






文章目录
一、参考
二、为什么要有数据库连接池
传统数据库连接的问题?
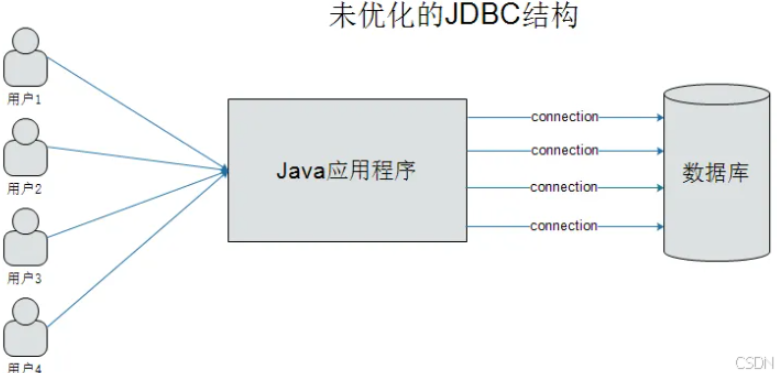
- 频繁创建和关闭连接:
- 每次执行 SQL 都需要创建连接,操作完成后关闭连接。
创建和关闭连接是非常耗时的操作(涉及网络通信、身份验证等)。
- 资源浪费:
- 连接对象占用系统资源(如内存、CPU)。
- 频繁创建和关闭连接会导致资源浪费。
- 性能瓶颈:
- 高并发场景下,频繁创建连接会导致数据库性能下降。
- 连接数限制:
- 数据库对同时打开的连接数有限制,频繁创建连接可能导致连接数耗尽
连接池的优势
- 复用连接: 连接池预先创建一定数量的连接,应用程序从池中获取连接,使用完毕后归还连接。
- 减少开销: 避免了频繁创建和关闭连接的开销,提高了性能。
- 资源控制: 可以限制最大连接数,防止数据库连接数过多导致资源耗尽。
- 提高响应速度: 连接池中的连接是预先创建的,应用程序可以快速获取连接。
连接池的工作原理
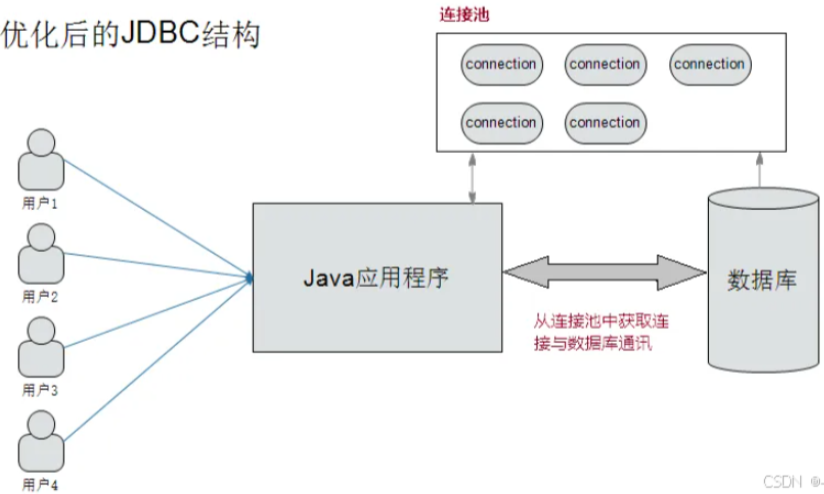
核心组件:
-
连接池管理器: 负责创建、管理和销毁连接池。
-
连接池: 维护一组数据库连接,提供连接的获取和归还功能。
-
空闲连接: 当前未被使用的连接,存放在连接池中。
-
活动连接: 当前正在被使用的连接。
工作流程:
- 初始化连接池: 在应用程序启动时,连接池会预先创建一定数量的数据库连接。
- 获取连接:
- 应用程序从连接池中请求一个连接。
如果池中有空闲连接,则直接返回;如果没有空闲连接且未达到最大连接数,则创建新连接;如果已达到最大连接数,则等待或抛出异常。
- 使用连接: 应用程序使用连接执行数据库操作。
- 归还连接: 操作完成后,应用程序将连接归还给连接池,而不是关闭连接。
- 连接回收: 连接池会定期检查连接的有效性,回收无效连接并创建新连接。
三、常用连接池对比
常见的连接池有C3P0、Druid、HikariCP 、DBCP
-
JDBC的数据库连接池使用javax.sql.DataSource来表示,DataSource只是一个接口,该接口通常由第三方来实现。
-
C3P0数据库连接池,速度相对较慢(只是慢一丢丢),但是稳定性很好,Hibernate,Spring底层用的就是C3P0。
-
DBCP数据库连接池,速度比C3P0快,但是稳定性差。
-
Proxool数据库连接池,有监控连接池状态的功能,但稳定性仍然比C3P0差一些。
-
BoneCP数据库连接池,速度较快。
-
Druid数据库连接池(德鲁伊连接池),由阿里提供,集DBCP,Proxool,C3P0连接池的优点于一身,是日常项目开发中使用频率最高的数据库连接池。
-
HikariCP:HikariCP是一个轻量级、高效的JDBC连接池,具有快速启动和低延迟的特点。 HikariCP的设计目标是提供极佳的性能和可靠性,同时尽量减少资源消耗和开销。HikariCP支持各种JDBC驱动程序和数据源。相比于其他连接池,HikariCP配置简单,易于使用。
