









一、消息系统概述
一)消息系统按消息发送模型分类
1、peer-to-peer(单播)
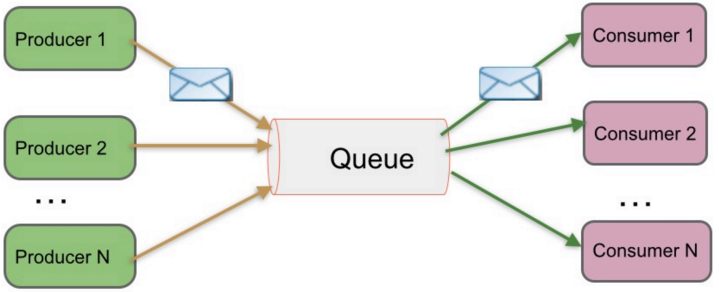
特点:
- 一般基于pull或polling接收消息
- 发送对队列中的消息被一个而且仅仅一个接收者所接收,即使有多个接收者在同一队列中侦听同一消息
- 即支持异步“即发即弃”的消息传送方式,也支持同步请求/应答传送方式
2、发布/订阅(支持单播和多播)
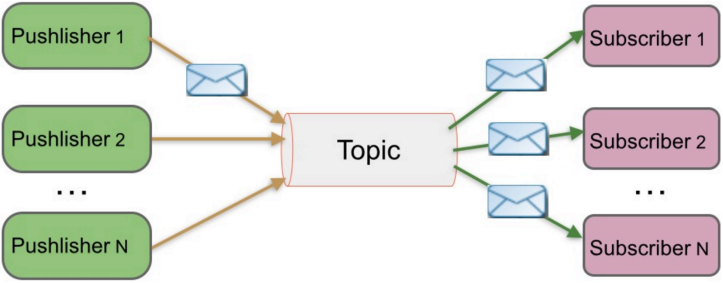
特点:
- 发布到一个主题的消息,可被多个订阅者所接收
- 发布/订阅可基于push消费数据,也可基于pull或者polling消费数据
- 解耦能力比P2P模型更强
二)消息系统使用场景
- 解耦 各位系统之间通过消息系统这个统一的接口交换数据,无须了解彼此的存在
- 冗余 部分消息系统具有消息持久化能力,可规避消息处理前丢失的风险
- 扩展 消息系统是统一的数据接口,各系统可独立扩展
- 峰值处理能力 消息系统可顶住峰值流量,业务系统可根据处理能力从消息系统中获取并处理对应量的请求
- 可恢复性 系统中部分组件失效并不会影响整个系统,它恢复后仍然可从消息系统中获取并处理数据
- 异步通信 在不需要立即处理请求的场景下,可以将请求放入消息系统,合适的时候再处理
三)常用的消息系统对比
1、RabbitMQ
Erlang编写,支持多协议 AMQP,XMPP,SMTP,STOMP。 支持负载均衡、数据持久化。同时支持Peer-to-Peer和发布/订阅模式
使用场景:比较重量级,企业开发中。
2、Redis
基于Key-Value对的NoSQL数据库,同时支持MQ功能,可做轻量级队列服务使用。就入队操作而言,Redis对短消息(小于10KB)的性能比RabbitMQ好,长消息的性能比RabbitMQ差。
3、ZeroMQ
轻量级,不需要单独的消息服务器或中间件,应用程序本身扮演该角色,Peer-to-Peer。它实质上是一个库,需要开发人员自己组合多种技术,使用复杂度高。
特点:不支持数据的持久化,很难做到异步发送,做到的是点对点异步缓存。
4、ActiveMQ
JMS实现,Peer-to-Peer,支持持久化、 XA事务
5、Kafka/Jafka
高性能跨语言的分布式发布/订阅消息系统,数据持久化,全分布式,同时支持在线和离线处理
7、MetaQ/RocketMQ
纯Java实现,发布/订阅消息系统,支持本地事务和XA分布式事务
二、kafka
http://www.jasongj.com/tags/Kafka/
一)kafka概述
1、kafka简介
Apache Kafka是分布式发布-订阅消息系统,在 kafka官网上对 kafka 的定义:一个分布式发布-订阅消息传递系统。 它最初由LinkedIn公司开发,Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。Kafka是一种快速、可扩展的、设计内在就是分布式的,分区的和可复制的提交日志服务。
2、kafka的设计目标
- 高吞吐量、低延迟:在廉价的商用机器上单机可支持每秒100万条消息的读写
- 消息持久化、可靠性:所有消息均被持久化到磁盘,无消息丢失,支持消息重放
- 可扩展性,完全分布式:producer、broker、consumer均支持水平扩展
- 高并发:支持数千个客户端同时读写
- 容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败)
- 同时满足适应在线流处理和离线批处理
3、kafka2.0.0版本新增改变了哪些功能详细
kafka2.0.0版本新增改变了哪些功能详细:http://www.aboutyun.com/forum.php?mod=viewthread&tid=24981
4、kafka的适应场景
- 日志收集:一个公司可以用Kafka可以收集各种服务的log,通过kafka以统一接口服务的方式开放给各种consumer,例如hadoop、Hbase、Solr等。
- 消息系统:解耦和生产者和消费者、缓存消息等。
- 用户活动跟踪:Kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后订阅者通过订阅这些topic来做实时的监控分析,或者装载到hadoop、数据仓库中做离线分析和挖掘。
- 运营指标:Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告。
- 流式处理:比如spark streaming和storm
- 事件源
5、kafka最详细原理总结
