






六、搭建基于知识图谱的农医对话系统
11.安装Redis
任务描述
本任务完成Redis库的安装和学习,以便后续进行用户对话管理,存储用户的聊天记录。
知识点:安装Redis库、测试Redis库是否安装成功
重 点:测试Redis库是否安装成功
难 点:测试Redis库是否安装成功
内 容:1. 开发准备:新建代码文件
2. 安装Redis库
(1)简介
(2)安装Redis
(3) 测试Redis是否安装成功

redis-server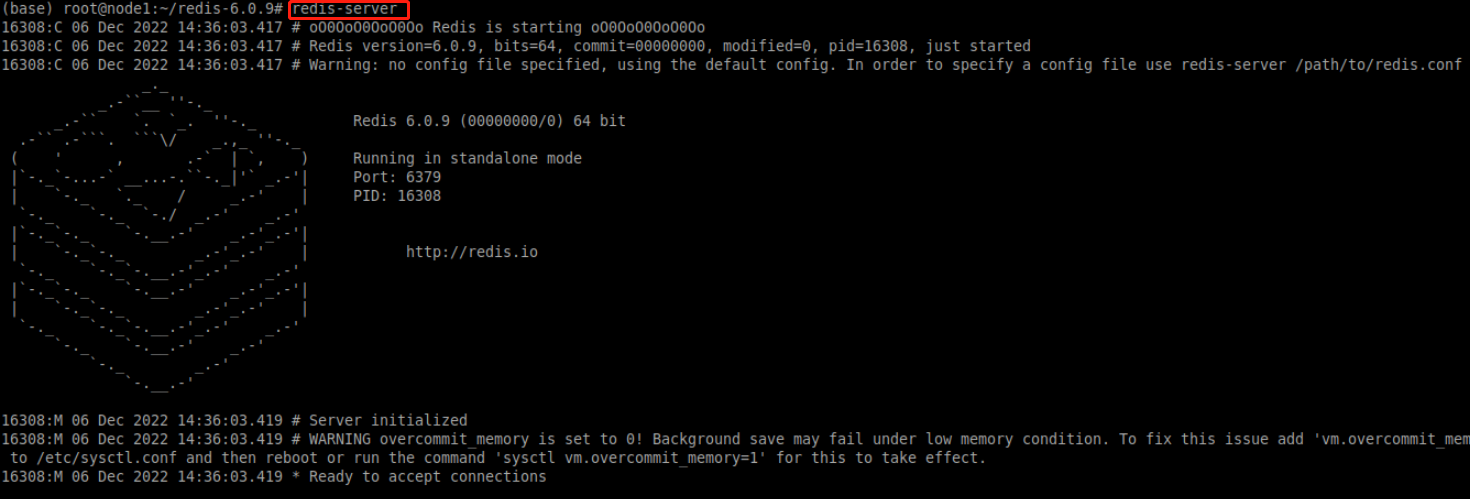

1. 开发准备
(1)创建代码文件
在test/目录下新建一个python文件,命名为"for_redis.py"。
2. 安装Redis库
(1)简介
Redis 是一个高性能的key-value数据库,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。Redis支持各种不同方式的排序,且为了保证效率,数据都是缓存在内存中。Redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并在此基础上实现了master-slave(主从)同步。
本项目主要使用Redis进行用户对话管理, 存储用户的聊天记录。
(2)安装Redis
在终端执行以下命令下载Redis的安装包:
wget https://download.redis.io/releases/redis-6.0.9.tar.gz命令执行过程,如下图所示:
执行以下命令解压压缩包redis-6.0.9.tar.gz:
tar xzf redis-6.0.9.tar.gz 切换到redis-6.0.9/目录下:
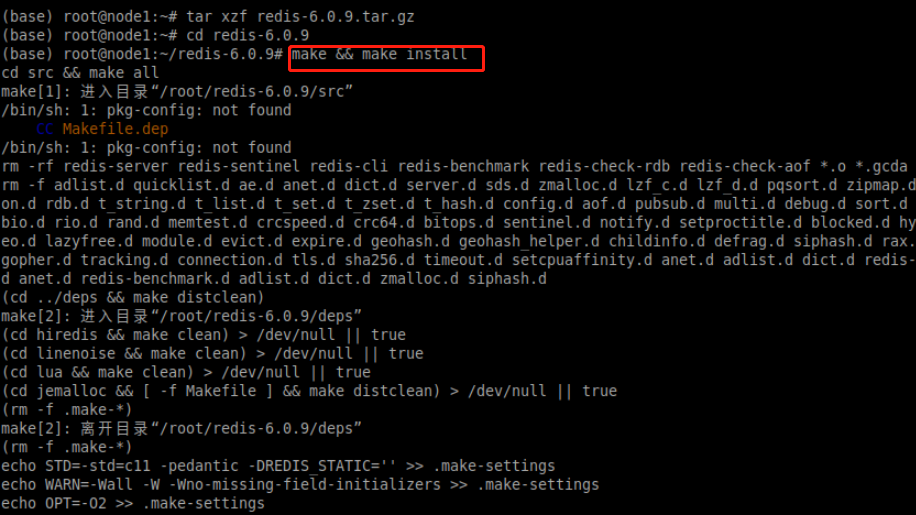
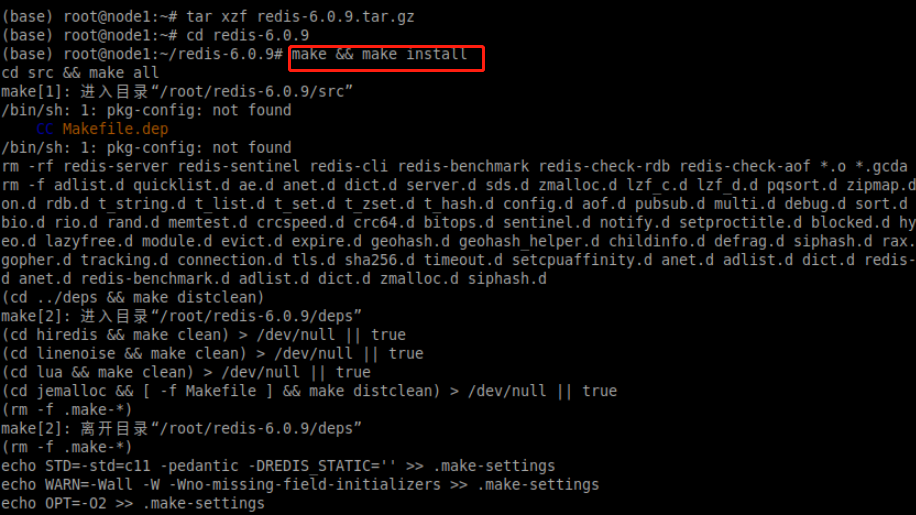
cd redis-6.0.9运行编译命令:
make && make install编译过程如下图所示:
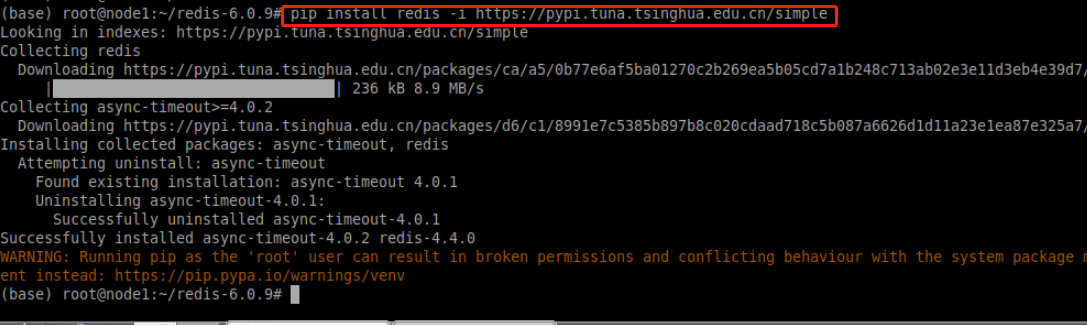
安装redis:
pip install redis -i https://pypi.tuna.tsinghua.edu.cn/simple安装过程如下图所示:
(3)测试Redis是否安装成功
Redis支持存储的value类型相对较多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)等。本项目中主要用到Hash类型的读写。
在终端执行以下命令启动redis:
redis-server启动过程如下图所示,不进行配置的话redis的端口是6379。
在for_redis.py文件中添加以下代码:
import redis
#redis的基本配置
REDIS_CONFIG = {
"host": "0.0.0.0",
"port": 6379
}
link_pool = redis.ConnectionPool(**REDIS_CONFIG)
con_redis= redis.StrictRedis(connection_pool=link_pool)
#my_ id是一个用户的标识
my_id = "0001"
last_sentence= "这是最后一句:".encode('utf-8')
# value是需要记录的数据具体内容
my_output = "输出Redis".encode('utf-8')
con_redis.hset(my_id,last_sentence, my_output)
print(con_redis.hget(my_id, last_sentence).decode('utf-8'))输出效果如下图所示,说明Redis安装成功。

12.对话生成
任务描述
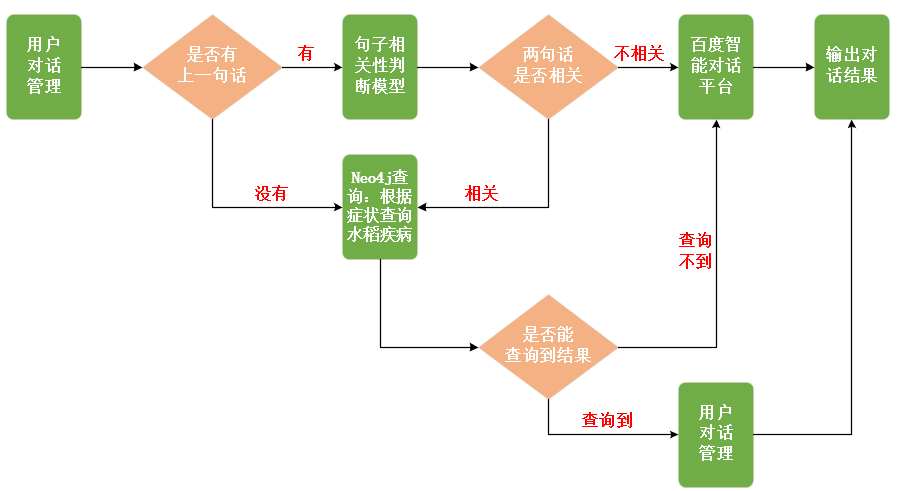
