







目录
Redis的常见命令和客户端使用
一、初识Redis
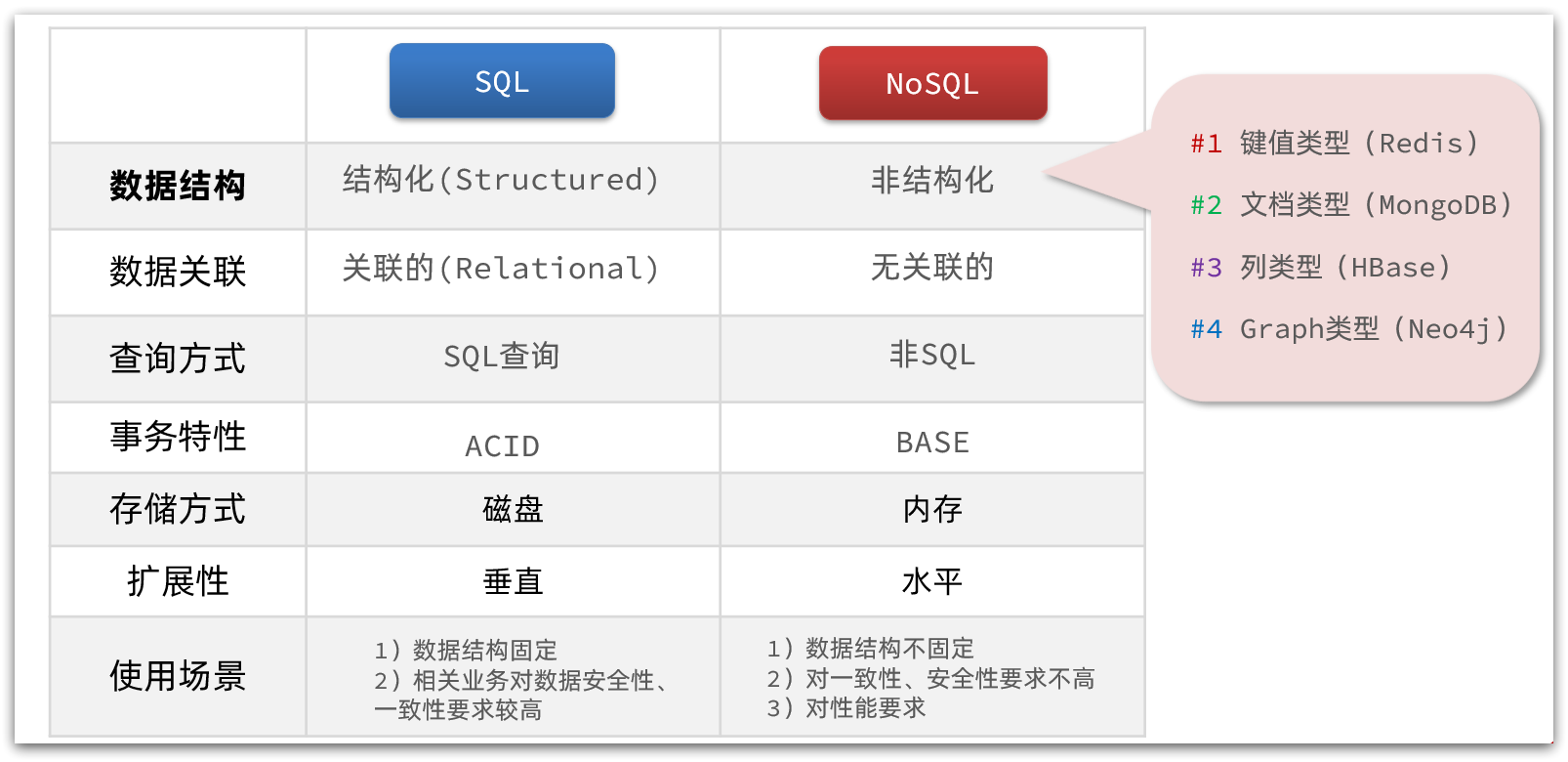
1、 认识NoSQL
NoSql可以翻译做Not Only Sql(不仅仅是SQL),或者是No Sql(非Sql的)数据库。是相对于传统关系型数据库而言,有很大差异的一种特殊的数据库,因此也称之为非关系型数据库。
关系型数据库和非关系数据库的区别
扩展性
- 关系型数据库集群模式一般是主从,主从数据一致,起到数据备份的作用,称为垂直扩展。
- 非关系型数据库可以将数据拆分,存储在不同机器上,可以保存海量数据,解决内存大小有限的问题。称为水平扩展。
- 关系型数据库因为表之间存在关联关系,如果做水平扩展会给数据查询带来很多麻烦
2、认识Redis
Redis诞生于2009年,全称是Remote Dictionary Server 远程词典服务器,是一个基于内存的键值型NoSQL数据库
特征:
- 键值(key-value)型,value支持多种不同数据结构,功能丰富
- 单线程,每个命令具备原子性
- 低延迟,速度快(基于内存、IO多路复用、良好的编码)。
- 支持数据持久化
- 支持主从集群、分片集群
- 支持多语言客户端
3、安装Redis
https://blog.csdn.net/hc1285653662/article/details/127819045
二、Redis常见命令
1、Redis通用命令
通用指令是部分数据类型的,都可以使用的指令,常见的有:
- KEYS:查看符合模板的所有key,不建议在生产环境下使用
- DEL:删除一个指定的key,返回值是删除成功的数量
- EXISTS:判断key是否存在
- EXPIRE:给一个key设置有效期,有效期到期时该key会被自动删除
- TTL:查看一个KEY的剩余有效期
通过help [command] 可以查看一个命令的具体用法,例如:
# 查看keys命令的帮助信息:
127.0.0.1:6379> help keys
KEYS pattern
summary: Find all keys matching the given pattern
since: 1.0.0
group: generic
2、String类型
String类型,也就是字符串类型,是Redis中最简单的存储类型。
其value是字符串,不过根据字符串的格式不同,又可以分为3类:
- string:普通字符串
- int:整数类型,可以做自增、自减操作
- float:浮点类型,可以做自增、自减操作
不管是哪种格式,底层都是字节数组形式存储,只不过是编码方式不同。字符串类型的最大空间不能超过512m
1)String的常见命令有:
- SET:添加或者修改已经存在的一个String类型的键值对
- GET:根据key获取String类型的value
- MSET:批量添加多个String类型的键值对
- MGET:根据多个key获取多个String类型的value
- INCR:让一个整型的key自增1
- INCRBY:让一个整型的key自增并指定步长,例如:incrby num 2 让num值自增2
- INCRBYFLOAT:让一个浮点类型的数字自增并指定步长
- SETNX:添加一个String类型的键值对,前提是这个key不存在,否则不执行
- SETEX:添加一个String类型的键值对,并且指定有效期
2)Key结构
Redis没有类似MySQL中的Table的概念,我们该如何区分不同类型的key呢?
例如,需要存储用户、商品信息到redis,有一个用户id是1,有一个商品id恰好也是1,此时如果使用id作为key,那就会冲突了,该怎么办?
我们可以通过给key添加前缀加以区分,不过这个前缀不是随便加的,有一定的规范:
Redis的key允许有多个单词形成层级结构,多个单词之间用’:'隔开,格式如下:
项目名:业务名:类型:id
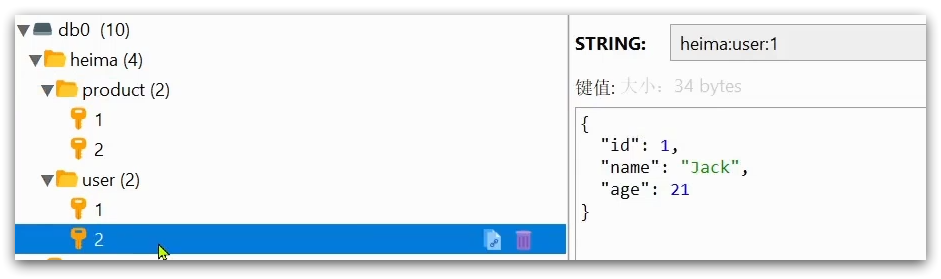
例如我们的项目名称叫 heima,有user和product两种不同类型的数据,我们可以这样定义key:
-
user相关的key:heima:user:1
-
product相关的key:heima:product:1
如果Value是一个Java对象,例如一个User对象,则可以将对象序列化为JSON字符串后存储:
| KEY | VALUE |
|---|---|
| heima:user:1 | {“id”:1, “name”: “Jack”, “age”: 21} |
| heima:product:1 | {“id”:1, “name”: “小米11”, “price”: 4999} |
并且,在Redis的桌面客户端中,还会以相同前缀作为层级结构,让数据看起来层次分明,关系清晰:
3、Hash类型
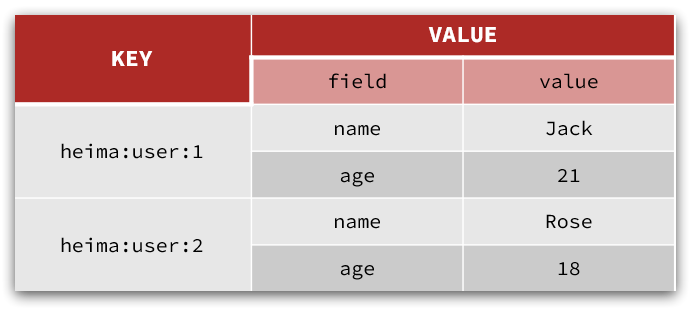
Hash类型,也叫散列,其value是一个无序字典,类似于Java中的HashMap结构。
String结构是将对象序列化为JSON字符串后存储,当需要修改对象某个字段时很不方便:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TCIleK0A-1666913999566)(Redis.assets/x2zDBjf.png)]](https://img-blog.csdnimg.cn/463f37f5833e4aceb3a1a81a1a4c198c.png)
Hash结构可以将对象中的每个字段独立存储,可以针对单个字段做CRUD:
Hash的常见命令有:
- HSET key field value:添加或者修改hash类型key的field的值
- HGET key field:获取一个hash类型key的field的值
- HMSET:批量添加多个hash类型key的field的值
- HMGET:批量获取多个hash类型key的field的值
- HGETALL:获取一个hash类型的key中的所有的field和value
- HKEYS:获取一个hash类型的key中的所有的field
- HVALS:获取一个hash类型的key中的所有的value
- HINCRBY:让一个hash类型key的字段值自增并指定步长
- HSETNX:添加一个hash类型的key的field值,前提是这个field不存在,否则不执行
4、List类型
Redis中的List类型与Java中的LinkedList类似,可以看做是一个双向链表结构。既可以支持正向检索和也可以支持反向检索。
特征也与LinkedList类似:
- 有序
- 元素可以重复
- 插入和删除快
- 查询速度一般
常用来存储一个有序数据,例如:朋友圈点赞列表,评论列表等。
List的常见命令有:
- LPUSH key element … :向列表左侧插入一个或多个元素
- LPOP key:移除并返回列表左侧的第一个元素,没有则返回nil
- RPUSH key element … :向列表右侧插入一个或多个元素
- RPOP key:移除并返回列表右侧的第一个元素
- LRANGE key star end:返回一段角标范围内的所有元素
- BLPOP和BRPOP:与LPOP和RPOP类似,只不过在没有元素时等待指定时间,而不是直接返回nil
5、Set 类型
Redis的Set结构与Java中的HashSet类似,可以看做是一个value为null的HashMap。因为也是一个hash表,因此具备与HashSet类似的特征:
- 无序
- 元素不可重复
- 查找快
- 支持交集、并集、差集等功能
Set的常见命令有:
- SADD key member … :向set中添加一个或多个元素
- SREM key member … : 移除set中的指定元素
- SCARD key: 返回set中元素的个数
- SISMEMBER key member:判断一个元素是否存在于set中
- SMEMBERS:获取set中的所有元素
- SINTER key1 key2 … :求key1与key2的交集
- SDIFF key1 key2 : 求key1与key2的差集,就是key1有的,key2没的
- SUNION key1 key2 : 求key1与key2的并集
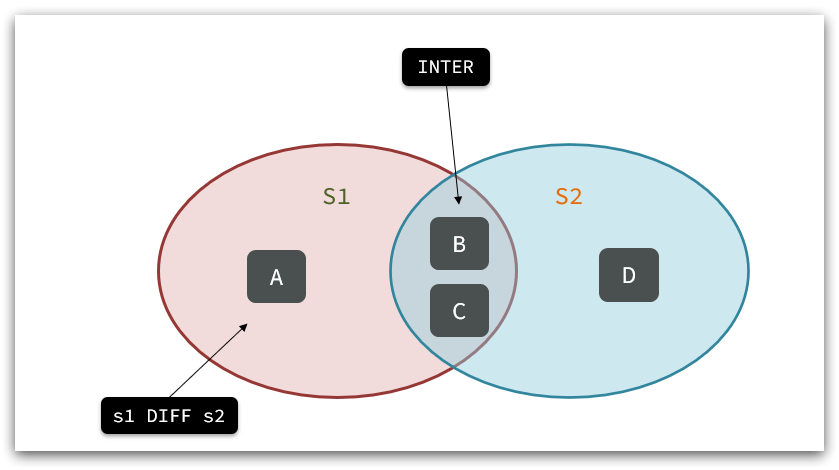
例如两个集合:s1和s2:
求交集:SINTER s1 s2
求s1与s2的不同:SDIFF s1 s2
6、SortedSet类型
SortedSet中的每一个元素都带有一个score属性,可以基于score属性对元素排序,底层的实现是一个跳表(SkipList)加 hash表。
SortedSet具备下列特性:
- 可排序
- 元素不重复
- 查询速度快
因为SortedSet的可排序特性,经常被用来实现排行榜这样的功能。
SortedSet的常见命令有:
- ZADD key score member:添加一个或多个元素到sorted set ,如果已经存在则更新其score值
- ZREM key member:删除sorted set中的一个指定元素
- ZSCORE key member : 获取sorted set中的指定元素的score值
- ZRANK key member:获取sorted set 中的指定元素的排名
- ZCARD key:获取sorted set中的元素个数
- ZCOUNT key min max:统计score值在给定范围内的所有元素的个数
- ZINCRBY key increment member:让sorted set中的指定元素自增,步长为指定的increment值
- ZRANGE key min max:按照score排序后,获取指定排名范围内的元素
- ZRANGEBYSCORE key min max:按照score排序后,获取指定score范围内的元素
- ZDIFF、ZINTER、ZUNION:求差集、交集、并集
注意:所有的排名默认都是升序,如果要降序则在命令的Z后面添加REV即可,例如:
- 升序获取sorted set 中的指定元素的排名:ZRANK key member
- 降序获取sorted set 中的指定元素的排名:ZREVRANK key memeber
三、Redis客户端
在Redis官网中提供了各种语言的客户端,地址:https://redis.io/docs/clients/

其中Java客户端也包含很多:
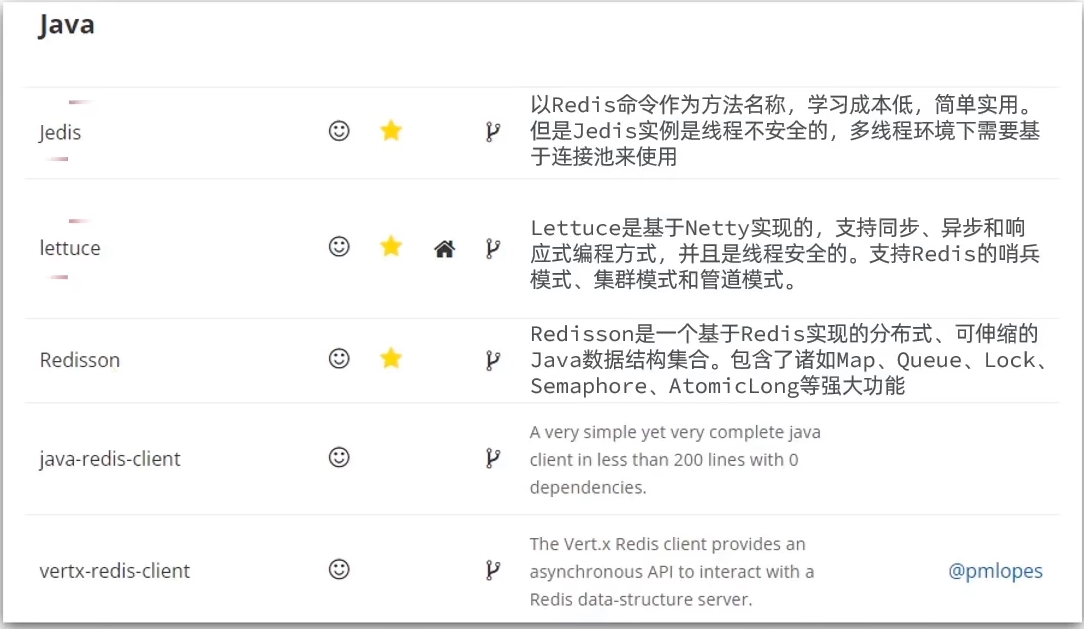
标记为*的就是推荐使用的java客户端,包括:
- Jedis和Lettuce:这两个主要是提供了Redis命令对应的API,方便我们操作Redis,而SpringDataRedis又对这两种做了抽象和封装,因此我们后期会直接以SpringDataRedis来学习。
- Redisson:是在Redis基础上实现了分布式的可伸缩的java数据结构,例如Map、Queue等,而且支持跨进程的同步机制:Lock、Semaphore等待,比较适合用来实现特殊的功能需求。
1、Jedis快速入门
1)引入依赖:
<!--jedis-->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.7.0</version>
</dependency>
<!--单元测试-->
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter</artifactId>
<version>5.7.0</version>
<scope>test</scope>
</dependency>
2)建立连接
新建一个单元测试类,内容如下:
private Jedis jedis;
@BeforeEach
void setUp() {
// 1.建立连接
// jedis = new Jedis("192.168.150.101", 6379);
jedis = JedisConnectionFactory.getJedis();
// 2.设置密码
jedis.auth("123321");
// 3.选择库
jedis.select(0);
}
3)测试:
@Test
void testString() {
// 存入数据
String result = jedis.set("name", "虎哥");
System.out.println("result = " + result);
// 获取数据
String name = jedis.get("name");
System.out.println("name = " + name);
}
@Test
void testHash() {
// 插入hash数据
jedis.hset("user:1", "name", "Jack");
jedis.hset("user:1", "age", "21");
// 获取
Map<String, String> map = jedis.hgetAll("user:1");
System.out.println(map);
}
4)释放资源
@AfterEach
void tearDown() {
if (jedis != null) {
jedis.close();
}
}
- 连接池
Jedis本身是线程不安全的,并且频繁的创建和销毁连接会有性能损耗,因此我们推荐大家使用Jedis连接池代替Jedis的直连方式。
package com.heima.jedis.util;
import redis.clients.jedis.*;
public class JedisConnectionFactory {
private static JedisPool jedisPool;
static {
// 配置连接池
JedisPoolConfig poolConfig = new JedisPoolConfig();
poolConfig.setMaxTotal(8);
poolConfig.setMaxIdle(8
poolConfig.setMinIdle(0);
poolConfig.setMaxWaitMillis(1000);
// 创建连接池对象,参数:连接池配置、服务端ip、服务端端口、超时时间、密码
jedisPool = new JedisPool(poolConfig, "192.168.150.101", 6379, 1000, "123321");
}
public static Jedis getJedis(){
return jedisPool.getResource();
}
}
2、SpringDataRedis客户端
SpringData是Spring中数据操作的模块,包含对各种数据库的集成,其中对Redis的集成模块就叫做SpringDataRedis,官网地址:https://spring.io/projects/spring-data-redis