http://www.itkeyword.com/doc/3033455819328241799/kafka-apache-scala
二)kafka架构
1、kafka架构图
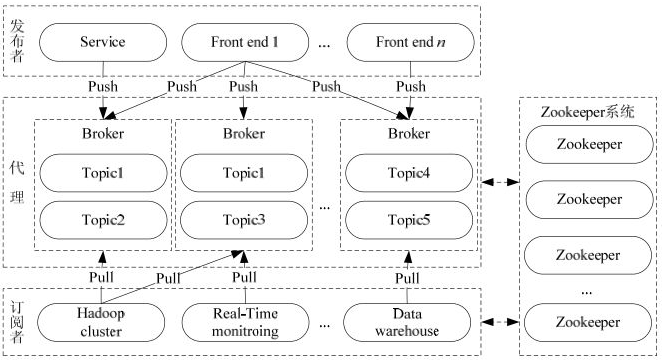
2、kafka架构组件
- 话题(Topic):是特定类型的消息流。消息是字节的有效负载(Payload),话题是消息的分类名或种子(Feed)名;
- 生产者(Producer):是能够发布消息到话题的任何对象;
- 服务代理(Broker):已发布的消息保存在一组服务器中,它们被称为代理(Broker)或Kafka集群;
- 消费者(Consumer):可以订阅一个或多个话题,并从Broker拉数据,从而消费这些已发布的消息;
1、topic
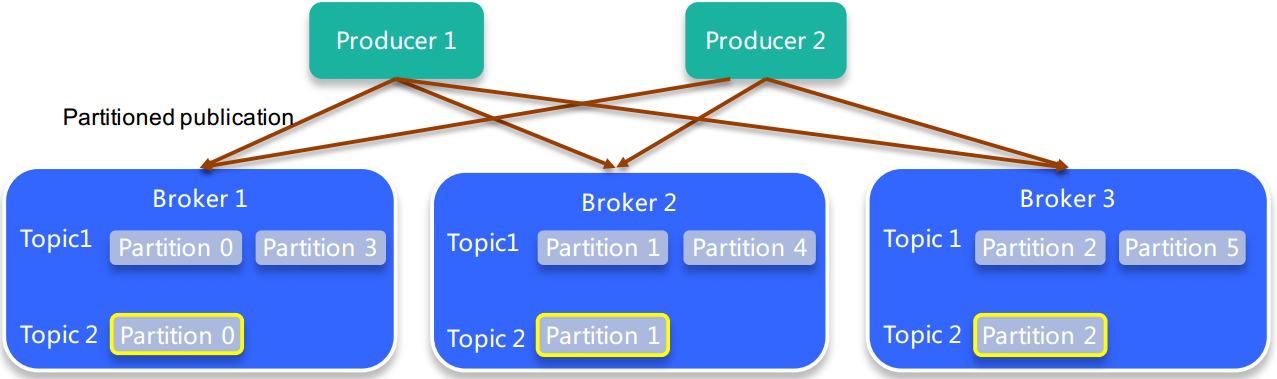
- 逻辑概念:同一个topic的消息可分布在一个或多个节点(broker)上
- 一个topic包含一个或者多个partition(partition均匀分布在集群中)
- 每条消息都属于且仅属于一个topic
- producer发布数据时,必须指定将改消息发布到哪一个topic
- consumer订阅消息时,也必须指定订阅那个topic的消息
2、partition
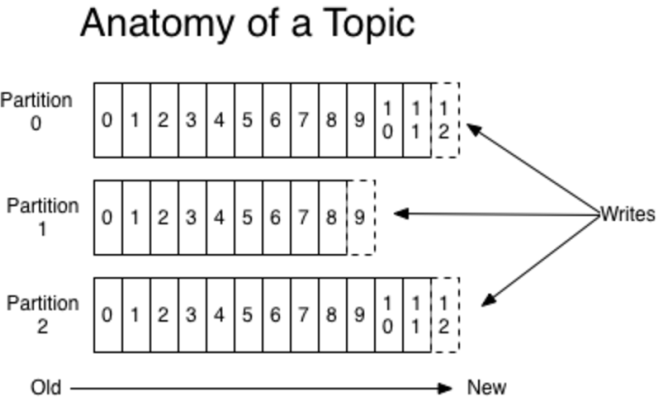
- 物理概念:一个partition只分布在一个broker上(不考虑备份的情况)
- 一个partition物理上对应一个文件夹
- 一个partition包含多个segment(线段、部分)
- 一个segment对应一个文件
- segment由一个个不可变记录组成
- 记录只会被append到segment中,不会被单独删除或者修改
- 清除过期日志时,直接删除一个或多个segment
kafka的最小物理单位是partition,所以offset是记录在partition中的(segment index中),那么partition是跨机器的,offset的是partiton内管理的。
kafka 提供两种分配策略 range和roundrobin,由参数partition.assignment.strategy指定,默认是range策略。本文只讨论range策略。所谓的range其实就是按照阶段平均分配。
3、sync(同步) producer和async(异步) producer
1、sync producer特点
- 低延迟
- 低吞吐率
- 无数据丢失
2、async producer特点
- 高延迟
- 高吞吐率
- 可能会有数据丢失
4、consumer和partition
kafka的配置要点:https://yq.aliyun.com/ziliao/417900
更多内容见:http://www.open-open.com/lib/view/open1434551761926.html
- 如果consumer比partition多,是浪费,因为kafka的设计是在一个partition上是不允许并发的,所以consumer数不要大于partition数
- 如果consumer比partition少,一个consumer会对应于多个partitions,这里主要合理分配consumer数和partition数,否则会导致partition里面的数据被取的不均匀
- 如果consumer从多个partition读到数据,不保证数据间的顺序性,kafka只保证在一个partition上数据是有序的,但多个partition,根据你读的顺序会有不同
- 增减consumer,broker,partition会导致rebalance,所以rebalance后consumer对应的partition会发生变化
- High-level接口中获取不到数据的时候是会block的
三)单点版kafka的安装使用
1、kafka部署方式
- 在虚拟机上部署kafka
- 使用kafka带的zookeeper起kafka:适用单独部署kafka
- 使用单独的zookeeper起kafka:公司架构已有zookeeper
- 使用docker部署kafka
- 使用kafka带的zookeeper起kafka:适用单独部署kafka
- 使用单独的zookeeper起kafka:公司架构已有zookeeper
2、下载kafka
kafka下载最新版地址:Apache Kafka
kafka下载指定版本:Index of /dist/kafka
zookeeper下载地址:Index of /apache/zookeeper/stable
下载二进制包
