







Dubbo 集群容错
关于Dubbo的集群容错策略以及各自的使用场景,这个常见的面试题相信大家并不陌生。
本文带大家一起看看几种集群的源码实现。
看本文之前可能需要看之前文章
Cluster 接口
集群的作用 : 当服务目录Directory有多个服务提供方时,需要将多个服务提供方组织成一个集群,并伪装成一个提供方(Invoker)
Cluster 接口方法定义,前面文章已经介绍了 服务消费者引用调用了创建代理对象时 cluster.join 方法将服务目录的Invokers 列表伪装成一个Invoker 。然后内部进行负载均衡算法、集群容错处理,本文继续深入一探究竟。
@Adaptive
<T> Invoker<T> join(Directory<T> directory) throws RpcException;
AbstractCluster & AbstractClusterInvoker 模版类
AbstractCluster
AbstractCluster.join 方法在doJoin 基础上增加拦截器,先忽略拦截器。
doJoin 是一个抽象的方法具体有子类实现,返回AbstractClusterInvoker
@Override
public <T> Invoker<T> join(Directory<T> directory) throws RpcException {
return buildClusterInterceptors(doJoin(directory), directory.getUrl().getParameter(REFERENCE_INTERCEPTOR_KEY));
}
protected abstract <T> AbstractClusterInvoker<T> doJoin(Directory<T> directory) throws RpcException;
AbstractClusterInvoker
invoker 方法处理业务逻辑方法模板方法核心逻辑:
加载对应负载均衡算法(LoadBalance)这里并没有调用负载均衡算法选择一个invoker,虽然AbstractClusterInvoker已经 实现逻辑select / reselect ,调用负载均衡算法选择一个invoker 是在子类中处理的。
子类需要实现doInvoke,doInvoke需要完成的逻辑
-
根据
负载均衡算法选择一个服务提供者进行调用 -
调用出错会进行对应的相应的处理也就是
集群容错机制。
public Result invoke(final Invocation invocation) throws RpcException {
checkWhetherDestroyed();
// binding attachments into invocation.
Map<String, Object> contextAttachments = RpcContext.getContext().getObjectAttachments();
if (contextAttachments != null && contextAttachments.size() != 0) {
((RpcInvocation) invocation).addObjectAttachments(contextAttachments);
}
