







现象:
node节点 3-5秒间断性地显示 PLEG is not healthy: pleg was last seen active 3m45.252087921s ago; threshold is 3m0s。
node 节点 显示 notready。
分析:
K8S集群中,与节点就绪状态有关的组件,主要有四个,分别是集群的核心数据库etcd,集群的入口API Server,节点控制器以及驻守在集群节点上,直接管理节点的kubelet。
一方面,kubelet扮演的是集群控制器的角色,它定期从API Server获取Pod等相关资源的信息,并依照这些信息,控制运行在节点上Pod的执行;另外一方面,kubelet作为节点状况的监视器,它获取节点信息,并以集群客户端的角色,把这些状况同步到API Server。
在这个问题中,kubelet扮演的是第二种角色。
Kubelet会使用上图中的NodeStatus机制,定期检查集群节点状况,并把节点状况同步到API Server。而NodeStatus判断节点就绪状况的一个主要依据,就是PLEG。
PLEG是Pod Lifecycle Events Generator的缩写,基本上它的执行逻辑,是定期检查节点上Pod运行情况,如果发现感兴趣的变化,PLEG就会把这种变化包装成Event发送给Kubelet的主同步机制syncLoop去处理。但是,在PLEG的Pod检查机制不能定期执行的时候,NodeStatus机制就会认为,这个节点的状况是不对的,从而把这种状况同步到API Server。
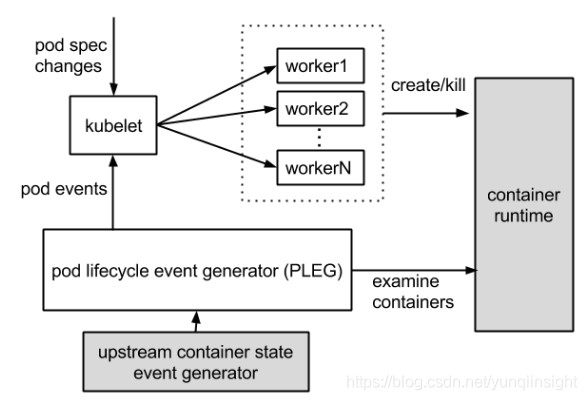
官方这张PLEG示意图,这个图片主要展示了两个过程。一方面,kubelet作为集群控制器,从API Server处获取pod spec changes,然后通过创建worker线程来创建或结束掉pod;另外一方面,PLEG定期检查容器状态,然后把状态,以事件的形式反馈给kubelet。
PLEG有两个关键的时间参数,一个是检查的执行间隔,另外一个是检查的超时时间。以默认情况为准,PLEG检查会间隔一秒,换句话说,每一次检查过程执行之后,PLEG会等待一秒钟,然后进行下一次检查;而每一次检查的超时时间是三分钟,如果一次PLEG检查操作不能在三分钟内完成,那么这个状况,会被上一节提到的NodeStatus机制,当做集群节点NotReady的凭据,同步给API Server.
出现上述现象,肯定是3分钟检查超时导致。
解决方案1:删除node上Dead/Exited状态容器
1、查看节点kubelet日志
docker logs --tail 100 kubelet
PodSandboxStatus of sandbox "3780e5f912" for pod "pangu-gateway-jc5-5c7b77449-2874f_common(20dc3f10-ce23-11e9-b285-525400d43e28)" error: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Failed to stop sandbox "3780e5f9170e1d60d8" before removing: rpc error: code = DeadlineExceeded desc = context deadline exceeded
可见 pod common/pangu-gateway-jc5-5c7b77449-2874f 可能有问题
2、查看此pod
kubectl get pod pangu-gateway-jc5-5c7b77449-2874f -n common
提示 并无此pod , not found.
3、docker ps | grep pangu-gateway-jc5
提示 并无此pod , not found.
docker ps -a | grep pangu-gateway-jc5
3780e5f912 rancher/pause:3.1 "/pause" About an hour ago Dead About an hour k8s_POD_pangu-gateway-jc5-5c7b77449-2874f_common_20dc3f10-ce23-11e9-b285-525400d43e28
显示此pod 处于Dead状态
4、删除处理Dead状态的容器
docker rm 3780e5f912
或
docker rm -f $(docker ps -a | grep Dead| awk '{print $1}')
如果删除不掉提示,filesystem is busy.
可以:
a、删除对应deployment,重试 docker rm 3780e5f912
b、查看 "删除状态为Dead的容器"
5、最好 删除节点上 所有处于Dead状态的容器
删除之后,节点状态处于ready状态,不再提示pleg超时问题,问题解决!















 56
56











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