wget http://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.0.0/kafka_2.11-2.0.0.tgz
wget https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/stable/zookeeper-3.4.12.tar.gz3、kafka的目录结构
kafka_2.11-2.0.0
├── bin
├── config
├── libs
├── LICENSE
├── NOTICE
└── site-docs
4 directories, 2 fileskafka配置文件
############################# Server Basics
# The id of the broker. This must be set to a unique integer for each broker.
broker.id=0
# Switch to enable topic deletion or not, default value is false
delete.topic.enable=true
############################# Socket Server Settings
# FORMAT:
# listeners = listener_name://host_name:port
# EXAMPLE:
# listeners = PLAINTEXT://your.host.name:9092
listeners=PLAINTEXT://kafka01.test.com:9092
# Hostname and port the broker will advertise to producers and consumers. If not set,
# it uses the value for "listeners" if configured. Otherwise, it will use the value
# returned from java.net.InetAddress.getCanonicalHostName().
advertised.listeners=PLAINTEXT://kafka01.test.com:9092
# The number of threads that the server uses for receiving requests from the network and sending responses to the network
num.network.threads=3
# The number of threads that the server uses for processing requests, which may include disk I/O
num.io.threads=8
# The send buffer (SO_SNDBUF) used by the socket server
socket.send.buffer.bytes=102400
# The receive buffer (SO_RCVBUF) used by the socket server
socket.receive.buffer.bytes=102400
# The maximum size of a request that the socket server will accept (protection against OOM)
socket.request.max.bytes=104857600
############################# Log Basics
# A comma seperated list of directories under which to store log files
log.dirs=/opt/ytd_data01/kafka
num.partitions=5
# This value is recommended to be increased for installations with data dirs located in RAID array.
num.recovery.threads.per.data.dir=1
############################# Internal Topic Settings
# For anything other than development testing, a value greater than 1 is recommended for to ensure availability such as 3.