- 提供了对不同Redis客户端的整合(Lettuce和Jedis)
- 提供了RedisTemplate统一API来操作Redis
- 支持Redis的发布订阅模型
- 支持Redis哨兵和Redis集群
- 支持基于Lettuce的响应式编程
- 支持基于JDK、JSON、字符串、Spring对象的数据序列化及反序列化
- 支持基于Redis的JDKCollection实现
SpringDataRedis中提供了RedisTemplate工具类,其中封装了各种对Redis的操作。并且将不同数据类型的操作API封装到了不同的类型中:

1)、快速入门
1)引入依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.5.7</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.heima</groupId>
<artifactId>redis-demo</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>redis-demo</name>
<description>Demo project for Spring Boot</description>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<!--redis依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!--common-pool 兼容jedis和lu-->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>
<!--Jackson依赖-->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build>
</project>
2)配置Redis
spring:
redis:
host: 192.168.150.101
port: 6379
password: 123321
lettuce:
pool:
max-active: 8
max-idle: 8
min-idle: 0
max-wait: 100ms
3)注入RedisTemplate
因为有了SpringBoot的自动装配,我们可以拿来就用:
@SpringBootTest
class RedisStringTests {
@Autowired
private RedisTemplate redisTemplate;
}
4)编写测试
@SpringBootTest
class RedisStringTests {
@Autowired
private RedisTemplate edisTemplate;
@Test
void testString() {
// 写入一条String数据
redisTemplate.opsForValue().set("name", "虎哥");
// 获取string数据
Object name = stringRedisTemplate.opsForValue().get("name");
System.out.println("name = " + name);
}
}
2) 自定义序列化
RedisTemplate可以接收任意Object作为值写入Redis:

只不过写入前会把Object序列化为字节形式,默认是采用JDK序列化,得到的结果是这样的:

缺点:
- 可读性差
- 内存占用较大
我们可以自定义RedisTemplate的序列化方式,代码如下:
@Configuration
public class RedisConfig {
