






-----------------------------------------MongoDB高级索引------------------------------------
student文档集合如下(包含了address子文档和tags数组):
{
address: {
country:'china',city:'shanxi'
},
tags:[
'music',
'blogs'
],
name:'hedanning'
}
索引数组字段
如果我们要基于tags标签来检索用户,为此我们需要对集合中的数组tags建立索引。
在数组中创建索引需要对数组的中的每个字段依次建立索引。所以我们为数组tags创建索引时,会为music和blogs三个值建立单独的索引。
- 创建索引:db.student.ensureIndex({tags:1})
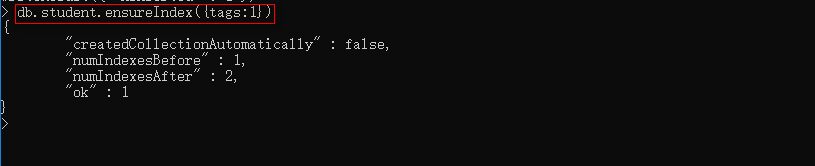
- 检索集合中的tags字段:db.student.find({tags:'music'})

索引文档字段:
如果我们需要通过country,city字段来检索文档,因为这些字段是文档的字段,所以我们需要对子文档建立索引。
- 为子文档的两个字段创建索引:
db.student.ensureIndex({'address.country':1,'address.city':1})

- 使用子文档的字段来检索数据:

-----------------------------------------MongoDB索引限制------------------------------------
额外开销:
每个索引占据一定的存储空间,在进行插入、更新和删除操作时也需要对索引进行操作。所以,如果很少对集合进行读取操作,不建议使用索引。
内存使用:
由于索引存储在内存中,应该确保该索引的大小不超过内存的限制。
如果索引的大小大于内存的限制,MongoDB会删除一些索引,这将导致性能下降。
查询限制:
索引不能被以下的查询使用:
- 正则表达式及非操作符,如:$nin,$not等
- 算术运算符,如:$mod等
- $where 子句
可以使用explain()来查看查询语句是否使用了索引。
索引键限制:
如果现有的索引字段的值超过索引键的限制,MongoDB中不会创建索引。
插入文档超过索引键的限制:
如果文档的索引字段值超过了索引键的限制,MongoDB不会将任何文档转换成索引的集合。与mongorestore和mongoimport工具类似。
最大范围:
- 集合中索引不能超过64个
- 索引名的长度不能超过128个字符
- 一个复合索引最多可以有31个字段
-----------------------------------------MongoDB ObjectId------------------------------------
MongoDB ObjectId
ObjectId是一个13字节BSON类型的数据,格式如下啊:
- 前四个字节表示时间戳
- 接下来的3个字节是机器标识码
- 紧接的两个字节是由进程id组成
- 最后的三个字节是随机数
MongoDB中存储的文档必须有一个"_id"键。这个键的值可以是任何类型的,默认是个ObjectId对象。
在一个集合里面,每个文档都有唯一的"_id"值,来确保集合里面每个文档都能被唯一标识。
MongoDB采用ObjectId,而不是其他比较常规的做法(比如:自动增加的主键)的主要原因是:因为在多个服务器上同步自动增加主键值既费力还费时。
创建新的ObjectId:newObjectId = ObjectId()