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
############################# Log Flush Policy
# The number of messages to accept before forcing a flush of data to disk
#log.flush.interval.messages=10000
# The maximum amount of time a message can sit in a log before we force a flush
#log.flush.interval.ms=1000
############################# Log Retention Policy
# The minimum age of a log file to be eligible for deletion due to age
log.retention.hours=24
# segments don't drop below log.retention.bytes. Functions independently of log.retention.hours.
#log.retention.bytes=1073741824
# The maximum size of a log segment file. When this size is reached a new log segment will be created.
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
############################# Zookeeper
# root directory for all kafka znodes.
zookeeper.connect=zk01.test.com:2181,zk02.test.com:2181,zk03.test.com:2181
# Timeout in ms for connecting to zookeeper
zookeeper.connection.timeout.ms=6000
############################# Group Coordinator Settings
group.initial.rebalance.delay.ms=04、四种部署方式
1、在虚拟上部署
使用kafka带的zookeeper起kafka
cd /opt/ytd_soft
wget http://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.0.0/kafka_2.11-2.0.0.tgz
tar xvf kafka_2.11-2.0.0.tgz
cd kafka_2.11-2.0.0
#zookeeper默认是前台启动,让其后台启动使用nohup command &&
#前台启动
#./bin/zookeeper-server-start.sh config/zookeeper.properties
#后台启动
nohup ./bin/zookeeper-server-start.sh config/zookeeper.properties &&
ss -lutnp |grep 2181
#启动kafka,默认非daemon启动,-daemon启动
./bin/kafka-server-start.sh -daemon config/server.properties
ss -lutnp|grep 9092测试kafka是否可用
#创建topic
# cd /opt/ytd_soft/kafka_2.11-2.0.0
# bin/kafka-topics.sh --zookeeper localhost:2181 --create --topic test1 --partitions 3 --replication-factor 1
Created topic "test1".
#查看topic详情
# bin/kafka-topics.sh --zookeeper localhost:2181 --describe --topic test1
Topic:test1 PartitionCount:3 ReplicationFactor:1 Configs:
Topic: test1 Partition: 0 Leader: 0 Replicas: 0 Isr: 0
Topic: test1 Partition: 1 Leader: 0 Replicas: 0 Isr: 0
Topic: test1 Partition: 2 Leader: 0 Replicas: 0 Isr: 0
