







基于python的nlp预备知识
载入语料库
import nltk
nltk.download('stopwords')
nltk.download('punkt')
nltk.download('brown')
brown 语料库的导入
# corpus是一个语料库,brown是brown大学制作的语料库,关于标题的分类
from nltk.corpus import brown
brown.categories()
len(brown.sents()) # 多少条句子
len(brown.words()) # 多少个词
分词
nltk的word_tokenize
import nltk
sentence = 'hello, world'
tokens = nltk.word_tokenize(sentence) # 调用库nltk的word_tokenize进行分词
tokens
[‘hello’, ‘,’, ‘world’]
Stem抽取题干和Lemma 词形还原
NLTK实现Stemming三种方式
# 从输出可以看出,lancaster词干提取器最为严格,
# 他的速度很快,但是会减少单词的很大部分,会让词干模糊难于理解
print('第1种方式'+'*'*100)
# 1
from nltk.stem.porter import PorterStemmer
porter_stemmer = PorterStemmer()
porter_stemmer.stem('maximum') # 'maximum'
porter_stemmer.stem('presumably') # 'presum'
porter_stemmer.stem('multiply') # 'multipli'
porter_stemmer.stem('working') # work
print('第2种方式'+'*'*100)
# 2
from nltk.stem.lancaster import LancasterStemmer
lancaster_stemmer = LancasterStemmer()
lancaster_stemmer.stem('maximum') # 'maxim'
lancaster_stemmer.stem('presumably') # 'presum'
lancaster_stemmer.stem('multiply') # 'multiply'
porter_stemmer.stem('working') # work
print('第3种方式'+'*'*100)
# 3
from nltk.stem import SnowballStemmer
snowball_stemmer = SnowballStemmer('english')
snowball_stemmer.stem('maximum') # 'maximum'
snowball_stemmer.stem('presumably') # 'presum'
snowball_stemmer.stem('multiply') # 'multipli'
porter_stemmer.stem('working') # work
NLTK实现Lemma 词形还原
# NLTK实现Lemma 词形还原
>>> from nltk.stem import WordNetLemmatizer
>>> wordnet_lemmatizer = WordNetLemmatizer()
>>> wordnet_lemmatizer.lemmatize('dogs') # 'dog'
>>> wordnet_lemmatizer.lemmatize('churches') # 'church'
>>> wordnet_lemmatizer.lemmatize('aardwolves') # 'aardwolf'
>>> wordnet_lemmatizer.lemmatize('abaci') # 'abacus'
>>> wordnet_lemmatizer.lemmatize('working') # working属于stemming,词干抽取,所以没用
>>> wordnet_lemmatizer.lemmatize('are') # are
>>> wordnet_lemmatizer.lemmatize('are',pos = 'v') # be
停止词
from nltk.corpus import stopwords
sentence = 'food is my family'
word_list = nltk.word_tokenize(sentence) # 分词
filtered_words = [word for word in word_list if word not in stopwords.words('english')]
filtered_words
[‘food’, ‘is’, ‘my’, ‘family’]
[‘food’, ‘family’]
停止词网站
关键词打分
dict.get(key, default=None)
key – 字典中要查找的键。
default – 如果指定键的值不存在时,返回该默认值值。
返回指定键的值,如果值不在字典中返回默认值None。
# 情感分析打分
sentiment_dictionary = {} # {'abandon': -2, 'abandoned': -2,'abandons': -2...}
for line in open("data/AFINN-111.txt"): # 一行一行读 第一行 abandon -2
word, score = line.split('\t') # 按照tab键分开两词
sentiment_dictionary[word] = int(score) # 字典格式放入
# 把这个打分表记录在一个Dict上以后
# 跑一遍整个句子,把对应的值相加
sentence = 'like love'
words = nltk.word_tokenize(sentence)
total_score = sum(sentiment_dictionary.get(word, 0) for word in words) # 方法不错
# 有值就是Dict中的值,没有就是0
total_score
情感分析
# 情感分析
from nltk.classify import NaiveBayesClassifier # 朴素贝叶斯
# 随手造点训练集
s1 = 'this is a good book'
s2 = 'this is a awesome book'
s3 = 'this is a bad book'
s4 = 'this is a terrible book'
def preprocess(s):
return {word: True for word in s.lower().split()} # 巧妙的表达方式