创建文档的时间戳:ObjectId('5d5dec1de1ea9491096b7e1c').getTimestamp()
![]()
ObjectId转换为字符串:new ObjectId().str
![]()
-----------------------------------------MongoDB Map Reduce------------------------------------
MongoDB Map Reduce
Map-Reduce是一种计算模型,简单的说就是将大批量的工作(数据)分解(Map)执行,然后再将结果合并成最终结果(Reduce)。
MongoDB提供的Map-Reduce非常灵活,对于大规模数据分析也相当实用。
MapReduce命令
语法:
db.collection.mapReduce(
function() {emit(key,value);}, //map 函数
function(key,values) {return reduceFunction}, //reduce 函数
{
out: collection,
query: document,
sort: document,
limit: number
}
)使用MapReduce要实现两个函数:Map函数和Reduce函数。
Map函数:调用emit(key,value),遍历collection中所有的记录,将key与value传递给Reduce函数进行处理。
Map函数必须调用emit(key,value)返回键值对。
参数说明:
- map映射函数:生成键值对序列,作为reduce函数参数。
- reduce函数:统计函数,reduce函数的任务就是将key-values变成key-value,也就是把values数组变成一个单一的值value。
- out:统计结果存放集合(不指定则使用临时集合,在客户端断开后自动删除)。
- query:筛选条件,只有满足条件的文档才会调用map函数。
- sort:和limit结合的sort排序参数,在发往map函数前给文档排序,可以优化分组机制。
- limit:发往map函数的文档数量的上限。如果没有limit,单独使用sort的用处不大。
实例:
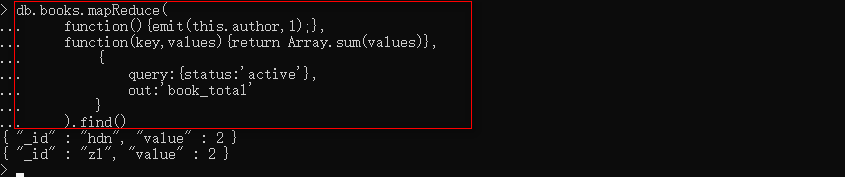
将在books集合中使用mapReduce函数来选取已发布的文章(status:'active'),并通过author分组,流程图:


执行结果:

执行结果说明:
- result:存储结果的集合的名字,这个是临时集合,MapReduce的连接关闭后自动就被删除了。
- timeMillis:执行花费的时间,单位为毫秒。
- input:满足条件被发送到map函数的文档个数。
- emit:在map函数中emit被调用的次数。
- output:结果结合中的文档个数。
- ok:是否成功,成功为1。
使用find操作符来查看mapReduce的查询结果:
-----------------------------------------MongoDB 固定集合------------------------------------
MongoDB固定集合是性能出色且有着固定大小的集合(集合空间大小和文档个数上限),如果空间大小到达上限,则插入下一个文档时,会覆盖第一个文档;如果文档个数到达上限,同样插入下一个文档时,或覆盖第一个文档。两个参数上限判断取的是【与】的逻辑。
创建固定集合:capped参数设置为true
db.createCollection('创建的集合名称',{capped:true,size:10000})
db.createCollection('cappedCollection',{capped:true,size:10000})
- 指定文档个数上限:max:1000
db.createCollection('创建的集合名称',{capped:true,size:10000,max:1000})
db.createCollection('cappedCollection',{capped:true,size:10000,max:1000})
- 判断集合是否为固定集合:
db.COLLECTION_NAME.isCapped()
db.cappedCollection.isCapped()
- 将已存在的集合转换为固定集合:
db.runCommand({'固定集合名称':'要转换的集合',size:10000})
固定集合查询:
固定结合文档按照插入顺序存储,默认情况下查询的就是按照插入顺序返回的,也可以使用$natural调整返回顺序。
db.cappedCollection.find().sort({$natural:-1})
固定集合的功能特点:
可以进行插入、更新操作,但更新不能超过collection的大小,否则更新失败。
不可以进行删除操作,但是可以调用drop()删除集合中的所有行,但是drop()后需要显示地重建集合。
固定集合属性及用法:
属性:
- 固定集合插入速度极快
- 按照插入顺序的查询输出极快
- 能够在插入最新数据时,淘汰最早的数据
用法:
- 存储日志信息
- 缓存一些少量的文档
-----------------------------------------MongoDB 自动增长------------------------------------
MongoDB中没有像SQL一样有自动增长的功能,MongoDB的_id是系统自动生成的12字节唯一标识。
但在某些情况下,我们可能需要实现ObjectId自动增长功能,我们通过变成的方式来实现。
















 362
362











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









