







《Neural Networks and Deep Learning》学习笔记——《Neural Networks and Deep Learning》是Michael Nielsen 所著的一本神经网络与深度学习的在线学习教材,通过Python(+Theano)实现神经网络识别MNIST手写数据集,生动易懂的讲解了神经网络与深度学习的基本原理,是一本非常不错的入门教材。本文是对其学习的总结。
目录
- 初识神经网络
1.1 感知器
1.2 Sigmoid函数
1.3 代价函数
1.4 梯度下降算法 - 反向传播算法
- 神经网络改进算法
- 深度学习
4.1 万有逼近定理(Universal Approximation Theory)
4.2 训练深度神经网络时的问题
4.3 卷积神经网络(CNN)
1.感知器(Perceptron)
通过对感知器的介绍来初步了解神经网络的结构。
简单的感知器结构如下图所示,
x1,x2,x3
为其0/1输入,output为其0/1输出。感知器可以有多个输入,但只有一个输出。

为了方便计算其输出,引入了神经网络中的第一个参数(注意与超参数区分)——权值
ω
,从而其输出为:
output=⎧⎩⎨⎪⎪⎪⎪⎪⎪01if ∑jwjxj≤ thresholdif ∑jwjxj> threshold(1)
对上式进行简单变换,令 b=−threshold ,便引入了神经网络的第二个参数——偏置b:
output={01if w⋅x+b≤0if w⋅x+b>0(2)
由此可知,感知器是通过改变 ω 和b的值来改变输出。对此简单推广——训练神经网络的目的是对 ω 和b的值进行学习,找出其最优值以获得目标输出。

2.Sigmoid函数
由于感知器的激励函数为阶跃函数a=step(z),在某些情况下,
ω
和b很微小的改变都会对输出造成很大的扰动(从0变为1),因此在实际情况在很难进行学习。因此引入平滑连续的Sigmoid函数,
σ(z)≡11+e−z.(3)
由下图阶跃函数和Sigmoid函数的图像比较可知,Sigmoid函数是平滑连续的Sigmoid函数相较于阶跃函数,其输入x,输出a均是连续的,即x,a ∈ [0,1]。


| 感知器 | Sigmoid | |
|---|---|---|
| 输入x | 0/1 | 0–1 |
| 输出a | 0/1 | 0–1 |
| 激励函数 | 阶跃函数 | Sigmoid函数 |
因此Sigmoid神经元输出为:
11+exp(−∑jwjxj−b).(4)
我们已经知道可以通过改变 ω 和b的值来改变输出,而应用Sigmoid函数很容易通过对 ω 和b的学习得到目标输出(偏导易计算):
Δoutput≈∑j∂output∂wjΔwj+∂output∂bΔb(5)
下面引入多层感知器(MLPs, 因为一些历史原因这种结构被称为多层感知器,但其实质是基于Sigmoid神经元)