#模拟消费者consumer(kafka之前的版本参数是:bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning)
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test1 --from-beginning
#另外一个窗口,模拟生产者producer
# cd /opt/ytd_soft/kafka_2.11-2.0.0
# bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test1
>11
>111
>222使用单独的zookeeper起kafka
安装启动zookeeper
cd /opt/ytd_soft
wget https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/stable/zookeeper-3.4.12.tar.gz
tar xvf zookeeper-3.4.12.tar.gz
cd zookeeper-3.4.12/
bin/zkServer.sh start conf/zoo_sample.cfg
bin/zkServer.sh status conf/zoo_sample.cfg
ss -lutnp|grep 2181部署kafka,更改kafka配置文件server.properties(若zookeeper是集群或zookeeper不在本机上必须更改),其他步骤和上面的一样
zookeeper.connect=localhost:2181
2、使用docker部署(自己创建镜像)
使用kafka带的zookeeper起kafka
使用kafka带的zookeeper起kafka
部署zookeeper
jdk和zookeeper创建镜像时下载
FROM centos:7.9
RUN cp -rp /etc/yum.repos.d/CentOS-Base.repo{,.bak} && curl -o /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-6.repo
RUN yum -y install vim lsof wget tar bzip2 unzip vim-enhanced passwd sudo yum-utils hostname net-tools rsync man git make automake cmake patch logrotate python-devel libpng-devel libjpeg-devel pwgen python-pip
RUN mkdir /opt/java &&\
wget --no-check-certificate --no-cookies --header "Cookie: oraclelicense=accept-securebackup-cookie" http://download.oracle.com/otn-pub/java/jdk/8u191-b12/2787e4a523244c269598db4e85c51e0c/jdk-8u191-linux-x64.tar.gz -P /opt/java
RUN tar zxvf /opt/java/jdk-8u191-linux-x64.tar.gz -C /opt/java &&\
JAVA_HOME=/opt/java/jdk1.8.0_191 &&\
sed -i "/^PATH/i export JAVA_HOME=$JAVA_HOME" /root/.bash_profile &&\
sed -i "s%^PATH.*$%&:$JAVA_HOME/bin%g" /root/.bash_profile &&\
source /root/.bash_profile
ENV ZOOKEEPER_VERSION "3.4.12"
RUN mkdir /opt/zookeeper &&\
wget http://mirror.olnevhost.net/pub/apache/zookeeper/zookeeper-$ZOOKEEPER_VERSION/zookeeper-$ZOOKEEPER_VERSION.tar.gz -P /opt/zookeeper
RUN tar zxvf /opt/zookeeper/zookeeper*.tar.gz -C /opt/zookeeper
RUN echo "source /root/.bash_profile" > /opt/zookeeper/start.sh &&\
echo "cp /opt/zookeeper/zookeeper-"$ZOOKEEPER_VERSION"/conf/zoo_sample.cfg /opt/zookeeper/zookeeper-"$ZOOKEEPER_VERSION"/conf/zoo.cfg" >> /opt/zookeeper/start.sh &&\
