







- 问题来源
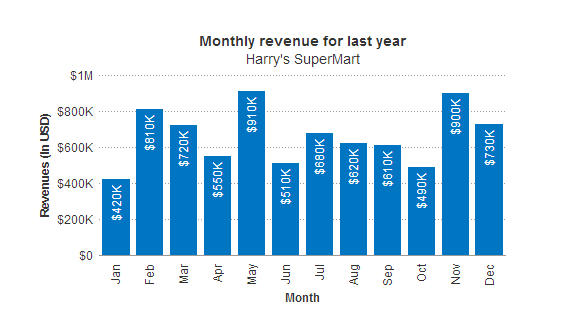
需求:根据年度将相应年度的每个月的投诉数进行统计,并以图表的形式展示在页面中;在页面中可以选择查看当前年度及其前4年的投诉数。在页面中可以选择不同的年度,然后页面展示该年度的曲线统计图
图片实例(非最终结果)
- 目标
统计年度的每个月的投诉数
Action:
①获取ajax传回后台的年份year
②统计年度的每个月的投诉数并输出json格式字符串 - 表结构分析
投诉表complain及对应的实体类

public class Complain implements java.io.Serializable {
// Fields
private String compId;
private String compCompany;//投诉人单位
private String compName;//投诉人姓名
private String compMobile;//投诉人手机
private Boolean isNm;//匿名投诉
private Timestamp compTime;//投诉时间
private String compTitle;//投诉标题
private String toCompName;//被投诉人
......//因为本文主要讲解左连接查询,在此不一一列举实例类
4. 统计语句
根据需求,我们首先会想到如下的统计相应年度各个月的
select 月份,投诉数
from 投诉
where 年度=传入值
group by 月份-—–实际月份的投诉数统计结果———–
select month(comp_time) as '月份',count(*) '总数'
from complain
where year(comp_time)=2016
group by month(comp_time)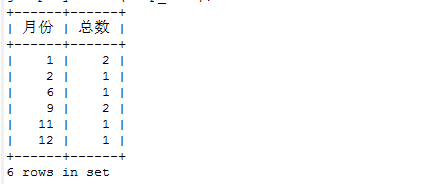
但是结果并不是我们想要得到的,投诉数为0的月份不显示
要保证投诉数为0的月份也要显示,在此想到用到左连接:
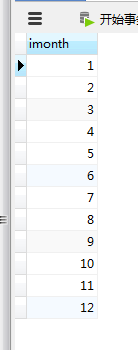
①创建新表tmonth–用来tag 1-12个月份
②sql语句创建
select imonth, count(comp_id)
from tmonth left join complain on imonth=month(comp_time)
and year(comp_time)=2016
group by imonth
order by imonth;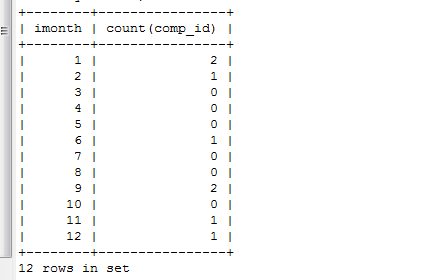
5. 查询优化(*)
尽管上面的数据已经是我们想要的,但是由此联想到数据量的增长,比如百万级以上的数据
假设complain表中存在百万级以上的数据,根据上面的sql查询
select imonth, count(comp_id)
from tmonth left join complain on imonth=month(comp_time)一定会得到百万级以上的数据,然后对这个百万级数据数进行分组,而不是根据12个月进行分组,从而导致网站性能上面会差很多;
解决办法:
既然提到根据12个月进行分组,优化后的sql语句 则是
select imonth,c2
from tmonth left join (select month(comp_time) c1, count(comp_id) c2 from complain where year(comp_time)=2016 group by month(comp_time)) t
on imonth = c1
order by imonth;结果:
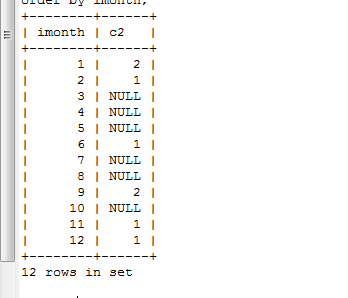
(至于出现null,则只需要在进行代码设计上进行判断即可)
















 668
668

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











