







一、AVL树(二叉平衡树:高度平衡的二叉搜索树)
0、二叉平衡树的概念
左右子树高度差不超过1的二叉搜索树。
public class AVLTree{
static class AVLTreeNode {
public TreeNode left = null; // 节点的左孩子
public TreeNode right = null; // 节点的右孩子
public TreeNode parent = null; // 节点的双亲
public int val = 0;
public int bf = 0; // 当前节点的平衡因子=右子树高度-左子树的高度
public TreeNode(int val) {
this.val = val;
}
}
public TreeNode root;
//插入函数等....
}
// 将AVLTreeNode定义为AVLTree的静态内部类
1、二叉平衡树的查找
二叉平衡树的查找和二叉搜索树的方法是一样的,因为它们具有相同的结构特点——右孩子val值小于根节点val,根节点val小于左孩子val。
2、二叉平衡树的插入
二叉搜索树的插入一定是插入到叶子节点的位置。
二叉平衡树将节点插入到叶子节点之后,要维护左右子树的平衡因此可能还要进行旋转操作。
- 先将数据插入到AVL树当中(和二叉搜索数一样)
- 插入进去后,根据平衡因子来进行对树的调整
3、插入后无需旋转的情况:
注意各节点bf值得变化

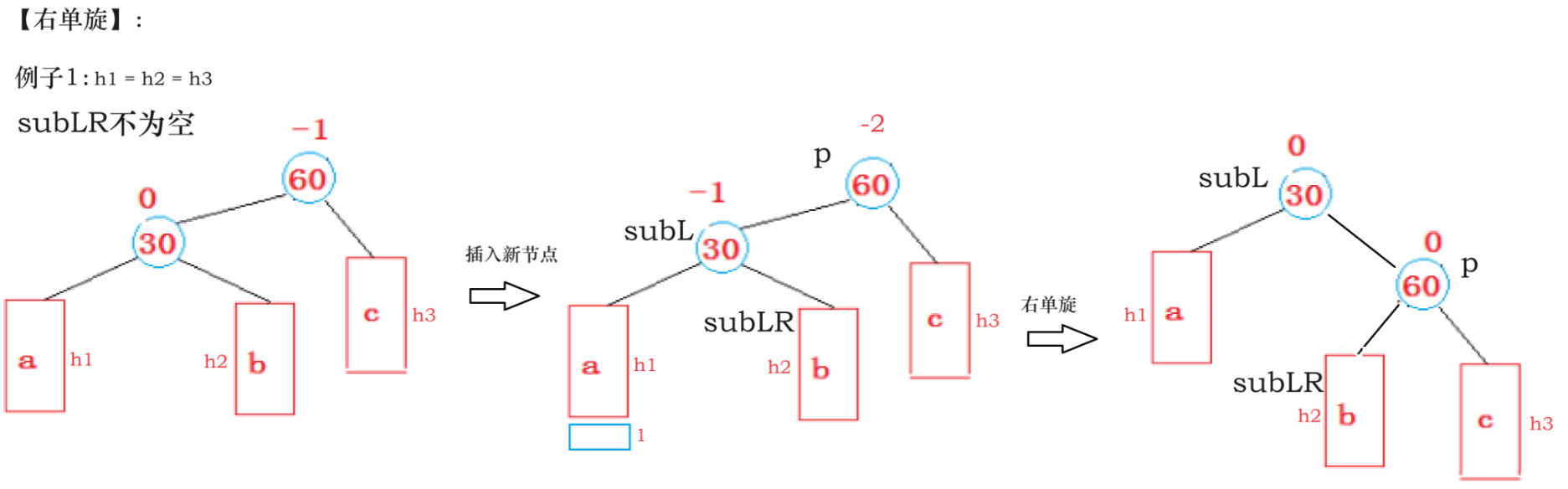
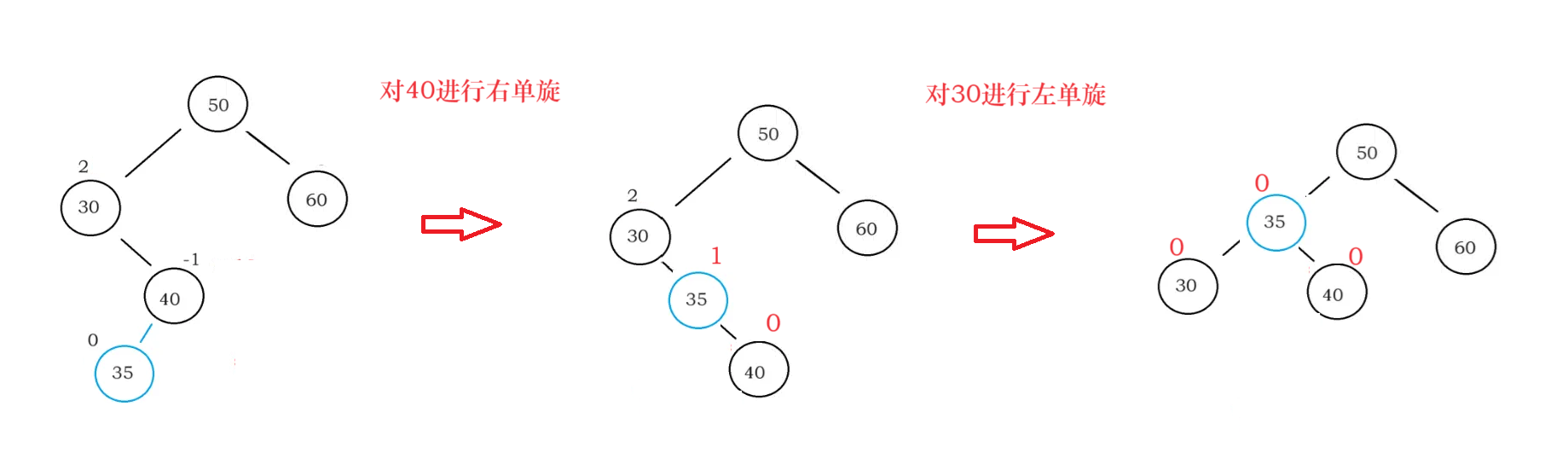
4、右单旋&左单旋:
对parent进行右单旋就是把parent.left提拔成根节点
注意各节点bf值得变化
对parent进行左单旋就是把parent.right提拔成根节点
注意各节点bf值得变化


补充:相对与根节点各个节点的名称,后续得图会用到这些名称


树parent是pParent(parent.parent)的一棵子树,对parent进行旋转后需要将新的根节点的parent指针指向pParent.


//检查 当前是不是就是根节点
if(parent == root) {
root = subL;
// subL.parent等于parent,subL提拔成了根节点,所以要将subL.parent设置为null,
subL.parent = null;
}else {
//不是根节点,判断这棵子树是左子树还是右子树
if(pParent.left == parent) {
pParent.left = subL;
}else {
pParent.right = subL;
}
subL.parent = pParent;
}
5、左右双旋 &右左双旋
- 注意指针指向
- 注意维护bf
右左双旋过程图:

左右双旋过程图:


下面这两幅图介绍了左右双旋时如何维护个节点的bf值(右左双选的不想画了,太累了)


/**
* 左右双旋
* @param parent
*/
private void rotateLR(TreeNode parent) {
TreeNode subL = parent.left;
TreeNode subLR = subL.right;
int bf = subLR.bf;
rotateLeft(parent.left);
rotateRight(parent);
// 这个规律很重要,中间状态的bf值不重要,根据初始状态的bf值来修改平衡状态的bf值
if(bf == -1) {
parent.bf = 1;
subL.bf = 0;
subLR.bf = 0;
}else if(bf == 1){
parent.bf = 0;
subL.bf = -1;
subLR.bf = 0;
}
}
/**
* 右左双旋
* @param parent
*/
private void rotateRL(TreeNode parent) {
TreeNode subR = parent.right;
TreeNode subRL = subR.left;
int bf = subRL.bf;
rotateRight(parent.right);
rotateLeft(parent);
// 这个规律很重要,中间状态的bf值不重要,根据初始状态的bf值来修改平衡状态的bf值
if(bf == 1) {
parent.bf = -1;
subR.bf = 0;
subRL.bf = 0;
}else if(bf == -1){
parent.bf = 0;
subR.bf = 1;
subRL.bf = 0;
}
}
6、总代码
package org.example;
/**
* @Author 12629
* @Description:
*/
public class AVLTree {
static class TreeNode {
public int val;
public int bf;//平衡因子
public TreeNode left;//左孩子的引用
public TreeNode right;//右子树的引用
public TreeNode parent;//父亲节点的引用
public TreeNode(int val) {
this.val = val;
}
}
public TreeNode root;//根节点
public boolean insert(int val) {
TreeNode node = new TreeNode(val);
if(root == null) {
root = node;
return true;
}
TreeNode parent = null;
TreeNode cur = root;
while (cur != null) {
if(cur.val < val) {
parent = cur;
cur = cur.right;
}else if(cur.val == val) {
return false;
}else {
parent = cur;
cur = cur.left;
}
}
//cur == null
if(parent.val < val) {
parent.right = node;
}else {
parent.left = node;
}
//
node.parent = parent;
cur = node;
// 平衡因子 的修改
while (parent != null) {
//先看cur是parent的左还是右 决定平衡因子是++还是--
if(cur == parent.right) {
//如果是右树,那么右树高度增加 平衡因子++
parent.bf++;
}else {
//如果是左树,那么左树高度增加 平衡因子--
parent.bf--;
}
//检查当前的平衡因子 是不是绝对值 1 0 -1
if(parent.bf == 0) {
//说明已经平衡了
break;
}else if(parent.bf == 1 || parent.bf == -1) {
//继续向上去修改平衡因子
cur = parent;
parent = cur.parent;
}else {
//右树高-》需要降低右树的高度
if(parent.bf == 2) {
if(cur.bf == 1) {
//左旋
rotateLeft(parent);
}else {
//cur.bf == -1
rotateRL(parent);
}
}else {
//parent.bf == -2 左树高-》需要降低左树的高度
if(cur.bf == -1) {
//右旋
rotateRight(parent);
}else {
//cur.bf == 1
rotateLR(parent);
}
}
//上述代码走完就平衡了
break;
}
}
return true;
}
private void rotateRL(TreeNode parent) {
TreeNode subR = parent.right;
TreeNode subRL = subR.left;
int bf = subRL.bf;
rotateRight(parent.right);
rotateLeft(parent);
if(bf == 1) {
parent.bf = -1;
subR.bf = 0;
subRL.bf = 0;
}else if(bf == -1){
parent.bf = 0;
subR.bf = 1;
subRL.bf = 0;
}
}
/**
* 左右双旋
* @param parent
*/
private void rotateLR(TreeNode parent) {
TreeNode subL = parent.left;
TreeNode subLR = subL.right;
int bf = subLR.bf;
rotateLeft(parent.left);
rotateRight(parent);
if(bf == -1) {
parent.bf = 1;
subL.bf = 0;
subLR.bf = 0;
}else if(bf == 1){
parent.bf = 0;
subL.bf = -1;
subLR.bf = 0;
}
}
/**
* 左单旋
* @param parent
*/
private void rotateLeft(TreeNode parent) {
TreeNode subR = parent.right;
TreeNode subRL = subR.left;
parent.right = subRL;
subR.left = parent;
if(subRL != null) {
subRL.parent = parent;
}
TreeNode pParent = parent.parent;
parent.parent = subR;
if(root == parent) {
root = subR;
root.parent = null;
}else {
if(pParent.left == parent) {
pParent.left = subR;
}else {
pParent.right = subR;
}
subR.parent = pParent;
}
subR.bf = parent.bf = 0;
}
/**
* 右单旋
* @param parent
*/
private void rotateRight(TreeNode parent) {
TreeNode subL = parent.left;
TreeNode subLR = subL.right;
parent.left = subLR;
subL.right = parent;
//没有subLR
if(subLR != null) {
subLR.parent = parent;
}
//必须先记录
TreeNode pParent = parent.parent;
parent.parent = subL;
//检查 当前是不是就是根节点
if(parent == root) {
root = subL;
// subL.parent等于parent,subL提拔成了根节点,所以要将subL.parent设置为null.
subL.parent = null;
}else {
//不是根节点,判断这棵子树是左子树还是右子树
if(pParent.left == parent) {
pParent.left = subL;
}else {
pParent.right = subL;
}
subL.parent = pParent;
}
subL.bf = 0;
parent.bf = 0;
}
//中序遍历的结果是有序的 就能说明当前树 一定是AVL树吗? 不一定的
private boolean inorder(TreeNode root){
return inorderHelper(root,Long.MIN_VALUE);
}
private boolean inorderHelper(TreeNode root,long pre) {
if(root == null) {
return true;
}
if(!inorderHelper(root.left,pre)) {
return false;
}
if(pre < root.val){
pre = root.val;
if(!inorderHelper(root.right,pre)){
return false;
}
return true;
}
return false;
}
private int height(TreeNode root) {
if(root == null) {
return 0;
}
int leftH = height(root.left);
int rightH = height(root.right);
return leftH > rightH ? leftH+1 : rightH+1;
}
public boolean isBalanced(TreeNode root) {
if(root == null) {
return true;
}
int leftH = height(root.left);
int rightH = height(root.right);
if(rightH-leftH != root.bf) {
System.out.println("这个节点:"+root.val+" 平衡因子异常");
return false;
}
return Math.abs(leftH-rightH) <= 1
&& isBalanced(root.left)
&& isBalanced(root.right)
&&inorder(root);// 不仅要左右平衡,还要排序
}
}
二叉平衡树的适用和不适用场景如下:
适用场景:
- 动态数据集合:
- 当需要频繁地对数据集合进行插入、删除和查找操作时,二叉平衡树是一个很好的选择。它能够保持O(log n)的时间复杂度,避免了普通二叉搜索树在极端情况下退化为链表的问题。
- 需要保持数据有序性:
- 二叉平衡树能够维护数据的有序性,同时也具有较高的查找效率。这在需要保持数据有序性并进行快速查找的场景中非常适用,例如索引数据库、缓存系统等。
- 需要高效的范围查询:
- 由于二叉平衡树能够维护数据的有序性,因此可以很高效地进行范围查询,例如查找某个区间内的所有元素。这在一些需要范围查询的应用中很有用,如地理信息系统、网络路由表管理等。
不适用场景:
- 数据集合变化较小:
- 如果数据集合的变化(插入、删除)很少,使用普通的二叉搜索树可能更加简单高效,因为不需要维护平衡性。
- 内存使用要求苛刻:
- 二叉平衡树需要存储额外的平衡信息(如高度、平衡因子),会占用更多的内存。如果内存使用非常受限,可能需要选择其他更简单的数据结构。
- 对写操作要求极高:
- 由于需要进行平衡操作,二叉平衡树的写操作(插入和删除)会稍微慢于普通的二叉搜索树。如果对写操作的性能要求极高,可能需要考虑其他数据结构。
总的来说,二叉平衡树是一种非常实用的数据结构,在需要高效管理动态有序数据集合的场景中表现优秀。但在某些特定的应用需求中,可能需要根据具体情况来权衡选择适合的数据结构。
二、红黑树
0、红黑树的概念
红黑树,是一种二叉搜索树,但在每个结点上增加一个存储位表示结点的颜色,可以是Red或Black。 通过对任何 一条从根到叶子的路径上各个结点着色方式的限制,红黑树确保没有一条路径会比其他路径长出俩倍,因而是接近 平衡的。
红黑树的性质
- 最长路径做多是最短路径的2倍。
- 每个结点不是红色就是黑色。
- 根节点是黑色的。
- 如果一个节点是红色的,则它的两个孩子结点是黑色的【没有2个连续的红色节点】。
- 对于每个结点,从该结点到其所有后代叶结点的简单路径上,均 包含相同数目的黑色结点。
- 每个叶子结点都是黑色的(此处的叶子结点指的是空结点) 。
**思考:为什么红黑树能保证:其最长路径中节点个数不会超过最短路径节点个数的两倍? **
答:路径最短为一条路径上都是黑色结点,路径最长为红黑结点交替的一条路径,因为两条路径上黑色结点数量相同,所以最长路径不会超过最短路路径的两倍。
public class RBTree {
static class RBTreeNode {
public RBTreeNode left ;
public RBTreeNode right;
public RBTreeNode parent;
public int val;
public COLOR color;
public RBTreeNode(int val) {
this.val = val;
//我们新创建的节点,颜色默认是红色的.为什么?
this.color = COLOR.RED;
}
}
public RBTreeNode root;
public boolean insert(int val) {
//todo
}
}
**思考:在节点的定义中,为什么要将节点的默认颜色给成红色的? **
答:在红黑树的定义中,将节点的默认颜色设置为红色有以下几个原因:
- 方便维护树的性质:
- 如果新插入的节点默认为黑色,那么可能会破坏第5条性质"从任意节点到其所有后代叶子节点的简单路径上,均包含相同数目的黑色节点"。
- 将新插入的节点设为红色,可以暂时不违反第5条性质,等待后续的调整操作来维护平衡。
- 简化插入操作:
- 将新节点默认设为红色,可以简化插入操作。如果新节点是黑色,则需要进一步调整树的结构和颜色来维护第5条性质。
- 将新节点设为红色后,只需要针对违反第4条性质(“不能有两个连续的红色节点”)的情况进行局部调整,而不需要对整个树的结构进行全局调整。
- 便于理解和分析:
- 将新插入节点设为红色,使得红黑树的结构和颜色变化更容易理解和分析。
- 如果新节点是黑色,则需要考虑更多的特殊情况,增加了算法的复杂性。
总之,将红黑树节点的默认颜色设置为红色,可以简化插入操作,维护树的性质,并且有利于算法的理解和分析。这是红黑树设计的一个重要考虑因素。
1、红黑树的查找
红黑树是一个特殊的二叉搜索树,查找方法和二叉搜索树是一致的
2、红黑树的插入
红黑树是在二叉搜索树的基础上加上其平衡限制条件,因此红黑树的插入可分为两步:
- 按照二叉搜索的树规则插入新节点
- 检测新节点插入后,红黑树的性质是否造到破坏。因为新节点的默认颜色是红色,因此:如果其双亲节点的颜色是黑色,没有违反红黑树任何性质,则不需要调整;但当新插入节点的双亲节点颜色为红色时,就违反了性质三不能有连在一起的红色节点,此时需要对红黑树分情况来讨论:
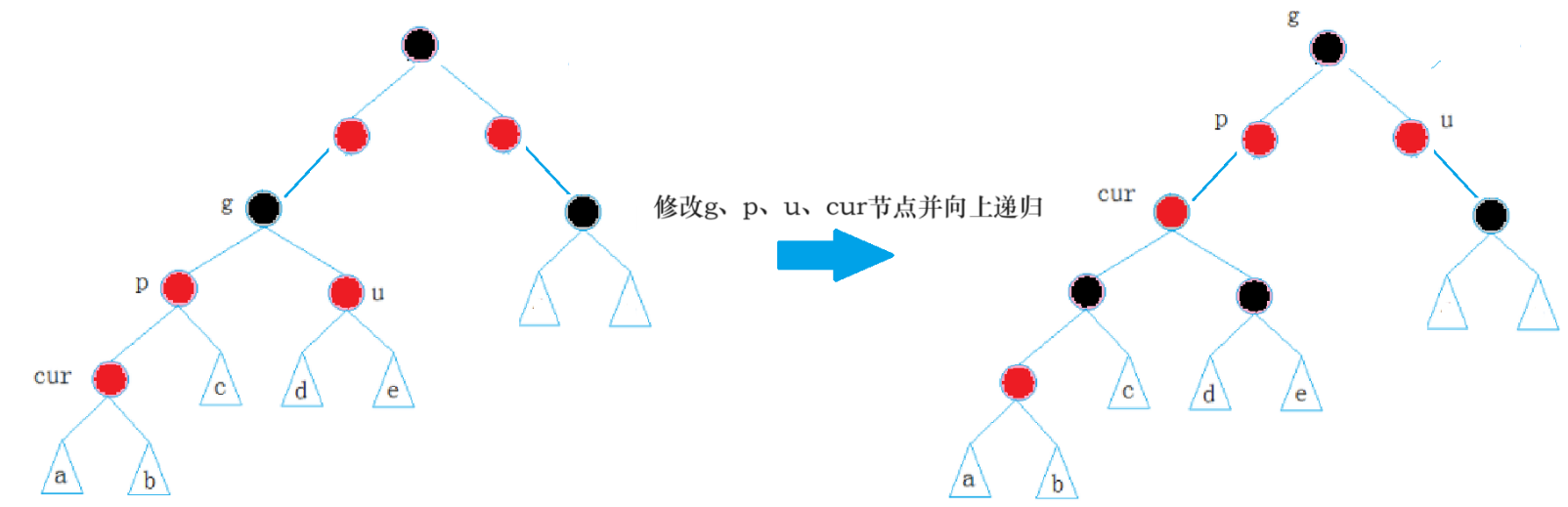
约定:cur为当前节点,p为父节点,g为祖父节点,u为叔叔节点:
情况一: cur为红,p为红,g为黑,u存在且为红


