







一.基础
1.定义
是远离其它观测数据而疑为不同机制产生的观测数据
根据概率理论对异常的形式化定义如下

2.分类
点异常
- 单个异常数据点,将数据集中每个数据映射到高维空间中,其中孤立的点被称为点异常。这种异常点与其他数据点具有明显差异,这种异常分类是异常数据中最为简单的一种,也是异常检测研究中最常研究的异常类型
条件异常/上下文异常
- 一个数据本身看属于正常点,但在特定的条件下又与一般情况有差异,这类数据称为条件异常或上下文异常。其中上下文指数据集间的结构和关系,每个数据均由上下文特征及行为特征来定义,即条件异常需要考虑的不仅仅是数据的取值,还需要考虑数据出现的环境,也就是说某一数据在特定数据环境下被判断为异常,而在其他数据集中则可能是正常的

群体异常/序列异常
- 数据属性在正常范围内,且从上下文环境角度判断也属于正常的数据仍有可能是异常数据,如下图所示,在脑电图中虚线圆圈部分与脑电图整体图形不一致模式称之为聚集异常(集合异常)异常数据集中单个点可能并不异常,但这些相互关联的数据点聚集在一起时变为异常的情况。聚集异常不仅需要考虑数据的取值,上下文环境,还需要考虑数据集是否符合整体模式。聚集异常检测常用于时间序列,空间数据以及图形式的数据中
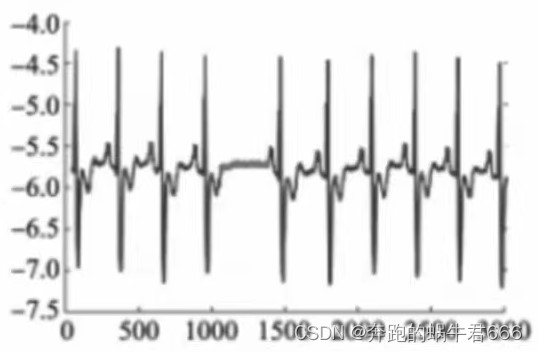
后两种异常通常需要和业务紧密结合,单纯从数据本身出发具有一定的辨识难度,再加上运维领域中大比例情况下出现的是点异常,客户多关注于此,因而通常情况下我们更关注点异常
3.应用领域
- 入侵检测:最普遍的两种为基于主机的入侵检测系统和网络入侵检测系统
- 欺诈检测:主要是不同领域的非法活动检测,主要应用领域为银行欺诈,移动蜂窝网络故障,保险欺诈,医疗欺诈
- 恶意软件检测
- 医疗异常检测
- 深度学习用于社交网络中的异常检测:社交网络中的异常通常是指个人的不正常甚至违法的行为,如垃圾邮件发送者,性侵者,在线欺诈者,虚假用户或谣言散布者
- 日志异常检测:指找到异常日志,从而判断系统故障原因与性质,通常将日志数据建模为自然语言序列进行异常检测
- 物联网大数据异常检测:通过监控数据流信息检测异常设备和系统行为
- 工业异常检测:挑战是数据量和数据的动态特性,因为故障通常是由多种因素引起的
- 时间序列中的异常检测:包括单变量时间序列异常检测和多变量时间序列异常检测
