






https://www.cnblogs.com/my_life/articles/6008032.html
http://yaocoder.blog.51cto.com/2668309/1543352
http://www.cnblogs.com/my_life/articles/3569555.html
https://www.cnblogs.com/itcomputer/p/4679059.html
用top命令很容易定位到是谁占用CPU最高。

以我们的这个业务进程(imDevServer)举例,为什么说这货是个潜伏者呢?因为这是个多线程的进程,我们要知道实际上占用cpu的最小单位是线程,所以肯定是众线程中的某一个或几个占用CPU过高导致的。top -H -p pid命令查看进程内各个线程占用的CPU百分比
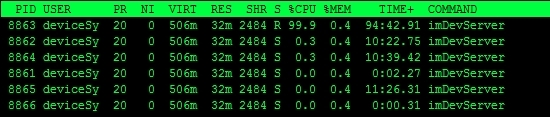
如上图所示我们可以看出id为8863的线程cpu占用率最高。好,我们现在只要能找到他偷走的cpu就好了,虽然这小子嘴巴严,但是我们有一套完善的审问流程,不怕他不招。首先出马的是strace -T -r -c -p pid命令
strace -o server.strace -Ttt -p 16739
执行一段时候后,ctrl-c退出,显示如下统计信息
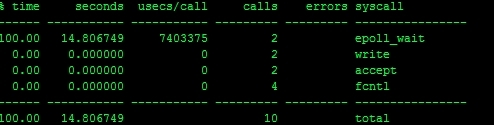
它的作用是查看系统调用和花费的时间,epoll_wait虽然占用的调用时间多,但是他本身是个正常的阻塞调用。
如果没有任何统计信息,可能存在一个空的死循环
跟踪指定的系统调用 -e
-e 选项仅仅被用来展示特定的系统调用(例如,open,write等等)
strace -e open -p 23333
trace的统计概要 -c
它包括系统调用的概要,执行时间,错误等等。使用-c选项能够以一种整洁的方式展示。 strace -c -p 23333
保存输出结果 -o
通过使用-o选项可以把strace命令的输出结果保存到一个文件中。
显示时间戳 -t
使用-t选项,可以在每行的输出之前添加时间戳。
更精细的时间戳 -tt
-tt选项可以展示微秒级别的时间戳。
相对时间 -r
-r选项展示系统调用之间的相对时间戳。
-T Show the time spent in system calls. This records the time difference between the beginning and the end of each system call.
输出:
0.000084 recvfrom(20, "+OK\r\n", 65536, 0, NULL, NULL) = 5 <0.026377>
0.026464 sendto(20, "*3\r\n$5\r\nSETNX\r\n$48\r\nffmpeg_monit"..., 87, 0, NULL, 0) = 87 <0.000018>
相对时间 系统函数(参数) = 返回值 <调用耗时>
我们接着让pstack pid出马
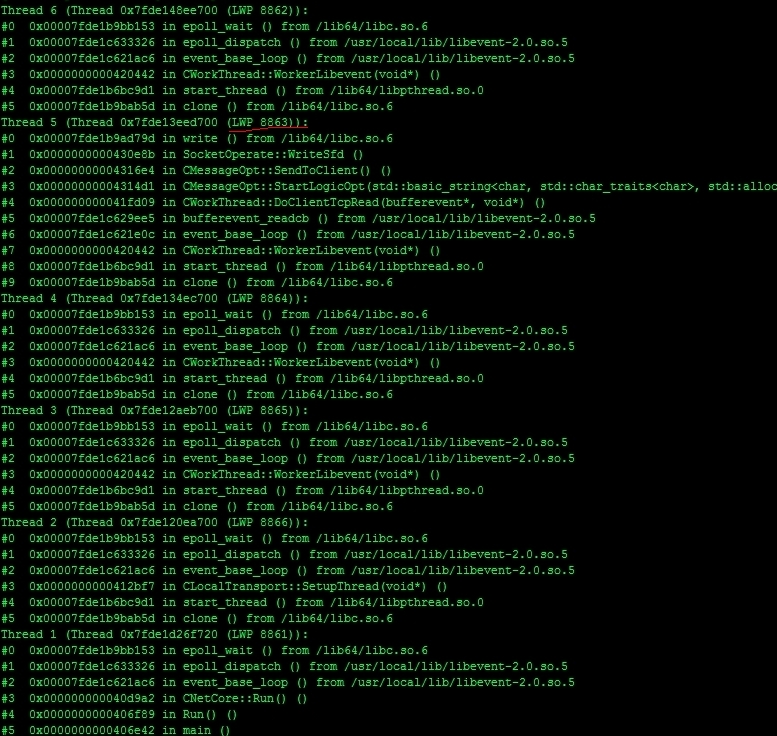
可以看到每个线程的调用堆栈,找到已经找出的占用CPU最高的那个线程,然后看他的调用堆栈,很容易看出在哪一步逻辑上导致了busy loop,
再使用trace -p tid看看线程的调用过程接着定位到代码,修复bug,找回被偷走的cpu。
=======================================================================================
客户端的一个http请求响应耗时1秒,找出这一秒的耗时的地方
1: strace -T -tt -p 42444
2: 分析 每行最后<0.0xxx>的耗时,发现不部分耗时都很小,比较大的几个耗时是0.02xxx
3:

50个0.02的耗时,加起来差不多就是1秒钟的时间
4: 0.02的函数基本上都是read(11)的操作,接下来分析11这个fd对应的是哪个ip
5: lsof -p 42444

6: ping bj.acgncommentdev.r.qiyi.db

ping的耗时是26ms,这正好对应上面的read(11)的0.02的耗时时长
7:根据上面的ip从你的代码中大概也就知道了这是一个什么服务了。
上面的第五步或者更简单一点:
lsof -p pid -nP
-n: 显示IP而不是域名
-P: 显示端口号,而不是端口的服务名称

一目了然















 735
735

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