**情况二: **cur为红,p为红,g为黑,u不存在/u为黑 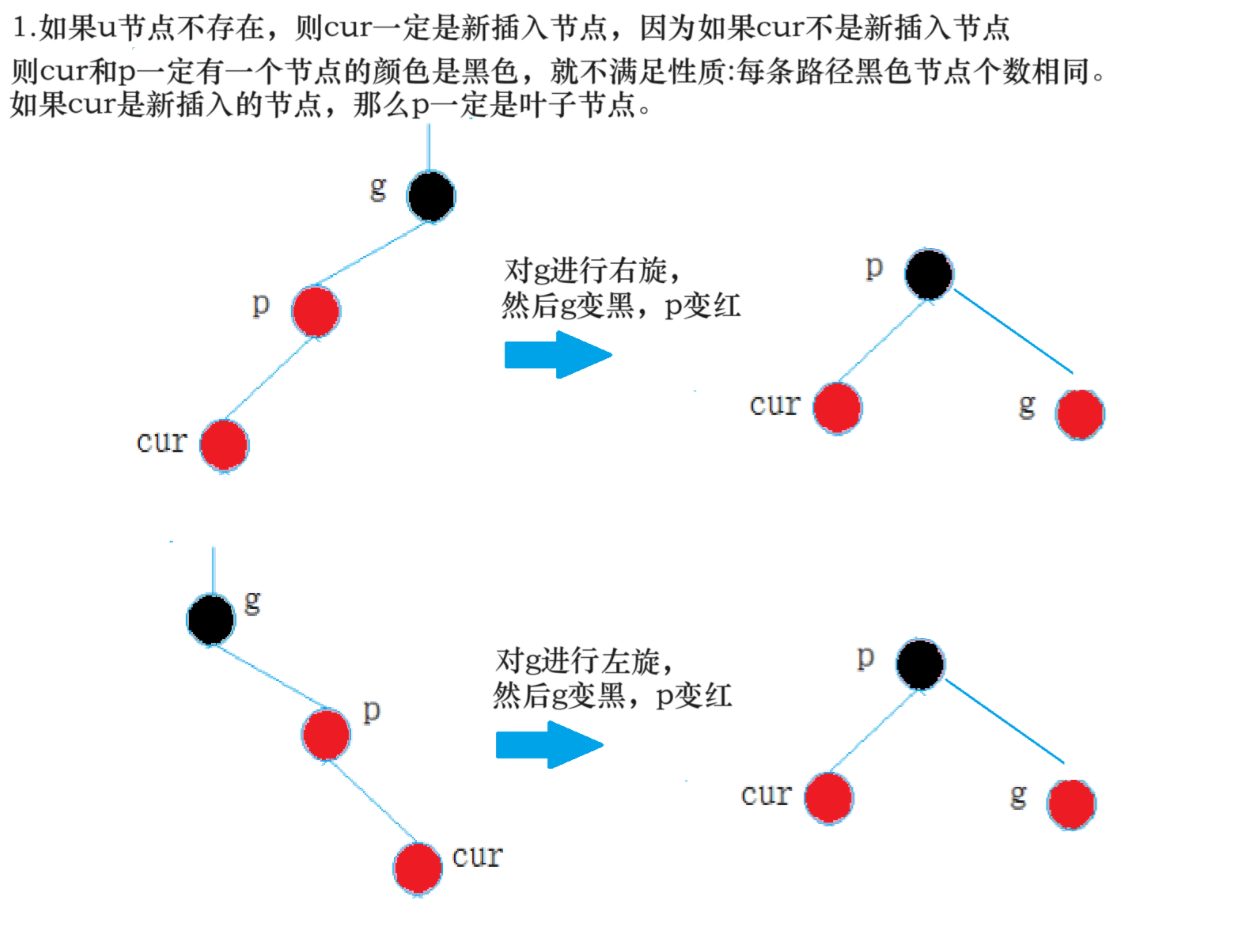



**情况三: **cur为红,p为红,g为黑,u不存在/u为黑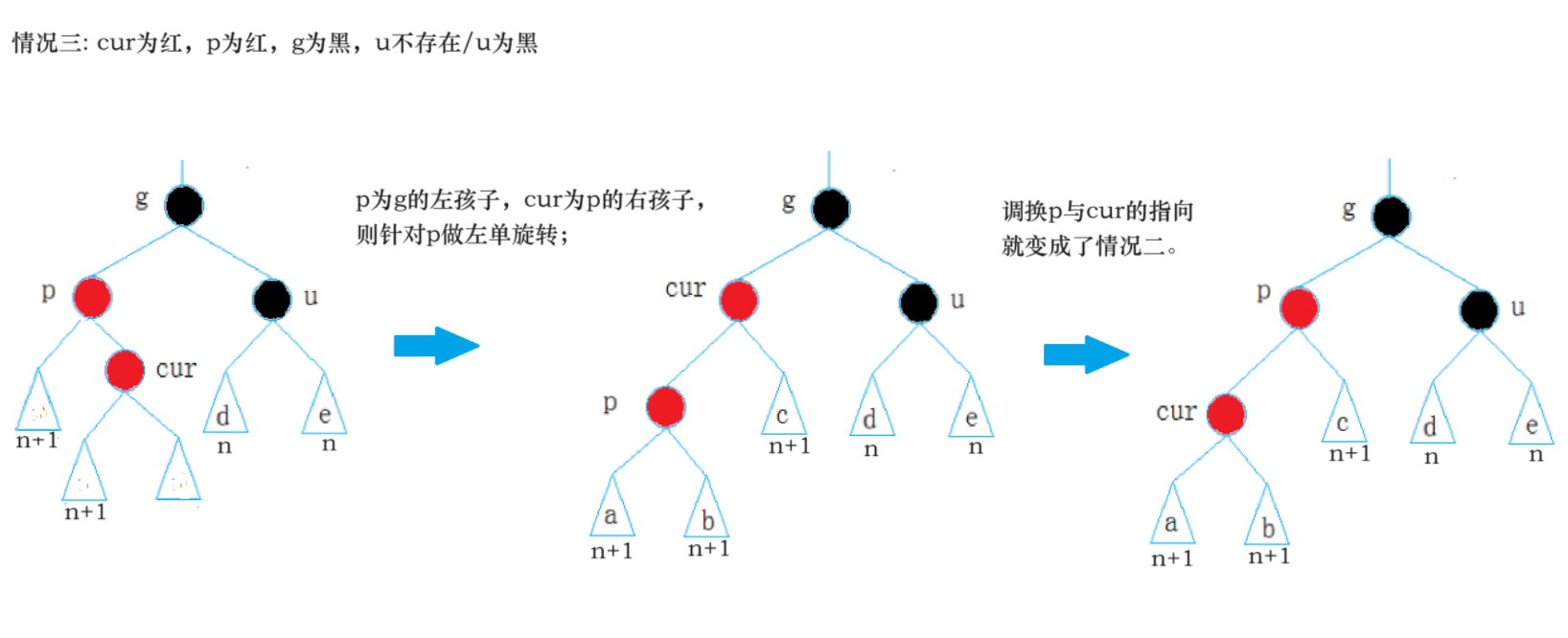

其中用到了左单旋、右单旋操作,参考AVL树。
3、模拟实现红黑树
package org.example.rbtree;
public class RBTree {
static class RBTreeNode {
public RBTreeNode left ;
public RBTreeNode right;
public RBTreeNode parent;
public int val;
public COLOR color;
public RBTreeNode(int val) {
this.val = val;
//我们新创建的节点,颜色默认是红色的.为什么?
this.color = COLOR.RED;
}
}
public RBTreeNode root;
public boolean insert(int val) {
RBTreeNode node = new RBTreeNode(val);
if (root == null) {
root = node;
root.color = COLOR.BLACK;
return true;
}
RBTreeNode parent = null;
RBTreeNode cur = root;
while (cur != null) {
if (cur.val < val) {
parent = cur;
cur = cur.right;
} else if (cur.val == val) {
return false;
} else {
parent = cur;
cur = cur.left;
}
}
//cur == null
if (parent.val < val) {
parent.right = node;
} else {
parent.left = node;
}
//
node.parent = parent;
cur = node;
//红黑树来说:就需要调整颜色
while (parent != null && parent.color == COLOR.RED) {
RBTreeNode grandFather = parent.parent;//这个引用不可能为空
if(parent == grandFather.left) {
RBTreeNode uncle = grandFather.right;
if(uncle != null && uncle.color == COLOR.RED) {
parent.color = COLOR.BLACK;
uncle.color = COLOR.BLACK;
grandFather.color = COLOR.RED;
//继续向上修改
cur = grandFather;
parent = cur.parent;
}else {
//uncle不存在 或者 uncle是黑色的
//情况三:
if(cur == parent.right) {
rotateLeft(parent);
RBTreeNode tmp = parent;
parent = cur;
cur = tmp;
}//情况三 变成了情况二
//情况二
rotateRight(grandFather);
grandFather.color = COLOR.RED;
parent.color = COLOR.BLACK;
}
}else {
//parent == grandFather.right
RBTreeNode uncle = grandFather.left;
if(uncle != null && uncle.color == COLOR.RED) {
parent.color = COLOR.BLACK;
uncle.color = COLOR.BLACK;
grandFather.color = COLOR.RED;
//继续向上修改
cur = grandFather;
parent = cur.parent;
}else {
//uncle不存在 或者 uncle是黑色的
//情况三:
if(cur == parent.left) {
rotateRight(parent);
RBTreeNode tmp = parent;
parent = cur;
cur = tmp;
}//情况三 变成了情况二
//情况二
rotateLeft(grandFather);
grandFather.color = COLOR.RED;
parent.color = COLOR.BLACK;
}
}
}
root.color = COLOR.BLACK;
return true;
}
/**
* 左单旋
* @param parent
*/
private void rotateLeft(RBTreeNode parent) {
RBTreeNode subR = parent.right;
RBTreeNode subRL = subR.left;
parent.right = subRL;
subR.left = parent;
if(subRL != null) {
subRL.parent = parent;
}
RBTreeNode pParent = parent.parent;
parent.parent = subR;
if(root == parent) {
root = subR;
root.parent = null;
}else {
if(pParent.left == parent) {
pParent.left = subR;
}else {
pParent.right = subR;
}
subR.parent = pParent;
}
}
/**
* 右单旋
* @param parent
*/
private void rotateRight(RBTreeNode parent) {
RBTreeNode subL = parent.left;
RBTreeNode subLR = subL.right;
parent.left = subLR;
subL.right = parent;
//没有subLR
if(subLR != null) {
subLR.parent = parent;
}
//必须先记录
RBTreeNode pParent = parent.parent;
parent.parent = subL;
//检查 当前是不是就是根节点
if(parent == root) {
root = subL;
root.parent = null;
}else {
//不是根节点,判断这棵子树是左子树还是右子树
if(pParent.left == parent) {
pParent.left = subL;
}else {
pParent.right = subL;
}
subL.parent = pParent;
}
}
/**
* 判断当前树 是不是红黑树
* 得满足 红黑树的性质
* @return
*/
public boolean isRBTree() {
if(root == null) {
//如果一棵树是空树,那么这棵树就是红黑树
return true;
}
if(root.color != COLOR.BLACK) {
System.out.println("违反了性质:根节点必须是黑色的!");
}
//存储当前红黑树当中 最左边路径的黑色的节点个数
int blackNum = 0;
RBTreeNode cur = root;
while (cur != null) {
if(cur.color == COLOR.BLACK) {
blackNum++;
}
cur = cur.left;
}
//检查是否存在两个连续的红色节点 && 每条路径上黑色的节点的个数是一致的
return checkRedColor(root) && checkBlackNum(root,0,blackNum);
}
/**
*
* @param root
* @param pathBlackNum 每次递归的时候,计算黑色节点的个数 0
* @param blackNum 事先计算好的某条路径上的黑色节点的个数 2
* @return
*/
private boolean checkBlackNum(RBTreeNode root,int pathBlackNum,int blackNum) {
if(root == null) {
return true;
}
if(root.color == COLOR.BLACK) {
pathBlackNum++;
}
if(root.left == null && root.right == null) {
if(pathBlackNum != blackNum) {
System.out.println("违反了性质:每条路径上黑色的节点个数是不一样的!");
return false;
}
}
return checkBlackNum(root.left,pathBlackNum,blackNum) &&
checkBlackNum(root.right,pathBlackNum,blackNum);
}
/**
* 检查是否存在两个连续的红色节点
* @param root
* @return
*/
private boolean checkRedColor(RBTreeNode root) {
if(root == null) {
return true;
}
if(root.color == COLOR.RED) {
RBTreeNode parent = root.parent;
if(parent.color == COLOR.RED) {
System.out.println("违反了性质:连续出现了两个红色的节点");
return false;
}
}
return checkRedColor(root.left) && checkRedColor(root.right);
}
public void inorder(RBTreeNode root) {
if(root == null) {
return;
}
inorder(root.left);
System.out.print(root.val+" ");
inorder(root.right);
}
}
三、位图
0、位图概念
所谓位图,就是用每一个比特位来存放某种状态(0或1),是一种哈希思想的应用,适用于海量数据,整数,数据无重复的场景。通常是用来判断某个数据存不存在的。(注意比特位访问的顺序,下图是使用byte[]数组来充当位图,它的第一位是第一个byte的第一个比特位也就是byte[0]最右边的比特位)
2、位图求交、并、差集
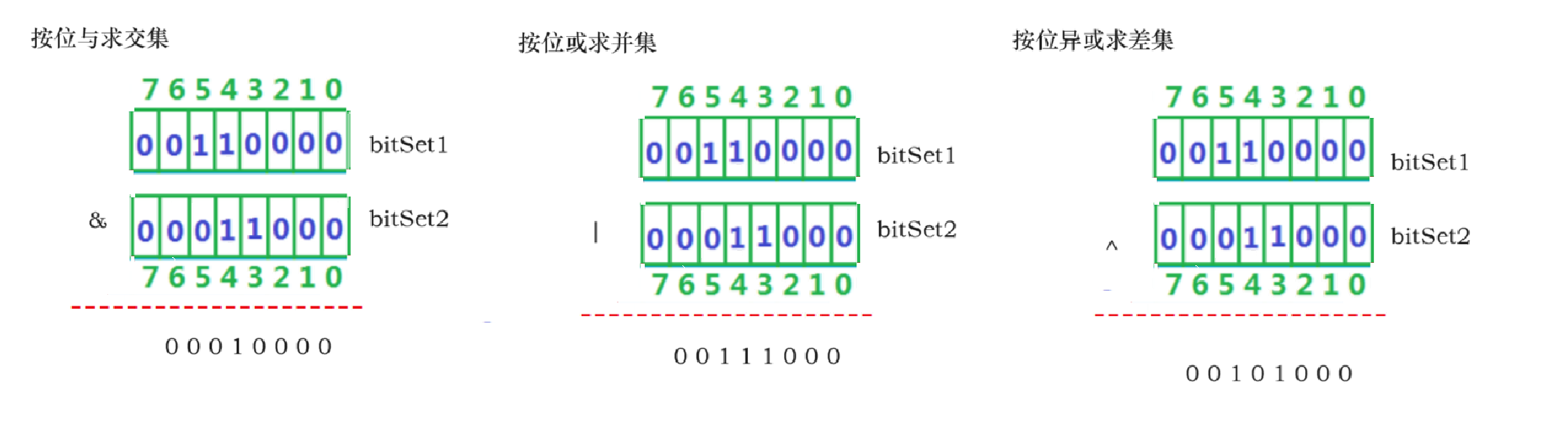
3、位图模拟实现
import java.util.Arrays;
public class MyBitSet {
public byte[] elem;
//usedSize记录当前位图当中 存在了多少个有效的数据
public int usedSize;
public MyBitSet() {
this.elem = new byte[1];
}
/**
* @param n 多少位
* n = 12
* 有可能会多给一个字节,但是无所谓。
*/
public MyBitSet(int n) {
this.elem = new byte[n/8+1];
}
/**
* 设置某一位为 1
* @param val
*/
public void set(int val) {
if(val < 0) {
throw new IndexOutOfBoundsException();
}
int arrayIndex = val / 8 ;
//扩容
if(arrayIndex > elem.length-1) {
elem = Arrays.copyOf(elem,arrayIndex+1);
}
int bitIndex = val % 8;
// 将elem[arrayIndex]的第bitIndex个比特位设置位1。
elem[arrayIndex] |= (1 << bitIndex);
usedSize++;
}
/**
* 判断当前位 是不是1
* @param val
*/
public boolean get(int val) {
if(val < 0) {
throw new IndexOutOfBoundsException();
}
int arrayIndex = val / 8 ;
int bitIndex = val % 8;
if((elem[arrayIndex] & (1 << bitIndex)) != 0) {
return true;
}
return false;
}
/**
* 将对应位置 置为 0
* @param val
*/
public void reSet(int val) {
if(val < 0) {
throw new IndexOutOfBoundsException();
}
int arrayIndex = val / 8 ;
int bitIndex = val % 8;
elem[arrayIndex] &= ~(1 << bitIndex);
usedSize--;
}
//当前位图中记录的元素的个数
public int getUsedSize() {
return usedSize;
}
}
位图的应用:
- 快速查找某个数据是否在一个集合中
- 排序 + 去重
- 求两个集合的交集、并集等
- 操作系统中磁盘块标记
补充、常见位运算总结
a,基础运算符
常见位运算符:
右移:>>
左移:<<
取反 : ~
与 :& 有0就为0
或 : | 有1就为1
异或:^ 相同为0,相异为1/无进位相加
b,给定一个数n,确定他的二进制表示第x位是0还是1
最低位在最右边
n:0110101000 我想要知道第x位的是0还是1,只需要让这一位和1与一下就可以了,
0110101000
(n>>x)&1 这个结果就是n的第x位是0还是1,并且不会改变n的大小。
c,将一个数n的二进制表示第x位修改为1
n:0110101000
0000001000 将这两个数或一下就可以得到修改后的值,所以我们需要构造出一个第x为1,其他位为0的数字,也就是(1<<x)那么最终的公式是:
n=n|(1<<x) 或者写成这样也可以 n|=(1<<x)
可以对a=0进行改造得到我们想要的值
d,将一个数n的二进制表示第x位修改为0
n:0110101000
1111110111 将这两个数&一下就可以了,所以我们需要构造出来一个第x位为0,其他位为1的二进制数,也就是~(1<<x) 那么最终运算的公式是:
n&=(~(1<<x)) 或者写成这样也可以 n=n&(~(1<<x))
e,位图思想
本质就是哈希表,我们常见的哈希表是数组形式比如int[10]={0,1,2,3,4,5,6,7,8,9},根据下标可以在O(1)时间复杂度下找到arr[i],位图的思想就说:把一个数n的二进制表示整体看做一个哈希表,每一位0或者1可以表示两个状态。boolean数组或许就是这样。(未完待续…)
f,提取一个二进制数最右侧的1
这个怎么提取确实难想,直接上答案吧:
n&(-n) 这样一个数字就是成功提取了二进制数n的最右侧1,
n = 0110101000 ,对进行取反加1得到 -n:1001011000
n = 0110101000
-n = 1001011000
ret = n&(-n) = 0000001000 这个就是最终的提取结果,n不会被改变,这个结果需要一个变量来接收.
g, 将一个二进制数n最右侧的1改为0
这个算法按理讲应该可以想出来,我要改变最低为的1,就代表比这一位高的都不能变,比这一位低的都是0,那么n-1就会是一个高位和n一致,第位从1全变成1,要改变的这一位从1变成了0,那么n&(-n)就是最终结果;
n=0110101000
n-1=0110100111
n&(n-1)=0101010000 ok,这就成功把最右侧1改为了0
h,运算符的优先级
自己写的时候能加括号就加括号
在编程中,运算符的优先级决定了表达式中运算的执行顺序。下面是一些常见运算符的优先级:
- 括号 (): 最高优先级,表达式会首先被求值。
- 一元运算符: 如
!、-、++、--等。 - 算术运算符:
*、/、%、+、-。乘、除、取模的优先级高于加、减。 - 位运算符:
~、&、|、^、<<、>>。 - 关系运算符:
<、>、<=、>=、==、!=。 - 逻辑运算符:
&&、||。 - 赋值运算符:
=、+=、-=、*=、/=、%=等。
当表达式中含有多个运算符时,优先级高的运算符会先被求值。如果优先级相同,则从左到右依次求值。
我们可以使用括号来改变表达式的求值顺序。括号内的表达式会首先被求值。
没咋用过逗号运算符
例如:
5 + 3 * 2 // 结果是 11, 因为 * 的优先级高于 +
(5 + 3) * 2 // 结果是 16, 因为括号内的表达式先被求值
位运算符是一类特殊的运算符,它们直接对数字的二进制位进行操作。位运算符的优先级如下:
- 位非 (~): 最高优先级,对一个数的二进制位进行取反操作。
- 位与 (&): 对两个数的对应位进行"与"操作。
- 位或 (|): 对两个数的对应位进行"或"操作。
- 位异或 (^): 对两个数的对应位进行"异或"操作。
- 左移 (<<): 将一个数的二进制位向左移动指定的位数。
- 右移 (>>): 将一个数的二进制位向右移动指定的位数。
位运算符的优先级高于算术运算符,但低于一元运算符。
例如:
a = 5 & 3 // 结果为 1,因为 5 的二进制是 101,3 的二进制是 011,按位与得到 001,即 1
b = 5 | 3 // 结果为 7,因为 5 的二进制是 101,3 的二进制是 011,按位或得到 111,即 7
c = 5 ^ 3 // 结果为 6,因为 5 的二进制是 101,3 的二进制是 011,按位异或得到 110,即 6
d = 5 << 1 // 结果为 10,因为 5 的二进制是 101,左移 1 位得到 1010,即 10
e = 5 >> 1 // 结果为 2,因为 5 的二进制是 101,右移 1 位得到 10,即 2
理解位运算符的优先级和使用方法对于一些底层编程和优化很有帮助。
i,异或(^)运算的规律
1,a^0=a
2,a^a=0
3,abc=a(bc) 异或运算满足交换律,一大堆数异或在一起,计算结果和异或顺序无关。
前两个还是比较好理解的,最后一个特性也是与生俱来的,因为异或没有进位相加
PS:
7,8两小节可以帮助我们完成力扣这三道题目(191,338,461)
第9可以帮助我们完成力扣这两道题目(136,260)
四、布隆过滤器
日常生活中,包括在设计计算机软件时,我们经常要判断一个元素是否在一个集合中,比如在字处理软件中,需要检查一个英语单词是否拼写正确(也就是要判断它是否在已知的字典中);在 FBI,一个嫌疑人的名字是否已经在嫌疑名单上;在网络爬虫里,一个网址是否被访问过等等。最直接的方法就是将集合中全部的元素存在计算机中,遇到一个新元素时,将它和集合中的元素直接比较即可。
一般来讲,计算机中的集合是用哈希表(hash table)来存储的。它的好处是快速准确,缺点是费存储空间。当集合比较小时,这个问题不显著,但是当集合巨大时,哈希表存储效率低的问题就显现出来了。
比如说,一个像 Yahoo、Hotmail 和 Gmail 那样的公众电子邮件(email)提供商,总是需要过滤来自发送垃圾邮件的人(spammer)的垃圾邮件。一个办法就是记录下那些发垃圾邮件的 email 地址。由于那些发送者不停地在注册新的地址,全世界少说也有几十亿个发垃圾邮件的地址,将他们都存起来则需要大量的网络服务器。
如果用哈希表,每存储一亿个 email 地址,就需要 1.6GB 的内存(用哈希表实现的具体办法是将每一个 email 地址对应成一个八字节的信息指纹,然后将这些信息指纹存入哈希表,由于哈希表的存储效率一般只有 50%,因此一个 email 地址需要占用十六个字节。一亿个地址大约要 1.6GB,即十六亿字节的内存)。因此存储几十亿个邮件地址可能需要上百 GB 的内存。除非是超级计算机,一般服务器是无法存储的。
- 用哈希表存储用户记录,缺点:浪费空间。
- 用位图存储用户记录,缺点:位图一般只能处理整形,如果内容编号是字符串,就无法处理了。
- 将哈希与位图结合,即布隆过滤器。
0、布隆过滤器概念
布隆过滤器是由布隆(Burton Howard Bloom)在1970年提出的 一种紧凑型的、比较巧妙的概率型数据结构,特点是高效地插入和查询,可以用来告诉你**“某样东西一定不存在或者可能存在”**,它是用多个哈希函数,将一个数据映射到位图结构中。此种方式不仅可以提升查询效率,也可以节省大量的内存空间。 
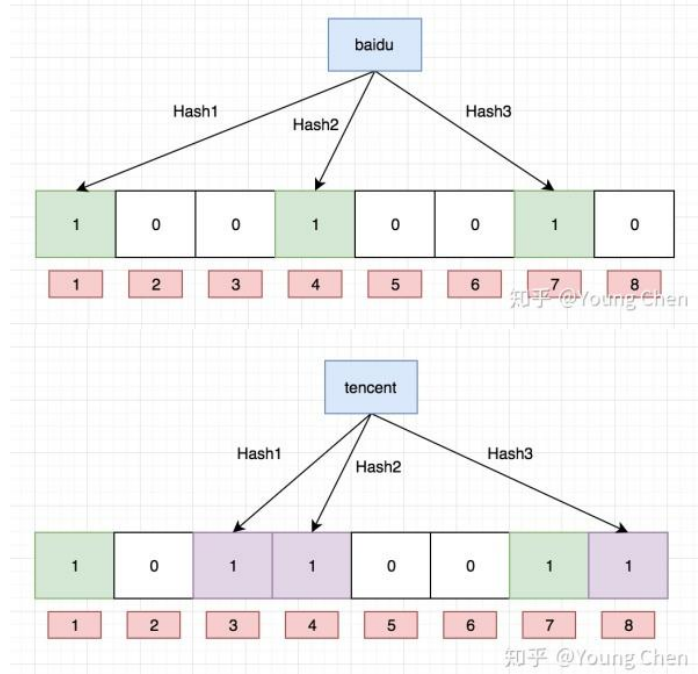
1、布隆过滤器查找