- 视频监控:检测视频中的异常场景
4.困难与挑战
- 未知性:异常与许多未知因素有关,例如具有未知的突发行为,数据结构和分布的实例,它们直到真正发生时才为人所知,比如恐怖袭击,诈骗和网络入侵等应用
- 异常类的异构性:异常是不规则的,一类异常可能表现出与另一类异常完全不同的异常特征。例如在视频监控中,抢劫,交通事故和盗窃等异常事件在视觉上有很大差异
- 类别不均衡:异常通常是罕见的数据实例,而正常实例通常占数据的绝大部分,因此,收集大量标了标签的异常实例是困难的,甚至是不可能的。这导致在大多数应用程序中无法获得大规模的标记数据
5.数据类型
用于异常检测的数据通常可分为两类
序列数据:如voice,text,music,time series,protein sequences
非序列数据:images,other data
二.分类
1.基于标签的异常检测算法分类
有监督异常检测算法
- 是指在训练集中的正常实例和异常实例都有标签,训练二类或多类分类器
- 有监督异常检测方法主要面临两个问题:①在训练数据中,相对于正常数据来讲,异常的数据量太小,会对检测效果产生影响 ②实际操作中很难精确地标注数据是正常还是异常,而且异常的情况也难以全部覆盖
- 因此在实际异常检测中,应用较少
半监督异常检测算法
- 在训练集中只有单一类别(正常实例),没有异常实例参与训练
- 半监督异常检测技术的一种典型方法是基于训练数据集为正常时间序列数据建立模型,然后利用该模型识别待检测数据中的异常
- 半监督异常检测学习正常数据的判别边界,不属于正常类的数据被判断为异常
- 由于训练中不需要标注异常序列,半监督式异常检测方法的应用相对更加广泛
无监督异常检测算法
- 在训练集中既有正常实例也可能存在异常实例,但假设数据的比例是正常实例远大于异常实例,模型训练过程中没有标签进行校正
- 此类技术的核心思想在于异常的情况相对于正常得情况而言是很少的,且与正常情况存在较大的差异,这种异常可以体现在数据之间的距离远近,分布密度,偏离程度等方面
- 无监督异常检测算法通常仅根据数据的内在属性(如距离,密度等)检测数据的异常值
- 自编码器是所有无监督深度异常检测模型的核心
2.基于模型的异常检测算法分类
基于传统方法的异常检测模型
