






'''
关联规则
'''
import os
import pandas as pd #导入处理二维表格的库
import numpy as np #导入数值计算的库
import networkx as nx#聚类分析的库
import csv
import pickle #二进制,序列化和反序列化
import matplotlib.pyplot as plt #导入画图的包
from mlxtend.preprocessing.transactionencoder import TransactionEncoder#将数组转化成一个二维表格
from mlxtend.frequent_patterns import apriori#导入关联规则的数据算法
from mlxtend.frequent_patterns import association_rules#展现两种物品的关系
plt.rcParams["font.sans-serif"]=['Simhei'] # 规定图上中文字体,使用黑体画图
plt.rcParams["axes.unicode_minus"]=False #在图上不显示坐标轴的信息
# plt.axes().get_xaxis().set_visible(False) # 隐藏x坐标轴
# plt.axes().get_yaxis().set_visible(False) # 隐藏y坐标轴
# 导入数据(数据不规则)
os.chdir(r"C:\Users\a2044\Desktop\Subject document\大数据\投资学")
with open(r"fundStocks.csv",'r',encoding='utf-8',errors='ignore') as f:#errors='ignore'忽略空值
transactions=[l for l in csv.reader(f)]
print(transactions)
te=TransactionEncoder()#实例化
'''
TransactionEncoder()是一个用于转换数据格式的类,用于将事务型数据转换成布尔型二维矩阵,其中每一行代表一个事务,每一列代表一个可能出现的项集,
如果某个事务包含了该项集,则对应位置上的值为1,否则为0。fit_transform()是该类的一个方法,用于拟合数据并进行转换。
具体来说,它会根据给定的数据data来确定可能出现的项集,并将data转换为布尔型二维矩阵的形式。该方法返回转换后的布尔型矩阵。
'''
TransactionEncoder().fit_transform(data)
transaction_df=pd.DataFrame(te.fit_transform(transactions),columns=te.columns_,)#columns设置列名,与导入数据的列名一致
transaction_df.head()#每一行的True 表示对应的投资者持有该公司的股票,行代表客户,列代表公司股票
# 数据预处理
transaction_df=transaction_df.drop(transaction_df.columns[0],axis=1)#删除某一行(axis=0)或者列(axis=1)
transaction_df.head()
# 去掉列名为股票号的列
transaction_df=transaction_df.drop(transaction_df.iloc[:,1:1927],axis=1)
transaction_df.head()
# 查看排名前十的股票持有量的公司(ascending=False降序排序),画条形图;找谁的支持度最高
transaction_df.sum().sort_values(ascending=False).head(10).plot.bar()#计算True的个数,即股票出现个数
# 统计频繁项集:多种商品的关联度,一件商品出现,同时另一件商品出现的概率
frequent_itemsets=apriori(transaction_df,min_support=0.01,use_colnames=True)#频繁项集,min_support最小支持度(某一个项集出现的最小频率)
frequent_itemsets
# support为前项和后项的个数除于总数
# 提升度lift
ar=association_rules(frequent_itemsets,metric='confidence',min_threshold=0.3)#confidence置信度(反映条件概率)
