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









