







 本文探讨了三种加速深度学习中梯度下降算法收敛速度的方法:Monmentum、RMSprop和Adam。Monmentum利用加权平均使梯度更新更平滑,RMSprop通过指数移动平均处理梯度波动,而Adam是前两者的优势结合。这些策略能有效提升模型训练的效率。
本文探讨了三种加速深度学习中梯度下降算法收敛速度的方法:Monmentum、RMSprop和Adam。Monmentum利用加权平均使梯度更新更平滑,RMSprop通过指数移动平均处理梯度波动,而Adam是前两者的优势结合。这些策略能有效提升模型训练的效率。
上篇博客讲的是利用处理(分组数据集)训练数据集的方法,加快梯度下降法收敛速度,本文将介绍如何通过处理梯度的方法加快收敛速度。首先介绍Monmentum,再次介绍RMSprop,最后介绍两种算法的综合体Adam。
1.Monmentum
在介绍Monmentum之前,首先介绍加权平均法。加入给出一组数据的散点图,要求用一条曲线尽可能准确地描述散点图的趋势,如下图所示(图来自吴恩达课件):
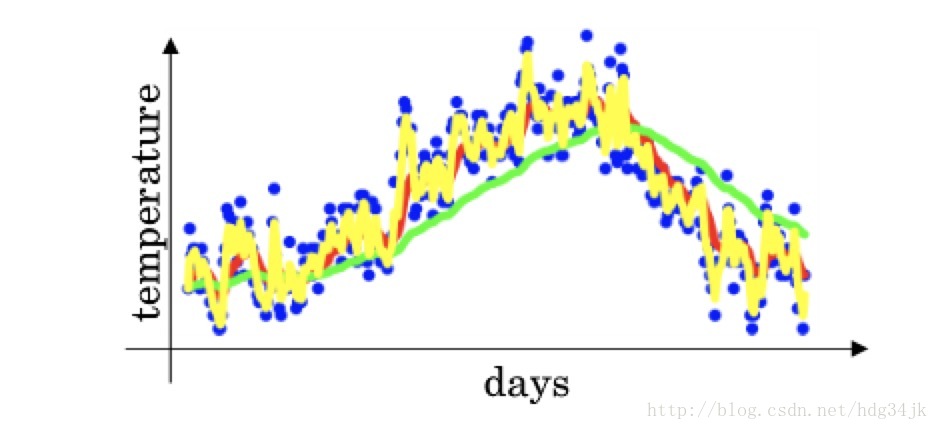
描述时利用加权平均:
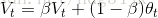
通过控制β的大小,控制曲线的平滑度,通常取β=0.9。如果将mini-batch梯度加权平均,则,mini-batch收敛曲线(蓝线)将会更加平滑,在横轴方向走的更快:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 969
969

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