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory connectionFactory){
// 创建RedisTemplate对象
RedisTemplate<String, Object> template = new RedisTemplate<>();
// 设置连接工厂
template.setConnectionFactory(connectionFactory);
// 创建JSON序列化工具
GenericJackson2JsonRedisSerializer jsonRedisSerializer =
new GenericJackson2JsonRedisSerializer();
// 设置Key的序列化
template.setKeySerializer(RedisSerializer.string());
template.setHashKeySerializer(RedisSerializer.string());
// 设置Value的序列化
template.setValueSerializer(jsonRedisSerializer);
template.setHashValueSerializer(jsonRedisSerializer);
// 返回
return template;
}
}
这里采用了JSON序列化来代替默认的JDK序列化方式。最终结果如图:
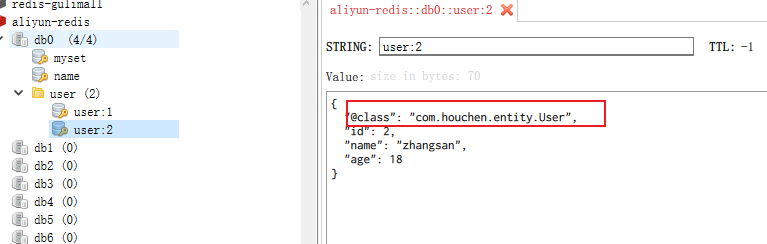
整体可读性有了很大提升,并且能将Java对象自动的序列化为JSON字符串,并且查询时能自动把JSON反序列化为Java对象。不过,其中记录了序列化时对应的class名称,目的是为了查询时实现自动反序列化。这会带来额外的内存开销。
3)StringRedisTemplate
为了节省内存空间,我们可以不使用JSON序列化器来处理value,而是统一使用String序列化器,要求只能存储String类型的key和value。当需要存储Java对象时,手动完成对象的序列化和反序列化。
这种用法比较普遍,因此SpringDataRedis就提供了RedisTemplate的子类:StringRedisTemplate,它的key和value的序列化方式默认就是String方式。
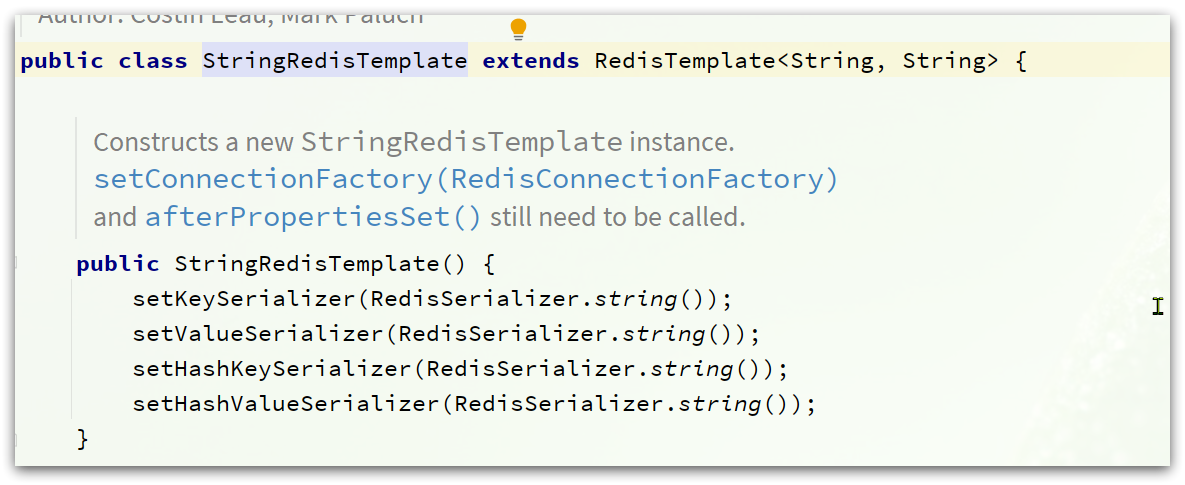
省去了我们自定义RedisTemplate的序列化方式的步骤,而是直接使用:
@Autowired
private StringRedisTemplate stringRedisTemplate;
// JSON序列化工具
private static final ObjectMapper mapper = new ObjectMapper();
@Test
void testSaveUser() throws JsonProcessingException {
// 创建对象
User user = new User("虎哥", 21);
// 手动序列化
String json = mapper.writeValueAsString(user);
// 写入数据
stringRedisTemplate.opsForValue().set("user:200", json);
// 获取数据
String jsonUser = stringRedisTemplate.opsForValue().get("user:200");
// 手动反序列化
User user1 = mapper.readValue(jsonUser, User.class);
System.out.println("user1 = " + user1);
}
四、扩展
1、为什么jedis是线程不安全的?
