










1、堆的定义
堆分为大顶堆和小顶堆
大(小)顶堆定义:取任意一个有儿子的节点,它的值比其左右儿子的值都大(小),满足这样条件的完全二叉树为堆。
注:以下都以大顶堆为例来说堆排序,小顶堆同理。
2、堆排序的思想
堆排序很充分的运用完全二叉树的特性:
- 随便一组数据就是一颗完全二叉树(因为不需要考虑为空节点的情况);
- 如果按照层次遍历一棵树,规定根节点下标为1,那么在这颗树中 已知一个节点的下标为n,其左孩子为的下标一定为2n,右孩子的下标一定为2n+1;
堆排序分为两步:
- 构建一个大(小)顶堆;
- 通过交换堆尾部元素与堆顶元素,每次循环输出堆顶元素即可;
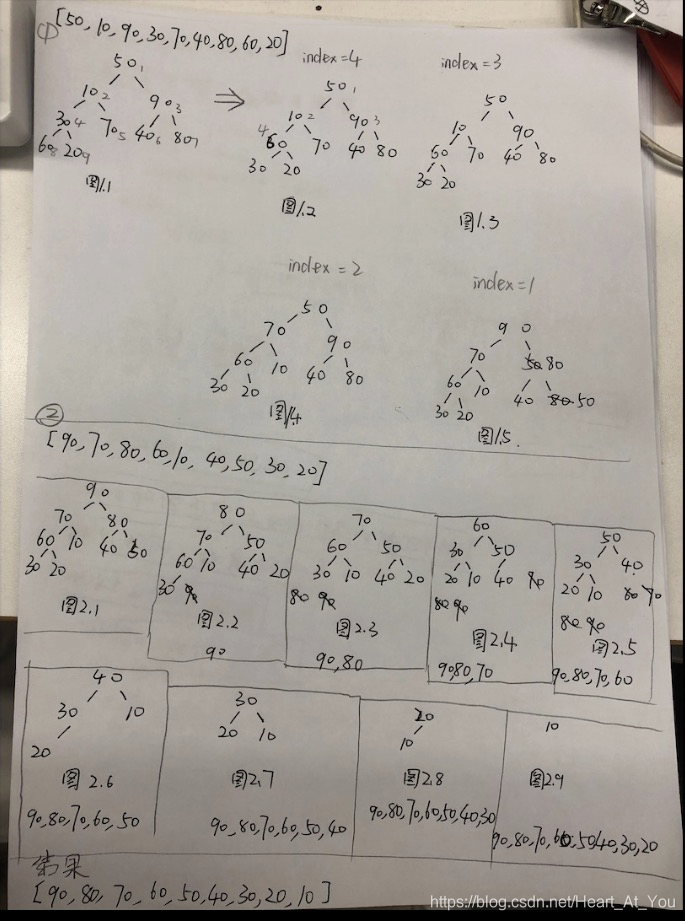
举例说明给定一组数据如何进行堆排序
[50,10,90,30,70,40,80,60,20]:
- 图中步骤1为构建一个大顶堆过程,图中步骤2为交换堆尾部元素与堆顶元素,依次输出结果,树中浅色笔标注的为数组下标,深色笔标注的为节点值;
- 步骤1:找到这颗完全二叉树中所有 有儿子的节点 ,比较其与儿子节点的大小关系,如果比儿子节点小,与儿子节点中较大的一个交换;反之,保持不动;
- 步骤2:,每轮循环,通过 将堆尾元素与堆顶元素交换位置 的方式输出堆顶元素,交换的同时破坏了堆结构,再调整二叉树为堆结构 ;
3、堆排序代码
如果第2部分的内容你已经详读,并且亲自计算过,那么不难发现,堆排序可以分成三个模块函数:
主流程控制函数heapSort、交换元素swap、堆的调整函数heapAdjust
具体代码如下:
function heapSort(arr) {
let i
// 先构建一个堆
for (i = (Math.floor(arr.length / 2) - 1); i>=0; i--) {
heapAdjust(arr, i, arr.length)
}
console.log('堆的构建', arr)
// 按顺序输出节点
for (i = (arr.length - 1); i>=0; i--) {
swap(arr, 0, i)
heapAdjust(arr, 0, i-1)
}
}
function swap(arr, indexFirst, indexNext){
let temp = arr[indexFirst]
arr[indexFirst] = arr[indexNext]
arr[indexNext] = temp
}
function heapAdjust(arr, start, max) {
let j, temp = arr[start]
// 找到当前start下标元素的孩子节点,调整父子两代之间的大小关系
for (j = 2*start; j<=max; j*=2) {
// debugger
// 找到孩子中较大的一个,再去和父亲比较大小
if (j < max && arr[j] < arr[j+1]) {
++j
}
// 如果父亲已经是最大的,不动
if (temp >= arr[j]) {
break
}
// 交换父亲和较大孩子节点
swap(arr, start, j)
start = j
}
arr[start] = temp
}
var arr = [50, 10, 90, 30,70, 40, 80, 60, 20]
heapSort(arr)
console.log(arr)
4、堆排序的复杂度分析
堆排序相对于 冒泡、选择排序、插入排序 这些复杂度为O(n^2)的来讲,其复杂度为O(nlogn)
5、为什么不使用平衡二叉树来进行排序
平衡二叉树在构建方面是相比堆来讲是 严格的、消耗空间的,平衡二叉树是对一组可能随时会有插入和删除操作的数据保持其大小顺序的一种数据结构;
如果用平衡二叉树来对一组固定数组来进行排序,其复杂度还不如冒泡、插入和选择排序;














 2005
2005











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