时间复杂度与哈希函数的个数成正比也就是O(K),K位哈希函数的个数。
3、布隆过滤器模拟实现
import java.util.BitSet;
class SimpleHash {
public int cap;//当前容量
public int seed;//随机
public SimpleHash(int cap,int seed) {
this.cap = cap;
this.seed = seed;
}
//根据seed不同 创建不能的哈希函数
int hash(String key) {
int h;
//(n - 1) & hash
return (key == null) ? 0 : (seed * (cap-1)) & ((h = key.hashCode()) ^ (h >>> 16));
}
}
public class MyBloomFilter {
public static final int DEFAULT_SIZE = 1 << 20;
//位图
public BitSet bitSet;
//记录存了多少个数据
public int usedSize;
public static final int[] seeds = {5,7,11,13,27,33};
public SimpleHash[] simpleHashes;
public MyBloomFilter() {
bitSet = new BitSet(DEFAULT_SIZE);
simpleHashes = new SimpleHash[seeds.length];
for (int i = 0; i < simpleHashes.length; i++) {
simpleHashes[i] = new SimpleHash(DEFAULT_SIZE,seeds[i]);
}
}
/**
* 添加元素 到布隆过滤器
* @param val
*/
public void add(String val) {
//让X个哈希函数 分别处理当前的数据
for (SimpleHash simpleHash : simpleHashes) {
int index = simpleHash.hash(val);
//把他们 都存储在位图当中即可
bitSet.set(index);
}
}
/**
* 是否包含val ,这里会存在一定的误判的
* @param val
* @return
*/
public boolean contains(String val) {
//val 一定 也是通过这个几个哈希函数去 看对应的位置
for (SimpleHash simpleHash : simpleHashes) {
int index = simpleHash.hash(val);
//只要有1个为 0 那么一定不存在
boolean flg = bitSet.get(index);
if(!flg) {
return false;
}
}
return true;
}
public static void main(String[] args) {
MyBloomFilter myBloomFilter = new MyBloomFilter();
myBloomFilter.add("hello");
myBloomFilter.add("hello2");
myBloomFilter.add("bit");
myBloomFilter.add("haha");
System.out.println(myBloomFilter.contains("hello"));
System.out.println(myBloomFilter.contains("hello3"));
System.out.println(myBloomFilter.contains("he"));
}
}
package org.example.bloomfilterdemo;
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
/**
* @Author huis
*/
public class Test {
private static int size = 1000000;//预计要插入多少数据
private static double fpp = 0.001;//期望的误判率
private static final BloomFilter<Integer> BLOOM_FILTER
= BloomFilter.create(Funnels.integerFunnel(), size, fpp);
public static void main(String[] args) {
//插入数据
for (int i = 0; i < 1000000; i++) {
BLOOM_FILTER.put(i);
}
int count = 0;
for (int i = 1000000; i < 2000000; i++) {
if (BLOOM_FILTER.mightContain(i)) {
count++;
}
}
System.out.println("总共的误判数:" + count);
}
}
<dependencies>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>19.0</version>
</dependency>
</dependencies>
4、 布隆过滤器删除
布隆过滤器不能直接支持删除工作,因为在删除一个元素时,可能会影响其他元素。比如:删除上图中"tencent"元素,如果直接将该元素所对应的二进制比特位置0,“baidu”元素也被删除了,因为这两个元素在多个哈希函数计算出的比特位上刚好有重叠。
**一种支持删除的方法:**将布隆过滤器中的每个比特位扩展成一个小的计数器,插入元素时给k个计数器(k个哈希函数计算出的哈希地址)加一,删除元素时,给k个计数器减一,通过多占用几倍存储空间的代价来增加删除操作。这种方法的缺陷:
- 无法确认元素是否真正在布隆过滤器中【会有误判】
- 存在计数回绕【回绕意思为:溢出】
5、 布隆过滤器优点
- 增加和查询元素的时间复杂度为:O(K), (K为哈希函数的个数,一般比较小),与数据量大小无关
- 哈希函数相互之间没有关系,方便硬件并行运算
- 布隆过滤器不需要存储元素本身,在某些对保密要求比较严格的场合有很大优势
- 在能够承受一定的误判时,布隆过滤器比其他数据结构有这很大的空间优势
- 数据量很大时,布隆过滤器可以表示全集,其他数据结构不能
- 使用同一组散列函数的布隆过滤器可以进行交、并、差运算;
6、布隆过滤器缺陷
- 有误判率,即存在假阳性(False Position),即不能准确判断元素是否在集合中(补救方法:再建立一个白名单,存储可能会误判的数据)
- 不能获取元素本身
- 一般情况下不能从布隆过滤器中删除元素
- 如果采用计数方式删除,可能会存在计数回绕问题
7、布隆过滤器使用场景
- google的guava包中有对Bloom Filter的实现
- 网页爬虫对URL的去重,避免爬去相同的URL地址。
- 垃圾邮件过滤,从数十亿个垃圾邮件列表中判断某邮箱是否是垃圾邮箱。
- 解决数据库缓存击穿,黑客攻击服务器时,会构建大量不存在于缓存中的key向服务器发起请求,在数据量足够大的时候,频繁的数据库查询会导致挂机。
- 秒杀系统,查看用户是否重复购买。
8、 海量数据类型面试题
0、哈希切割
- **给一个超过100G大小的log file, log中存着IP地址, 设计算法找到出现次数最多的IP地址? 与上题条件相同, 如何找到topK的IP? **
**答:**如果忽略大小,我们可以统计每个IP出现的次数。我们可以使用<K,V>结构来解决这个题。但是问题目前是100G的数据太大了,一次性是无法加载到内存当中的。
思路:尝试把当前这1个文件给拆分成若干个小文件。问题是如何拆分?如果按照大小将100G进行均分,会出现一个情况,一个文件当中最多的IP地址,不一定就是整体上最多的IP地址。所以,均分解决不了。
哈希切割:将相同的IP字符串存储到同一个文件(文件组或文件夹)当中去。
a、将IP字符串转化为整数
b、文件下标 = hash(IP),将IP存储到对应的小文件中去
c、读取每个文件的内容,统计每个IP出现的次数
1、位图应用
- 给定100亿个整数,设计算法找到只出现一次的整数?
**方法一:哈希切割:**将相同数字哈希切割到同一个文件中去,遍历每个文件,统计每个数字出现的次数,此时内存中就可以知道那些数字只出现了一次。
**方法二:两个位图: **若bitSet1[num]=1,bitSet1[num]=0,则说明num只出现了一次
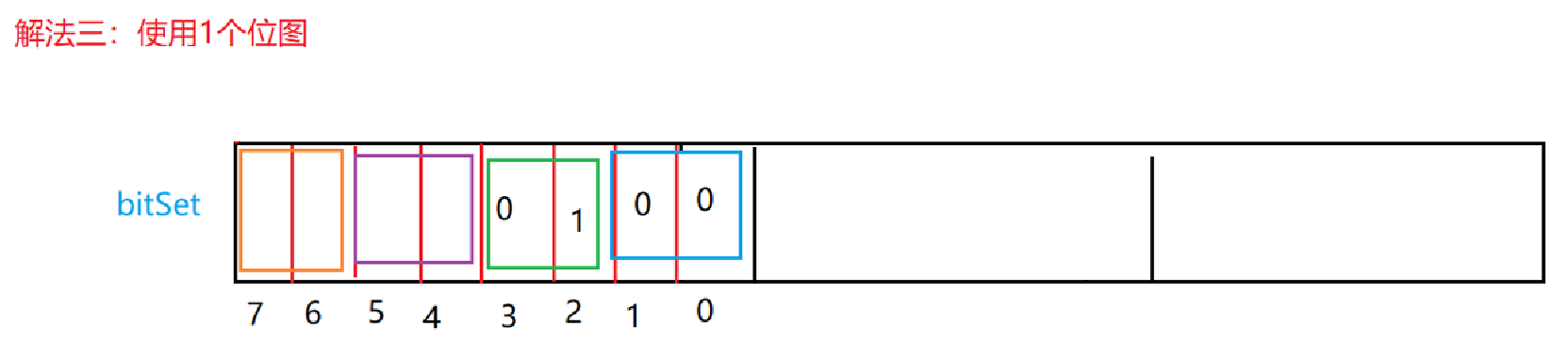
**方法三:一个位图:**使用两个比特位从当小型计数器,统计数字出现的个数
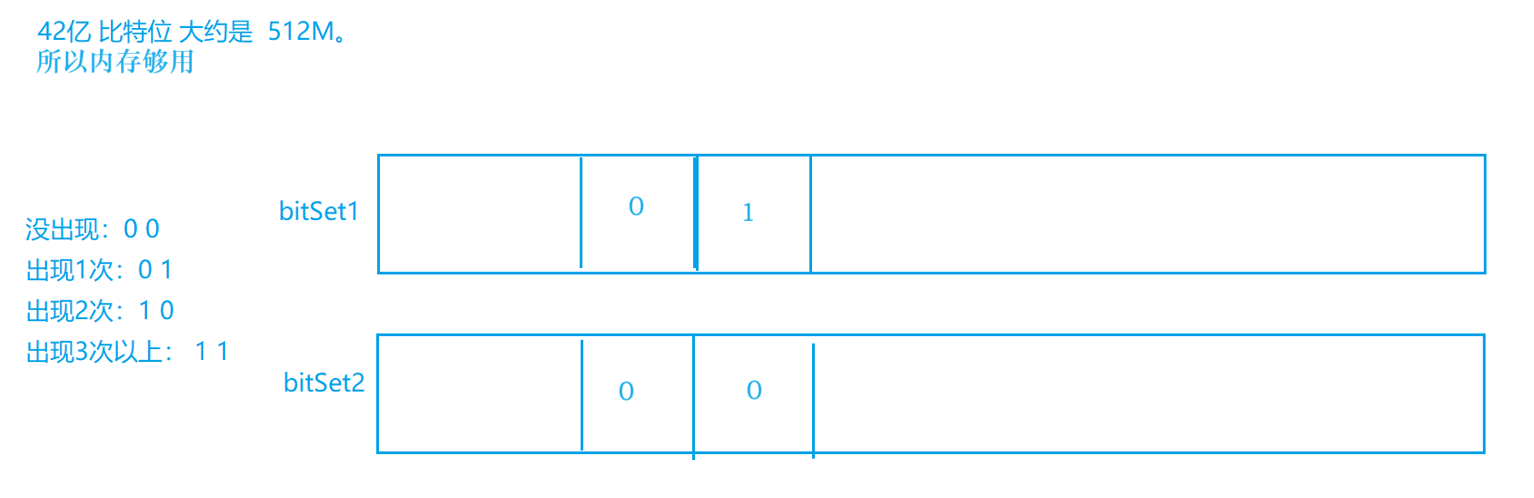
- 给两个文件,分别有100亿个整数,我们只有1G内存,如何找到两个文件的交集?
方法一:哈希切割
对两个大文件分别进行哈希切割,切割若干小文件到两个文件夹中(此过程可以顺手对文件排序),然后遍历两个文件夹中的文件求出交集。
方法二:位图
将两个文件的数据添加到用两个位图中,为两个位图做按位与操作就可以求出交集
- 位图应用变形:1个文件有100亿个int,1G内存,设计算法找到出现次数不超过2次的所有整数。
答:哈希切割、两个位图
3、布隆过滤器
- 给两个文件,分别有100亿个query,我们只有1G内存,如何找到两个文件交集?分别给出精确算法和近似算法。
答:
方法一:哈希切割(精确计算)
方法二:布隆过滤器(近似计算)