在本任务中,主要完成对话系统等额搭建,主要过程如下: 用户发送的消息由redis库管理,先根据用户标识判断,是否有上一句话?没有上一句话,就直接在水稻疾病知识图谱中进行查询(根据“水稻病症状”实体查询“水稻疾病”实体),并定义答案模板将答案组织成自然语言返回给用户,同时将用户的第一句话存储到Redis,查询不到答案时,则调用百度智能对话平台进行兜底;有上一句话时,先调用句子相关性判断模型判断两句话是否相关,相关时,则直接在水稻疾病知识图谱中进行查询,查询到,则使用redis库进行管理,查询不到,则依然调用百度智能对话平台进行兜底。
知识点:使用Redis库进行用户对话管理、句子相关性判断、基于Neo4j的知识检索、百度智能对话平台兜底
重 点:使用Redis库进行用户对话管理、句子相关性判断、基于Neo4j的知识检索、百度智能对话平台兜底
难 点:使用Redis库进行用户对话管理、句子相关性判断、基于Neo4j的知识检索、百度智能对话平台兜底
内 容:1. 开发准备:新建代码文件,安装Flask-Cors
2. 定义对话模板
3. 对话生成
(1)导入包
(2)配置访问参数
(3)查找水稻病症状实体对应的水稻疾病实体
(4)对话规则生成
(5)处理用户输入的信息
4. 测试
1. 开发准备
(1)创建代码文件
在networking/目录下新建1个json文件,命名为“talk_template.json”。
在networking/目录下新建两个python文件,分别命名为“principal”、“for_principal”。
(2)安装Flask-Cors
为了在后续服务中实现跨域请求,执行以下命令安装Flask-Cors:
pip install Flask-Cors==3.0.10安装过程如下:
2. 定义对话模板
在networking/目录下的talk_template.json文件中定义对话模板,示例如下:
{
"1": "我是稻稻,您的水稻疾病助手,写出水稻病症状,我就能为您判断水稻病哦!",
"2": "稻稻判断您的水稻可能以下农业病: %s",
"3": "稻稻还不知道您再说什么,您可以换一种说法再次尝试",
"4": "稻稻觉得还是稻稻之前为您判断的水稻病,并不是新的水稻病"
}3. 对话生成
本模块主要实现对话生成功能,包含用户对话管理、句子相关性判断、基于Neo4j的知识检索、百度智能对话平台兜底等几部分,具体流程如下图所示:
在networking/目录下的principal.py文件中编写本模块的代码:
(1)导入包
import requests
import redis
import json
from flask import Flask
from flask_cors import CORS
from flask import request
app = Flask(__name__)
CORS(app, resources=r'/*')
from for_Unit import unit_chat
from neo4j import GraphDatabase(2)配置访问参数
配置Neo4j图数据库连接对象,注意将“auth”参数中Neo4j的密码修改为自己的;
# 配置Neo4j连接对象
NEO4J_CONFIG = {
"uri": "bolt://localhost:7687",
"auth": ("neo4j", "123456"),
"encrypted": False
}
neo4j_driver = GraphDatabase.driver(**NEO4J_CONFIG)配置Redis的挂起端口。
# 配置redis的挂起端口
REDIS_CONFIG = {
"host": "0.0.0.0",
"port": 6379
}
link_pool = redis.ConnectionPool( **REDIS_CONFIG)配置调用两句话相关性判断模型的调用接口,注意端口号要与模型挂起的端口号保持一致。