- 基于统计的方法:使用这类方法的基本假设是正常的数据是遵循特定分布形式的,并且占了很大比例,而异常点的位置和正常点相比存在比较大的偏移。比如高斯分布,在平均值加减3倍标准差以外的部分仅占了0.2%左右的比例,一般我们把这部分数据就标记为异常数据。基于统计的异常监测一般需要充分的数据基础和相应的先验知识,此时检测效果可能是非常有效的,然而,此类检测方法一般是针对单个属性或低维数据的,而对于高纬度的时间序列数据就难以估计其真实的分布
- 基于重构的方法:重构是指从经过变换的数据中恢复出原始数据。基于重构的异常检测是指首先将数据进行压缩或降维,然后从低纬度数据中恢复原始数据,根据重构误差检测异常。该方法假设异常点是不可被压缩的活不能从低维映射空间有效地被重构的,常见的方法有PCA,Robust PCA,random projection等降维方法
- 基于重构的方法 - 降维:直观地,降维是指把数据的维度降下来,用一个相对低维的向量来表示原始高维度的特征;理解上讲,降维就是学习数据新的表示,这种数据新的表示在形式上更简洁,而且要求能够尽可能多地保存数据原有的信息(或者让其信息变得更好,更清晰更明确),原因有维度灾难,查询和计算的准确性和效率,去噪,数据压缩,可视化
- 聚类分析方法:通过聚类的结果来分辨正常与异常的数据,是一种典型的非监督式异常检测技术。通常来说,基于聚类的异常检测可基于三种假设来分辨异常数据,即①不属于任何簇的数据即为异常 ②距离簇中心很远的数据即为异常 ③归属于数据点少或稀疏簇的数据即为异常。使用聚类算法进行异常检测,可利用大量已有的聚类研究结果。聚类与异常检测还是有较大差异的,异常检测的目标在于寻找不正常的数据,而聚类的目的在于确定数据归属的类别
- one-class分类方法:仅利用包含一类的数据训练模型,即区分两个类别的边界线是通过仅有的一类数据的信息学习得到的。在异常检测中,即对正常数据建立区分性边界,异常点被划分到边界外。常见的方法有OC-SVM,SVDD等
基于深度学习的异常检测模型
- deep one-class
- deep clustering:采用深度学习的聚类方法进行异常检测流程为用神经网络对输入数据进行编码 → 最后的编码序列可以代表神经网络的很多特征 → 对编码序列进行聚类就可以达成聚类的目的 → 该类方法被用于异常检测的包括CAE-I2 cluster,DAE-DBC