- 如何扩展BloomFilter使得它支持删除元素的操作。
答:把位图的每个单位都设计成一个小型计数器。
扩展阅读:一致性哈希 、哈希与加密、布隆过滤器
五、并查集
0、并查集概念
并查集(Union-Find)是一种用于维护元素分组信息的数据结构。它支持以下两种基本操作:
- 合并(Union):将两个不同的集合合并为一个集合。
- 查找(Find):确定某个元素属于哪个集合。
并查集通常用于解决涉及集合合并和查询的问题,例如:
- 连通性问题:判断两个元素是否在同一个连通分量中。
- 图的连通性问题:判断一个无向图是否连通。
- 基于并查集的最小生成树算法,如Kruskal算法。
并查集的实现主要有两种:
1、基于数组的并查集:使用一个数组来表示集合,数组中的每个元素代表该元素所属的集合的代表元素。
2、基于树的并查集:使用树结构来表示集合,每个集合用一棵树表示,树的根节点就是该集合的代表元素。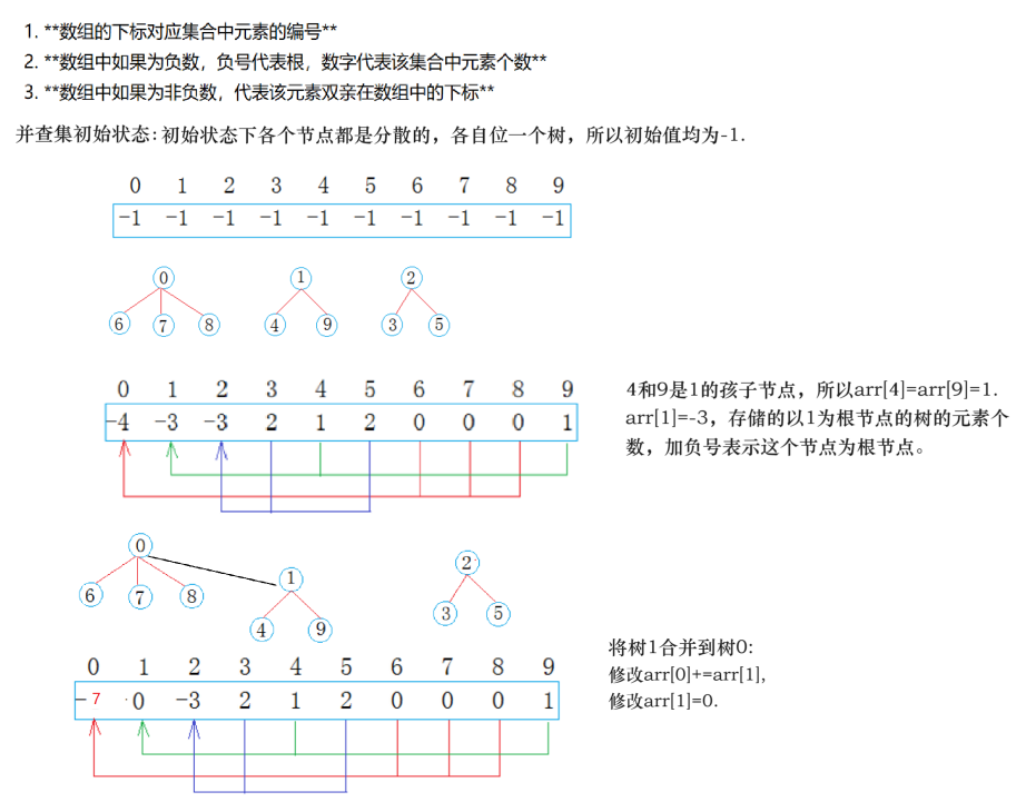
1、模拟实现并查集
import java.util.Arrays;
public class UnionFindSet {
public int[] elem;
public UnionFindSet(int n) {
this.elem = new int[n];
Arrays.fill(elem,-1);
}
/**
* 查找数据x 的根节点
* @param x
* @return 下标
*/
public int findRoot(int x) {
if(x < 0) {
throw new IndexOutOfBoundsException("下标不合法,是负数");
}
while (elem[x] >= 0 ) {
x = elem[x];//1 0
}
return x;
}
/**
* 查询x1 和 x2 是不是同一个集合
* @param x1
* @param x2
* @return
*/
public boolean isSameUnionFindSet(int x1,int x2) {
int index1 = findRoot(x1);
int index2 = findRoot(x2);
if(index1 == index2) {
return true;
}
return false;
}
/**
* 这是合并操作
* @param x1
* @param x2
*/
public void union(int x1,int x2) {
int index1 = findRoot(x1);
int index2 = findRoot(x2);
if(index1 == index2) {
return;
}
elem[index1] = elem[index1] + elem[index2];
elem[index2] = index1;
}
public int getCount() {
int count = 0;
for (int x : elem) {
if(x < 0) {
count++;
}
}
return count;
}
public void print() {
for (int x : elem) {
System.out.print(x+" ");
}
System.out.println();
}
//省份的数量
public int findCircleNum(int[][] isConnected) {
int n = isConnected.length;
UnionFindSet ufs = new UnionFindSet(n);
for(int i = 0;i < isConnected.length;i++) {
for(int j = 0;j < isConnected[i].length;j++) {
if(isConnected[i][j] == 1) {
ufs.union(i,j);
}
}
}
return ufs.getCount();
}
//等式的满足性
public boolean equationsPossible(String[] equations) {
UnionFindSet ufs = new UnionFindSet(26);
for(int i = 0; i < equations.length;i++) {
if(equations[i].charAt(1) == '=') {
ufs.union(equations[i].charAt(0)-'a',equations[i].charAt(3)-'a');
}
}
for(int i = 0; i < equations.length;i++) {
if(equations[i].charAt(1) == '!') {
int index1 = ufs.findRoot(equations[i].charAt(0)-'a');
int index2 = ufs.findRoot(equations[i].charAt(3)-'a');
if(index1 == index2) {
return false;
}
}
}
return true;
}
public static void main(String[] args) {
String[] str = {"a==b","b!=a"};
//equationsPossible(str);
}
//亲戚题
public static void main2(String[] args) {
int n = 10;
int m = 3;
int p = 2;
UnionFindSet unionFindSet = new UnionFindSet(n);
System.out.println("合并:0和6:");
unionFindSet.union(0,6);
unionFindSet.union(0,1);
System.out.println("合并:3和7:");
unionFindSet.union(3,7);
System.out.println("合并:4和8:");
unionFindSet.union(4,8);
System.out.println("以下是不是亲戚:");
boolean flg = unionFindSet.isSameUnionFindSet(1,8);
if(flg) {
System.out.println("是亲戚!");
}else {
System.out.println("不是亲戚!");
}
System.out.println("当亲的亲戚关系 "+unionFindSet.getCount()+" 对!");
}
public static void main1(String[] args) {
UnionFindSet unionFindSet = new UnionFindSet(10);
System.out.println("合并:0和6:");
unionFindSet.union(0,6);
System.out.println("合并:0和7:");
unionFindSet.union(0,7);
System.out.println("合并:0和8:");
unionFindSet.union(0,8);
System.out.println("合并:1和4:");
unionFindSet.union(1,4);
System.out.println("合并:1和9:");
unionFindSet.union(1,9);
System.out.println("合并:2和3:");
unionFindSet.union(2,3);
System.out.println("合并:2和5:");
unionFindSet.union(2,5);
unionFindSet.print();
System.out.println("合并:8和1:");
unionFindSet.union(8,1);
unionFindSet.print();
System.out.println("查找是不是同一个集合");
System.out.println(unionFindSet.isSameUnionFindSet(6, 9));
System.out.println(unionFindSet.isSameUnionFindSet(8, 2));
}
}
2、并查集主要功能

六、LURCache
0、LUR Cache概念
LRU是Least Recently Used的缩写,意思是最近最少使用,它是一种Cache替换算法。 什么是Cache?狭义的Cache指的是位于CPU和主存间的快速RAM,通常它不像系统主存那样使用DRAM技术,而使用昂贵但较快速的SRAM技术。广义上的Cache指的是位于速度相差较大的两种硬件之间,用于协调两者数据传输速度差异的结构。除了CPU与主存之间有Cache,内存与硬盘之间也有Cache,乃至在硬盘与网络之间也有某种意义上的Cache── 称为Internet临时文件夹或网络内容缓存等。Cache的容量有限,因此当Cache的容量用完后,而又有新的内容需要添加进来时,就需要挑选并舍弃原有的部分内容,从而腾出空间来放新内容。LRU Cache 的替换原则就是将最近最少使用的内容替换掉。其实, LRU译成最久未使用会更形象, 因为该算法每次替换掉的就是一段时间内最久没有使用过的内容。
2、LRU Cache的实现
实现LRU Cache的方法和思路很多,但是要保持高效实现O(1)的put和get,那么使用双向链表和哈希表的搭配是最高效和经典的。使用双向链表是因为双向链表可以实现任意位置O(1)的插入和删除,使用哈希表是因为哈希表的增删查改也是O(1)。 
3、JDK中类似LRUCahe的数据结构LinkedHashMap
参数说明:
- initialCapacity 初始容量大小:使用无参构造方法时,此值默认是16。
- loadFactor 加载因子:使用无参构造方法时,此值默认是 0.75f。
- accessOrder: false表示基于插入顺序;true表示基于访问顺序。
public static void main(String[] args) {
// 当accessOrder为false时:
Map<String, String> map = new LinkedHashMap<>(16,0.75f,false);
map.put("1", "a");
map.put("2", "b");
map.put("4", "e");
map.put("3", "c");
System.out.println(map);
}
// 输出结果:
// {1=a, 2=b, 4=e, 3=c}
// 以上结果按照插入顺序进行打印
public static void main(String[] args) {
Map map = new LinkedHashMap<>(16,0.75f,true);
map.put("1", "a");
map.put("2", "b");
map.put("4", "e");
map.put("3", "c");
map.get("1");
map.get("2");
System.out.println(map);
}
/*
输出结果:
{4=e, 3=c, 1=a, 2=b}
每次使用get方法,访问数据后,会把数据放到当前双向链表的最后。
当accessOrder为true时,get方法和put方法都会调用recordAccess方法使得最近使用的Entry移到双向链表的末尾;
当accessOrder为默认值false时,从源码中可以看出recordAccess方法什么也不会做。
*/
4、LRUCache结构的特点
双向链表的头节点是最近最少使用的元素,尾节点是最近最长用的节点。
LRUCache(Least Recently Used Cache)是一种常用的缓存淘汰策略,它的主要特点如下:
- 容量限制:LRUCache有固定的容量上限,当缓存满时需要淘汰最久未使用的数据。
- 快速访问:LRUCache需要能够快速地查找、插入和删除缓存项,通常使用哈希表(字典)和双向链表的组合实现。
- 访问顺序跟踪:LRUCache需要记录每个缓存项的访问顺序,以便快速找到最久未使用的项。
- 最近最少使用:当缓存满时,LRUCache会淘汰最近最少被访问的缓存项。这样可以保留最有价值的数据。
- 时间复杂度:基于哈希表和双向链表的LRUCache实现,可以达到平均时间复杂度O(1)的增删查操作。
典型的LRUCache实现如下:
- 使用一个哈希表(字典)存储键值对,便于快速查找。
- 使用一个双向链表维护访问顺序,最近访问的节点放在链表头部。
- 当缓存已满时,将链表尾部(最久未使用)的节点移除。
- 当访问一个缓存项时,将其移动到链表头部。
- 当添加一个新缓存项时,将其加到链表头部。
这种结构可以高效地实现LRU缓存的所有操作,是LRU缓存广泛使用的基础。
5、手搓LRUCaChe
import java.util.LinkedHashMap;
import java.util.Map;
public class LRUCache extends LinkedHashMap<Integer, Integer>{
public int capacity;
public LRUCache(int capacity) {
//这个的true 代表 基于访问顺序
super(capacity,0.75F,true);
this.capacity = capacity;
}
@Override
public Integer get(Object key) {
return super.getOrDefault(key,-1);
}
@Override
public Integer put(Integer key, Integer value) {
return super.put(key, value);
}
@Override
protected boolean removeEldestEntry(Map.Entry<Integer, Integer> eldest) {
return size() > capacity;
}
public static void main(String[] args) {
LRUCache lruCache = new LRUCache(3);
lruCache.put(100,10);
lruCache.put(110,11);
lruCache.put(120,12);
System.out.println(lruCache);
System.out.println("获取元素");
System.out.println(lruCache.get(110));
System.out.println(lruCache);
System.out.println(lruCache.get(100));
System.out.println(lruCache);
System.out.println("存放元素,会删除头节点,因为头节点是最近最少使用的: ");
lruCache.put(999,99);
System.out.println(lruCache);
}
public static void main3(String[] args) {
LinkedHashMap<String,Integer> linkedHashMap =
new LinkedHashMap<>(16,0.7f,true);
linkedHashMap.put("高博",10);
linkedHashMap.put("abcd",11);
linkedHashMap.put("hello",12);
System.out.println(linkedHashMap);
System.out.println("获取元素");
System.out.println(linkedHashMap.get("abcd"));
System.out.println(linkedHashMap);
System.out.println(linkedHashMap.get("高博"));
System.out.println(linkedHashMap);
}
//是基于插入顺序
public static void main1(String[] args) {
LinkedHashMap<String,Integer> linkedHashMap =
new LinkedHashMap<>(16,0.7f,false);
linkedHashMap.put("高博",10);
linkedHashMap.put("abcd",11);
linkedHashMap.put("hello",12);
System.out.println(linkedHashMap);
System.out.println("获取元素");
System.out.println(linkedHashMap.get("abcd"));
System.out.println(linkedHashMap);
}
}
import java.util.HashMap;
import java.util.Map;
/**
* @Author 12629
* @Description:
*/
public class MyLRUCache {
static class DLinkNode {
public int key;
public int val;
public DLinkNode prev;
public DLinkNode next;
public DLinkNode() {
}
public DLinkNode(int key, int val) {
this.key = key;
this.val = val;
}
@Override
public String toString() {
return "{ key=" + key +", val=" + val+"} ";
}
}
public DLinkNode head;//双向链表的头节点
public DLinkNode tail;//双向链表的尾巴节点
public int usedSize;//代表当前双向链表当中 有效的数据个数
public Map<Integer,DLinkNode> cache;//定义一个map
public int capacity;//容量
public MyLRUCache(int capacity) {
this.head = new DLinkNode();
this.tail = new DLinkNode();
head.next = tail;
tail.prev = head;
cache = new HashMap<>();
this.capacity = capacity;
}
/**
* 存储元素
* 1. 查找当前的这个key 是不是存储过
* @param key
* @param val
*/
public void put(int key,int val) {
//1. 查找当前的这个key 是不是存储过
DLinkNode node = cache.get(key);
//2. 如果没有存储过
if(node == null) {
//2.1 需要实例化一个节点
DLinkNode dLinkNode = new DLinkNode(key,val);
//2.2 存储到map当中一份
cache.put(key,dLinkNode);
//2.3 把该节点存储到链表的尾巴
addToTail(dLinkNode);
usedSize++;
//2.4 检查当前双向链表的有效数据个数 是不是超过了capacity
if(usedSize > capacity) {
//2.5 超过了,就需要移除头部的节点
DLinkNode remNode = removeHead();
//2.6 清楚cache当中的元素
cache.remove(remNode.key);
//2.7 usedSize--;
usedSize--;
}
printNodes("put");
}else {
//3. 如果存储过
//3.1 更新这个key对应的value
node.val = val;
//3.2 然后将该节点,移动至尾巴处【因为这个是新插入的数据】
moveToTail(node);
}
}
/**
* 移除当前节点到尾巴节点
* 逻辑:先删除 后添加到尾巴
* @param node
*/
private void moveToTail(DLinkNode node) {
//1. 先删除这个节点
removeNode(node);
//2. 添加到尾巴节点
addToTail(node);
}
/**
* 删除指定节点
* @param node
*/
private void removeNode(DLinkNode node) {
node.prev.next = node.next;
node.next.prev = node.prev;
}
/**
* 添加节点到链表的尾部
* @param node
*/
private void addToTail(DLinkNode node) {
tail.prev.next = node;
node.prev = tail.prev;
node.next = tail;
tail.prev = node;
}
private DLinkNode removeHead() {
DLinkNode del = head.next;
head.next = del.next;
del.next.prev = head;
return del;
}
/**
* 访问当前的key
* 逻辑:把你访问的节点 放到尾巴
* @param key
* @return
*/
public int get(int key) {
DLinkNode node = cache.get(key);
if(node == null) {
return -1;
}
//把最近 最多使用的 放到了链表的尾巴
moveToTail(node);
printNodes("get ");
return node.val;
}
public void printNodes(String str) {
System.out.println(str+": ");
DLinkNode cur = head.next;
while (cur != tail) {
System.out.print(cur);
cur = cur.next;
}
System.out.println();
}
public static void main(String[] args) {
MyLRUCache lruCache = new MyLRUCache(3);
lruCache.put(100,10);
lruCache.put(110,11);
lruCache.put(120,12);
System.out.println("获取元素");
System.out.println(lruCache.get(110));
System.out.println(lruCache.get(100));
System.out.println("存放元素,会删除头节点,因为头节点是最近最少使用的: ");
lruCache.put(999,99);
}
}
七、B-树
| 种类 -最后随机 O( ) 哈希 无要求 O(1) | 数据格式 | 时间复杂度 |
|---|---|---|
| 顺序查找 | 无要求 | O(N) |
| 二分查找 | 有序 | O(log2N) |
| 二叉搜索树 | 无要求 | O(log2N) 或者 O(N) |
| 二叉平衡树(AVL树和红黑树) | 无要求- 最后随机 | O(log2N) |
| 哈希 | 无要求 | O(1) |
| 位图 | 无要求 | O(1) |
| 布隆过滤器 | 无要求 | O(K)(K为哈希函数个数,一般比较小) |
以上结构适合用于数据量不是很大的情况,如果数据量非常大,一次性无法加载到内存中,使用上述结构就不是很方便。比如:使用平衡树搜索一个大文件。
上面方法其实只在内存中保存了每一项数据信息中需要查找的字段以及数据在磁盘中的位置,整体的数据实际也在磁盘中。缺陷:
- 树的高度比较高,查找时最差情况下要比较树的高度次
- 数据量如果特别大时,树中的节点可能无法一次性加载到内存中,需要多次IO
那如何加速对数据的访问呢? - 提高IO的速度
- 降低树的高度—多叉树平衡树
0、B-树
1970年,R.Bayer和E.mccreight提出了一种适合外查找的树,它是一种平衡的多叉树,称为B树(有些地方写的是B树,注意不要误读成"B减树")。一棵M阶(M>2)的B树,是一棵平衡的M路平衡搜索树,可以是空树或者满足一下性质:
- 根节点至少有两个孩子。
- 每个非根节点至少有M/2-1(上取整)个关键字,至多有M-1个关键字,并且以升序排列。
例如:当M=3的时候,至少有3/2=1.5,向上取整等于2,2-1=1个关键字,最多是2个关键字。 - 每个非根节点至少有M/2(上取整)个孩子,至多有M个孩子。
例如:当M=3的时候,至少有3/2=1.5,向上取整等于2个孩子。最多有3个孩子。 - key[i]和key[i+1]之间的孩子节点的值介于key[i]、key[i+1]之间。
- 所有的叶子节点都在同一层。
为了简单起见,假设M = 3. 即三叉树,每个节点中存储两个数据,两个数据可以将区间分割成三个部分,因此节点 应该有三个孩子,为了后续实现简单期间,节点的结构如下: 
注意:孩子永远比数据多一个。
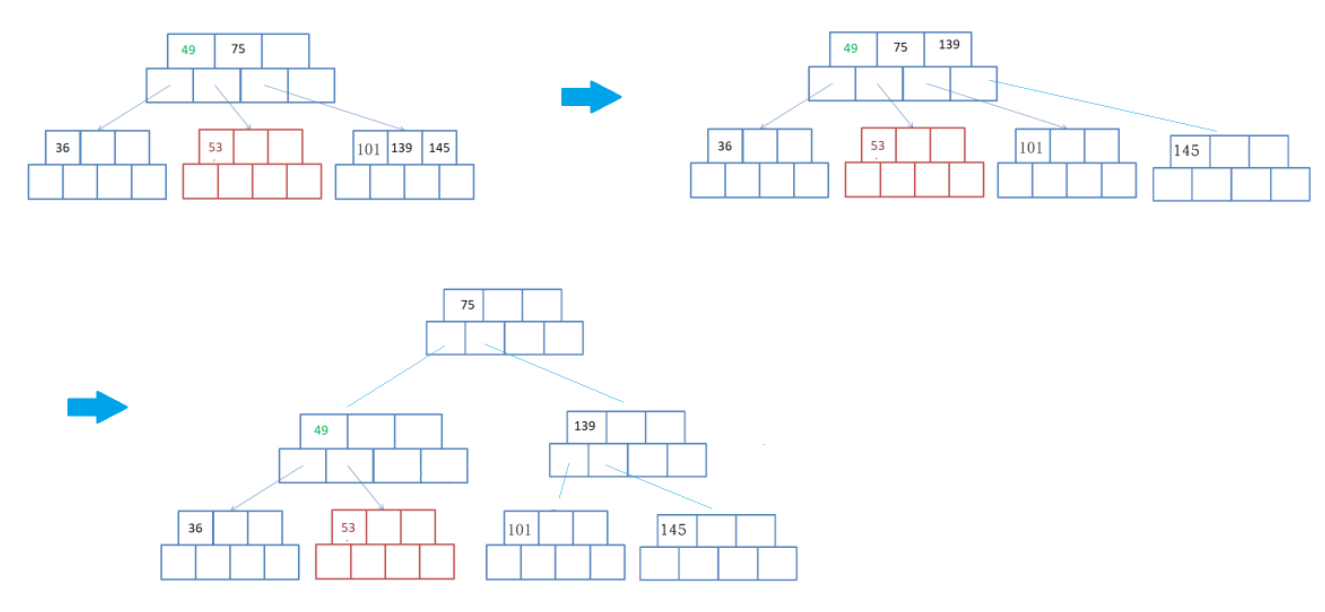
插入过程当中,有可能需要分裂,分裂的 前提是: 假设,当前是要组成一个M路查找树,关键字数必须小于等于M-1(这里关键字数>M-1就要进行节点拆分) 规则是: 把中间的元素,提取出来,放到父亲节点上,左边的单独构成一个节点,右边的单独构成一个节点。 用序列{53, 139, 75, 49, 145, 36, 101}构建B树的过程如下: 