| 特性 | HikariCP | Apache Commons DBCP | Tomcat JDBC Pool | H2 Database Connection Pool | c3p0 | Druid |
|---|---|---|---|---|---|---|
| 性能 | 非常高 | 一般 | 一般 | 一般 | 一般 | 非常高 |
| 配置简单性 | 高 | 中等 | 中等 | 低 | 中等 | 中等 |
| 可定制性 | 中等 | 中等 | 低 | 低 | 高 | 高 |
| 监控和统计功能 | 有 | 无 | 无 | 无 | 无 | 有 |
| 防火墙功能 | 无 | 无 | 无 | 无 | 无 | 有 |
| 社区活跃度 | 高 | 中等 | 中等 | 低 | 中等 | 高 |
| 适用场景 | 各种场景 | 一般场景 | Tomcat 环境 | 嵌入式数据库场景 | 各种场景 | 大型互联网企业环境 |
| 是否支持连接池复用 | 是 | 是 | 是 | 是 | 是 | 是 |
| 支持的数据库 | 所有主流数据库 | 所有主流数据库 | 所有主流数据库 | H2 Database | 所有主流数据库 | 所有主流数据库 |
目前主流使用 Druid 和 HikariCP 数据库连接池
-
HikariCP,号称性能最好的数据库连接池。Spring Boot 2.X 版本,默认采用 HikariCP 。
-
Druid,为监控而生的数据库连接池。阿里大规模采用 Druid 。
HikariCP 连接池
-
HikariCP 是一个高性能的 JDBC 连接池实现,以其轻量、快速和简单著称。它的设计目标是尽可能减少开销,提供最快的数据库连接获取速度。
-
特点
- 轻量:代码量少,依赖少。
- 高性能:在大多数场景下性能优于其他连接池。
- 简单易用:配置简单,开箱即用。
- 可靠性高:经过严格测试,稳定性强。
- HikariCP 通过优化代码和减少锁竞争,显著提高了连接获取的速度
- 减少了不必要的对象创建和垃圾回收,降低了 JVM 的开销
- 自动维护连接池的健康状态,回收无效连接
HikariCP 单数据源
- 引入依赖
<dependencies>
<!--此依赖默认使用Hikari连接池,实现对数据库连接池的自动化配置-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<!-- 默认版本是 8.0.22-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.22</version>
</dependency>
</dependencies>
- 在application.yml中,添加 HikariCP 配置
server:
port: 8010
spring:
#配置数据源
datasource:
url: jdbc:mysql://localhost:33306/atguigudb?useUnicode=true&characterEncoding=utf-8&useSSL=true&serverTimezone=UTC
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: 123456