- autoencoder:一个通用的自动编码器由编码器和解码器组成,编码器将原始数据映射到低维特征空间,而解码器试图从投影的低维空间恢复数据。这两种网络的参数通过重构损失函数来学习,为了使整体重构误差最小化,保留的信息必须尽可能与输入实例相关。典型实例有稀疏自动编码器,去噪自动编码器,收缩自动编码器,鲁邦自动编码器等

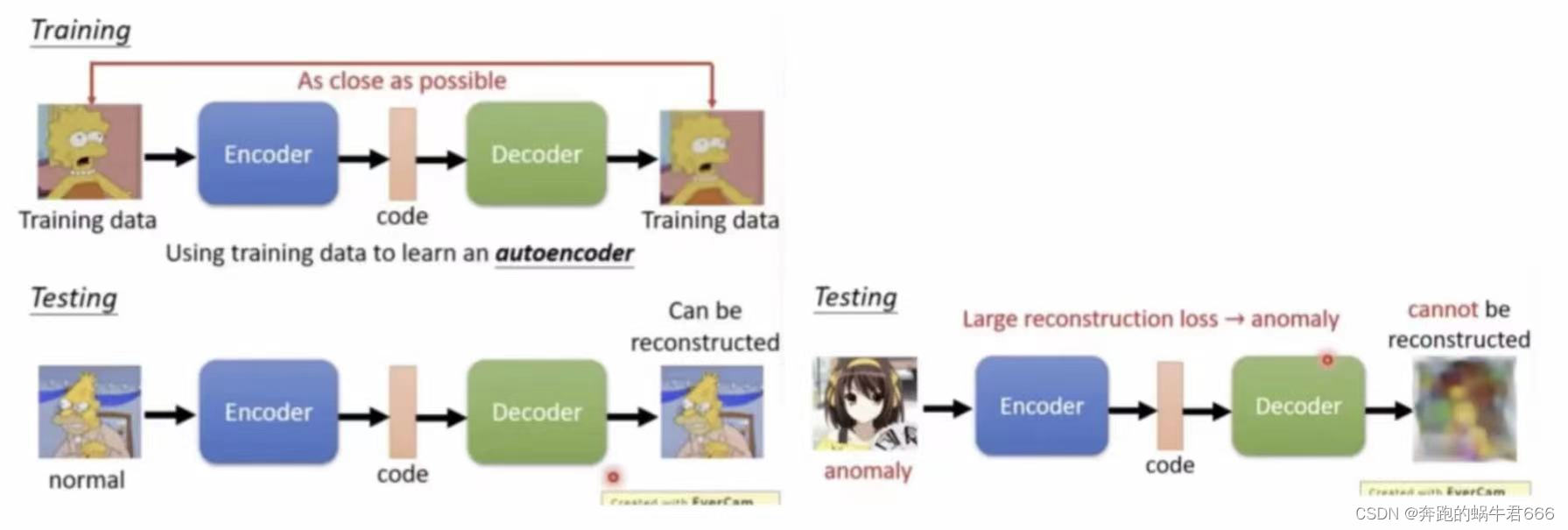
- generative models:旨在学习生成网络的潜在特征空间,使得潜在空间能够很好地捕捉到给定数据背后的常态。将生成模型用于异常检测是基于在生成网络的潜在特征空间中正常实例比异常实例能够更准确地被产生这一假设;实际实例和生成实例之间的残差被定义为异常分数。典型案例有AnoGAN,GANomaly,Wasserstein GAN,Cycle GAN,VAE等;该类方法的关键问题是如何设计合适的生成器和目标函数
- generative models - GAN:包含生成模型和判别模型两个模型。生成模型的任务是生成看起来自然真实的,和原始数据相似的实例;判别模型的任务是判断给定的实例看起来是自然真实的还是人为伪造的;真实实例来源于数据集,伪造实例来源于生成模型
三.如何分析出异常波动的原因
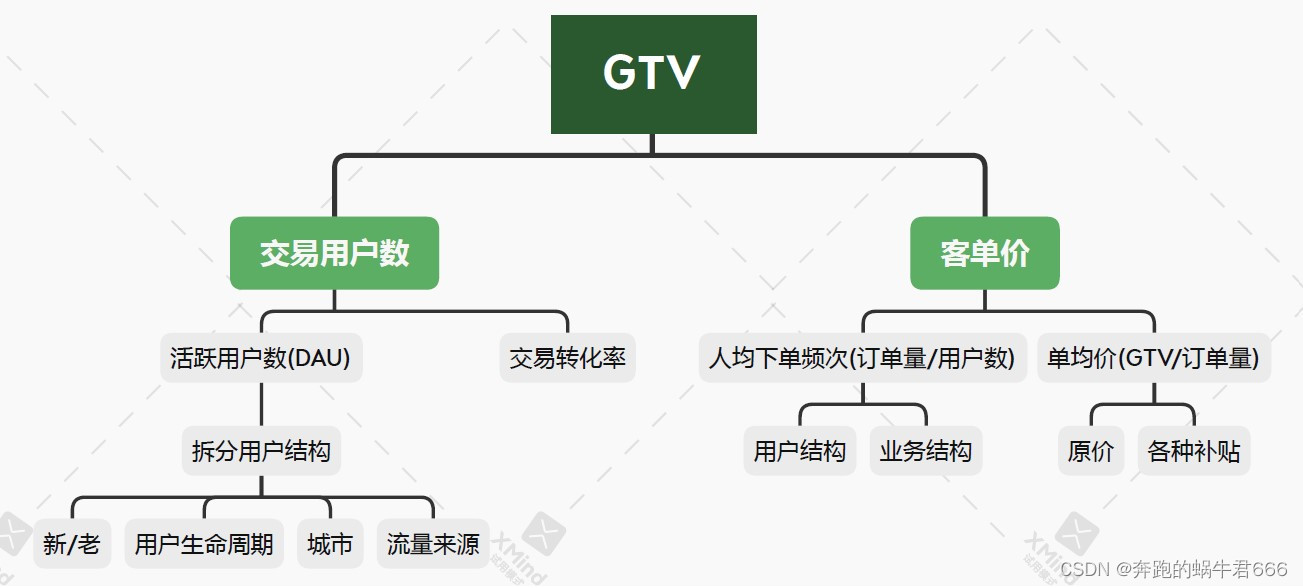
工作场景:已知某指标异常(以GMV & GTV为例),确定异常的原因
需要人工寻找异常指标,比如人工发现某指标异常(以GMV & GTV为例),然后确定GMV & GTV异常的原因
第一步:杜邦分析法对异常指标进行拆解
- 确定影响指标波动的核心因子,以便再做更细粒度的分析
- 杜邦分析法是利用几种主要的财务比率之间的关系来综合地分析企业的财务状况。具体来说,它是一种用来评价公司盈利能力和股东权益回报水平,从财务角度评价企业绩效的一种经典方法。其基本思想是将企业净资产收益率诸暨分解为多项财务比率乘积,这样有助于深入分析比较企业经营业绩。由于这种分析方法最早由美国杜邦公司使用,故名杜邦分析法
- 核心是拆解
第二步:连环替代法或者使用波动贡献法定位核心指标 / 维度
连环替代法定位核心指标
维度拆解定位:根据指标下钻维度方案,生成单个指标解释度的基尼系数,定位什么特征对核心指标产生关键影响


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