插入过程总结:
- 如果树为空,直接插入新节点中,该节点为树的根节点
- 树非空,找待插入元素在树中的插入位置(注意:找到的插入节点位置一定在叶子节点中)
- 检测是否找到插入位置(假设树中的key唯一,即该元素已经存在时则不插入)
比特就业课 - 按照插入排序的思想将该元素插入到找到的节点中
- 检测该节点是否满足B-树的性质:即该节点中的元素个数是否等于M,如果小于则满足
- 如果插入后节点不满足B树的性质,需要对该节点进行分裂:
申请新节点
找到该节点的中间位置
将该节点中间位置右侧的元素以及其孩子搬移到新节点中
将中间位置元素以及新节点往该节点的双亲节点中插入,即继续4 - 如果向上已经分裂到根节点的位置,插入结束
1、B-树插入实现
public class Pair <K,V>{
private K key;
private V val;
public Pair(K key, V val) {
this.key = key;
this.val = val;
}
public K getKey() {
return key;
}
public void setKey(K key) {
this.key = key;
}
public V getVal() {
return val;
}
public void setVal(V val) {
this.val = val;
}
}
public class MyBtree {
static class BTRNode {
public int[] keys;//关键字
public BTRNode[] subs;//孩子
public BTRNode parent;//存储当前孩子节点的父亲节点
public int usedSize;//记录当前节点中关键字的数量
public BTRNode () {
//说明一下:这里多给一个 是为了好进行分裂
this.keys = new int[M];
this.subs = new BTRNode[M+1];
}
}
public static final int M = 3;
public BTRNode root;//当前B树的根节点
/**
* 往B树当中 插入一个元素
* @param key
*/
public boolean insert(int key) {
//1、如果B树为空的时候
if(root == null) {
root = new BTRNode();
root.keys[0] = key;
root.usedSize++;
return true;
}
//2、当B树不为空的时候,我们需要查看当前B树当中 是否存在我的Key
Pair<BTRNode,Integer> pair = find(key);
//判断 这里获取到的val值 是不是-1 来确定 当前是否存在该key
if(pair.getVal() != -1) {
return false;
}
//3、说明不存在这个key 我们要进行插入
BTRNode parent = pair.getKey();
int index = parent.usedSize-1;
for (; index >= 0;index--) {
if(parent.keys[index] >= key) {
parent.keys[index+1] = parent.keys[index];
}else {
break;
}
}
parent.keys[index+1] = key;
parent.usedSize++;
//为什么不处理 孩子呢 因为你每次插入都是再叶子节点,所以叶子节点都是null
if(parent.usedSize < M) {
//没有满
return true;
}else {
//满了-》分裂
split(parent);
return true;
}
}
/**
* 分裂的逻辑
* @param cur 当前需要分裂的节点
*/
private void split(BTRNode cur) {
BTRNode newNode = new BTRNode();
//1. 先存储当前需要分裂节点的父节点
BTRNode parent = cur.parent;
//2. 开始挪数据
int mid = cur.usedSize >> 1;
int i = mid+1;
int j = 0;
for( ; i < cur.usedSize;i++) {
newNode.keys[j] = cur.keys[i];
newNode.subs[j] = cur.subs[i];
//处理刚刚拷贝过来的孩子节点的父亲节点 为新分裂的节点
if(newNode.subs[j]!=null) {
newNode.subs[j].parent = newNode;
}
j++;
}
//多拷贝一次孩子
newNode.subs[j] = cur.subs[i];
if(newNode.subs[j]!=null) {
newNode.subs[j].parent = newNode;
}
//更新当前新节点的有效数据
newNode.usedSize = j;
//这里的-1 指的是 将来要提到父亲节点的key
cur.usedSize = cur.usedSize - j - 1;
//特殊:处理根节点的情况
if(cur == root) {
root = new BTRNode();
root.keys[0] = cur.keys[mid];
root.subs[0] = cur;
root.subs[1] = newNode;
root.usedSize = 1;
cur.parent = root;
newNode.parent = root;
return;
}
//更新当前新的节点的父亲节点
newNode.parent = parent;
//开始移动父亲节点
int endT = parent.usedSize-1;
int midVal = cur.keys[mid];
for (; endT >= 0 ; endT--) {
if(parent.keys[endT] >= midVal) {
parent.keys[endT+1] = parent.keys[endT];
parent.subs[endT+2] = parent.subs[endT+1];
}else {
break;
}
}
parent.keys[endT+1] = midVal;
//将当前父节点的孩子节点 新增为newNode
parent.subs[endT+2] = newNode;
parent.usedSize++;
if(parent.usedSize >= M) {
split(parent);
}
}
private Pair<BTRNode,Integer> find(int key) {
BTRNode cur = root;
BTRNode parent = null;
while (cur != null) {
int i = 0;
while (i < cur.usedSize) {
if(cur.keys[i] == key) {
//返回一个当前找到的节点 和 当前这个数据在节点当中的下标
return new Pair<>(cur,i);
}else if(cur.keys[i] < key) {
i++;
}else {
break;
}
}
parent = cur;
cur = cur.subs[i];
}
return new Pair<>(parent,-1);
}
public static void main(String[] args) {
MyBtree myBtree = new MyBtree();
int[] array = {53, 139, 75, 49, 145, 36,101};
for (int i = 0; i < array.length; i++) {
myBtree.insert(array[i]);
}
System.out.println("fdsafafa");
myBtree.inorder(myBtree.root);
}
private void inorder(BTRNode root){
if(root == null) {
return;
}
for(int i = 0; i < root.usedSize; ++i){
inorder(root.subs[i]);
System.out.println(root.keys[i]);
}
inorder(root.subs[root.usedSize]);
}
}
3、B-性能分析