subjectmodel_url = "http://127.0.0.1:8084/farmer/receive/"(3)查找水稻病症状实体对应的水稻疾病实体
定义interrogate_inneo4j()方法,用于查找水稻症状实体对应的水稻疾病实体。传入参数如下:
- input_content:用户输入的文本
def interrogate_inneo4j(input_content):
with neo4j_driver.session() as session:
find_inneo4j = "MATCH(a:Symptom) WHERE(%r contains a.name) WITH a MATCH(a)-[r:dis_to_sym]-(b:Disease) RETURN b.name LIMIT 6" %input_content
output = list(map(lambda i: i[0], session.run(find_inneo4j)))
return output(4)对话生成规则
定义Main_Logic()类方法,用于定义对话生成规则。在Main_Logic()类中定义一下几个方法:
__init__():初始化函数,用于初始化要用的变量,参数说明如下:
- id_for_user:用户id,每个关注公众进行对话的用户都会有一个id;
- input_content:用户输入的对话
- rules_answer:规则对话模板,对话模板文件在talk_template.json
- redis_con:用于连接redis
foremost_deal_talk():用于处理用户第一句话的对话场景。主要过程如下:
- 调用 interrogate_inneo4j()方法,抓住水稻症状实体查找水稻疾病实体;
- 如果没有查询到实体,则访问百度Unit,进行对话兜底;
- 若查询到实体,则将用户的第一句话存储到redis,并把查询到的结果转换为字符串,结合模板2组合成对话返回。模板2为上述在talk_template.json文件中定义的"稻稻判断您的水稻可能以下农业病: %s"。
second_deal_talk():用于处理非第一句话的对话场景。参数 foremost_sen为用户的前一句话。主要过程如下:
- post请求两句话相关性判断模型,判断redis库中存储的用户的前一句话和本次输入的相关性;
- 不相关则直接交给百度Unit,进行对话兜底;
- 相关则继续进行以下处理:
- 调用 interrogate_inneo4j()方法,抓住水稻症状实体查找水稻疾病实体;
- 如果没有查询到实体,则访问百度Unit,进行对话兜底;
- 若查询到实体,则从redis中获取用户前一句话从知识图谱中查询到的水稻疾病实体
- 如果找到用户前一句话从知识图谱中查询到的水稻疾病实体,则合并两次对话获取的实体,并存储到dis_second变量中;将两次对话不重复的实体存储到output变量中。否则,dis_second、output变量都为本次对话获取的疾病实体。
- 将dis_second变量中保存的实体存储到redis中,覆盖掉之前redis中存储的水稻疾病实体。
- 如果output变量不为空,则按照对话模板2("稻稻判断您的水稻可能以下农业病: %s")生成对话;否则按照对话模板4("稻稻觉得还是稻稻之前为您判断的水稻病,并不是新的水稻病")生成对话。
class Main_Logic(object):
def __init__(self, id_for_user, input_content,rules_answer, redis_con):
self.id_for_user = id_for_user
self.input_content = input_content
self.rules_answer = rules_answer # 预先设置好的话,回复给用户
self.redis_con = redis_con # # 用于连接redis