type: com.zaxxer.hikari.HikariDataSource
hikari:
# 连接池中允许的最小连接数。缺省值:10
minimum-idle: 10
# 连接池中允许的最大连接数。缺省值:10
maximum-pool-size: 100
# 自动提交
auto-commit: true
# 一个连接idle状态的最大时长(毫秒),超时则被释放(retired),缺省:10分钟
idle-timeout: 600
# 连接池名字
pool-name: 泡泡的HikariCP
# 一 个连接的生命时长(毫秒),超时而且没被使用则被释放(retired),缺省:30分钟,建议设置比数据库超时时长少30秒
max-lifetime: 1800000
# 等待连接池分配连接的最大时长(毫秒),超过这个时长还没可用的连接则发生SQLException, 缺省:30秒
connection-timeout: 30000
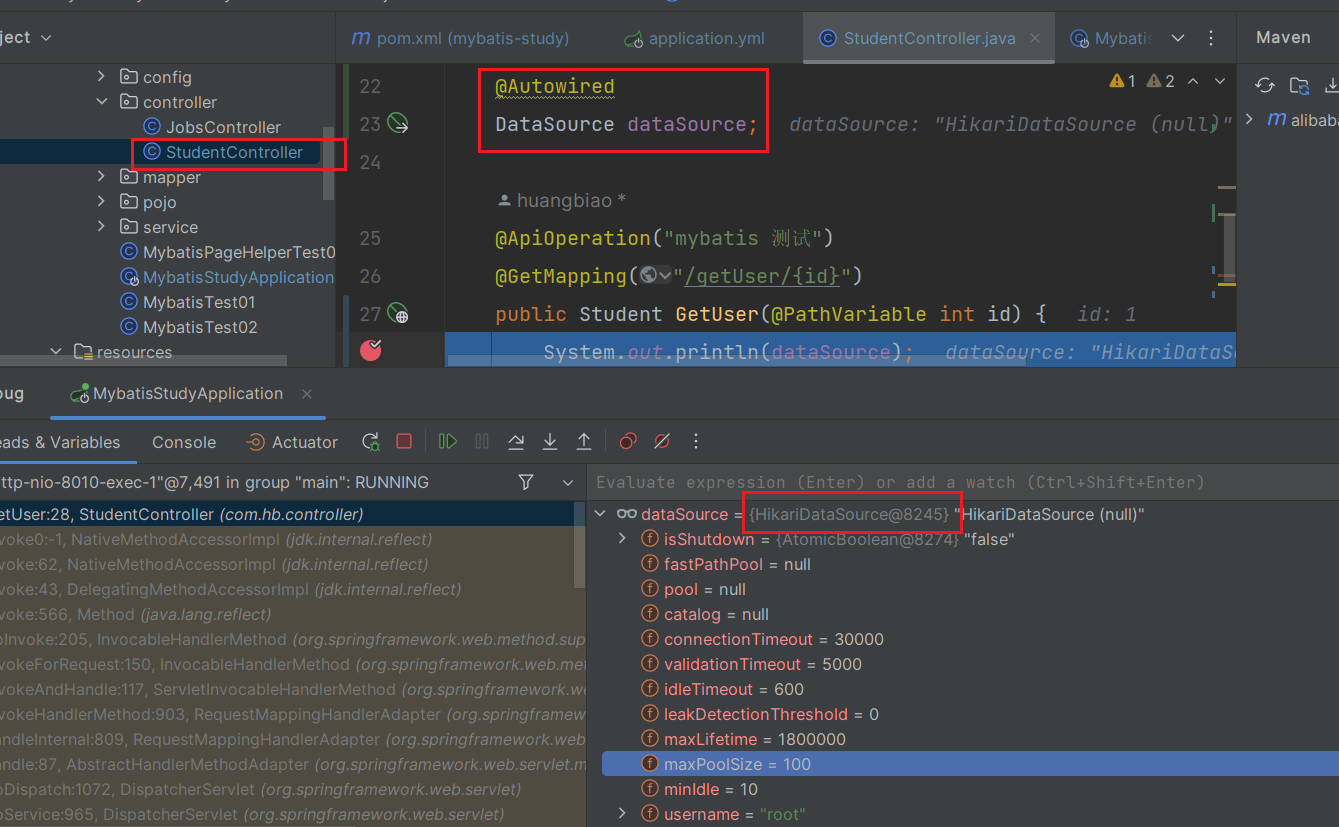
- 定义控制器,调用数据库
package com.hb.controller;
import com.hb.pojo.Student;
import com.hb.service.StudentService;
import io.swagger.annotations.Api;
import io.swagger.annotations.ApiOperation;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RestController;
import javax.sql.DataSource;
@RestController
@Api(tags = {"Student模块"}, value = "数据字典控制器")
public class StudentController {
@Autowired
private StudentService studentService;
@Autowired
DataSource dataSource;
@ApiOperation("mybatis 测试")
@GetMapping("/getUser/{id}")
public Student GetUser(@PathVariable int id) {
System.out.println(dataSource);
Student student = studentService.sell(id);
return student;
}
}
HikariCP 多数据源
后续补充
Druid 连接池
-
Druid 是阿里巴巴开源的数据库连接池实现**,除了高性能外,还提供了丰富的监控和统计功能,适合需要深度监控和管理的场景**
-
特点
- 高性能:性能接近 HikariCP。
- 功能丰富:支持 SQL 监控、防火墙、加密等功能。
- 监控强大:内置监控页面,支持实时查看连接池状态和 SQL 执行情况。
- 扩展性强:支持自定义过滤器
-
核心优势
- SQL 监控:可以监控 SQL 的执行时间、执行次数等,帮助优化 SQL 性能。