ar
# antecedents(前项),consequents(后项),在前项出现的条件下,后向出现的概率为confidence;lift越大前后项关联性越大;
# leverage杠杆率,若为零,则前项和后项相互独立;conviction衡量后项与前项的依赖度
# 画图
ar[['support','confidence','lift']].plot.scatter(x='support',y='lift',c='confidence',colormap='viridis')
ar=association_rules(frequent_itemsets,metric='confidence',min_threshold=0.5)#confidence置信度(反映条件概率)
ar=ar.query('support>=0.02 and lift>=2').sort_values(by='lift',ascending=False) #查找相应范围的支持度和提升度,并以提升度降序排序
ar
ar=round(ar[['antecedents','consequents','support','confidence','lift']],3)#保留三位小数
ar
# 数据可视化:自定义函数来绘制关联规则的图像
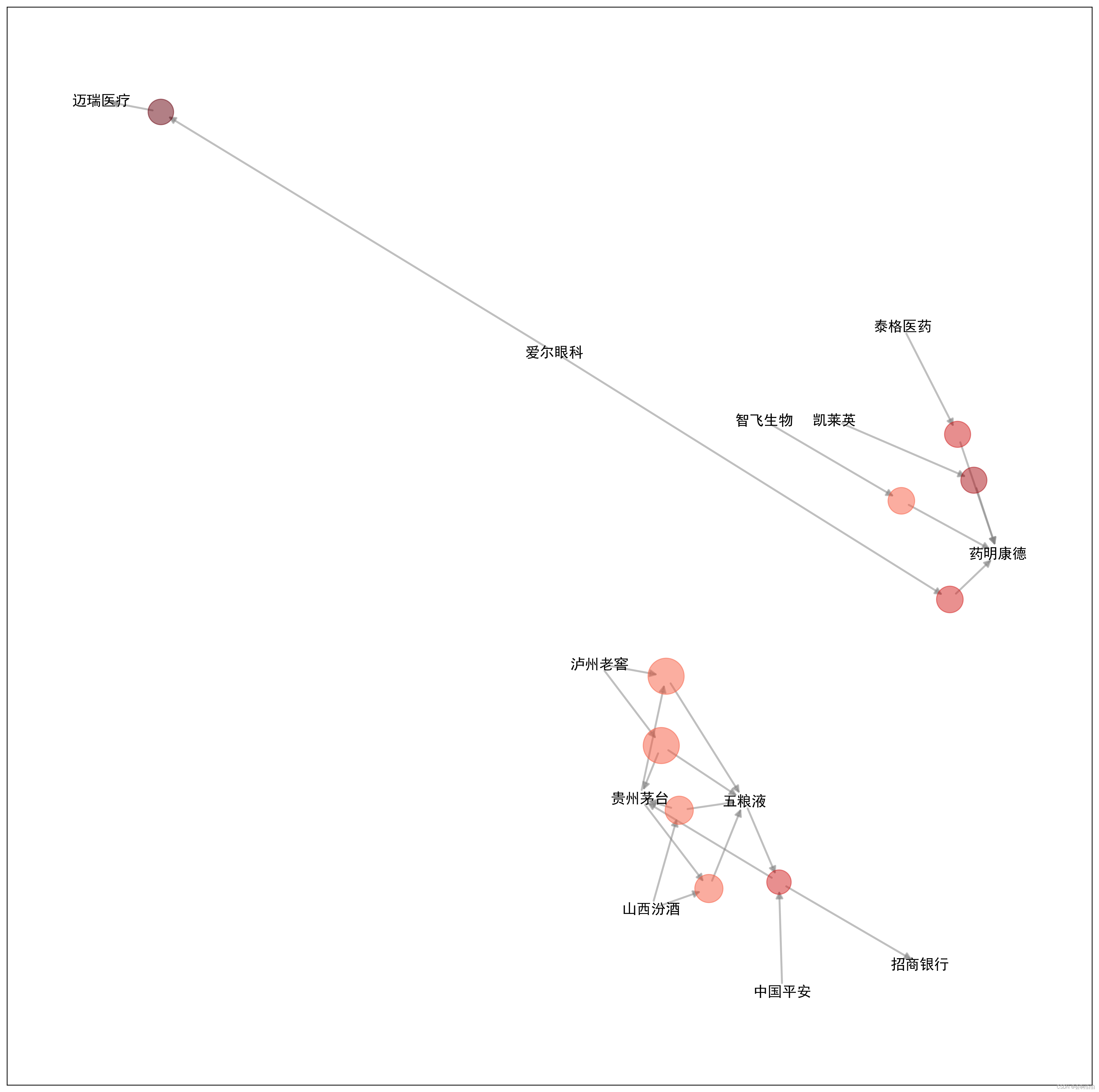
def drawGraph(ar,Multiplier=1000): #Multiplier乘积因子,将数值扩大1000倍
G=nx.DiGraph() #绘制网状图
size_dict={}#支持度,以圆圈大小反映,越大越好
color_dict={}#提升度,以颜色深浅反映,越深越好
label_dict={}#存储股票名称
for i in ar.index:
ser=ar.loc[i]
G.add_node(i)#把新的点添加到图里
size_dict[i]=ser['support']*Multiplier
color_dict[i]=ser['lift']
label_dict[i]=''
for ant in list(ser['antecedents']):
G.add_node(ant)#把新的点添加到图里
size_dict[ant]=0
color_dict[ant]=0
label_dict[ant]=ant
G.add_edge(ant,i) #把前项与带有颜色的圆圈连起来
for j in list(ser['consequents']):
G.add_node(j)#把新的点添加到图里
size_dict[j]=0
color_dict[j]=0
label_dict[j]=j
G.add_edge(i,j) #把后项与带有颜色的圆圈连起来
node_list,size_list=zip(*size_dict.items()) #把绘制的字典放到数组里;zip()将数据打包成元组
node_list,color_list=zip(*color_dict.items())
plt.figure(figsize=(20,20),dpi=250)#设置figsize图片长宽,dpi清晰度
pos=nx.spring_layout(G) #设置版式
cmap=plt.cm.get_cmap('Reds') #设置色系
nx.draw_networkx_nodes(G,pos=pos,nodelist=node_list,node_size=size_list,node_color=color_list,alpha=0.5,cmap=cmap)
#绘制带颜色的圆圈,节点位置,nodelist点的列表,点的大小,节点的颜色,alpha透明度,色系
nx.draw_networkx_edges(G,pos=pos,edge_color='grey',alpha=0.5,width=2,arrowsize=15)
# 绘制连线;edge_color颜色(灰色);width线宽;arrowsize箭头大小
nx.draw_networkx_labels(G,pos=pos,labels=label_dict,font_size=15)#font_size字体大小
drawGraph(ar.head(10),Multiplier=30000) 结果:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









