







视频超分是由图像超分发展而来的。基于深度学习的图像超分辨率(SISR)首次实现于2014年,推广到视频超分是在2017年,由此可见超分辨率还是一个比较新颖的课题方向。

超分类任务主要源自对图像视频信息的传输和恢复。在实际生活中,有很多情况下需要对图像或者视频进行传输,而由于视频图像的分辨率越来越高,体积越来越大,传输成本比如网络带宽等也在不断提升。因此对图像或者视频进行下采样(压缩)之后再进行传输,到达客户端以后在对图像视频进行恢复(restore)是很有必要的(比如微信发送照片时默认发送低分辨率的)。
图像超分辨率(Iimage Super-Resolution):
图像超分辨率的经典网络就是提出于2014年的SRCNN:
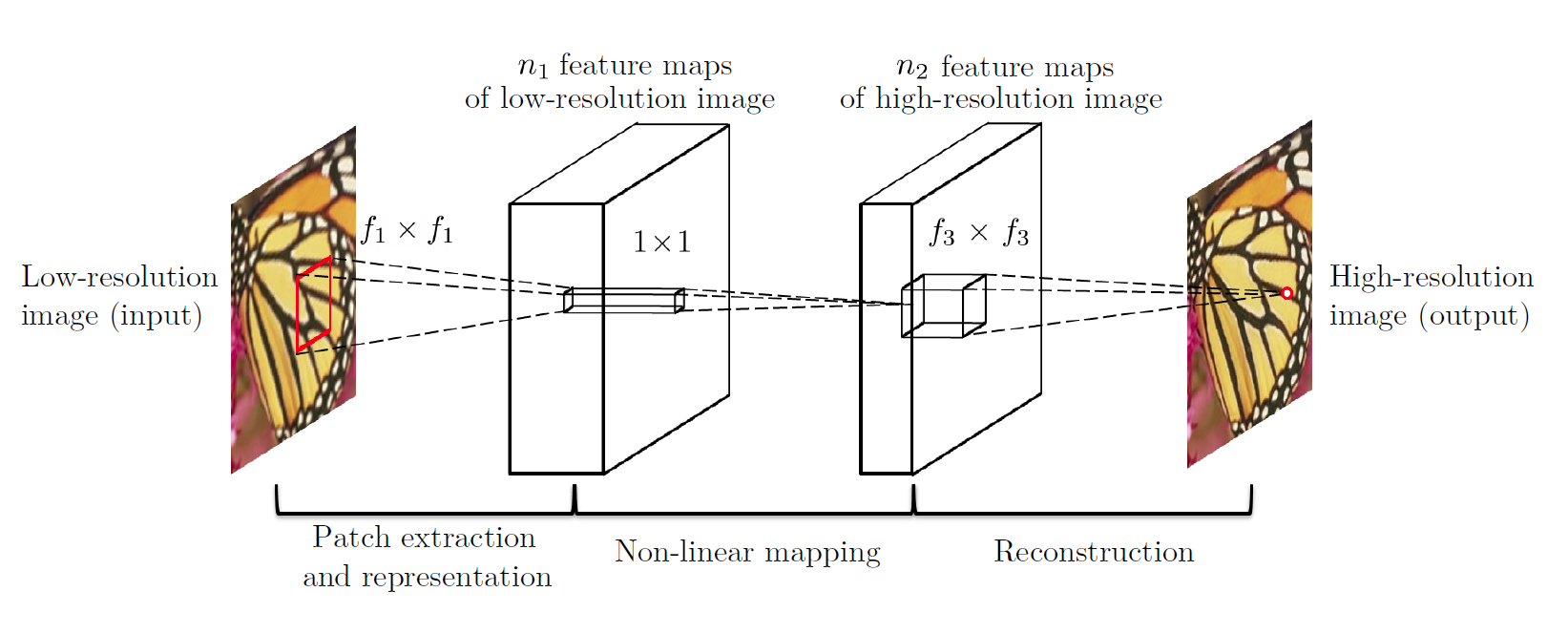
该网络以一张低分辨率图像为输入,输出一张高分辨率图像,仅有三层卷积层,学习的是两张图象之间的映射关系。有的同学可能会问:如何对两张大小不一的寻求其映射关系呢? 实际上早期的SR网络都是先对输入图像进行插值放大(传统方法,如二次插值,最近邻插值等),使得输入图像与输出图像大小维度相等,然后在寻求输入图像与输出的高清图像之间的映射关系。
实际上,一般而言用于训练网络的低分辨率图像就是由高分辨率图像经过下采样得到的,所以一个SR网络实际上学习的是以某种下采样方式得到的低分辨率图像与原图的映射关系。这也就是为什么说超分问题是一个病态问题的原因。因为真正在自然界中,获取到的图像并不是由高清图人工将采样得到的。
在后几年的发展中,图像超分已经取得了长足的进展。其中比较突出的也最为常用的一个放大结构称为亚像素卷积:
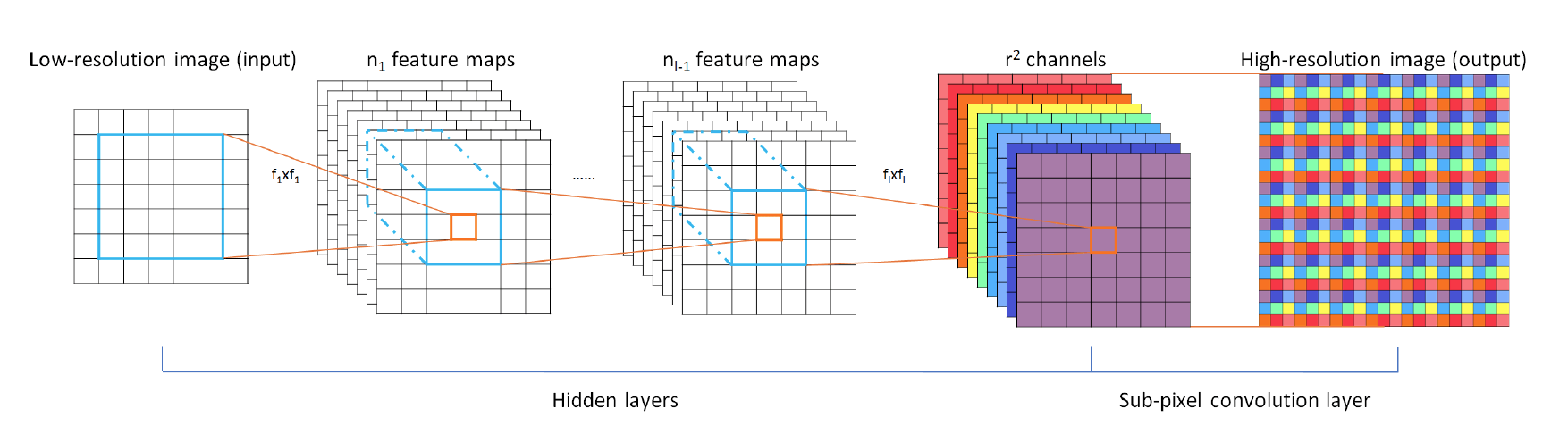
亚像素卷积输入基本原理是对输入大小为h,w的图像,经过若干层卷积得到h*w*r^2大小的特征图,其中r^2为通道数。然后直接将r^2个通道上同一位置的像素排列成r*r的方块,最为放大后的像素块。如此一来原来h*w*r^2大小的特征图就被变形为rh*rw大小的特征图,同时也完成了放大操作。亚像素卷积提出与ESPCN中,主要考虑的因素的是在之前的先有传统插值放大之后在学习映射关系的方法中,深度学习网络完成的工作只是微调传统放大的结果,传统放大的结果基本上已经决定了网络的性能。而将放大步骤也放在网络中完成则极大的提高了网络的重建性能。
视频超分辨率(Video Super-Resolution):
视频超分是在图像超分的基础上发展而来的。视频顾名思义是多帧图像的堆叠。最简单的视频超分方法当然是将视频直接按照帧一帧一帧的逐幅图像的进行图像超分,最后再将超分的结果堆叠起来,构成超分视频。