- 防火墙功能:提供 SQL 防火墙,防止恶意 SQL 注入。
- 加密支持:支持数据库密码加密,提高安全性。
- 扩展性:支持自定义过滤器,方便扩展功能
druid 使用案例
- 引入依赖
<dependencies>
<!-- 如果使用druid-spring-boot-starter, 那么需要在启动类上使用@SpringBootApplication(exclude = DruidDataSourceAutoConfigure.class) -->
<!--引入druid数据源-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.2.16</version>
</dependency>
<!-- 默认版本是 8.0.22-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.22</version>
</dependency>
</dependencies>
- 在application.yml中,添加 druid 配置
一定要指明 spring.datasource.type = com.alibaba.druid.pool.DruidDataSource , 表明现在使用的事 druid 连接池
server:
port: 8010
spring:
#配置数据源
datasource:
url: jdbc:mysql://localhost:33306/atguigudb?useUnicode=true&characterEncoding=utf-8&useSSL=true&serverTimezone=UTC
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: 123456
# druid-spring-boot-starter 依赖自动生效 druid,可以不配置 type 属性,但建议配置
type: com.alibaba.druid.pool.DruidDataSource
druid:
initial-size: 10 # 初始化时建立物理连接的个数。初始化发生在显示调用init方法,或者第一次getConnection时
min-idle: 10 # 最小连接池数量
maxActive: 200 # 最大连接池数量
maxWait: 60000 # 获取连接时最大等待时间,单位毫秒。配置了maxWait之后,缺省启用公平锁,并发效率会有所下降,如果需要可以通过配置
timeBetweenEvictionRunsMillis: 60000 # 关闭空闲连接的检测时间间隔.Destroy线程会检测连接的间隔时间,如果连接空闲时间大于等于minEvictableIdleTimeMillis则关闭物理连接。
minEvictableIdleTimeMillis: 300000 # 连接的最小生存时间.连接保持空闲而不被驱逐的最小时间
# WebStatFilter:用于收集 Web 应用程序的 SQL 慢查询日志。
web-stat-filter:
enabled: true
