







 本文详细解析了《Fully Convolutional Networks for Semantic Segmentation》论文,该研究将CNN转换为FCN,实现了像素级别的语义分割。通过反卷积层进行上采样,确保输出与输入图像大小一致,提出了一种端到端的深度学习解决方案。实验表明,FCN-8s模型在语义分割任务中表现最优,并且能够适应不同尺寸的输入图像。
本文详细解析了《Fully Convolutional Networks for Semantic Segmentation》论文,该研究将CNN转换为FCN,实现了像素级别的语义分割。通过反卷积层进行上采样,确保输出与输入图像大小一致,提出了一种端到端的深度学习解决方案。实验表明,FCN-8s模型在语义分割任务中表现最优,并且能够适应不同尺寸的输入图像。
【论文信息】
《Fully Convolutional Networks for Semantic Segmentation》
CVPR 2015 best paper
key word: pixel level, fully supervised, CNN
【方法简介】
主要思路是把CNN改为FCN,输入一幅图像后直接在输出端得到dense prediction,也就是每个像素所属的class,从而得到一个end-to-end的方法来实现image semantic segmentation。
我们已经有一个CNN模型,首先要把CNN的全连接层看成是卷积层,卷积模板大小就是输入的特征map的大小,也就是说把全连接网络看成是对整张输入map做卷积,全连接层分别有4096个6*6的卷积核,4096个1*1的卷积核,1000个1*1的卷积核,如下图:
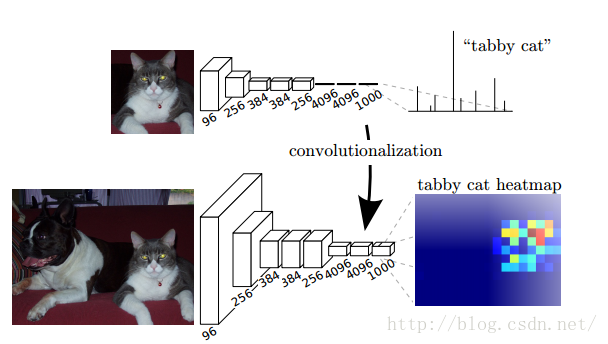
接下来就要对这1000个1*1卷积核的输出,做upsampling,得到1000个原图大小(如32*32)的输出,这些输出合并后,得到上图所示的heatmap。
【细节记录】
------------2016.11.4更新---------
fcn的输入图片为什么可以是任意大小呢?
首先,我们来看传统CNN为什么需要固定输入图片大小。
对于CNN,一幅输入图片在经过卷积和pooling层时,这些层是不care图片大小的。比如对于一个卷积层,outputsize = (inputsize - kernelsize) / stride + 1,它并不关心inputsize多大,对于一个inputsize大小的输入feature map,滑窗卷积,输出outputsize大小的feature map即可。pooling层同理。等要进入全连接层时,feature map(假设大小为n×n)要拉成一条向量,而向量中每个元素(共n^2个)作为一个结点都要与下一个层的所有结点(假设4096个)全连接,这里的权值个数是4096 × n^2,而我们知道神经网络结构一旦确定,它的权值个数都是固定的,所以这个n不能变化,n是conv5的outputsize,所以层层向回看,每个outputsize都要固定,那每个inputsize都要固定,因此输入图片大小要固定。
所以可以得出结论,一个确定的CNN网络结构之所以要固定输入图片大小,是因为全连接层权值数固定,而该权值数和feature map大小有关。
接着,我们来看FCN。FCN在CNN的基础上把1000个结点的全连接层改为含有1000个1×1卷积核的卷积层,经过这一层,还是得到二维的feature map,同样我们也不关心这个feature map大小。
到了反卷积层,注意,反卷积层也是卷积层,不关心input大小,滑窗卷积后输出output。
配个动图简单理解一下:下图中蓝色是反卷积层的input,绿色是反卷积层的output。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









