




Internal data representation of a convolutional neural network does not take into account important spatial hierachies between simple and complex objects.(Hinton)
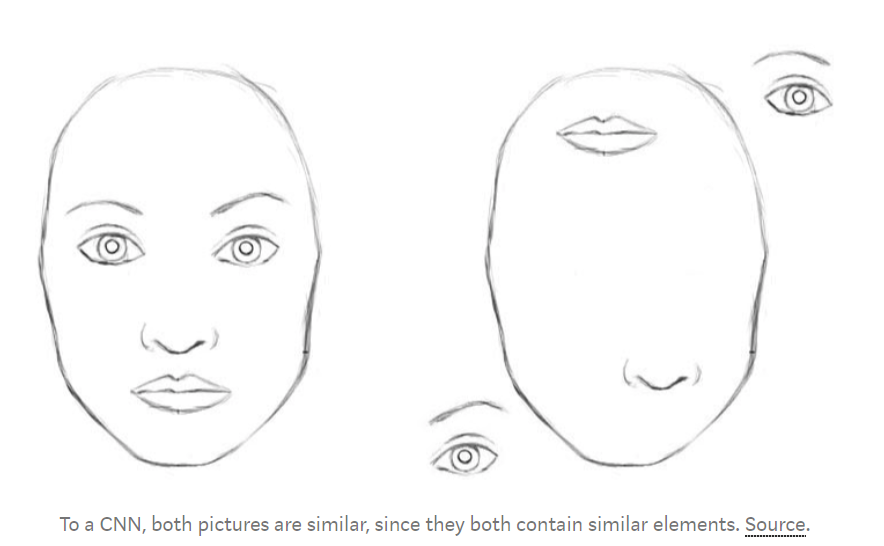
For a CNN, a mere presence of these objects can be a very strong indicator to consider that there is a face in the image. Orientational and relative spatial relationships between these components are not very important to a CNN.
intuition:
representation of objects in the brain does not depend on view angle
So at this point the question is: how do we model these hierarchical relationships inside of a neural network? The answer comes from computer graphics. In 3D graphics, relationships between 3D objects can be represented by a so-called pose, which is in essence traslation plus rotation.
in order to correctly do classification and object recognition, it is important to preserve hierarchcical pose relationships between object parts.
benifits:
- cut error rate by 45%
- only using a fraction of data that a CNN would use
Capsule:
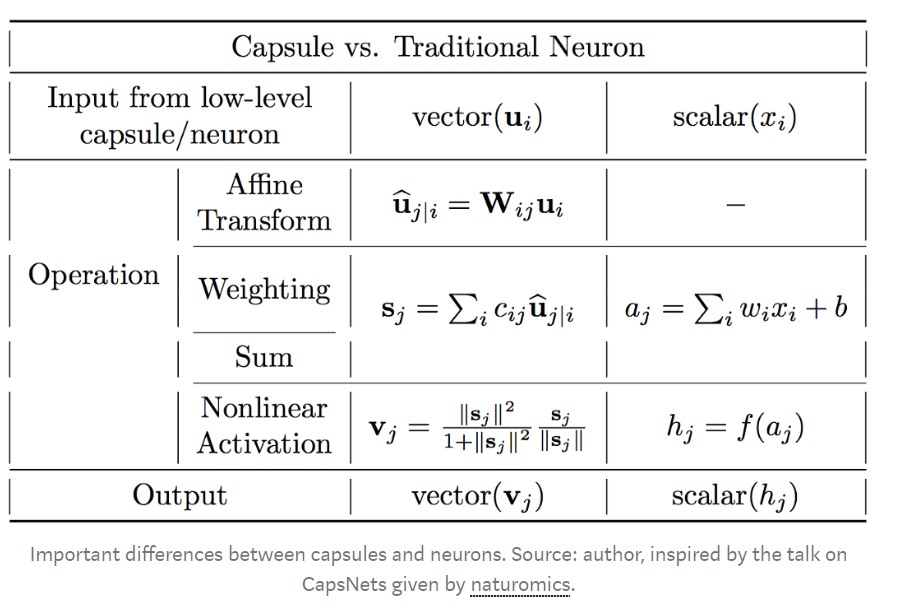
Capsules encapsulate all important information about the state of the feature they are detecting in vector form.
Capsules encode probability of detection of a feature as the length of their output vector. And the state of the detected feature is encoded as the direction in which that vector points to. So when detected feature moves around the image or its state somehow changes, the probability still stays the same(length of vector does not change), but its orientation changes.
Activities equivariance:
Neuronal activites will change when an object “moves over the manifold of possible appearances” in the picture. At the same time, the probabilities of detection remain constant, which is the form of invariance that we should aim at, and not the type offered by CNNs with max pooling.
How does a capsule work?
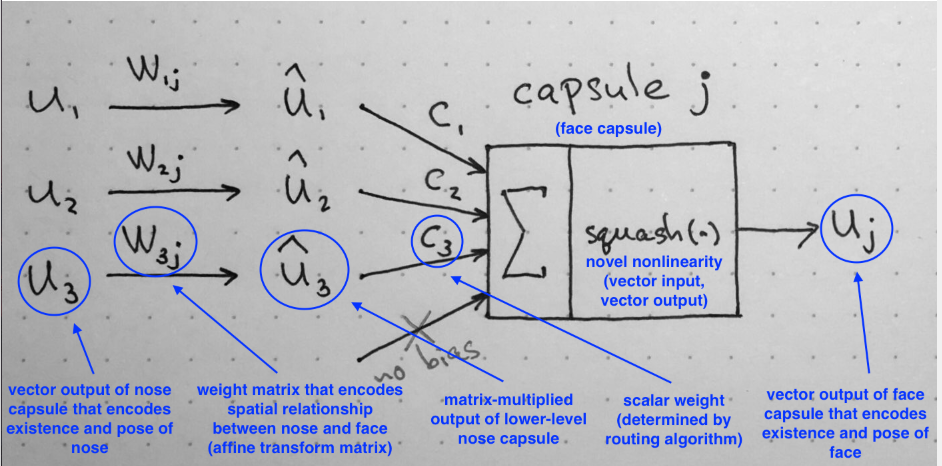
Lengths of input vectors encode probabilities that lower-level capsules detected their corresponding objects and directions of the vectors encode some internal state of the detected objects.
These vectors then are multiplied by corresponding weight matrices W that encode important spatial and other relationships between lower level features(eye, mouth and nose) and higher level feature(face). (For example, matrix W2j may encode relationship between nose and face: face is centered around its nose, its size is 10 times the size of the nose and its orientation in space corresponds to orientation of the nose, because they all lie on the same plane. )
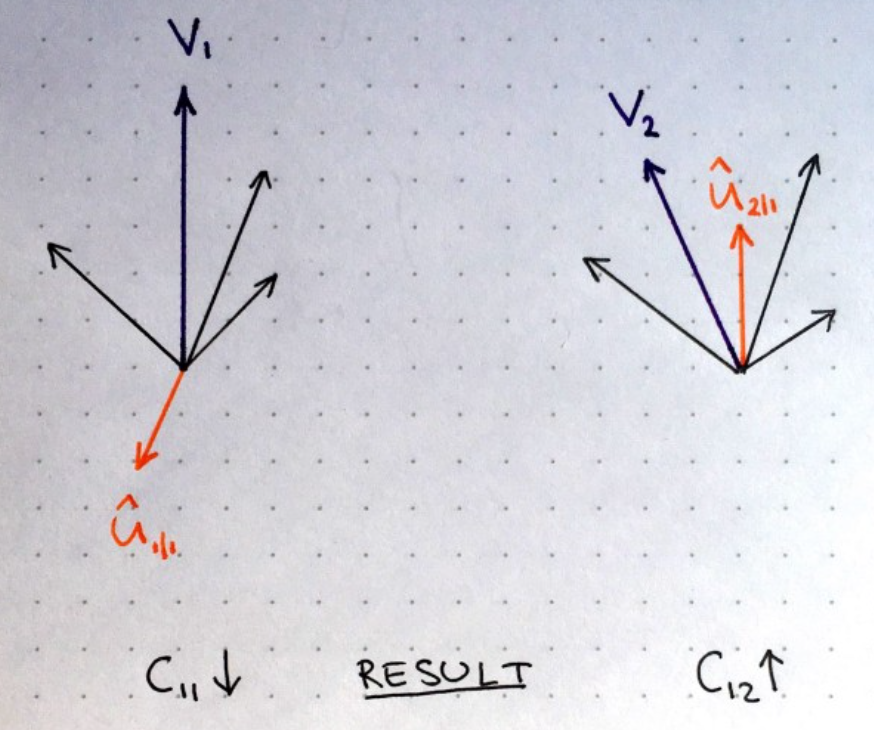
After multiplication by these matrices, what we get is the predicted position of the higher level feature. In other words, u1hat represents where the face should be according to the detected position of the eyes, u2hat represents where the face should be according to the detected position of the mouth and u3hat represents where the face should be according to the detected position of the nose.
At this point your intuition should go as follows: if these 3 predictions of lower level features point at the same position and state of the face, then it must be a face there.