# StatViewServlet:提供了一个可视化的监控页面,可以查看连接池的各项指标。
stat-view-servlet: # http://localhost:8010/druid/index.html 访问监控界面
enabled: true
url-pattern: /druid/*
login-username: druid
login-password: druid
# allow: 127.0.0.1可根据需要配置IP白名单
# deny: 可根据需要配置IP黑名单
validationQuery: SELECT 1 FROM DUAL # 验证数据库服务可用性的sql.用来检测连接是否有效的sql 因数据库方言而差, 例如 oracle 应该写成 SELECT 1 FROM DUAL
testWhileIdle: true # 申请连接时检测空闲时间,根据空闲时间再检测连接是否有效.建议配置为true,不影响性能,并且保证安全性。申请连接的时候检测,如果空闲时间大于timeBetweenEvictionRun
testOnBorrow: false # 申请连接时直接检测连接是否有效.申请连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能。
testOnReturn: false # 归还连接时检测连接是否有效.归还连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能。
poolPreparedStatements: true # 开启PSCache
maxPoolPreparedStatementPerConnectionSize: 20 #设置PSCache值
connectionErrorRetryAttempts: 3 # 连接出错后再尝试连接三次
breakAfterAcquireFailure: true # 数据库服务宕机自动重连机制
timeBetweenConnectErrorMillis: 300000 # 连接出错后重试时间间隔
asyncInit: true # 异步初始化策略
remove-abandoned: true # 是否自动回收超时连接
remove-abandoned-timeout: 1800 # 超时时间(以秒数为单位)
transaction-query-timeout: 6000 # 事务超时时间
filters: stat,wall,log4j2
useGlobalDataSourceStat: true #合并多个DruidDataSource的监控数据
connectionProperties: druid.stat.mergeSql\=true;druid.stat.slowSqlMillis\=5000 #通过connectProperties
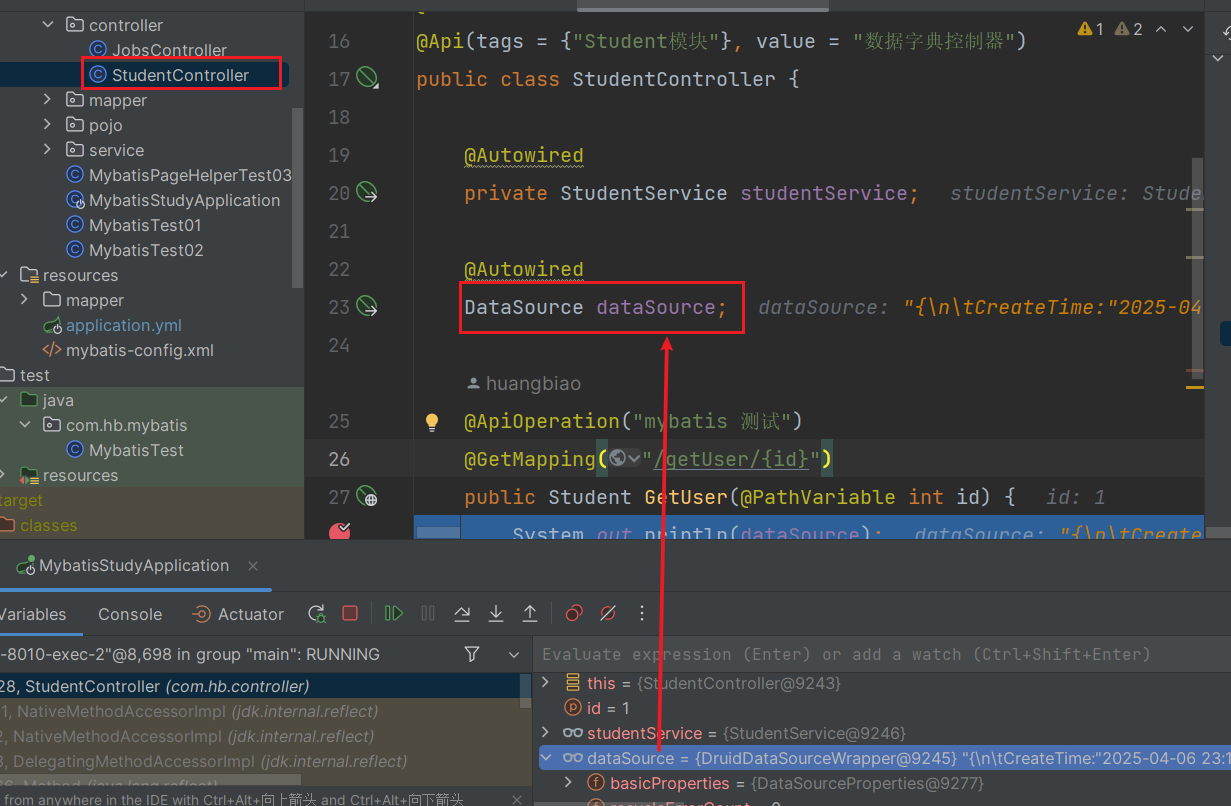
- 定义控制器,调用数据库
package com.hb.controller;
import com.hb.pojo.Student;
import com.hb.service.StudentService;
import io.swagger.annotations.Api;
