






"""
聚类分析
"""
import os
import pandas as pd #导入处理二维表格的库
import numpy as np #导入数值计算的库
from sklearn.preprocessing import StandardScaler #导入数据标准化模块
import matplotlib.pyplot as plt #导入画图的包
from factor_analyzer import FactorAnalyzer #导入因子分析的类
import seaborn as sns #导入画热力图的库
from sklearn.cluster import KMeans #导入聚类的库
from scipy.spatial.distance import cdist # 导入可以计算距离的类
# 导入数据
os.environ["OMP_NUM_THREADS"]='1' # 防止内存溢出'
X_comp=pd.read_csv(r"C:\Users\a2044\Desktop\Subject document\大数据\投资学\银行客户聚类案例.csv",index_col=-1)
#index_col=-1以数据最后一列(企业名)作为主键/id
X_comp.head()
# 数据预处理
scaler=StandardScaler() #实例化标准处理的类
X2_comp=pd.DataFrame(scaler.fit_transform(X_comp))#标准化数据
X2_comp.columns=['流动比率','速动比率','现金比率','资产负债率','长期借款总资产比',
'有形资产负债率','固定资产比率','有形资产比率','流动负债比率','经营负债比率',
'应收账款收入比','存货与收入比','资产报酬率','总资产净利润率','净资产收益率',
'投入资本回报率','营业毛利率','营业利润率','营业收入现金含量','营业收入增长率',
'所有者权益增长率','市盈率','市净率','托宾Q值']
X2_comp.index=X_comp.index
X2_comp.head()
# 用因子分析进行降维
fa=FactorAnalyzer(n_factors=24,rotation='varimax',method='ml')#实例化因子分析的类,先不降维,看看24个因子是什么样子的;method='ml'极大自然法
# rotation='varimax'用最大方差法进行旋转(影响效果好坏)
fa.fit(X2_comp)#执行因子分析操作,得到特征值和特征向量
ev,v=fa.get_eigenvalues()#得到特征值(方差)和特征向量
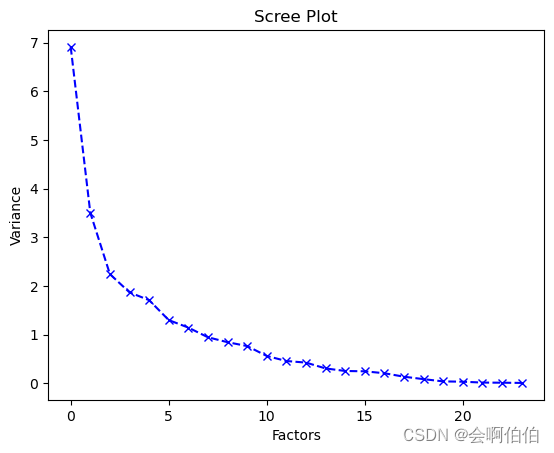
# 数据可视化;碎石图
plt.plot(ev,'bx--')#画出方差图
plt.title('Scree Plot')
plt.xlabel('Factors')#因子
plt.ylabel('Variance')#方差值
plt.show()
fa=FactorAnalyzer(n_factors=3,rotation='varimax',method='ml')#实例化因子分析的类,降维,3个因子;method='ml'极大自然法
# rotation='varimax'用最大方差法进行旋转(影响效果好坏)
fa.fit(X2_comp)#执行因子分析操作,得到特征值和特征向量
ev,v=fa.get_eigenvalues()#得到特征值(方差)和特征向量
Loading=pd.DataFrame(np.round(fa.loadings_,2))#得到载荷因子,保留两位小数
Loading.head()
Loading=Loading.T#转置
Loading.head()
Loading.columns=X2_comp.columns#列名
Loading[abs(Loading)<0.1]=0#小于0.1的载荷系数的化为0(载荷系数过小,进行截断处理)
Loading.head()
#找到解释能力最强的因子
Loading2=abs(Loading)
Lmaxi=pd.DataFrame(Loading2.idxmax()).T
Lmaxi.head()
#找到解释能力最强的因子的载荷因子
xx=[]
for i in range(len(Lmaxi.T)):
xx.append(Loading.iat[Lmaxi.iat[0,i],i])#Loading.iat[]通过行号或列号取值;将第i个因子号的对应的三个中最大的载荷系数读取出来
xx
Lm=pd.DataFrame(np.vstack((xx,Lmaxi)))#np.vstack()把两个数组拼接到一起,第一行为最大载荷系数,第二行为对应所在位置
Lm.columns=X2_comp.columns#列名
Lm.head()
Lm1=Lm.T
Lm1.columns=['载荷','因子序号']
Lm1.因子序号[abs(Lm1.载荷)<0.3]=np.nan#np.NaN是NumPy库中表示缺失值(NaN)的特征值;将载荷小于0.3的因子序号变为NaN
