







转载:http://www.importnew.com/21353.html
1. 锁优化的思路和方法
锁优化的思路和方法有以下几种:
- 减少锁持有时间
- 减小锁粒度
- 锁分离
- 锁粗化
- 锁消除
1.1 减少锁持有时间
public synchronized void syncMethod(){
othercode1();
mutextMethod();
othercode2();
}像上述代码这样,在进入方法前就要得到锁,其他线程就要在外面等待。
这里优化的一点在于,要减少其他线程等待的时间,所以,只需要在有线程安全要求的程序代码上加锁。
public void syncMethod(){
othercode1();
synchronized(this)
{
mutextMethod();
}
othercode2();
}1.2 减小锁粒度
将大对象(这个对象可能会被很多线程访问),拆成小对象,大大增加并行度,降低锁竞争。降低了锁的竞争,偏向锁,轻量级锁成功率才会提高。
最最典型的减小锁粒度的案例就是ConcurrentHashMap。
1.3 锁分离
最常见的锁分离就是读写锁ReadWriteLock,根据功能进行分离成读锁和写锁,这样读读不互斥,读写互斥,写写互斥。即保证了线程安全,又提高了性能。
读写分离思想可以延伸,只要操作互不影响,锁就可以分离。
比如LinkedBlockingQueue
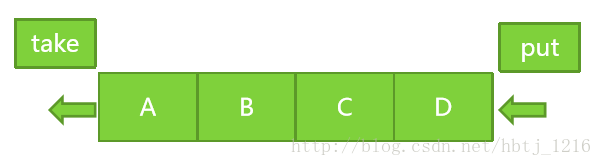
从头部取出数据,从尾部放入数据,使用两把锁。
1.4 锁粗化
通常情况下,为了保证多线程间的有效并发,会要求每个线程持有锁的时间尽量短,即在使用完公共资源后,应该立即释放锁。只有这样,等待在这个锁上的其他线程才能尽早的获得资源执行任务。
但是,凡事都有一个度,如果对同一个锁不停的进行请求、同步和释放,其本身也会消耗系统宝贵的资源,反而不利于性能的优化 。
举个例子:
public void demoMethod(){
synchronized(lock){
//do sth.
}
//...做其他不需要的同步的工作,但能很快执行完毕
synchronized(lock){
//do sth.
}
}这种情况,根据锁粗化的思想,应该合并:
public void demoMethod(){
//整合成一次锁请求
synchronized(lock){
//do sth.
//...做其他不需要的同步的工作,但能很快执行完毕
}
}当然这是有前提的,前提就是中间的那些不需要同步的工作是很快执行完成的。
再举一个极端的例子:
for(int i = 0; i < CIRCLE; i++){
synchronized(lock){
//...
}
}在一个循环内不同得获得锁。虽然JDK内部会对这个代码做些优化,但是还不如直接写成:
synchronized(lock){
for(int i=0;i<CIRCLE;i++){
}
}当然如果有需求说,这样的循环太久,需要给其他线程不要等待太久,那只能写成上面那种。如果没有这样类似的需求,还是直接写成下面那种比较好。
1.5 锁消除
锁消除是在编译器级别的事情。
在即时编译器时,如果发现不可能被共享的对象,则可以消除这些对象的锁操作。
也许你会觉得奇怪,既然有些对象不可能被多线程访问,那为什么要加锁呢?写代码时直接不加锁不就好了。
但是有时,这些锁并不是程序员所写的,有的是JDK实现中就有锁的,比如Vector和StringBuffer这样的类,它们中的很多方法都是有锁的。当我们在一些不会有线程安全的情况下使用这些类的方法时,达到某些条件时,编译器会将锁消除来提高性能。
比如:
public static void main(String args[]) throws InterruptedException {
long start = System.currentTimeMillis();
for (int i = 0; i < 2000000; i++) {
createStringBuffer("JVM", "Diagnosis");
}
long bufferCost = System.currentTimeMillis() - start;
System.out.println("craeteStringBuffer: " + bufferCost + " ms");
}
public static String createStringBuffer(String s1, String s2) {
StringBuffer sb = new StringBuffer();
sb.append(s1);
sb.append(s2);
return sb.toString();
}上述代码中的StringBuffer.append是一个同步操作,但是StringBuffer却是一个局部变量,并且方法也并没有把StringBuffer返回,所以不可能会有多线程去访问它。
那么此时StringBuffer中的同步操作就是没有意义的。
开启锁消除是在JVM参数上设置的,当然需要在server模式下:
-server -XX:+DoEscapeAnalysis -XX:+EliminateLocks并且要开启逃逸分析。 逃逸分析的作用呢,就是看看变量是否有可能逃出作用域的范围。
比如上述的StringBuffer,上述代码中craeteStringBuffer的返回是一个String,所以这个局部变量StringBuffer在其他地方都不会被使用。如果将craeteStringBuffer改成
public static StringBuffer craeteStringBuffer(String s1, String s2) {
StringBuffer sb = new StringBuffer();
sb.append(s1);
sb.append(s2);
return sb;
}那么这个 StringBuffer被返回后,是有可能被任何其他地方所使用的(譬如被主函数将返回结果put进map啊等等)。那么JVM的逃逸分析可以分析出,这个局部变量 StringBuffer逃出了它的作用域。
所以基于逃逸分析,JVM可以判断,如果这个局部变量StringBuffer并没有逃出它的作用域,那么可以确定这个StringBuffer并不会被多线程所访问,那么就可以把这些多余的锁给去掉来提高性能。
当JVM参数为:
-server -XX:+DoEscapeAnalysis -XX:+EliminateLocks输出:
craeteStringBuffer: 302 msJVM参数为:
-server -XX:+DoEscapeAnalysis -XX:-EliminateLocks输出:
craeteStringBuffer: 660 ms显然,锁消除的效果还是很明显的。

















 2690
2690

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