echo "/opt/zookeeper/zookeeper-$"ZOOKEEPER_VERSION"/bin/zkServer.sh start-foreground" >> /opt/zookeeper/start.sh
EXPOSE 2181
ENTRYPOINT ["sh", "/opt/zookeeper/start.sh"]
部署kafka(jdk和kafka安装包提前下载)
FROM centos:7.9
ENV KAFKA_VERSION "2.11-2.0.0"
RUN cp -rp /etc/yum.repos.d/CentOS-Base.repo{,.bak} && curl -o /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-6.repo
RUN yum -y install vim lsof wget tar bzip2 unzip vim-enhanced passwd sudo yum-utils hostname net-tools rsync man git make automake cmake patch logrotate python-devel libpng-devel libjpeg-devel pwgen python-pip
RUN mkdir /opt/java
ADD jdk-8u191-linux-x64.tar.gz /opt/java
RUN JAVA_HOME=/opt/java/jdk1.8.0_191 &&\
sed -i "/^PATH/i export JAVA_HOME=$JAVA_HOME" /root/.bash_profile &&\
sed -i "s%^PATH.*$%&:$JAVA_HOME/bin%g" /root/.bash_profile &&\
source /root/.bash_profile
RUN mkdir /opt/kafka
ADD kafka_$KAFKA_VERSION.tgz /opt/kafka
RUN sed -i 's/num.partitions.*$/num.partitions=3/g' /opt/kafka/kafka_$KAFKA_VERSION/config/server.properties
RUN echo "source /root/.bash_profile" > /opt/kafka/start.sh &&\
echo "cd /opt/kafka/kafka_"$KAFKA_VERSION >> /opt/kafka/start.sh &&\
echo "sed -i 's%zookeeper.connect=.*$%zookeeper.connect=zookeeper:2181%g' /opt/kafka/kafka_"$KAFKA_VERSION"/config/server.properties" >> /opt/kafka/start.sh &&\
echo "bin/kafka-server-start.sh config/server.properties" >> /opt/kafka/start.sh &&\
chmod a+x /opt/kafka/start.sh
EXPOSE 9092
ENTRYPOINT ["sh", "/opt/kafka/start.sh"]创建镜像
cd /opt/kafka/dockerfile
docker build -t zookeeper:v1.1 -f zookeeper.dockerfile .
docker build -t kafka:v1.0 -f kafka.dockerfile .启动kafka和zookeeper容器,先启动zookeeper
docker images|egrep "zookeeper|kafka"
docker run -itd --name zookeeper -h zookeeper -p 2181:2181 zookeeper:v1.1 /bin/bash
#--link 关联容器
docker run -itd --name kafka -h kafka -p 9092:9092 --link zookeeper kafka:v1.0 /bin/bash
ss -lutnp|egrep "2181|9092"测试kafka的可用性
docker exec -it kafka /bin/bash
source /root/.bash_profile
#创建topic
cd /opt/kafka/kafka_2.11-2.0.0
bin/kafka-topics.sh --zookeeper zookeeper:2181 --create --topic test1 --partitions 3 --replication-factor 1