Jedis 是一个 Java 客户端库,用于与 Redis 数据库进行交互。Jedis 的线程不安全性主要来自以下几个方面:
-
非线程安全的状态: Jedis 实例本身不是线程安全的。多个线程共享同一个 Jedis 实例时,它们可能会同时修改实例的内部状态,导致竞态条件。例如,多个线程可以同时在同一个 Jedis 实例上执行命令,这可能导致不一致的结果。
-
连接不安全: Jedis 在内部维护了一个连接池,但这个连接池不是线程安全的。多个线程可以同时从连接池中获取连接并执行操作,这可能导致连接的状态混乱。
-
不同线程之间的状态共享: 在某些情况下,Jedis 可能会在不同线程之间共享状态,这会导致问题。例如,如果一个线程订阅了一个频道,而另一个线程尝试取消订阅,可能会导致意外行为。
为了在多线程环境中使用 Jedis,你可以采取以下措施:
-
使用连接池: 在多线程环境中,你应该使用连接池来管理 Jedis 连接。连接池可以确保连接的复用,从而减少资源浪费。
-
每个线程使用独立的 Jedis 实例: 为每个线程创建独立的 Jedis 实例,这样可以避免线程之间的状态共享和竞态条件。
-
同步访问共享 Jedis 实例: 如果你必须在多个线程之间共享同一个 Jedis 实例,你可以使用锁或其他同步机制来确保线程安全。
总之,Jedis 不是线程安全的,因此在多线程环境中使用时需要小心处理,采取适当的措施来确保数据的一致性和避免竞态条件。连接池的使用是保证线程安全的一种有效方法。
2、Lettuce 和 Jedis的区别以及如何选择?
Lettuce 和 Jedis 都是用于与 Redis 数据库进行交互的 Java 客户端库,但它们在实现和性能方面有一些重要区别:
-
异步 vs. 同步:
- Lettuce: Lettuce 是一个基于异步的客户端库,它使用 Java 8 的 CompletableFuture 和 Reactor 等异步编程模型。这意味着它支持非阻塞、异步的 Redis 操作,可以在单个线程中处理多个 Redis 命令,从而更好地利用多核 CPU。
- Jedis: Jedis 是一个同步的客户端库,它使用传统的阻塞 I/O 操作来与 Redis 进行通信。这意味着每个 Redis 命令都会阻塞当前线程,直到完成。
-
连接管理:
- Lettuce: Lettuce 提供了高级连接池管理,它支持自动连接恢复和复用。连接池的配置非常灵活,可以根据需要进行调整。
- Jedis: Jedis 也有连接池,但在某些情况下,连接池的配置和性能可能不如 Lettuce 那么灵活和高效。
-
线程安全:
- Lettuce: Lettuce 是线程安全的,可以在多线程环境中安全使用。
- Jedis: Jedis 不是线程安全的,因此需要额外的同步机制来在多线程环境中使用。
-
性能:
- 由于 Lettuce 的异步模型和更好的连接管理,它通常在高并发环境下表现更好,能够更有效地利用系统资源。
- Jedis 在某些情况下可能会因为同步操作和连接管理方面的性能开销而不如 Lettuce。
-
支持性:
- Lettuce 支持更多高级特性,如 Redis Sentinel 和 Redis Cluster。
- Jedis 也支持这些特性,但 Lettuce 更加强大和灵活。
综上所述,Lettuce 通常在性能和高并发场景下更有优势,而 Jedis 则更适合一些简单的使用情况。选择哪个库取决于你的应用需求,特别是在需要异步操作、高并发、高可用性和灵活性方面的需求。















 1472
1472











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