4、B+树

5、B*树

八、图
0、图的概念
**图:**是由顶点集合及顶点间的关系组成的一种数据结构:G = (V, E),其中:
- 顶点集合V = {x|x属于某个数据对象集}是有穷非空集合;
- 边的集合E = {(x,y)|x,y属于V}或者E = {|x,y属于V && Path(x, y)}是顶点间关系的有穷集合。
(x, y)表示x到y的一条双向通路,即(x, y)是无方向的;Path表示从x到y的一条单向通路,即Path 是有方向的。
**顶点和边:**图中结点称为顶点,第i个顶点记作vi。两个顶点vi和vj相关联称作顶点vi和顶点vj之间有一条边, 图中的第k条边记作ek,ek = (vi,vj)或<vi,vj>。
**有向图和无向图:**在有向图中,顶点对<x,y>是有序的,顶点对<x,y>称为顶点x到顶点y的一条边(弧),<x,y>和<y,x>是两条不同的边,比如下图G3和G4为有向图。在无向图中,顶点对(x, y)是无序的,顶点对(x,y) 称为顶点x和顶点y相关联的一条边,这条边没有特定方向,(x, y)和(y,x)是同一条边,比如下图G1和G2为 无向图。注意:无向边(x, y)等于有向边<x,y>和<y,x>。 
完全图:在有n个顶点的无向图中,若有n * (n-1)/2条边,即任意两个顶点之间有且仅有一条边,则称此图为无向完全图,比如上图G1;在n个顶点的有向图中,若有n * (n-1)条边,即任意两个顶点之间有且仅有方向相反的边,则称此图为有向完全图,比如上图G4。
邻接顶点**:在无向图中G中,若(u, v)是E(G)中的一条边,则称u和v互为邻接顶点**,并称边(u,v)依附于顶点u和v;在有向图G中,若是E(G)中的一条边,则称顶点u邻接到v,顶点v邻接自顶点u,并称边与 顶点u和顶点v相关联。
顶点的度:顶点v的度是指与它相关联的边的条数,记作deg(v)。在有向图中,顶点的度等于该顶点的入度与 出度之和,其中顶点v的入度是以v为终点的有向边的条数,记作indev(v);顶点v的出度是以v为起始点的有向 边的条数,记作outdev(v)。因此:dev(v) = indev(v) + outdev(v)。注意:对于无向图,顶点的度等于该顶 点的入度和出度,即dev(v) = indev(v) = outdev(v)。
路径:在图G = (V, E)中,若从顶点vi出发有一组边使其可到达顶点vj,则称顶点vi到顶点vj的顶点序列为从 顶点vi到顶点vj的路径。
路径长度:对于不带权的图,一条路径的路径长度是指该路径上的边的条数;对于带权的图,一条路径的路 径长度是指该路径上各个边权值的总和。 
简单路径与回路:若路径上各顶点v1,v2,v3,…,vm均不重复,则称这样的路径为简单路径。若路 径上 第一个顶点v1和最后一个顶点vm重合,则称这样的路径为回路或环 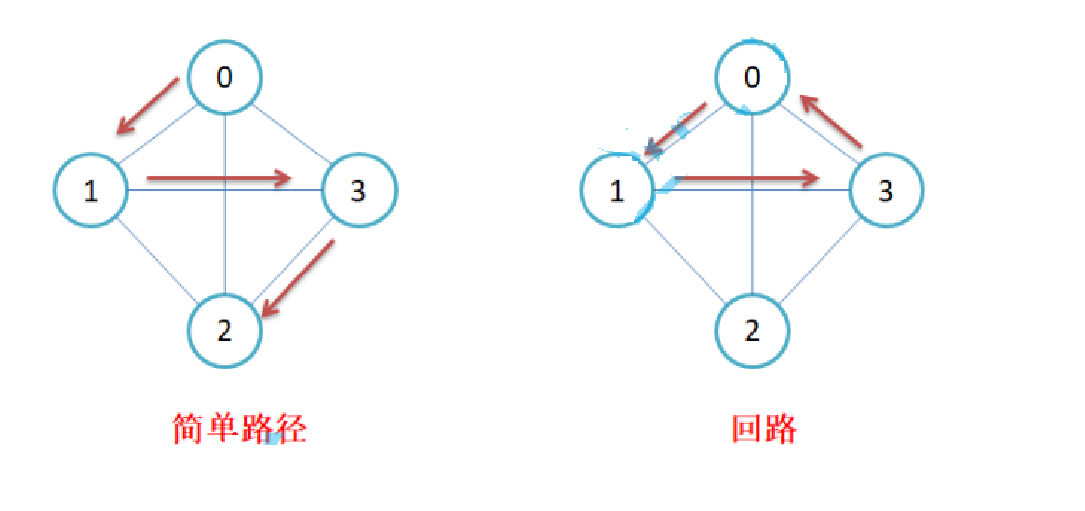
子图:设图G = {V, E}和图G1 = {V1 ,E1},若V1属于V且E1属于E,则称G1是G的子图。
连通图:在无向图中,若从顶点v1到顶点v2有路径,则称顶点v1与顶点v2是连通的。如果图中任意一 对顶点 都是连通的,则称此图为连通图。
强连通图:在有向图中,若在每一对顶点vi和vj之间都存在一条从vi到vj的路径,也存在一条从vj到 vi的路 径,则称此图是强连通图。
生成树:一个连通图的最小连通子图称作该图的生成树。有n个顶点的连通图的生成树有n个顶点和n-1条边。
1、如何存储图
因为图中既有节点,又有边(节点与节点之间的关系),因此,在图的存储中,只需要保存:节点和边关系即可。节点保存比较简单,只需要一段连续空间即可,那边关系该怎么保存呢?
1-1、邻接矩阵
因为节点与节点之间的关系就是连通与否,即为0或者1,因此邻接矩阵(二维数组)即是:先用一个数组将定点保存,然后采用矩阵来表示节点与节点之间的关系。 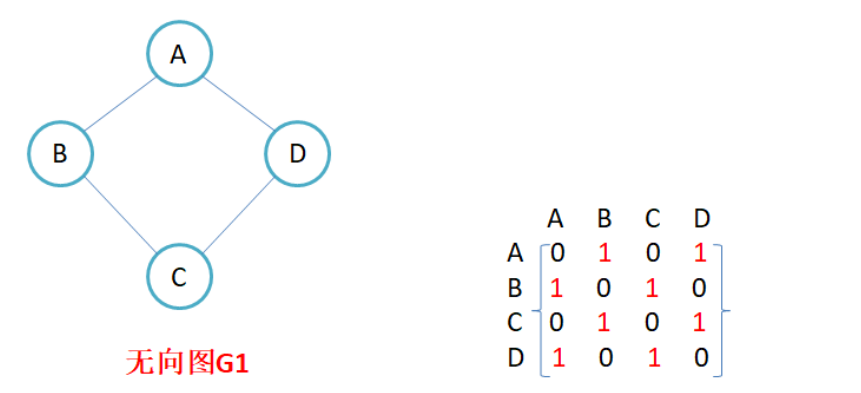
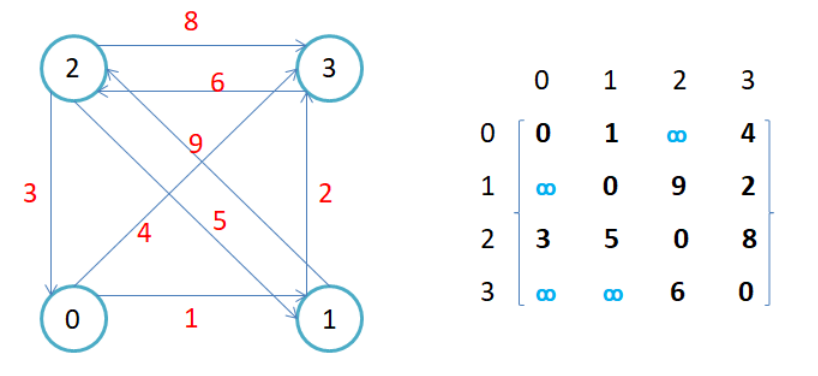
注意:
- 无向图的邻接矩阵是对称的,第i行(列)元素之和,就是顶点i的度。有向图的邻接矩阵则不一定是对称的,第i行(列)元素之后就是顶点i 的出(入)度。
- 如果边带有权值,并且两个节点之间是连通的,上图中的边的关系就用权值代替,如果两个顶点不通,则使用无穷大代替。
- 邻接矩阵存储图的优点是能够快速知道两个顶点是否连通,缺陷是如果顶点比较多,边比较少时,矩阵中存储了大量的0成为系数矩阵,比较浪费空间,并且要求两个节点之间的路径不是很好求。
public class Constant {
public static final int MAX = Integer.MAX_VALUE;
}
package org.example.graph;
import org.example.unionfindset.UnionFindSet;
import java.util.*;
/**
* @Author 12629
* @Description: 使用邻接矩阵来存储图
*/
public class GraphByMatrix {
private char[] arrayV;//顶点数组
private int[][] matrix;//矩阵
private boolean isDirect;//是否是有向图
/**
* 此时
* @param size 代表当前顶点的个数
* @param isDirect
*/
public GraphByMatrix(int size,boolean isDirect) {
this.arrayV = new char[size];
matrix = new int[size][size];
for (int i = 0; i < size; i++) {
Arrays.fill(matrix[i],Constant.MAX);
}
this.isDirect = isDirect;
}
public void initArrayV(char[] array) {
for (int i = 0; i < array.length; i++) {
arrayV[i] = array[i];
}
}
/**
*
* @param srcV 起点
* @param destV 终点
* @param weight 权值
*/
public void addEdge(char srcV,char destV,int weight) {
int srcIndex = getIndexOfV(srcV);
int destIndex = getIndexOfV(destV);
matrix[srcIndex][destIndex] = weight;
//如果是无向图 那么相反的位置 也同样需要置为空
if(!isDirect) {
matrix[destIndex][srcIndex] = weight;
}
}
/**
* 获取顶点V的下标
* @param v
* @return
*/
private int getIndexOfV(char v) {
for (int i = 0; i < arrayV.length; i++) {
if(arrayV[i] == v) {
return i;
}
}
return -1;
}
/**
* 获取顶点的度:有向图 = 入度+出度
* @param v
* @return
*/
public int getDevOfV(char v) {
int count = 0;
int srcIndex = getIndexOfV(v);
for (int i = 0; i < arrayV.length; i++) {
if(matrix[srcIndex][i] != Constant.MAX) {
count++;
}
}
//计算有向图的入度
if(isDirect) {
for (int i = 0; i < arrayV.length; i++) {
if(matrix[i][srcIndex] != Constant.MAX) {
count++;
}
}
}
return count;
}
public void printGraph() {
for (int i = 0; i < arrayV.length; i++) {
System.out.print(arrayV[i]+" ");
}
System.out.println();
for (int i = 0; i < matrix.length; i++) {
for (int j = 0; j < matrix[i].length; j++) {
if(matrix[i][j] == Constant.MAX) {
System.out.print("∞ ");
}else {
System.out.print(matrix[i][j]+" ");
}
}
System.out.println();
}
}
public void bfs(char v) {
//1、定义一个visited数组 标记当前这个顶点是不是已经被 访问的
boolean[] visited = new boolean[arrayV.length];
//2、定义一个队列,来辅助完成广度优先遍历
Queue<Integer> queue = new LinkedList<>();
int srcIndex = getIndexOfV(v);
queue.offer(srcIndex);
while (!queue.isEmpty()) {
int top = queue.poll();
System.out.print(arrayV[top]+"->");
visited[top] = true;//每次弹出一个元素 就置为true
for (int i = 0; i < arrayV.length; i++) {
if(matrix[top][i] != Constant.MAX && !visited[i]) {
queue.offer(i);
visited[i] = true;
}
}
}
}
/**
* 深度优先遍历
* @param v
*/
public void dfs(char v) {
boolean[] visited = new boolean[arrayV.length];
int srcIndex = getIndexOfV(v);
dfsChild(srcIndex,visited);
}
private void dfsChild(int srcIndex,boolean[] visited) {
System.out.print(arrayV[srcIndex]+"->");
visited[srcIndex] = true;
for (int i = 0; i < arrayV.length; i++) {
if(matrix[srcIndex][i] != Constant.MAX && !visited[i]) {
dfsChild(i,visited);
}
}
}
/**
* 定义了一个边的抽象类
*/
static class Edge {
public int srcIndex;
public int destIndex;
public int weight;//权重
public Edge(int srcIndex, int destIndex, int weight) {
this.srcIndex = srcIndex;
this.destIndex = destIndex;
this.weight = weight;
}
}
/**
* 克鲁斯卡尔算法 实现
* @param minTree
* @return
*/
public int kruskal(GraphByMatrix minTree) {
//1、定义一个优先级队列 用来存储边
PriorityQueue<Edge> minQ = new PriorityQueue<>(new Comparator<Edge>() {
@Override
public int compare(Edge o1, Edge o2) {
return o1.weight - o2.weight;
}
});
int n = arrayV.length;//顶点的个数
//2. 遍历邻接矩阵,把所有的边,放到优先级队列当中
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
if(i < j && matrix[i][j] != Constant.MAX) {
minQ.offer(new Edge(i,j,matrix[i][j]));
}
}
}
UnionFindSet ufs = new UnionFindSet(n);
//3、开始从 优先级队列当中 取边
int size = 0;
int totalWight = 0;
while (size < n-1 && !minQ.isEmpty()) {
Edge edge = minQ.poll();
int srcIndex = edge.srcIndex;
int destIndex = edge.destIndex;
if(!ufs.isSameUnionFindSet(srcIndex,destIndex)) {
//添加到最小生成树当中
minTree.addEdgeUseIndex(srcIndex,destIndex,matrix[srcIndex][destIndex]);
System.out.println("选择的边:"+arrayV[srcIndex]+"->"+
arrayV[destIndex]+":"+matrix[srcIndex][destIndex]);
size++;//记录添加的边的条数
totalWight+= matrix[srcIndex][destIndex];//记录最小生成树的 权值
ufs.union(srcIndex,destIndex);
}
}
if(size == n-1) {
return totalWight;
}else {
return -1;//没有最小生成树
}
}
private void addEdgeUseIndex(int srcIndex,int destIndex,int weight) {
matrix[srcIndex][destIndex] = weight;
//如果是无向图 那么相反的位置 也同样需要置为空
if(!isDirect) {
matrix[destIndex][srcIndex] = weight;
}
}
public static void testGraphMinTree() {
String str = "abcdefghi";
char[] array =str.toCharArray();
GraphByMatrix g = new GraphByMatrix(str.length(),false);
g.initArrayV(array);
g.addEdge('a', 'b', 4);
g.addEdge('a', 'h', 8);
//g.addEdge('a', 'h', 9);
g.addEdge('b', 'c', 8);
g.addEdge('b', 'h', 11);
g.addEdge('c', 'i', 2);
g.addEdge('c', 'f', 4);
g.addEdge('c', 'd', 7);
g.addEdge('d', 'f', 14);
g.addEdge('d', 'e', 9);
g.addEdge('e', 'f', 10);
g.addEdge('f', 'g', 2);
g.addEdge('g', 'h', 1);
g.addEdge('g', 'i', 6);
g.addEdge('h', 'i', 7);
GraphByMatrix kminTree = new GraphByMatrix(str.length(),false);
System.out.println(g.kruskal(kminTree));
kminTree.printGraph();
}
//起点
public int prim(GraphByMatrix minTree,char chV) {
int srcIndex = getIndexOfV(chV);
//存储已经确定的点
Set<Integer> setX = new HashSet<>();
//先把确定的顶点放到集合当中
setX.add(srcIndex);
//初始化Y集合 ,存储的是 未确定的顶点
Set<Integer> setY = new HashSet<>();
int n = arrayV.length;
for (int i = 0; i < n; i++) {
if(i != srcIndex) {
setY.add(i);
}
}
//定义一个优先级队列
PriorityQueue<Edge> minQ = new PriorityQueue<>(new Comparator<Edge>() {
@Override
public int compare(Edge o1, Edge o2) {
return o1.weight - o2.weight;
}
});
//遍历srcIndex连接出去的所边
for (int i = 0; i < n; i++) {
if(matrix[srcIndex][i] != Constant.MAX) {
minQ.offer(new Edge(srcIndex,i,matrix[srcIndex][i]));
}
}
int size = 0;
int totalWeight = 0;
//遍历优先级队列,取出n-1条边
while (!minQ.isEmpty()) {
Edge min = minQ.poll();
int srcI = min.srcIndex;
int desT = min.destIndex;
if(setX.contains(desT)) {
//构成环
System.out.println("构成环的边:"+arrayV[srcI]+"->"+
arrayV[desT]+":"+matrix[srcI][desT]);
}else {
minTree.addEdgeUseIndex(srcI,desT,min.weight);
System.out.println("选择的边:"+arrayV[srcI]+"->"+
arrayV[desT]+":"+matrix[srcI][desT]);
totalWeight += min.weight;
size++;
if(size == n-1) {
return totalWeight;
}
//更新两个集合的
setX.add(desT);
setY.remove(desT);
//把destI连接出去的所有边,也放到优先级队列当中
for (int i = 0; i < n; i++) {
if(matrix[desT][i] != Constant.MAX && !setX.contains(i)) {
minQ.offer(new Edge(desT,i,matrix[desT][i]));
}
}
}
}
return -1;
}
public static void testGraphMinTreePrim() {
String str = "abcdefghi";
char[] array =str.toCharArray();
GraphByMatrix g = new GraphByMatrix(str.length(),false);
g.initArrayV(array);
g.addEdge('a', 'b', 4);
g.addEdge('a', 'h', 8);
//g.addEdge('a', 'h', 9);
g.addEdge('b', 'c', 8);
g.addEdge('b', 'h', 11);
g.addEdge('c', 'i', 2);
g.addEdge('c', 'f', 4);
g.addEdge('c', 'd', 7);
g.addEdge('d', 'f', 14);
g.addEdge('d', 'e', 9);
g.addEdge('e', 'f', 10);
g.addEdge('f', 'g', 2);
g.addEdge('g', 'h', 1);
g.addEdge('g', 'i', 6);
g.addEdge('h', 'i', 7);
GraphByMatrix primTree = new GraphByMatrix(str.length(),false);
System.out.println(g.prim(primTree,'a'));
primTree.printGraph();
}
/**
*
* @param vSrc 指定的起点
* @param dist 距离数组
* @param pPath 路径
*/
public void dijkstra(char vSrc,int[] dist,int[] pPath) {
int srcIndex = getIndexOfV(vSrc);
//距离数据初始化
Arrays.fill(dist,Constant.MAX);
dist[srcIndex] = 0;
//路径数组初始化
Arrays.fill(pPath,-1);
pPath[srcIndex] = 0;
//当前顶点是否被访问过?
int n = arrayV.length;
boolean[] s = new boolean[n];
//n个顶点,要更新n次,每次都要从0下标开始,找到一个最小值
for (int k = 0; k < n; k++) {
int min = Constant.MAX;
int u = srcIndex;
for (int i = 0; i < n; i++) {
if(s[i] == false && dist[i] < min) {
min = dist[i];
u = i;//更新u下标
}
}
s[u] = true;//u:s
//松弛u连接出去的所有的顶点 v
for (int v = 0; v < n; v++) {
if(s[v] == false && matrix[u][v] != Constant.MAX
&& dist[u] + matrix[u][v] < dist[v]) {
dist[v] = dist[u] + matrix[u][v];
pPath[v] = u;//更新当前的路径
}
}
}
}
public void printShortPath(char vSrc,int[] dist,int[] pPath) {
int srcIndex = getIndexOfV(vSrc);
int n = arrayV.length;
for (int i = 0; i < n; i++) {
//i下标正好是起点 则不进行路径的打印
if(i != srcIndex) {
ArrayList<Integer> path = new ArrayList<>();
int pathI = i;
while (pathI != srcIndex) {
path.add(pathI);
pathI = pPath[pathI];
}
path.add(srcIndex);
Collections.reverse(path);
for (int pos : path) {
System.out.print(arrayV[pos]+" -> ");
}
System.out.println(dist[i]);
}
}
}
public static void testGraphDijkstra() {
/*String str = "syztx";
char[] array = str.toCharArray();
GraphByMatrix g = new GraphByMatrix(str.length(),true);
g.initArrayV(array);
g.addEdge('s', 't', 10);
g.addEdge('s', 'y', 5);
g.addEdge('y', 't', 3);
g.addEdge('y', 'x', 9);
g.addEdge('y', 'z', 2);
g.addEdge('z', 's', 7);
g.addEdge('z', 'x', 6);
g.addEdge('t', 'y', 2);
g.addEdge('t', 'x', 1);
g.addEdge('x', 'z', 4);*/
/*
搞不定负权值*/
String str = "sytx";
char[] array = str.toCharArray();
GraphByMatrix g = new GraphByMatrix(str.length(),true);
g.initArrayV(array);
g.addEdge('s', 't', 10);
g.addEdge('s', 'y', 5);
g.addEdge('t', 'y', -7);
g.addEdge('y', 'x', 3);
int[] dist = new int[array.length];
int[] parentPath = new int[array.length];
g.dijkstra('s', dist, parentPath);
System.out.println("dasfa");
g.printShortPath('s', dist, parentPath);
}
public boolean bellmanFord(char vSrc,int[] dist,int[] pPath) {
int srcIndex = getIndexOfV(vSrc);
//距离数据初始化
Arrays.fill(dist,Constant.MAX);
dist[srcIndex] = 0;
//路径数组初始化
Arrays.fill(pPath,-1);
pPath[srcIndex] = 0;
int n = arrayV.length;
for (int k = 0; k < n; k++) {
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
if(matrix[i][j] != Constant.MAX &&
dist[i] + matrix[i][j] < dist[j]) {
dist[j] = dist[i] + matrix[i][j];
pPath[j] = i;
}
}
}
}
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
if(matrix[i][j] != Constant.MAX &&
dist[i] + matrix[i][j] < dist[j]) {
return false;
}
}
}
return true;
}
public static void testGraphBellmanFord() {
String str = "syztx";
char[] array = str.toCharArray();
GraphByMatrix g = new GraphByMatrix(str.length(),true);
g.initArrayV(array);
g.addEdge('s', 't', 6);
g.addEdge('s', 'y', 7);
g.addEdge('y', 'z', 9);
g.addEdge('y', 'x', -3);
g.addEdge('z', 's', 2);
g.addEdge('z', 'x', 7);
g.addEdge('t', 'x', 5);
g.addEdge('t', 'y', 8);
g.addEdge('t', 'z', -4);
g.addEdge('x', 't', -2);
//负权回路实例
/* g.addEdge('s', 't', 6);
g.addEdge('s', 'y', 7);
g.addEdge('y', 'z', 9);
g.addEdge('y', 'x', -3);
g.addEdge('y', 's', 1);
g.addEdge('z', 's', 2);
g.addEdge('z', 'x', 7);
g.addEdge('t', 'x', 5);
g.addEdge('t', 'y', -8);
g.addEdge('t', 'z', -4);
g.addEdge('x', 't', -2);*/
int[] dist = new int[array.length];
int[] parentPath = new int[array.length];
boolean flg = g.bellmanFord('s', dist, parentPath);
if(flg) {
g.printShortPath('s', dist, parentPath);
}else {
System.out.println("存在负权回路");
}
}
public void floydWarShall(int[][] dist,int[][] pPath) {
int n = arrayV.length;
for (int i = 0; i < n; i++) {
Arrays.fill(dist[i],Constant.MAX);
Arrays.fill(pPath[i],-1);
}
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
if(matrix[i][j] != Constant.MAX) {
dist[i][j] = matrix[i][j];
pPath[i][j] = i;
}else {
pPath[i][j] = -1;
}
if(i == j) {
dist[i][j] = 0;
pPath[i][j] = -1;
}
}
}
for (int k = 0; k < n; k++) {
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
if(dist[i][k] != Constant.MAX &&
dist[k][j] != Constant.MAX &&
dist[i][k] + dist[k][j] < dist[i][j]) {
dist[i][j] = dist[i][k] + dist[k][j];
//更新父节点下标
//pPath[i][j] = k;//不对
//如果经过了 i->k k->j 此时是k
//i->x->s->k k->..t->...x->j
pPath[i][j] = pPath[k][j];
}
}
}
// 测试 打印权值和路径矩阵观察数据
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
if(dist[i][j] == Constant.MAX) {
System.out.print(" * ");
}else{
System.out.print(dist[i][j]+" ");
}
}
System.out.println();
}
System.out.println("=========打印路径==========");
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
System.out.print(pPath[i][j]+" ");
}
System.out.println();
}
System.out.println("=================");
}
}
public static void testGraphFloydWarShall() {
String str = "12345";
char[] array = str.toCharArray();
GraphByMatrix g = new GraphByMatrix(str.length(),true);
g.initArrayV(array);
g.addEdge('1', '2', 3);
g.addEdge('1', '3', 8);
g.addEdge('1', '5', -4);
g.addEdge('2', '4', 1);
g.addEdge('2', '5', 7);
g.addEdge('3', '2', 4);
g.addEdge('4', '1', 2);
g.addEdge('4', '3', -5);
g.addEdge('5', '4', 6);
int[][] dist = new int[array.length][array.length];
int[][] parentPath = new int[array.length][array.length];
g.floydWarShall(dist,parentPath);
for (int i = 0; i < array.length; i++) {
g.printShortPath(array[i],dist[i],parentPath[i]);
System.out.println("************************");
}
}
public static void main(String[] args) {
testGraphFloydWarShall();
}
public static void main1(String[] args) {
GraphByMatrix graph = new GraphByMatrix(4,false);
char[] array = {'A','B','C','D'};
graph.initArrayV(array);
graph.addEdge('A','B',1);
graph.addEdge('A','D',1);
graph.addEdge('B','A',1);
graph.addEdge('B','C',1);
graph.addEdge('C','B',1);
graph.addEdge('C','D',1);
graph.addEdge('D','A',1);
graph.addEdge('D','C',1);
//graph.bfs('B');
graph.dfs('B');
//graph.printGraph();
//System.out.println(graph.getDevOfV('A'));
}
}
1-2、邻接表
邻接表:使用数组表示顶点的集合,使用链表表示边的关系。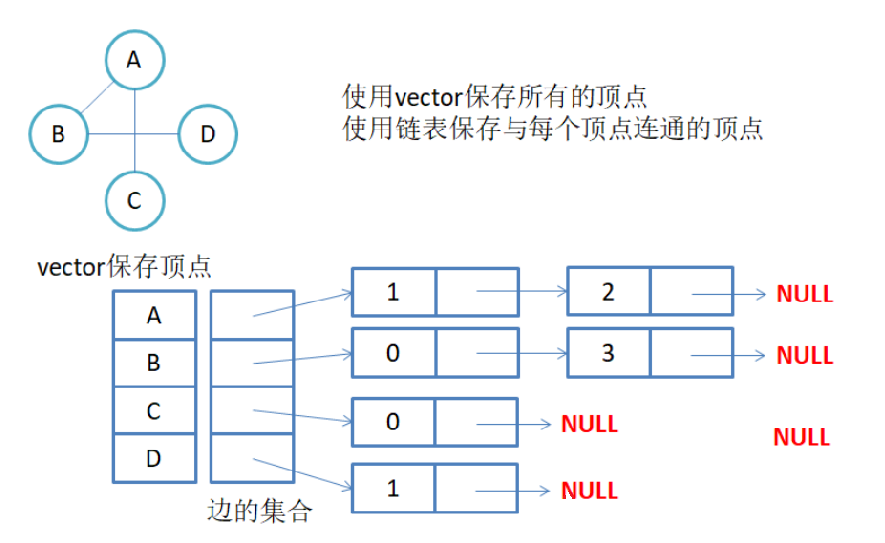
注意:无向图中同一条边在邻接表中出现了两次。如果想知道顶点vi的度,只需要知道顶点vi边链表集 合中结点的数目即可。 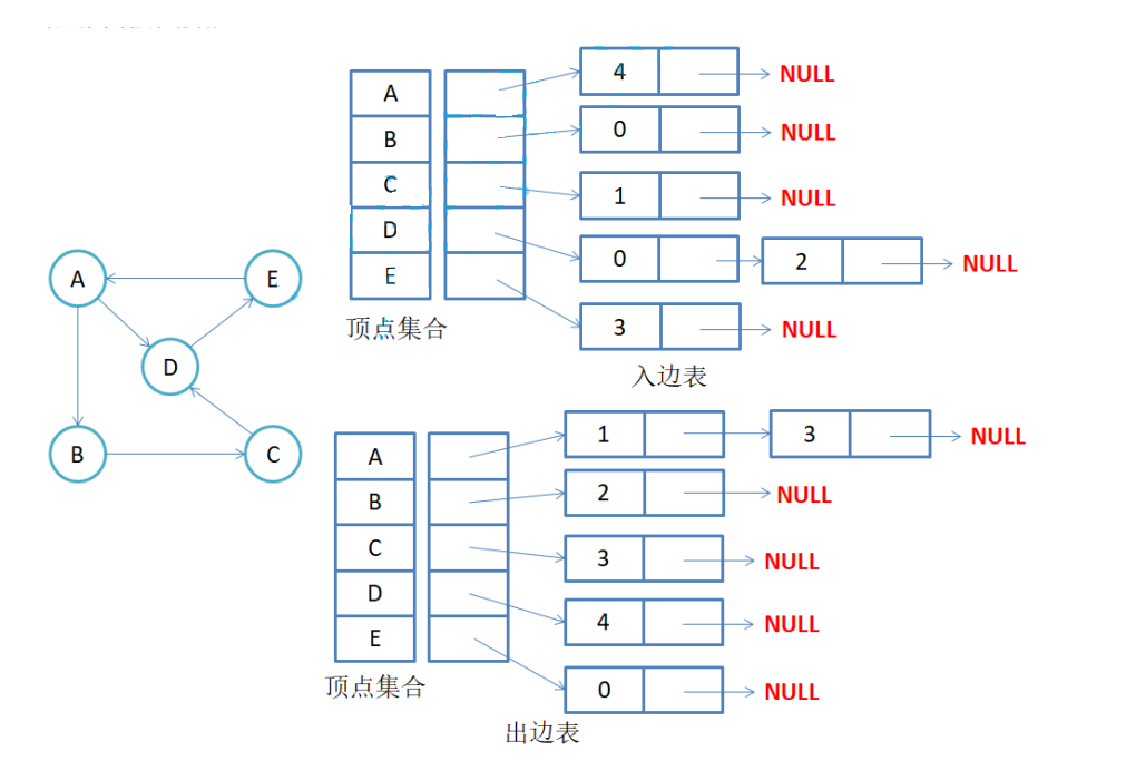
注意:有向图中每条边在邻接表中只出现一次,与顶点vi对应的邻接表所含结点的个数,就是该顶点的 出度,也称出度表,要得到vi顶点的入度,必须检测其他所有顶点对应的边链表,看有多少边顶点的dst 取值是i。
public class Constant {
public static final int MAX = Integer.MAX_VALUE;
}
package org.example.graph;
import java.util.ArrayList;
public class GraphByNode {
static class Node {
public int src;//起始位置
public int dest;//目标位置
public int weight;//权重
public Node next;
public Node(int src, int dest, int weight) {
this.src = src;
this.dest = dest;
this.weight = weight;
}
}
public char[] arrayV;
public ArrayList<Node> edgList;//存储边
public boolean isDirect;
public GraphByNode(int size,boolean isDirect) {
this.arrayV = new char[size];
edgList = new ArrayList<>(size);
for (int i = 0; i < size; i++) {
edgList.add(null);
}
this.isDirect = isDirect;
}
/**
* 初始化顶点数组
* @param array
*/
public void initArrayV(char[] array) {
for (int i = 0; i < array.length; i++) {
arrayV[i] = array[i];
}
}
/**
* 添加边
* @param srcV
* @param destV
* @param weight
*/
public void addEdge(char srcV,char destV,int weight) {
int srcIndex = getIndexOfV(srcV);
int destIndex = getIndexOfV(destV);
addEdgeChild(srcIndex,destIndex,weight);
//无向图 需要添加两条边
if(!isDirect) {
addEdgeChild(destIndex,srcIndex,weight);
}
}
private void addEdgeChild (int srcIndex , int destIndex,int weight) {
//这里拿到是头节点
Node cur = edgList.get(srcIndex);
while (cur != null) {
if(cur.dest == destIndex) {
return;
}
cur = cur.next;
}
//之前没有存储过这条边
Node node = new Node(srcIndex,destIndex,weight);
node.next = edgList.get(srcIndex);
edgList.set(srcIndex,node);
}
private int getIndexOfV(char v) {
for (int i = 0; i < arrayV.length; i++) {
if(arrayV[i] == v) {
return i;
}
}
return -1;
}
public void printGraph() {
for (int i = 0; i < arrayV.length; i++) {
System.out.print(arrayV[i]+"->");
Node cur = edgList.get(i);
while (cur != null) {
System.out.print(arrayV[cur.dest]+" ->");
cur = cur.next;
}
System.out.println();
}
}
/**
* 获取顶点的度
* @param v
* @return
*/
public int getDevOfV(char v) {
int count = 0;
int srcIndex = getIndexOfV(v);
Node cur = edgList.get(srcIndex);
while (cur != null) {
count++;
cur = cur.next;
}
//只是计算了出度
if(isDirect) {
int destIndex = srcIndex;
for (int i = 0; i < arrayV.length; i++) {
if(i == destIndex) {
continue;
}else {
Node pCur = edgList.get(i);
while (pCur != null) {
if(pCur.dest == destIndex) {
count++;
}
pCur = pCur.next;
}
}
}
}
return count;
}
public static void main(String[] args) {
GraphByNode graph = new GraphByNode(4,true);
char[] array = {'A','B','C','D'};
graph.initArrayV(array);
graph.addEdge('A','B',1);
graph.addEdge('A','D',1);
graph.addEdge('B','A',1);
graph.addEdge('B','C',1);
graph.addEdge('C','B',1);
graph.addEdge('C','D',1);
graph.addEdge('D','A',1);
graph.addEdge('D','C',1);
System.out.println("getDevOfV:: "+graph.getDevOfV('A'));
graph.printGraph();
}
}
2、图的遍历
给定一个图G和其中任意一个顶点v0,从v0出发,沿着图中各边访问图中的所有顶点,且每个顶点仅被遍历 一次。"遍历"即对结点进行某种操作的意思。 请思考树以前是怎么遍历的,此处可以直接用来遍历图吗?为什么?
2-1、图的广度优先遍历(层序遍历)