Scalar Weighting of Input Vectors
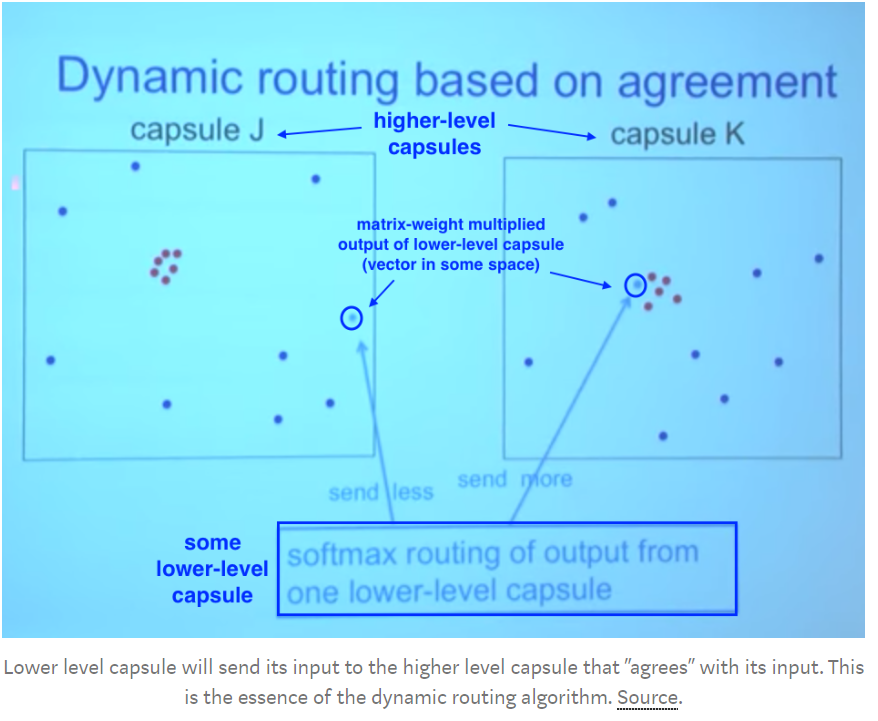
Where these points cluster together, this means that predictions of lower level capsules are close to each other.
Essence of the dynamic routing algorithm: Lower level capsule has a mechanism of measuring which upper level capsule better accommodates its results and will automatically adjust its weight in such a way that weight C corresponding to capsule K will be high, and weight C corresponding to capsule J will be low.
“Squash”: Novel vector-to-vector nonlinearity
Another innovation that CapsNet introduce is the novel nonlinear activation function that takes a vector and then “squashes” it to have length of no more than 1, but does not change its direction.
Dynamic Routing between Capsules

For each lower level capsule iii, its weights cijc_{ij}cij define a probability distribution of its output belonging to each higher level capsule jjj.
Lower level capsule will send its input to the higher level capsule that “agrees” with its input. This is the essence of the dynamic routing algorithm.

At start of training, this new coefficient bijb_{ij}bij is initialized at zero.
Essentially, softmax enforces probabilistic nature of coefficients cijc_{ij}cij described.
At the first iteration, the value of all coefficients cijc_{ij}cij will be equal. The state of all cijc_{ij}cij being equal at initialization of the algorithm represents the state of maximum confusion and uncertainty: lower level capsules have no idea which higher level capsules will best fit their output.
Step on line 7 is where the weight update happens. This step captures the essence of the routing algorithm. The dot product looks at similarity between input to the capsule and output from the capsule. The lower level will send its output to the higher level capsule whose output is similar.

















 1167
1167

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