def foremost_deal_talk(self):
# 用户发送的第一次会话,抓住水稻症状实体直接去查询对应的水稻病就可以了
list_1 = interrogate_inneo4j(self.input_content)
if not list_1:
print("没有查询到该实体,访问百度Unit",self.input_content)
return unit_chat(self.input_content)
print("图数据库的查询结果为:", list_1)
# redis存储用户的第一句话,进行会话管理
self.redis_con.hset(str(self.id_for_user), "foremost_talk", str(list_1))
self.redis_con.expire(str(self.id_for_user), 30000)
# 把列表结果转化为字符串类型数据,组合成对话返回结果
print("生成对话")
str_talk = ",".join(list_1)
return self.rules_answer["2"] % str_talk
def second_deal_talk(self, foremost_sen):
print("下面判断两句相关性:")
try:
# post请求两句话相关性判断模型,判断redis库中存储的用户的前一句话和本次输入的相关性
result = requests.post(subjectmodel_url, data={"data_1": foremost_sen, "data_2": self.input_content}, timeout=3)
print("两句相关性为(1相关,0不相关):", result.text)
# 不相关则直接交给百度Unit兜底
if result.text != "1":
return unit_chat(self.input_content)
except Exception as e:
print("两句相关性请求失败:", e)
return unit_chat(self.input_content)
list_1 = interrogate_inneo4j(self.input_content) # 根据症状实体查找症状实体
print("图数据库的查询结果为:", list_1)
if not list_1:
print("没有查询到该实体,访问百度Unit", self.input_content)
return unit_chat(self.input_content)
# 第一次会话查知识图谱时查到的水稻疾病实体
dis_foremost = self.redis_con.hget(str(self.id_for_user), "foremost_talk")
print(dis_foremost)
if dis_foremost:
# 第二次对话查到的疾病dis_second
dis_second = list(set(list_1) | set(eval(dis_foremost)))
# 去掉第一次包含的疾病
output = list(set(list_1) - set(eval(dis_foremost)))
else:
output = dis_second = list(set(list_1))
# 会话管理
self.redis_con.hset(str(self.id_for_user), "foremost_talk", str(dis_second))
self.redis_con.expire(str(self.id_for_user), 30000)
print("生成对话")
# 如果新水稻疾病实体存在则按模板二返回结果,否则返回模板四"稻稻觉得还是稻稻之前为您判断的水稻病,并不是新的水稻病"
if not output:
return self.rules_answer["4"]
else:
output = ",".join(output)
return self.rules_answer["2"] % output(5)处理用户输入的信息
在本模块中,首先需要添加路由,使用Flask中的route()装饰器将URL绑定到ser_principal()函数,如果用户访问http://xxxx/farmer/receive/(“xxx”表示ip+d端口号),将会调用ser_principal()函数进行处理。
ser_principal()函数的主要过程如下:
- 首先连接redis,根据用户的id判断是否有上一句话,将结果保存在foremost_talk_sym变量中,并将本次用户的对话存储到redis;
- 然后,加载对话模板、实例化Main_Logic()类;
- 最后,判断foremost_talk_sym变量是否为空,若不为空,则调用second_deal_talk()方法进行处理;若为空,则调用foremost_deal_talk()方法进行处理。
@app.route('/farmer/receive/', methods=["POST"]) # 装饰器
def ser_principal():
id_for_user = request.form['id_for_user']
talk_user = request.form['talk_user']
redis_con = redis.StrictRedis(connection_pool=link_pool) # 连接redis
foremost_talk_sym = redis_con.hget(str(id_for_user), "foremost_talk_sym")
redis_con.hset(str(id_for_user), "foremost_talk_sym", talk_user)
print("会话正常存储了对话")
# 加载对话模板文件
rules_answer = json.load(open("talk_template.json", "r"))
print('下面实例化Main_Logic类.')
main_logic = Main_Logic(id_for_user,talk_user,rules_answer, redis_con)
if foremost_talk_sym:
return main_logic.second_deal_talk(foremost_talk_sym)
else:
return main_logic.foremost_deal_talk()4. 测试
模拟用户ID及对话,测试上述代码的有效性。
在networking/目录下的for_principal.py文件中编写本模块的代码:
import requests # 导入requests包,模拟post请求
# 模拟用户的id为13424,输入信息为"菌丝块"
output = requests.post("http://127.0.0.1:8080/farmer/receive/", data={"id_for_user":"13431", "talk_user": "菌丝块"})
print(output.text)首先,挂起服务。
进入Ai_Farmer_Doctor/networking/目录下,在终端执行以下命令挂起服务,注意参数"-b"指定的是ip+端口,因为在for_principal.py文件中请求的端口为“8080”,挂起服务的端口要与请求服务的端口保持一致。
gunicorn -w 1 -b 0.0.0.0:8080 principal:app命令执行过程如下图所示:

在确保neo4j、redis服务启动、句子相关性判断模型挂起的情况下,运行for_principal.py文件,即可得到查询结果:

















 557
557

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