bin/kafka-topics.sh --zookeeper zookeeper:2181 --create --topic test2 --partitions 3 --replication-factor 1
#查看topic详情
bin/kafka-topics.sh --zookeeper zookeeper:2181 --describe --topic test2
bin/kafka-topics.sh --zookeeper zookeeper:2181 --describe --topic test1
#起consumer(注意版本差异,有可能参数不同)
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test1 --from-beginning
#单开一个会话,起producer(输入测试数据,看consumer是否全部接收)
docker exec -it kafka /bin/bash
source /root/.bash_profile
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test1四)kafka 高可用
1、CAP理论(原则或定理)
CAP理论和BASE理论详细信息见链接:https://www.cnblogs.com/duanxz/p/5229352.html
1、简述CAP理论
CAP原则又称CAP定理,指的是在一个分布式系统中, Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性),三者不可得兼。
CAP原则是NOSQL数据库的基石。Consistency(一致性)。 Availability(可用性)。Partition tolerance(分区容错性)。
分布式系统的CAP理论:理论首先把分布式系统中的三个特性进行了如下归纳:
- 一致性(C):在分布式系统中的所有数据备份,在同一时刻是否同样的值。(等同于所有节点访问同一份最新的数据副本)
- 通过某个节点的写操作结果对后面通过其他节点的读操作可见
- 若更新数据后,并发访问情况下可立即感知该更新,称为强制一致性
- 若允许之后部分或者全部感知不到该更新,称为弱一致性
- 若之后的一段时间(通常该事件不固定)后,一定可以感知该更新,称为最终一致性
- 可用性(A):在集群中一部分节点故障后,集群整体是否还能响应客户端的读写请求。(对数据更新具备高可用性)
- 任何一个个没有发生故障的节点,必须在有限的时间内返回合理的结果
- 分区容忍性(P):以实际效果而言,分区相当于对通信的时限要求。系统如果不能在时限内达成数据一致性,就意味着发生了分区的情况,必须就当前操作在C和A之间做出选择。
- 部分节点宕机或者无法与节点通信时,各分区间还可保持分布式系统的功能
2、CAP理论特征
CAP理论:分布式系统中,一致性、可用性、分区容忍性最多只可同时满足两个
一般分区容忍性都要求有保障,因此很多时候在可用性与一致性之间做权衡。
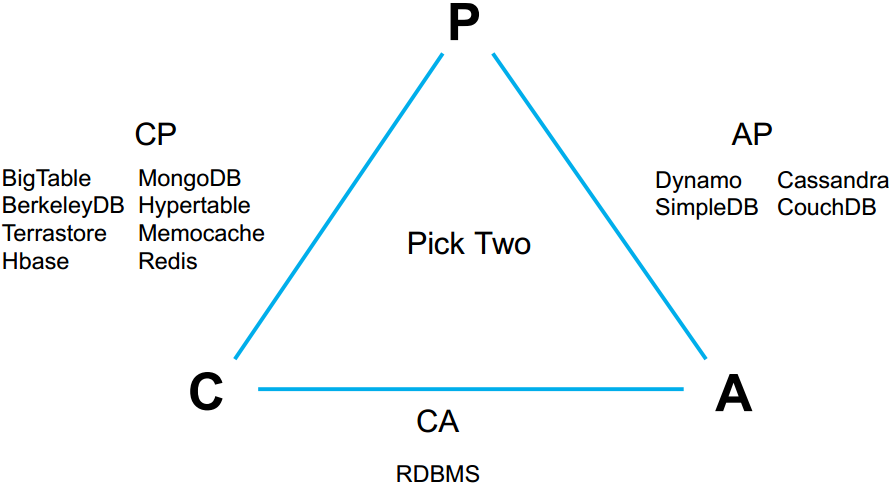
2、一致性方案
1、master-slave
- RDBMS的读写分离是典型的master-slave方案
- 同步复制可保证一致性,但会影响可用性
- 异步复制可提高可用性,但会降低一致性
2、WNR
- 主要用于去中心话(P2P)的分布式系统中。dynamoDB和Cassandra是采用此方案
- N代表副本数,W代表每次写操作要保证的最少写成功的副本数,R代表每次读至少读取的副本数
- 当W+R>N时,可保证每次读取的数据至少有一个副本具有最新的更新(大于)
- 多个写操作的顺序难以保证,可能导致多副本间的写操作书序不一致,dynamo通过向量适中保证最终一致性
3、paxos及其变种一致性算法(更多使用的是其变种)
- Google的chubby,zookeeper的Zab,RAFT
3、replica(复制使用pull)
- 当某个topic的replication-factor为N且N大于1时,每个partion都会有N个副本(replica)
- replica的个数小于等于broker数:对每个partition而言每个broker上只会有一个replica,因此broker ID表示replica
- 所有partition的所有replica默认情况会均匀分布到所有broker上
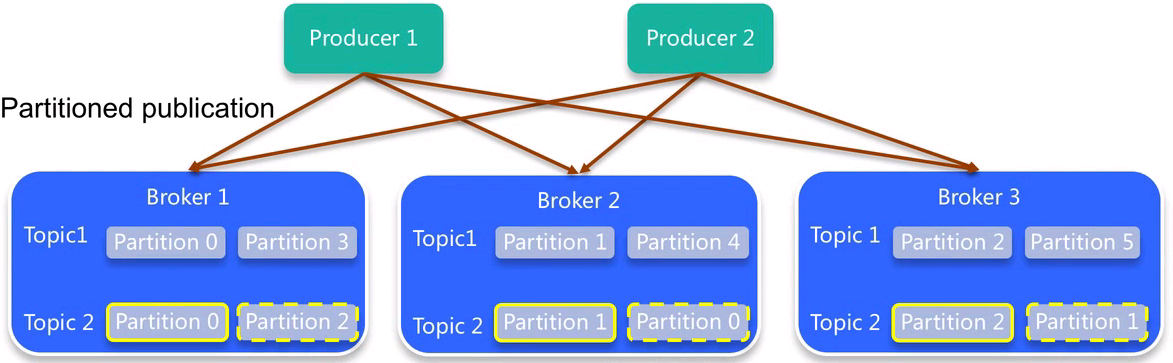
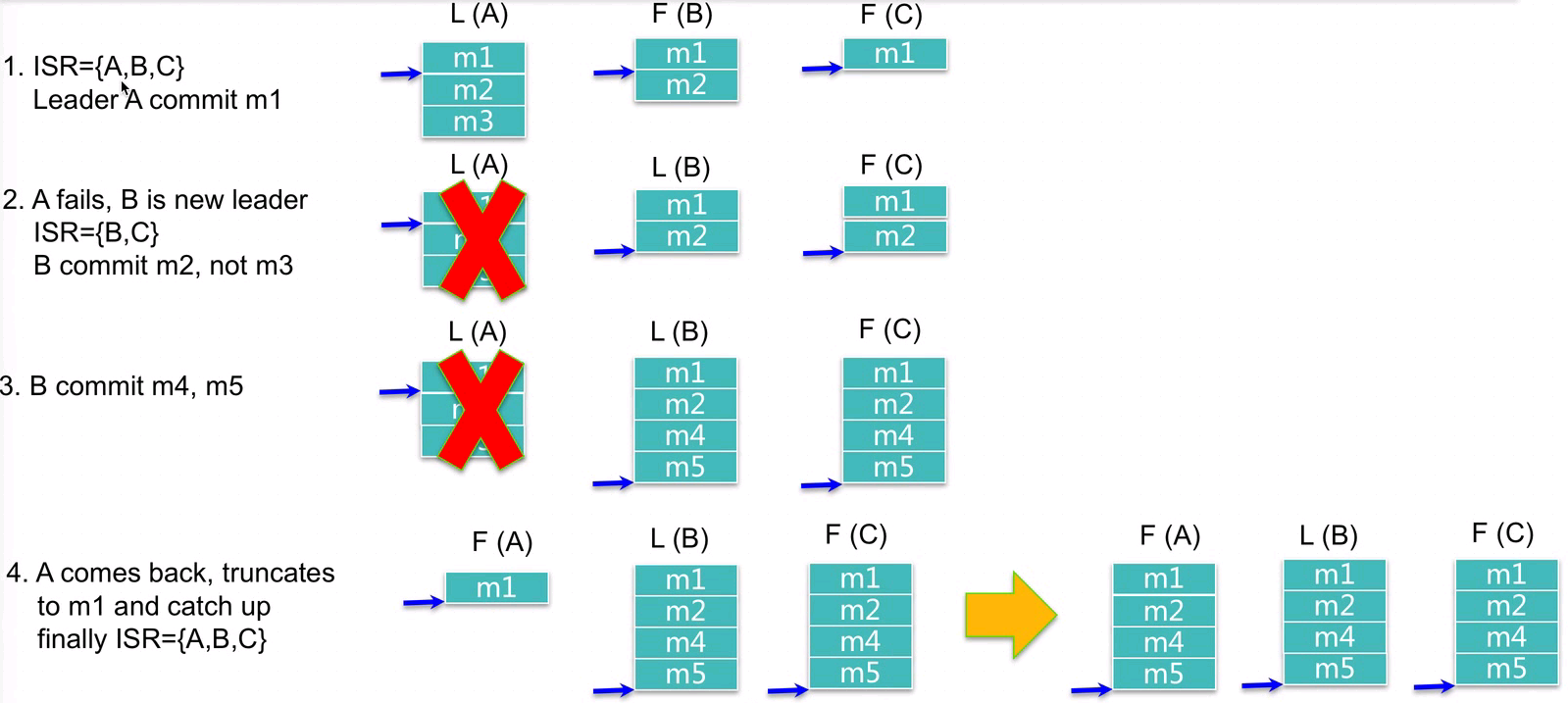
4、何时commit——ISR
Kafka HA一致性重要机制ISR:Kafka HA Kafka一致性重要机制之ISR(kafka replica)_1. rerplica.lag.time.max.ms-CSDN博客
如何处理replica恢复?
