







 Transformer模型由GoogleDeepMind在2017年的论文《AttentionIsAllYouNeed》中提出,它以自注意力机制为核心,替代了RNN和CNN,改善了序列数据处理的并行性和可扩展性。模型包含Encoder和Decoder,分别用多头自注意力和多头注意力机制捕捉序列关系。此模型在机器翻译等领域表现出色,现已被广泛应用。
Transformer模型由GoogleDeepMind在2017年的论文《AttentionIsAllYouNeed》中提出,它以自注意力机制为核心,替代了RNN和CNN,改善了序列数据处理的并行性和可扩展性。模型包含Encoder和Decoder,分别用多头自注意力和多头注意力机制捕捉序列关系。此模型在机器翻译等领域表现出色,现已被广泛应用。
1,概述
《Attention Is All You Need》是一篇由Google DeepMind团队在2017年发表的论文,该论文提出了一种新的神经网络模型,称为Transformer模型,用于自然语言处理任务。
该模型的创新点在于使用了一种称为“自注意力机制(self-attention mechanism)”的技术,以取代传统的循环神经网络(RNN)和卷积神经网络(CNN)等结构,这使得模型在处理序列数据时具有更好的并行性和可扩展性,同时能够捕捉序列中各个位置之间的相对关系,进而更好地对序列进行建模。
具体来说,自注意力机制允许模型同时计算输入序列中所有位置之间的关系权重,进而加权得到每个位置的特征表示。在Transformer模型中,自注意力机制被运用在了Encoder和Decoder两个部分中,分别用于编码输入序列和生成输出序列。
该论文还提出了一种新的训练方法,称为“无序列信息的训练(Training without sequence information)”,其基本思想是将输入序列中的每个位置看作独立的词向量,而不考虑它们在序列中的位置信息。通过这种方式,可以避免序列中的位置信息对模型训练的影响,提高模型的泛化性能。
该论文在机器翻译和语言建模等自然语言处理任务上取得了非常好的表现,其所提出的Transformer模型也被广泛应用于其他领域,如图像处理和语音识别等任务中。模型架构如下:
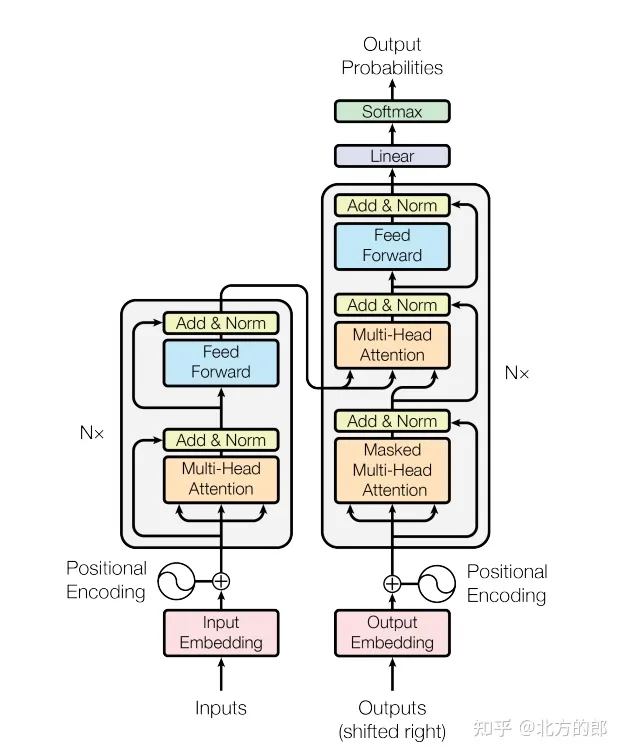
《Attention Is All You Need》论文提出的Transformer模型包括Encoder和Decoder两个部分。下面将分别介绍这两个部分的技术细节。
2,Encoder
Encoder的作用是将输入序列编码成一个高维向量表示,该向量表示将被输入到Decoder中用于生成输出序列。Encoder包括多个Encoder层,每个Encoder层由两个子层组成:多头自注意力机制和前馈网络。
多头自注意力机制
多头自注意力机制(multi-head self-attention)是Transformer模型的核心部分,其作用是从输入序列中学习并计算每个位置与其他位置之间的相关度。具体来说,多头自注意力机制将输入序列中的每个位置看作一个向量,然后对这些向量进行相似度计算,得到每个位置与其他位置之间的相关度。
多头自注意力机制将输入序列分别映射成多个维度相同的向量,然后分别应用自注意力机制,得到多个输出向量,最后将这些输出向量拼接起来,得到最终的向量表示。这种分头处理的方法可以使模型更好地捕捉不同方面的特征,从而提高模型的表现。
前馈网络
前馈网络(feedforward network)是Encoder层的另一个子层,其作用是对多头自注意力机制的输出向量进行非线性变换。前馈网络由两个线性变换和一个激活函数组成,其中线性变换将输入向量映射到一个高维空间,激活函数将这个高维向量进行非线性变换,最后再将其映射回原始维度。
3,Decoder
Decoder的作用是生成输出序列,它包括多个Decoder层,每个Decoder层由三个子层组成:多头自注意力机制、多头注意力机制和前馈网络。
多头自注意力机制
多头自注意力机制在Decoder中的作用与Encoder中类似,不同的是,它只关注当前时刻之前的位置。这种机制可以帮助模型更好地捕捉输入序列中的信息,并在生成输出序列时保留这些信息。
多头注意力机制
多头注意力机制(multi-head attention)是Decoder中的另一个子层,其作用是计算当前时刻的输入与输入序列之间的关系,并根据这些关系计算出当前时刻的上下文向量表示。
多头注意力机制将输入序列的向量表示与当前时刻的输入向量表示进行相似度计算,得到每个位置与当前时刻输入的相关度。然后,根据这些相关度计算当前时刻的上下文向量表示,用于生成输出序列。与多头自注意力机制类似,多头注意力机制也采用了分头处理的方法,从而更好地捕捉不同方面的特征。
前馈网络
前馈网络在Decoder中的作用与Encoder中类似,其作用是对多头自注意力机制和多头注意力机制的输出向量进行非线性变换。前馈网络同样由两个线性变换和一个激活函数组成,其中线性变换将输入向量映射到一个高维空间,激活函数将这个高维向量进行非线性变换,最后再将其映射回原始维度。
损失函数
Transformer模型使用了交叉熵损失函数(cross-entropy loss)作为优化目标,其目标是最小化模型生成的序列与目标序列之间的差异。具体来说,对于给定的输入序列和目标序列,Transformer模型通过最大化目标序列中每个位置的条件概率来生成输出序列。
4,总结
Transformer模型通过引入自注意力机制和多头注意力机制来替代传统的循环神经网络和卷积神经网络,从而提高了模型的表现。同时,Transformer模型还采用了分头处理和残差连接等技术,进一步提高了模型的效率和表现。该模型在机器翻译等任务中取得了极高的性能,成为自然语言处理领域的经典模型之一。

















 129
129

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