由上图可以得出神经网络的一般结构:输入层,隐含层,输出层。而且因为前一层的输出即作为后一层的输入:输入层->隐含层->输出层,因此这种结构被称为前向反馈神经网络。
3.代价函数(Cost function,Loss function)
如果要判断神经网络的输出是否达到我们的目标(接近理想输出)就要引入代价函数。
二次代价函数(均方误差)是一种常用的代价函数:
C(w,b)≡12n∑x∥y(x)−a∥2.(6)
其中n为输入x的数量,y(x)为理想输出,a为实际输出, ω 和b分别为权值和偏置。
由上式可以看出,C ≥ 0;如果C ≈ 0,则表明a ≈ y(x),即获得目标输出;反之C>>0,则表明输出误差大。因此我们现在可以通过最小化代价函数来学习 ω 和b的最优值,从而获得目标输出。
4.梯度下降算法(Gradient descent algorithm)
了解了代价函数后就需要寻找可以使代价函数最小化的方法——梯度下降法。
梯度下降法类似于我们用导数求极值的想法,即不断通过学习
ω
和b的值找能到使代价函数下降最大的方向,从而找到代价函数的全局最小值,此时
ω
和b的值便是可以得到目标输出的最优值。
为了便于理解,以一般二元函数
C(v1,v2)
为例,首先我们定义梯度
∇C
:
∇C≡(∂C∂v1,∂C∂v2)T.(7)
根据微积分相关知识,有:
ΔC≈∂C∂v1Δv1+∂C∂v2Δv2.(8)
简化得,
ΔC≈∇C⋅Δv.(9)
因此我们需要通过改变 Δv 的值,使 ΔC 为负。
选取 Δv=−η∇C ,其中 η 被称为学习速率,它是一个正的,且值很小(要保证(9)式成立)的(超)参数。将其代入(9)式,可得 ΔC≤0 ,从而保证函数C的值总是减少的。
即通过学习并更新函数C的自变量参数( v′=v−Δv )使C减小。然后不断重复这一过程得到函数C的全局最小值,学习到参数v的最优值。上述过程可由下图定性描述,
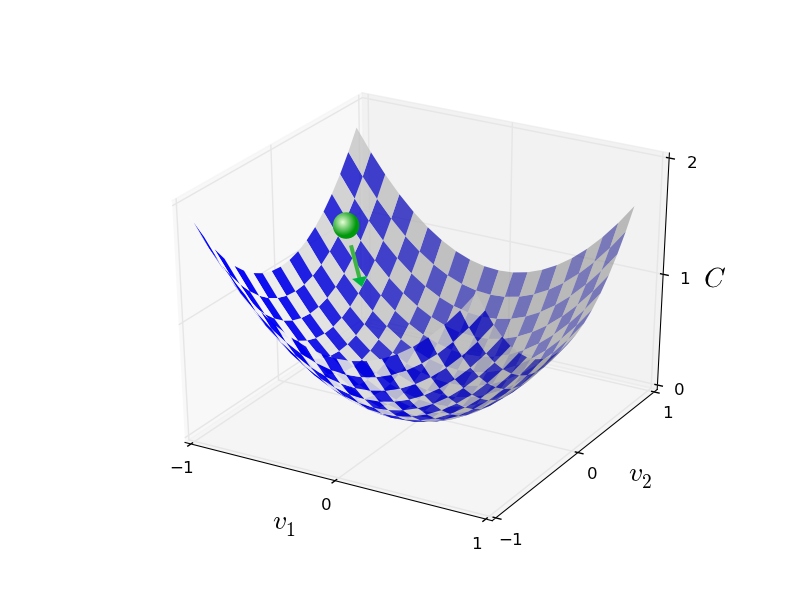
现在可将梯度下降法应用到我们的神经网络中:
ΔC≈∂C∂ωΔω+∂C∂bΔb.(10)
wkbl→→w′k=wk−η∂C∂wkb′l=bl−η∂C∂bl.(11)(12)
将(10)(11)(12)结合之前的分析可知, 当选择合适的学习速率 η 时(太大会导致 ΔC >0,太小则会使神经网络学习速率变慢) ΔC 恒为负,因此由式(11)(12)可以看出神经网络根据当前梯度自主学习并更新权值 ω 和偏置b,不断修正输出,直到代价函数 C≈0 ,从而获得目标输出。
让我们的注意力重新回到代价函数 C(w,b)≡12n∑x∥y(x)−a∥2 上。
令 Cx≡∥y(x)−a∥22 ,则 ∇C=1n∑x∇Cx 。这里便有一个问题,当输入训练样本数n很大的时候,学习速率会变得很慢,并不适合实际应用。因此提出了一种提高学习速率的改进方法——随机梯度下降算法。
因为我们减小代价函数的值时,只需要定性确定可以使其下降较大的方向及其参数值,并不需要精确计算,所以我们可以 随机选取一小部分输入样本数m,来近似计算梯度,其中这一小部分输入数据集被称为小批量,
∇C≈1m∑j=1m∇CXj,(13)
wkbl→→w′k=wk−ηm∑j∂CXj∂wkb′l=bl−ηm∑j∂CXj∂bl,(14)(15)
总结:
我们的目标是想通过学习权值和偏置的最优值来获得与理想输出非常接近的输出,这一目标可由代价函数来量化。即通过改变权值和偏置值到其最优值使我们的神经网络得到目标输出,此时代价函数达到最小值,这一过程通过梯度下降法得到。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