Lm1
# 聚类
YZ1=Lm1*1
YZ1.载荷[YZ1.因子序号!=0]=0#只保留因子序号为0的载荷,其他的载荷系数变为0
abb1=YZ1[YZ1.columns[0]]#获取因子序号为0的载荷该列的数据
D1=np.dot(X2_comp,abb1)#用于矩阵的乘法运算,把最初数据乘以载荷系数
JZ1=pd.DataFrame(D1)#将数据放入表格
YZ2=Lm1*1
YZ2.载荷[YZ2.因子序号!=1]=0#只保留因子序号为1的载荷,其他的载荷系数变为0
abb2=YZ2[YZ2.columns[0]]#获取因子序号为1的载荷该列的数据
D2=np.dot(X2_comp,abb2)#用于矩阵的乘法运算,把最初数据乘以载荷系数
JZ2=pd.DataFrame(D2)#将数据放入表格
YZ3=Lm1*1
YZ3.载荷[YZ3.因子序号!=2]=0#只保留因子序号为2的载荷,其他的载荷系数变为0
abb3=YZ3[YZ3.columns[0]]#获取因子序号为2的载荷该列的数据
D3=np.dot(X2_comp,abb3)#用于矩阵的乘法运算,把最初数据乘以载荷系数
JZ3=pd.DataFrame(D3)#将数据放入表格
# 合并三个表格
X_fa=pd.merge(pd.merge(JZ1,JZ2,left_index=True,right_index=True),JZ3,left_index=True,right_index=True)
#left_index=True,right_index=True左右拼接保持一致
X_fa.columns=['盈利性','杠杆率','流动性/偿债性']
X_fa.index=X_comp.index#命名主键名
# X_fa.head()#开头的数据
X_fa.tail(10)#后面的数据
X_fa.info()
# Kmeans聚类使同类的股票距离小,不同类的股票距离大,规避风险(让投资者不选择相同风险的股票),选择对冲股票
K=range(1,11)#股票分类,观察平均距离
meandistortions=[]
for k in K:
kmeans=KMeans(n_clusters=k)#n_init='auto'自动运算;n_clusters质心个数
kmeans.fit(X_fa) #聚类,每一个点(公司)到K个质心的距离,计算平均值
meandistortions.append( #kmeans.cluster_centers_每个循环里的K个质心;euclidean用欧氏距离计算
sum(np.min(cdist(X_fa,kmeans.cluster_centers_,'euclidean'),axis=1))/X_fa.shape[0],#除于点数目,求得平均距
)
meandistortions
# 发现分的类越多,距离越小(但是不是距离越小越好,因为容易过拟合)
# 分一个类为5.3265811388823305,
# 分两个类4.078115102259104,
# 画出碎石图
plt.plot(K,meandistortions,'bx--')
plt.xlabel('k')
plt.show()
np.random.seed(123)#设置一个随机种子
km=KMeans(n_clusters=4,n_init=10).fit(X_fa)#n_clusters=4 选择分为4类的
Xtype=pd.DataFrame(km.labels_)#km.labels_类别标签
Xtype.index=X2_comp.index
Xtype.columns=['Type']
Xnew=pd.merge(X_fa,Xtype,left_index=True,right_index=True).sort_values('Type')#拼接表格,sort_values('Type')按'Type'排序
Xnew.head()
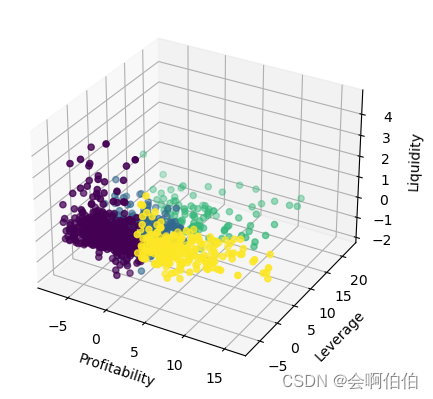
fig=plt.figure()
ax1=fig.add_subplot(projection='3d')#3D绘图
x=np.array(Xnew.盈利性)#X轴
y=np.array(Xnew.杠杆率)
z=np.array(Xnew['流动性/偿债性'])
t=np.array(Xnew.Type)
ax1.scatter3D(x,y,z,c=t)#3D绘图,c=t按不同的类别画不同的颜色
ax1.set_xlabel('Profitability')#盈利性Profitability
ax1.set_ylabel('Leverage')#杠杆率
ax1.set_zlabel('Liquidity')#流动性/偿债性
plt.show()
np.round(Xnew.groupby(['Type'])[['盈利性','杠杆率','流动性/偿债性']].mean(),2)结果如下:















 4461
4461

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