五)docker集群版kafka的安装使用
1、创建zookeeper和kafka镜像
实验环境是MAC的注意:docker在MAC电脑实现,它不支持MAC通过hosts绑定或IP直接访问kafka集群的
解决(前提配置文件中写的hostname):1、hosts绑定改成:127.0.0.1 kafka01
2、连接程序连接地址写成:localhost:9092
六)kafka如何使用zookeeper
zookeeper:https://www.cnblogs.com/happy-king/p/9921458.html
1、配置管理
2、leader election
3、服务发现
七)kafka高性能之道
1、高效使用磁盘
- 顺序写磁盘 顺序写磁盘性能高于随机写内存
- Append Only 数据不更新,无记录级的数据删除(只会整个segment删除)
- 充分利用Page Cache
- I/O Scheduler将连续的小块写组装成大块的物理写从而提高性能
- I/O Scheduler会尝试将一些写操作重新按顺序排好,从而减少磁盘头的移动时间
- 充分利用所有空闲内存(非JVM内存)
- 应用层cache也会有对应的page cache与之对应,直接使用page cache可增大可用cache
- 如使用heap内的cache,会增加GC负担
- 读操作可直接在page cache内进行。如果进程重启,JVM内的cache会失效,但page cache仍然可用
- 可通过如下参数强制flush,但不建议
- log.flush.interval.messages=10000
- log.flush.interval.ms=1000
- 支持多directory(多使用多drive)
2、零拷贝
1、传统模式下的拷贝
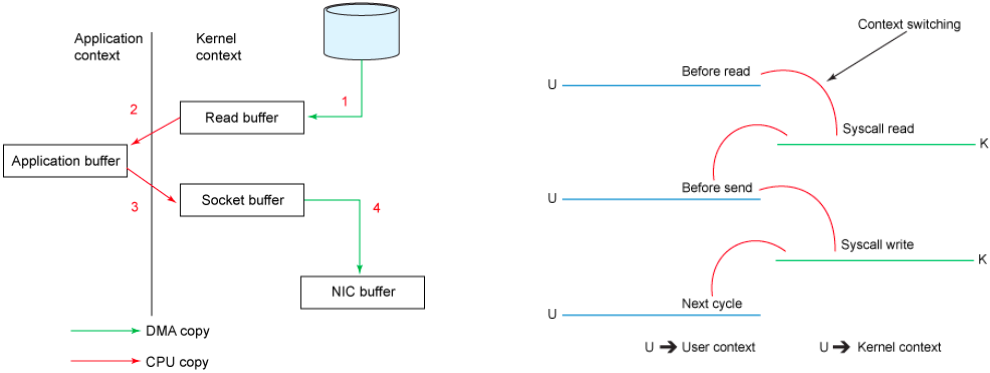
传统模式下的拷贝:数据从文件传输到网络需要4次数据拷贝,4次上下文切换(用户态和内核态)和2次系统调用
File.read(fileDesc, buf, len); Socket.send(socket, buf, len);
2、零拷贝
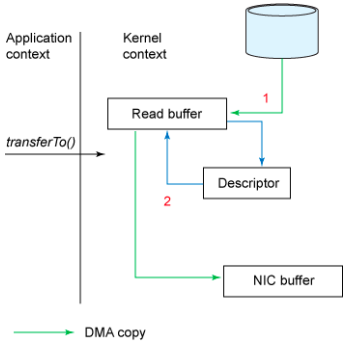
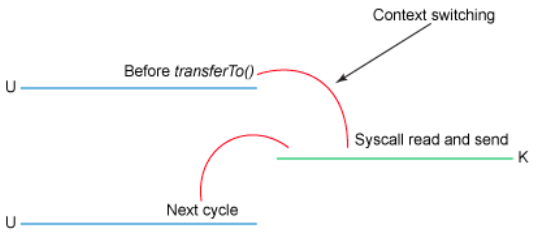
通过NIO的transferTo/transferFrom调用操作系统的sendfile实现零拷贝。总共发生2次内核数据拷贝(没有CPU参与(或没有用户态的)的拷贝),2次上下文切换和1次系统调用,消除了CPU数据拷贝
![]()
伪代码
3、批处理和压缩
- Producer和Consumer均支持批量处理数据,从而减少了网络传输的开销 (少次多量)
- Producer可将数据压缩后发送给broker,从而减少网络传输代价。目前支持Snappy, Gzip和LZ4压缩
4、partition(可以设置成broker数量一致)
- 通过Partition实现了并行处理和水平扩展
- Partition是Kafka(包括Kafka Stream)并行处理的最小单位
- 不同Partition可处于不同的Broker(节点),充分利用多机资源
- 同一Broker(节点)上的不同Partition可置于不同的Directory,如果节点上有多个Disk Drive,可将不同的Drive对应不同的Directory,从而使Kafka充分利用多Disk Drive的磁盘优势
5、ISR
ISR(In-Sync Replicas)
对每个消息都做f+1的备份:以单个消息为进行备份的基本单位,进行可靠性保障
ISR最核心的思想:以一段时间而非以一个消息为基本单位,进行可靠性保障
1、ISR实现了可用性和一致性的动态平衡 (会话失效后10秒删除节点)
replica.lag.time.max.ms=10000
2、ISR可容忍更多的节点失败
- Majority Quorum如果要容忍f个节点失败,则至少需要2f+1个节点
- ISR如果要容忍f个节点失败,至少需要f+1个节点
3、如何处理Replica Crash
- Leader crash后,ISR中的任何replica皆可竞选成为Leader
- 如果所有replica都crash,可选择让第一个recover的replica或者第一个在ISR中的replica成为leader
- unclean.leader.election.enable=true
八)kafka数据迁移
kafka 扩容之后迁移topic:https://my.oschina.net/remainsu/blog/1816010
kafka集群中数据自动迁移:Kafka集群中数据自动迁移-powerful_boy-ChinaUnix博客
















 2296
2296

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