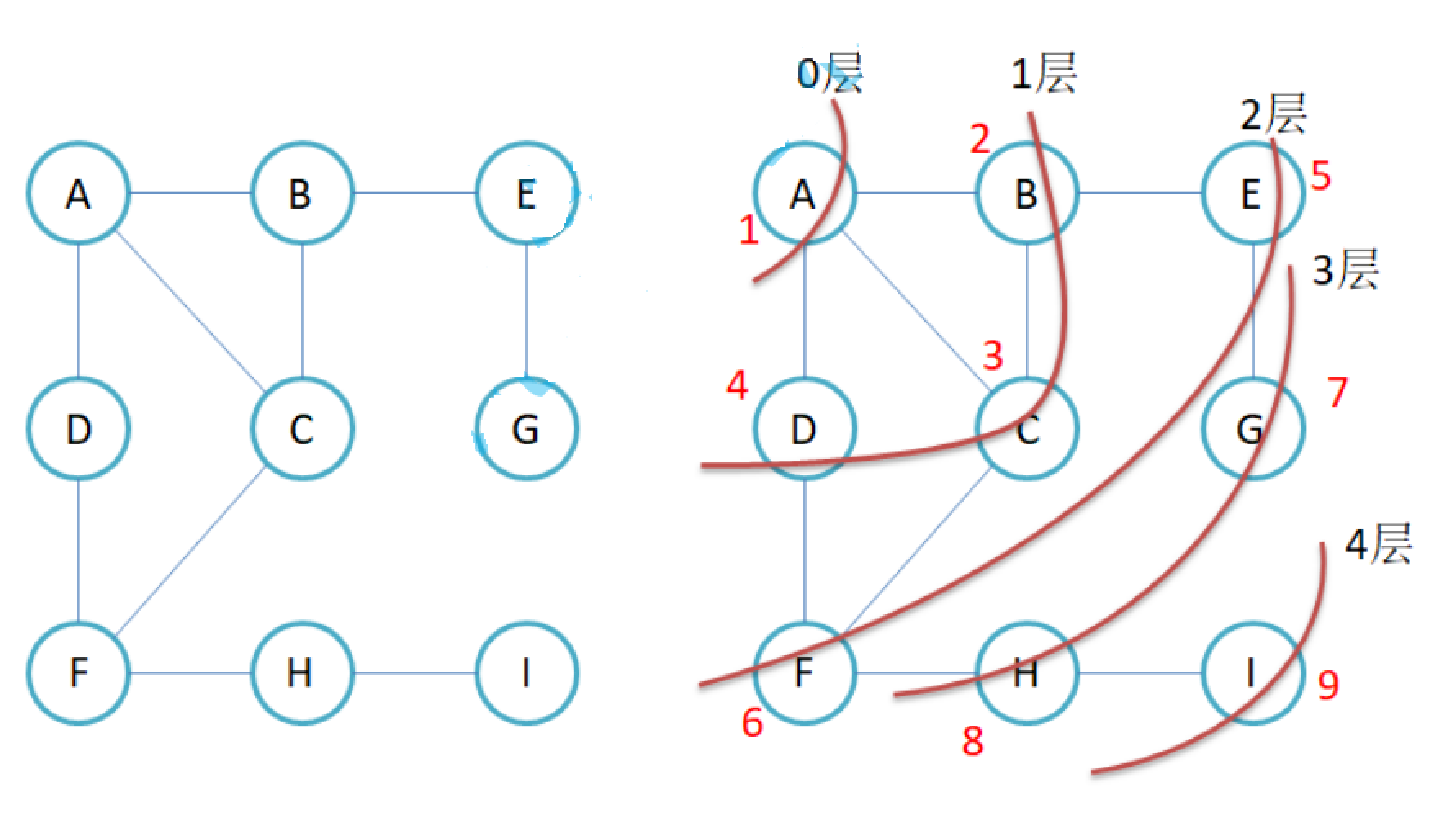
比如现在要找东西,假设有三个抽屉,东西在那个抽屉不清楚,现在要将其找到,广度优先遍历的做法是:
- 先将三个抽屉打开,在最外层找一遍。
- 将每个抽屉中红色的盒子打开,再找一遍。
- 将红色盒子中绿色盒子打开,再找一遍。
直到找完所有的盒子,注意:每个盒子只能找一次,不能重复找。
public void bfs(char v) {
//1、定义一个visited数组 标记当前这个顶点是不是已经被 访问的
boolean[] visited = new boolean[arrayV.length];
//2、定义一个队列,来辅助完成广度优先遍历
Queue<Integer> queue = new LinkedList<>();
int srcIndex = getIndexOfV(v);
queue.offer(srcIndex);
while (!queue.isEmpty()) {
int top = queue.poll();
System.out.print(arrayV[top]+"->");
visited[top] = true;//每次弹出一个元素 就置为true
for (int i = 0; i < arrayV.length; i++) {
if(matrix[top][i] != Constant.MAX && !visited[i]) {
queue.offer(i);
visited[i] = true;
}
}
}
}
2-2、图的深度优先遍历
比如现在要找东西,假设有三个抽屉,东西在那个抽不清楚,现在要将其找到,广度优先遍历的做法是:
- 先将第一个抽屉打开,在最外层找一遍
- 将第一个抽屉中红盒子打开,在红盒子中找一遍
- 将红盒子中绿盒子打开,在绿盒子中找一遍
- 递归查找剩余的两个盒子
深度优先遍历:将一个抽屉一次性遍历完(包括该抽屉中包含的小盒子),再去递归遍历其他盒子
public void dfs(char v) {
boolean[] visited = new boolean[arrayV.length];
int srcIndex = getIndexOfV(v);
dfsChild(srcIndex,visited);
}
private void dfsChild(int srcIndex,boolean[] visited) {
System.out.print(arrayV[srcIndex]+"->");
visited[srcIndex] = true;
for (int i = 0; i < arrayV.length; i++) {
if(matrix[srcIndex][i] != Constant.MAX && !visited[i]) {
dfsChild(i,visited);
}
}
}
3、图的最小生成树
连通图中的每一棵生成树,都是原图的一个极大无环子图,即:**从其中删去任何一条边,生成树就不在连通;反之,在其中引入任何一条新边,都会形成一条回路。 **
**若连通图由n个顶点组成,则其生成树必含n个顶点和n-1条边。**因此构造最小生成树的准则有三条:
- 只能使用图中的边来构造最小生成树。
- 只能使用恰好n-1条边来连接图中的n个顶点。
- 选用的n-1条边不能构成回路。
构造最小生成树的方法:Kruskal算法和Prim算法。这两个算法都采用了逐步求解的贪心策略。
贪心算法:是指在问题求解时,总是做出当前看起来最好的选择。也就是说贪心算法做出的不是整体最优的 的选择,而是某种意义上的局部最优解。贪心算法不是对所有的问题都能得到整体最优解。
3-1、Kruskal算法
Kruskal算法是一种用于查找图的最小生成树(Minimum Spanning Tree, MST)的贪心算法。最小生成树是连接图中所有顶点的边的集合,并且这些边的总权重最小,同时还要保证这些顶点是连通的。Kruskal算法的基本思想是按照边的权重从小到大的顺序选择边,但是要保证加上这条边后不会导致图中出现环。Kruskal算法的步骤如下:
- 排序:将图中的所有边按照权重从小到大排序。
- 初始化:创建一个空的边集合,用于存放最终的最小生成树的边。
- 遍历:按照排序后的顺序,依次考虑每条边。
- 如果加入这条边后不会导致图中出现环,则将这条边加入到最小生成树的边集合中。
- 检查环:可以使用并查集(Union-Find)数据结构来快速判断加入一条边是否会导致环的产生。
- 结束条件:当边集合中的边数等于图中顶点数减一时,或者所有边都被考虑过时,算法结束。
Kruskal算法的时间复杂度主要取决于边的排序和并查集的操作。如果使用优先队列(例如最小堆)来排序边,时间复杂度为O(E log E),其中E是边的数量。并查集的操作(查找和合并)的时间复杂度为O(α(N)),其中N是顶点数,α是阿克曼函数的反函数,通常认为α(N)的增长速度非常慢,对于实际问题可以近似认为是常数。
Kruskal算法适用于边稠密的图,因为它首先考虑的是边的权重,而不是顶点的连接情况。与之相对的是Prim算法,它是一种基于顶点的贪心算法,适用于顶点稠密的图。
总结:每次寻找全局最小的不构成环的边。
两个问题:
1、如何找到最小的边:优先级队列(小根堆)。
2、如何判断是否成环:使用并查集判断两个节点是否在同一个集合里面,这条边的两个点在同一个集合里面,就说明加上这条边就会成环。
public int kruskal(GraphByMatrix minTree) {
//1、定义一个优先级队列 用来存储边
PriorityQueue<Edge> minQ = new PriorityQueue<>(new Comparator<Edge>() {
@Override
public int compare(Edge o1, Edge o2) {
return o1.weight - o2.weight;
}
});
int n = arrayV.length;//顶点的个数
//2. 遍历邻接矩阵,把所有的边,放到优先级队列当中
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
if(i < j && matrix[i][j] != Constant.MAX) {
minQ.offer(new Edge(i,j,matrix[i][j]));
}
}
}
UnionFindSet ufs = new UnionFindSet(n);
//3、开始从 优先级队列当中 取边
int size = 0;
int totalWight = 0;
while (size < n-1 && !minQ.isEmpty()) {
Edge edge = minQ.poll();
int srcIndex = edge.srcIndex;
int destIndex = edge.destIndex;
if(!ufs.isSameUnionFindSet(srcIndex,destIndex)) {
//添加到最小生成树当中
minTree.addEdgeUseIndex(srcIndex,destIndex,matrix[srcIndex][destIndex]);
System.out.println("选择的边:"+arrayV[srcIndex]+"->"+
arrayV[destIndex]+":"+matrix[srcIndex][destIndex]);
size++;//记录添加的边的条数
totalWight+= matrix[srcIndex][destIndex];//记录最小生成树的 权值
ufs.union(srcIndex,destIndex);
}
}
if(size == n-1) {
return totalWight;
}else {
return -1;//没有最小生成树
}
}
private void addEdgeUseIndex(int srcIndex,int destIndex,int weight) {
matrix[srcIndex][destIndex] = weight;
//如果是无向图 那么相反的位置 也同样需要置为空
if(!isDirect) {
matrix[destIndex][srcIndex] = weight;
}
}
import java.util.Arrays;
public class UnionFindSet {
public int[] elem;
public UnionFindSet(int n) {
this.elem = new int[n];
Arrays.fill(elem,-1);
}
/**
* 查找数据x 的根节点
* @param x
* @return 下标
*/
public int findRoot(int x) {
if(x < 0) {
throw new IndexOutOfBoundsException("下标不合法,是负数");
}
while (elem[x] >= 0 ) {
x = elem[x];//1 0
}
return x;
}
/**
* 查询x1 和 x2 是不是同一个集合
* @param x1
* @param x2
* @return
*/
public boolean isSameUnionFindSet(int x1,int x2) {
int index1 = findRoot(x1);
int index2 = findRoot(x2);
if(index1 == index2) {
return true;
}
return false;
}
/**
* 这是合并操作
* @param x1
* @param x2
*/
public void union(int x1,int x2) {
int index1 = findRoot(x1);
int index2 = findRoot(x2);
if(index1 == index2) {
return;
}
elem[index1] = elem[index1] + elem[index2];
elem[index2] = index1;
}
public int getCount() {
int count = 0;
for (int x : elem) {
if(x < 0) {
count++;
}
}
return count;
}
public void print() {
for (int x : elem) {
System.out.print(x+" ");
}
System.out.println();
}
//省份的数量
public int findCircleNum(int[][] isConnected) {
int n = isConnected.length;
UnionFindSet ufs = new UnionFindSet(n);
for(int i = 0;i < isConnected.length;i++) {
for(int j = 0;j < isConnected[i].length;j++) {
if(isConnected[i][j] == 1) {
ufs.union(i,j);
}
}
}
return ufs.getCount();
}
//等式的满足性
public boolean equationsPossible(String[] equations) {
UnionFindSet ufs = new UnionFindSet(26);
for(int i = 0; i < equations.length;i++) {
if(equations[i].charAt(1) == '=') {
ufs.union(equations[i].charAt(0)-'a',equations[i].charAt(3)-'a');
}
}
for(int i = 0; i < equations.length;i++) {
if(equations[i].charAt(1) == '!') {
int index1 = ufs.findRoot(equations[i].charAt(0)-'a');
int index2 = ufs.findRoot(equations[i].charAt(3)-'a');
if(index1 == index2) {
return false;
}
}
}
return true;
}
public static void main(String[] args) {
String[] str = {"a==b","b!=a"};
//equationsPossible(str);
}
//亲戚题
public static void main2(String[] args) {
int n = 10;
int m = 3;
int p = 2;
UnionFindSet unionFindSet = new UnionFindSet(n);
System.out.println("合并:0和6:");
unionFindSet.union(0,6);
unionFindSet.union(0,1);
System.out.println("合并:3和7:");
unionFindSet.union(3,7);
System.out.println("合并:4和8:");
unionFindSet.union(4,8);
System.out.println("以下是不是亲戚:");
boolean flg = unionFindSet.isSameUnionFindSet(1,8);
if(flg) {
System.out.println("是亲戚!");
}else {
System.out.println("不是亲戚!");
}
System.out.println("当亲的亲戚关系 "+unionFindSet.getCount()+" 对!");
}
public static void main1(String[] args) {
UnionFindSet unionFindSet = new UnionFindSet(10);
System.out.println("合并:0和6:");
unionFindSet.union(0,6);
System.out.println("合并:0和7:");
unionFindSet.union(0,7);
System.out.println("合并:0和8:");
unionFindSet.union(0,8);
System.out.println("合并:1和4:");
unionFindSet.union(1,4);
System.out.println("合并:1和9:");
unionFindSet.union(1,9);
System.out.println("合并:2和3:");
unionFindSet.union(2,3);
System.out.println("合并:2和5:");
unionFindSet.union(2,5);
unionFindSet.print();
System.out.println("合并:8和1:");
unionFindSet.union(8,1);
unionFindSet.print();
System.out.println("查找是不是同一个集合");
System.out.println(unionFindSet.isSameUnionFindSet(6, 9));
System.out.println(unionFindSet.isSameUnionFindSet(8, 2));
}
}
3-2、Prim算法
Prim算法是一种用于寻找图的最小生成树(MST)的算法。以下是Prim算法的详细步骤:
- 选择起始顶点:从图中任意选择一个顶点作为起始点,并将其加入到最小生成树的集合中。
- 初始化:创建一个优先队列(最小堆),用于存储所有从已选择顶点到未选择顶点的边,以及这些边的权重。
- 循环:在图中还有未选择的顶点时,重复以下步骤:
- 从优先队列中取出权重最小的边。这条边连接一个已选择的顶点和一个未选择的顶点。
- 将这条边添加到最小生成树中,并将对应的未选择顶点加入到已选择顶点集合中。
- 更新优先队列:将所有从新加入的顶点出发的边加入到优先队列中,如果这些边的另一端顶点还未被选择。
- 结束条件:当所有顶点都被包含在最小生成树中,或者优先队列变空时,算法结束。
Prim算法的时间复杂度主要取决于优先队列的操作。如果使用普通的优先队列,算法的时间复杂度为O(E log V),其中E是边的数量,V是顶点的数量。如果使用斐波那契堆作为优先队列,算法的时间复杂度可以降低到O(E + V log V)。
Prim算法适用于顶点稠密的图,因为它每次都是选择连接到已选择顶点集合的最小边,而不是像Kruskal算法那样选择全局最小的边。这使得Prim算法在顶点数量远大于边的数量时效率更高。
public int prim(GraphByMatrix minTree,char chV) {
int srcIndex = getIndexOfV(chV);
//存储已经确定的点
Set<Integer> setX = new HashSet<>();
//先把确定的顶点放到集合当中
setX.add(srcIndex);
//初始化Y集合 ,存储的是 未确定的顶点
Set<Integer> setY = new HashSet<>();
int n = arrayV.length;
for (int i = 0; i < n; i++) {
if(i != srcIndex) {
setY.add(i);
}
}
//定义一个优先级队列
PriorityQueue<Edge> minQ = new PriorityQueue<>(new Comparator<Edge>() {
@Override
public int compare(Edge o1, Edge o2) {
return o1.weight - o2.weight;
}
});
//遍历srcIndex连接出去的所边
for (int i = 0; i < n; i++) {
if(matrix[srcIndex][i] != Constant.MAX) {
minQ.offer(new Edge(srcIndex,i,matrix[srcIndex][i]));
}
}
int size = 0;
int totalWeight = 0;
//遍历优先级队列,取出n-1条边
while (!minQ.isEmpty()) {
Edge min = minQ.poll();
int srcI = min.srcIndex;
int desT = min.destIndex;
if(setX.contains(desT)) {
//构成环
System.out.println("构成环的边:"+arrayV[srcI]+"->"+
arrayV[desT]+":"+matrix[srcI][desT]);
}else {
minTree.addEdgeUseIndex(srcI,desT,min.weight);
System.out.println("选择的边:"+arrayV[srcI]+"->"+
arrayV[desT]+":"+matrix[srcI][desT]);
totalWeight += min.weight;
size++;
if(size == n-1) {
return totalWeight;
}
//更新两个集合的
setX.add(desT);
setY.remove(desT);
//把destI连接出去的所有边,也放到优先级队列当中
for (int i = 0; i < n; i++) {
if(matrix[desT][i] != Constant.MAX && !setX.contains(i)) {
minQ.offer(new Edge(desT,i,matrix[desT][i]));
}
}
}
}
return -1;
}
从某一个点开始,局部选择权值最小的不成环的路径,局部选择是指与已选顶点相连的那些边。
两个问题:
如何选怎局部最小边:每加入一个顶点,就将与该顶点相连的边为选怎的边加入到优先级队列中
如何判断环路:并查集。
4、最短路径
最短路径问题:从在带权图的某一顶点出发,找出一条通往另一顶点的最短路径,最短也就是沿路径各边的权值总 和达到最小。
4-1、 单源最短路径–Dijkstra算法
单源最短路径问题:给定一个图G = ( V , E ) G=(V,E)G=(V,E),求源结点s ∈ V s∈Vs∈V到图中每个结点v ∈ V v∈Vv∈V的最短路径。Dijkstra算法就适用于解决带权重的有向图上的单源最短路径问题,同时算法要 求图中所有边的权重非负。一般在求解最短路径的时候都是已知一个起点和一个终点,所以使用Dijkstra算法 求解过后也就得到了所需起点到终点的最短路径。 针对一个带权有向图G,将所有结点分为两组S和Q,S是已经确定最短路径的结点集合,在初始时为空(初始 时就可以将源节点s放入,毕竟源节点到自己的代价是0),Q 为其余未确定最短路径的结点集合,每次从Q 中找出一个起点到该结点代价最小的结点u ,将u 从Q 中移出,并放入S 中,对u 的每一个相邻结点v 进行松 弛操作。松弛即对每一个相邻结点v ,判断源节点s到结点u 的代价与u 到v 的代价之和是否比原来s 到v 的代 价更小,若代价比原来小则要将s 到v 的代价更新为s 到u 与u 到v 的代价之和,否则维持原样。如此一直循 环直至集合Q 为空,即所有节点都已经查找过一遍并确定了最短路径,至于一些起点到达不了的结点在算法 循环后其代价仍为初始设定的值,不发生变化。Dijkstra算法每次都是选择V-S中最小的路径节点来进行更 新,并加入S中,所以该算法使用的是贪心策略。** Dijkstra算法存在的问题是不支持图中带负权路径,如果带有负权路径,则可能会找不到一些路径的最短路径。 **