List<Invoker<T>> invokers = list(invocation);
LoadBalance loadbalance = initLoadBalance(invokers, invocation);
RpcUtils.attachInvocationIdIfAsync(getUrl(), invocation);
return doInvoke(invocation, invokers, loadbalance);
}
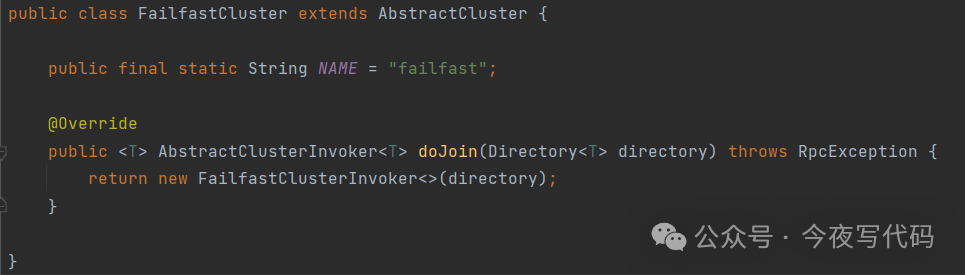
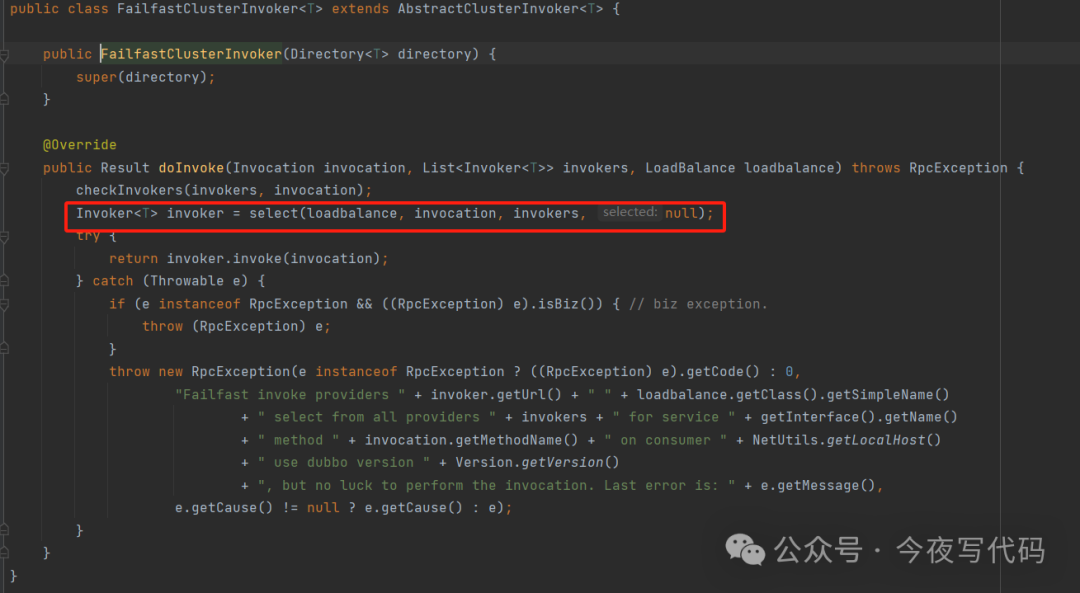
FailfastCluster
快速失败,也就是失败抛出异常,适用于非幂等的操作。代码实现很简单,返回一个 FailfastClusterInvoker,FailfastClusterInvoker逻辑也很简单:
-
调用负载均衡算法选择一个服务提供者
-
发生异常直接抛出异常
FailoverCluster
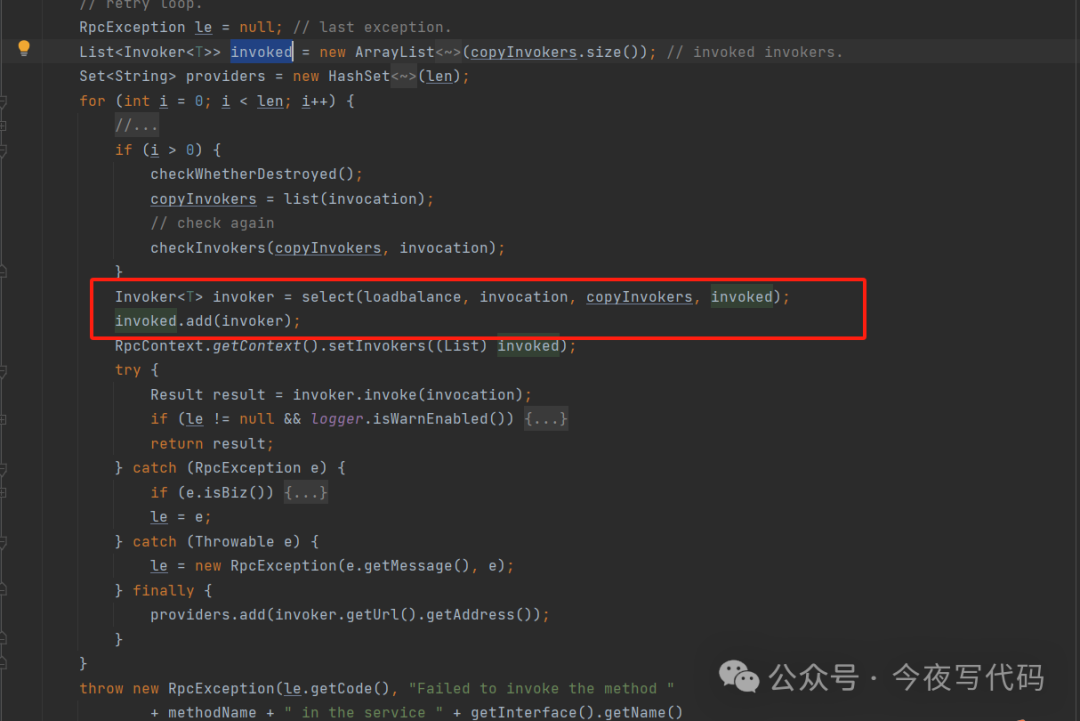
这是默认的集群策略,失败会重试其它服务器,需要配置指定一个重试次数(默认值2),一般用于读操作,如果写操作注意控制幂等,否则超时也可能导致重复数据。如果重试次数设置为0,效果等同于FailfastCluster快速失败。
代码核心逻辑:
-
最多循环调用 重试次数+1次
-
调用成功则返回结果
-
如果调用失败则在未选择的服务提供者中重新选择一个进行远程调用 当前已经选择了的服务提供者列表会加入到
invoked中,下次select 优先选择未选择的。 -
超过重试次数会保存