import io.swagger.annotations.ApiOperation;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RestController;
import javax.sql.DataSource;
@RestController
@Api(tags = {"Student模块"}, value = "数据字典控制器")
public class StudentController {
@Autowired
private StudentService studentService;
@Autowired
DataSource dataSource;
@ApiOperation("mybatis 测试")
@GetMapping("/getUser/{id}")
public Student GetUser(@PathVariable int id) {
System.out.println(dataSource);
Student student = studentService.sell(id);
return student;
}
}
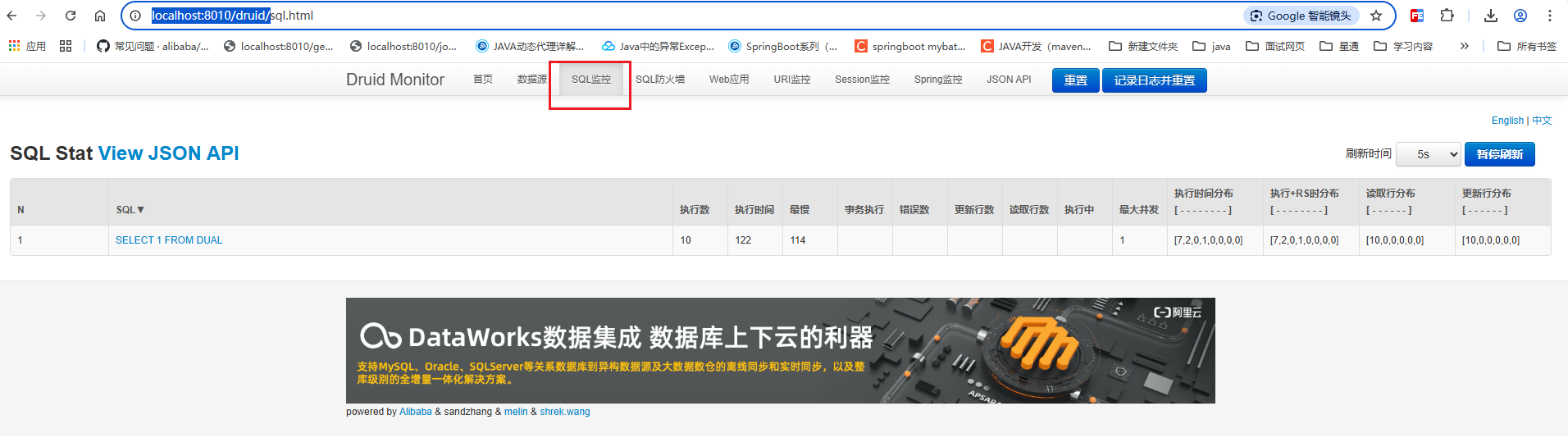
durid 监控界面
- springboot 添加开启监控页面的配置
server:
port: 8010
spring:
#配置数据源
datasource:
url: jdbc:mysql://localhost:33306/atguigudb?useUnicode=true&characterEncoding=utf-8&useSSL=true&serverTimezone=UTC
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: 123456
# druid-spring-boot-starter 依赖自动生效 druid,可以不配置 type 属性,但建议配置
type: com.alibaba.druid.pool.DruidDataSource
druid:
# WebStatFilter:用于收集 Web 应用程序的 SQL 慢查询日志。
web-stat-filter:
enabled: true
# StatViewServlet:提供了一个可视化的监控页面,可以查看连接池的各项指标。
stat-view-servlet: # http://localhost:8010/druid/index.html 访问监控界面
enabled: true
url-pattern: /druid/*
login-username: druid
login-password: druid
# allow: 127.0.0.1可根据需要配置IP白名单
# deny: 可根据需要配置IP黑名单
- 浏览器输入
http://localhost:8010/druid/

















 4420
4420

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