第一步初始化,第二步遍历s的出度跟新了到达y、t的最短距离,在第三步中可以选择遍历y的出度,也可以选择遍历t的出度,Dijkstra算法是选择先遍历小的哪一个也就是y顶点。
算法中添加了cheak数组第三步中y顶点已经被遍历过来标记cheak[y]=true;当遍历t的时候就不会在从t走向y了,因为权值都是正数,而刚才在选择先遍历谁的时候就已经说明从s到y比s到t近、说明s经过t在到达y的距离只会更远,所以当cheak[y]被标记后说明s到y的最短路径已经找到了,后续经过别的顶点也可到y顶点的路径不可能会更小了。
public void dijkstra(char vSrc,int[] dist,int[] pPath) {
int srcIndex = getIndexOfV(vSrc);
//距离数据初始化
Arrays.fill(dist,Constant.MAX);
dist[srcIndex] = 0;
//路径数组初始化
Arrays.fill(pPath,-1);
pPath[srcIndex] = 0;
//当前顶点是否被访问过?
int n = arrayV.length;
boolean[] s = new boolean[n];
//n个顶点,要更新n次,每次都要从0下标开始,找到一个最小值
for (int k = 0; k < n; k++) {
int min = Constant.MAX;
int u = srcIndex;
for (int i = 0; i < n; i++) {
if(s[i] == false && dist[i] < min) {
min = dist[i];
u = i;//更新u下标
}
}
s[u] = true;//u:s
//松弛u连接出去的所有的顶点 v
for (int v = 0; v < n; v++) {
if(s[v] == false && matrix[u][v] != Constant.MAX
&& dist[u] + matrix[u][v] < dist[v]) {
dist[v] = dist[u] + matrix[u][v];
pPath[v] = u;//更新当前的路径
}
}
}
}
public void printShortPath(char vSrc,int[] dist,int[] pPath) {
int srcIndex = getIndexOfV(vSrc);
int n = arrayV.length;
for (int i = 0; i < n; i++) {
//i下标正好是起点 则不进行路径的打印
if(i != srcIndex) {
ArrayList<Integer> path = new ArrayList<>();
int pathI = i;
while (pathI != srcIndex) {
path.add(pathI);
pathI = pPath[pathI];
}
path.add(srcIndex);
Collections.reverse(path);
for (int pos : path) {
System.out.print(arrayV[pos]+" -> ");
}
System.out.println(dist[i]);
}
}
}
4-2、 单源最短路径–Bellman-Ford算法
Dijkstra算法只能用来解决正权图的单源最短路径问题,但有些题目会出现负权图。这时这个算法就不能帮助 我们解决问题了,而bellman—ford算法可以解决负权图的单源最短路径问题。它的优点是可以解决有负权 边的单源最短路径问题,而且可以用来判断是否有负权回路。它也有明显的缺点,它的时间复杂度 O(N*E) (N是点数,E是边数)普遍是要高于Dijkstra算法O(N²)的。像这里如果我们使用邻接矩阵实现,那么遍历所有 边的数量的时间复杂度就是O(N^3),这里也可以看出来Bellman-Ford就是一种暴力求解更新。 
该算法计算谋起点到其他顶点的最短距离,如果有负权回路,一直转圈路径和一直减小,这种情况则返回false。如果没有负权回路,返回ture,可以找到每个顶点的最短路径。
如何判断是否有负权回路:在执行一次循环体即可,若有负权回路存在,每次指向循环体相当于围着负权回路绕了一圈,就会有顶点的最短路径更新,此时直接判定为有负权回路存在,返回false,如果循环体执行后没有顶点的最短路径更新,说明从起点到所有顶点的最短路径都已经找了,该图没有负权回路,返回true。
、public boolean bellmanFord(char vSrc,int[] dist,int[] pPath) {
int srcIndex = getIndexOfV(vSrc);
//距离数据初始化
Arrays.fill(dist,Constant.MAX);
dist[srcIndex] = 0;
//路径数组初始化
Arrays.fill(pPath,-1);
pPath[srcIndex] = 0;
int n = arrayV.length;
for (int k = 0; k < n; k++) {
// i,j循环是在遍历说有的边,可以改成双重循环
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
if(matrix[i][j] != Constant.MAX &&
dist[i]!=Constant.MAX &&
dist[i] + matrix[i][j] < dist[j]) {
dist[j] = dist[i] + matrix[i][j];
pPath[j] = i;
}
}
}
}
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
if(matrix[i][j] != Constant.MAX &&
dist[i] + matrix[i][j] < dist[j]) {
return false;
}
}
}
return true;
}
public class BellmanFord {
// 用于表示图中的边
static class Edge {
int source, dest, weight;
Edge(int source, int dest, int weight) {
this.source = source;
this.dest = dest;
this.weight = weight;
}
}
// 执行Bellman-Ford算法
static boolean bellmanFord(int V, Edge[] edges, int source) {
// 从源点到所有顶点的距离初始化为无穷大,除了源点自身
int[] distance = new int[V];
for (int i = 0; i < V; i++) {
distance[i] = Integer.MAX_VALUE;
}
distance[source] = 0;
// 遍历所有边V-1次
for (int i = 1; i < V; i++) {
for (Edge edge : edges) {
if (distance[edge.source] != Integer.MAX_VALUE &&
distance[edge.source] + edge.weight < distance[edge.dest]) {
distance[edge.dest] = distance[edge.source] + edge.weight;
}
}
}
// 检查是否存在负权重环
for (Edge edge : edges) {
if (distance[edge.source] != Integer.MAX_VALUE &&
distance[edge.source] + edge.weight < distance[edge.dest]) {
return false; // 如果可以进一步更新距离,说明存在负权重环
}
}
return true; // 图中不存在负权重环
}
// 主函数,用于测试Bellman-Ford算法
public static void main(String[] args) {
int V = 5; // 顶点的数量
Edge[] edges = new Edge[] {
new Edge(0, 1, -1), new Edge(0, 2, 4),
new Edge(1, 2, 3), new Edge(1, 3, 2),
new Edge(1, 4, 2), new Edge(3, 1, 1),
new Edge(4, 0, 6), new Edge(4, 3, -3)
};
boolean hasNegativeCycle = bellmanFord(V, edges, 0);
if (hasNegativeCycle) {
System.out.println("Graph contains a negative weight cycle");
} else {
System.out.println("Vertex \t Distance from Source");
for (int i = 0; i < V; i++) {
System.out.println(i + " \t\t " + (Integer.MAX_VALUE == edges[0].distance[i] ? "INF" : edges[0].distance[i]));
}
}
}
}
4-3、 多源最短路径–Floyd-Warshall算法
Floyd-Warshall算法是解决任意两点间的最短路径的一种算法()。 Floyd算法考虑的是一条最短路径的中间节点,即简单路径p={v1,v2,…,vn}上除v1和vn的任意节点。 设k是p 的一个中间节点,那么从i到j的最短路径p就被分成i到k和k到j的两段最短路径p1,p2。p1是从i到k且中间节 点属于{1,2,…,k-1}取得的一条最短路径。p2是从k到j且中间节点属于{1,2,…,k-1}取得的一条最短路径。

填表顺序不重要!填表不漏即可。

public void floydWarShall(int[][] dist,int[][] pPath) {
int n = arrayV.length;
for (int i = 0; i < n; i++) {
Arrays.fill(dist[i],Constant.MAX);
Arrays.fill(pPath[i],-1);
}
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
if(matrix[i][j] != Constant.MAX) {
dist[i][j] = matrix[i][j];
pPath[i][j] = i;
}else {
pPath[i][j] = -1;
}
if(i == j) {
dist[i][j] = 0;
pPath[i][j] = -1;
}
}
}
for (int k = 0; k < n; k++) {
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
if(dist[i][k] != Constant.MAX &&
dist[k][j] != Constant.MAX &&
dist[i][k] + dist[k][j] < dist[i][j]) {
dist[i][j] = dist[i][k] + dist[k][j];
//更新父节点下标
//pPath[i][j] = k;//不对
//如果经过了 i->k k->j 此时是k
//i->x->s->k k->..t->...x->j
pPath[i][j] = pPath[k][j];
}
}
}
// 测试 打印权值和路径矩阵观察数据
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
if(dist[i][j] == Constant.MAX) {
System.out.print(" * ");
}else{
System.out.print(dist[i][j]+" ");
}
}
System.out.println();
}
System.out.println("=========打印路径==========");
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
System.out.print(pPath[i][j]+" ");
}
System.out.println();
}
System.out.println("=================");
}
}
九、小技巧
有些函数的实现需要设计全局变量,但是全局变量用了一次就会被改变,影响下一次使用。加一层驱动函数重新初始化全局变量即可。或者将全局变量设置为被调函数的参数,驱动函数对参数进行初始化然后给对调函数传参。
class TreeNode {
int val;
TreeNode left;
TreeNode right;
TreeNode(int x) {
val = x;
}
}
public class Solution {
public boolean isValidBST(TreeNode root) {
return isValidBSTHelper(root, Long.MIN_VALUE, Long.MAX_VALUE);
}
private boolean isValidBSTHelper(TreeNode node, long min, long max) {
if (node == null) {
return true;
}
if (node.val <= min || node.val >= max) {
return false;
}
return isValidBSTHelper(node.left, min, node.val) &&
isValidBSTHelper(node.right, node.val, max);
}
public static void main(String[] args) {
TreeNode root = new TreeNode(2);
TreeNode left = new TreeNode(1);
TreeNode right = new TreeNode(3);
root.left = left;
root.right = right;
Solution solution = new Solution();
System.out.println(solution.isValidBST(root)); // true
System.out.println(solution.isValidBST(root)); // true
}
}
十、链接整理
红黑树(博客园)
红黑树(CSDN)
BitSet的实现原理(CSDN)
布隆过滤器(博客园)
一致性哈希(OSCHINA)
哈希加密(代码改变世界)
省份数量(力扣)
等式方程的可满足性(力扣)
LRU缓存(力扣)
MySQL常见面试题(知乎)
B树、B-树、B+树、B*树
MySQL索引背后的数据结构及算法原理
Floyd-傻子也能看懂的弗洛伊德算法















 41万+
41万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