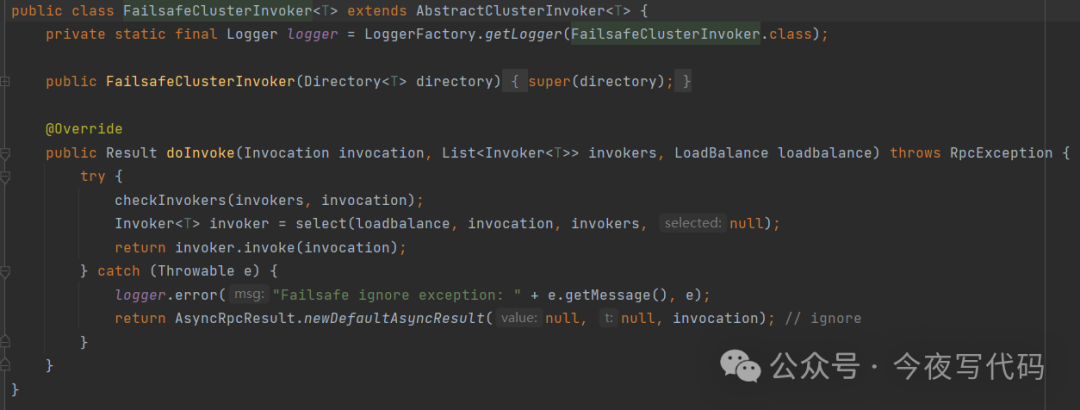
FailsafeCluster
失败安全:远程调用会返回空值,通常用于写入审计日志等操作,失败也不会影响业务流程。
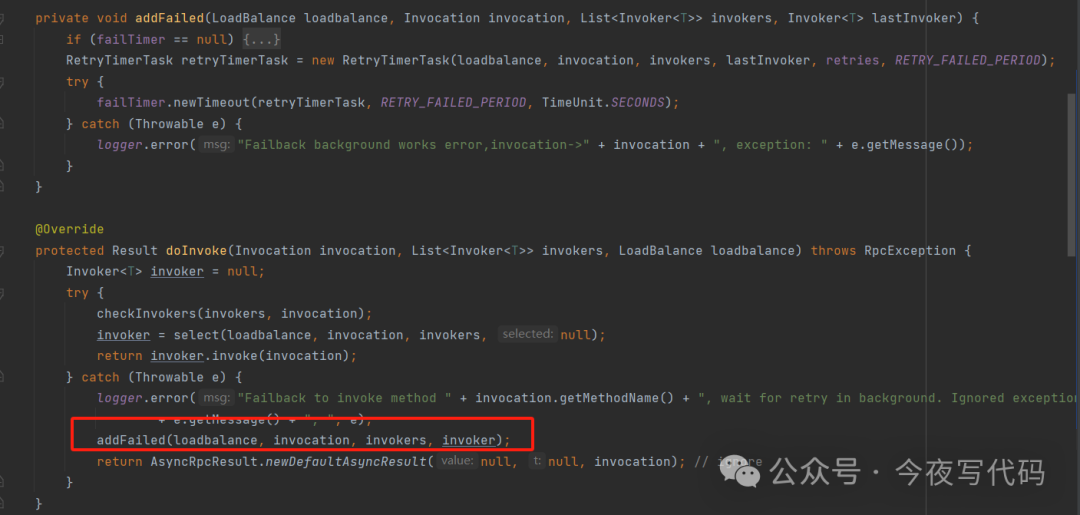
FailbackCluster
失败重试。失败了会被加入到失败列表,稍候通过定时任务重试。通常用于对实时性要求不高但需要保证最终一致性的场景,如消息通知。
与FailoverCluster重试不同,它不是立即重试,而是使用内置的HashedWheelTimer进行定时触发。
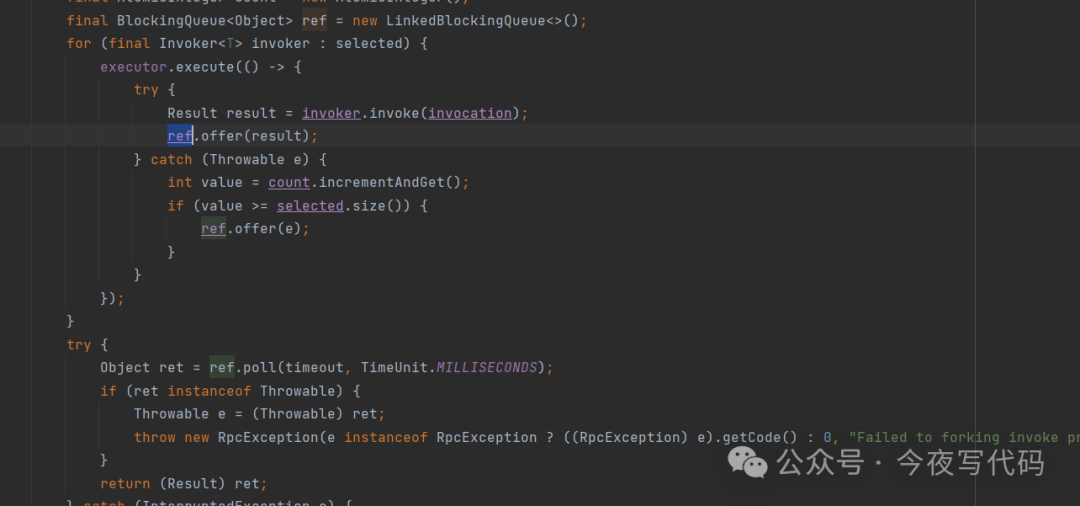
Forking Cluster
并行调用多个服务器,只要一个成功即返回。通常用于实时性要求较高的读操作,但会消耗较多服务器资源。
使用方式需要配置最大并行数(例如forks="2")
实现原理:并行异步调用,一旦返回结果放入BlockingQueue中。主线程一旦从BlockingQueue拿到结果或者异常,就立即返回。(其他几个异步调用结果就被忽略了,因此会造成资源浪费)
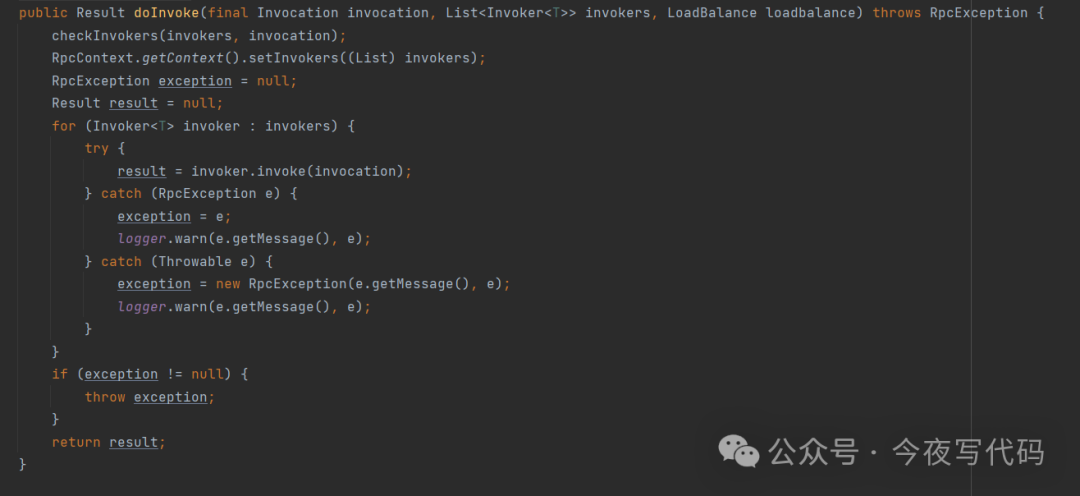
Broadcast Cluster
广播调用所有提供者,逐个调用,任意一台报错则报错。通常用于需要更新所有提供者状态的场景,如缓存更新
总结
本文主要介绍了常见的集群容错策略,代码也很清晰简单,一般情况主要考虑幂等,是否需要进行重试。















 381
381

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