然而,在近几年的研究中,人们逐渐认识到人们一直以来忽略的一部分信息,那就是帧间信息。实际上在不同帧的图像中,对于同一物体所包含的信息是不同的。如果能够利用不同帧之间的信息来重建该物体的话理论上来说肯定要比单帧图像超分要好。尤其是在人造数据集中,采用同一种下采样方式时不同帧的目标信息一定是不同的,所以很有必要将多帧信息进行融合。
帧间信息融合或者说提取的方法现在主要分为两大类:对齐的和不对齐的。

首先介绍不对齐的。对于不同帧而言,同一物体随着时间推进位置会发生变化,姿态也会产生一定的形变。如果不对运动目标进行对齐的话,可能会出现输入的多帧视频同一目标出现在不同位置的情况。这就要加深网络结构,以更大感受野,才能提取到运动范围较大的相同的特征。但是到目前为止,我认为如果不对其进行对齐仅依靠深度特征提取网络来取得大位移的特征的话,提取到的应该是融合特征,不如直接在浅层提取到的细节特征好。
所谓对齐就是将不同帧间的同一物体(位置发生变化的)对齐到同一位置,使得物体特征都处在相同位置,方便特征提取网络提取到物体尽可能多的特征。
一般而言,帧间对齐是依靠显式计算不同帧之间的光流来完成的:
众多光流估计网络比如FolwNet等基本上可以实现较为准确的光流估计。有了帧间光流以后,就可以将上一帧的运动目标补偿到这一帧中进行对齐,这样就可以将多帧输入同时输送到通用的图像超分SR网络进行超分。值得一提的是每次输出一张高分辨率HR帧,都会用到该帧对应的低分辨率LR帧和相邻的LR帧。
不难看出,上面基于光流的帧间信息对齐方法的准确性严重依赖于光流估计的准确性。并且由于除了超分网络还要借助光流估计网络,所以基于光流对齐的视频超分算法属于二阶段模型。因此除了显式的计算光流之外,最近逐渐出现了隐式对齐的一阶段算法,即不需要进行光流估计。
比如CVPR2020年收录的论文:TDAN——时间可变形对齐的视频超分辨率模型。
该文章的思路主要是借助DCN的思想,将每一帧输入图像提取特征后在特征层面进行对齐,如此一来不必计算光流,仅有一个网络就可以完成全部工作。
本次的文章只是简单介绍,具体的TDAN基本原理我将会额外更新一篇文章详细介绍。
想要了解TDAN的朋友可以从下面的链接查看论文:
https://arxiv.org/pdf/1812.02898.pdf
该论文的完整翻译我也已经上传了,欢迎下载。
有兴趣的朋友欢迎私信,共同学习。
















 5819
5819











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