# {'this': True, 'is':True, 'a':True, 'good':True, 'book':True}
# 当然啦, 我们以后可以升级这个方程, 比如 word2vec
# 把训练集给做成标准形式
training_data = [[preprocess(s1), 'pos'],
[preprocess(s2), 'pos'],
[preprocess(s3), 'neg'],
[preprocess(s4), 'neg']]
# 喂给model吃
model = NaiveBayesClassifier.train(training_data)
# 打出结果
print(training_data)
print(model.classify(preprocess('this is a bad book'))) # neg
[[{‘this’: True, ‘is’: True, ‘a’: True, ‘good’: True, ‘book’: True}, ‘pos’], [{‘this’: True, ‘is’: True, ‘a’: True, ‘awesome’: True, ‘book’: True}, ‘pos’], [{‘this’: True, ‘is’: True, ‘a’: True, ‘bad’: True, ‘book’: True}, ‘neg’], [{‘this’: True, ‘is’: True, ‘a’: True, ‘terrible’: True, ‘book’: True}, ‘neg’]]
文本相似度
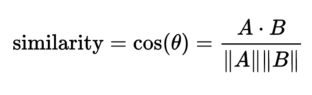
用Frequency 频率统计计算文本相似度
"""
功能:用元素频次表示文本特征,计算文本相似度
缺点:用频次计算,丢失位置特征
"""
import nltk
from nltk import FreqDist
import numpy as np
import pandas as pd
########### 制作词库,返回词库中所有单词的频次 #################
# 做个词库先
corpus = 'this is my sentence ' \
'this is my life ' \
'this is the day'
# corpus # 'this is my sentence this is my life this is the day'
# 随便tokenize一下,这里可以根据需要做任何的preprocessing:stopwords, lemma, stemming, etc.
tokens = nltk.word_tokenize(corpus)
# NLTK的FreqDist统计一下文字出现的频率
fdist = FreqDist(tokens)
# fdist类似于一个Dict
# FreqDist({'this': 3, 'is': 3, 'my': 2, 'sentence': 1, 'life': 1, 'the': 1, 'day': 1})
# 带上某个单词, 可以看到它在整个文章中出现的次数
# print(fdist['is']) # 3
# 好, 此刻, 我们可以把最常用的50个单词拿出来
standard_freq_vector = fdist.most_common(50) # 返回频次前50的列表,单词和频次呈元祖格式
# [('this', 3), ('is', 3), ('my', 2), ('sentence', 1), ('life', 1), ('the', 1), ('day', 1)]
size = len(standard_freq_vector) # 7, 词库有7个
def position_lookup(v):
"""
:param v: 列表,里面是元祖格式的单词和他对应的频次
[('this', 3), ('is', 3), ('my', 2), ('sentence', 1), ('life', 1), ('the', 1), ('day', 1)]
:return: loc: v中所有单词和对应的位置
fre: v中所有单词的频次
"""
loc = {}
fre = []
counter = 0
for word in v: # word遍历v ('this', 3)
loc[word[0]] = counter
fre.append(word[1])
counter += 1
return loc, fre
# 把标准的单词位置记录下来
loc, fre = position_lookup(standard_freq_vector)
# loc: {'this': 0, 'is': 1, 'my': 2, 'sentence': 3, 'life': 4, 'the': 5, 'day': 6}
# fre: [3, 3, 2, 1, 1, 1, 1]
# 将词对应的位置和频次,输出pd格式
standard_vector = [key for key, value in loc.items()]
df = pd.DataFrame({'词库': np.array(standard_vector), '词库频次': fre})
print(df)
################## 三个sentence,从词库中找sentence所有单词出现的频次 ########################
# 如果我们有个新句句⼦子:
sentence1 = 'this is my life '
sentence2 = 'this is my sentence '
sentence3 = 'life my is this'
sentence = [sentence1, sentence2, sentence3]
def vec(sen_tok, loc):
# 先新建一个跟我们的标准vector同样⼤大⼩小的向量量
freq_vector = [0] * size
for word in sen_tok:
try:
# 如果在我们的词库⾥里里出现过,在"标准位置"上+1
freq_vector[loc[word]] += 1
except KeyError:
# 如果是个新词,就pass掉
continue
# print(freq_vector)
return freq_vector
tokens = [nltk.word_tokenize(i) for i in sentence] # 将三个句子分词
# [['this', 'is', 'my', 'life'], ['this', 'is', 'my', 'sentence'], ['life', 'my', 'is', 'this']]
sent_fre = [vec(i, loc) for i in tokens] # 分别计算三个句子中单词在词库中出现的频次,如果是新词pass,所以要求词库要全面
# [[1, 1, 1, 0, 1, 0, 0], [1, 1, 1, 1, 0, 0, 0], [1, 1, 1, 0, 1, 0, 0]]
# pd格式
df['sen1_频次'] = sent_fre[0]
df['sen2_频次'] = sent_fre[1]
df['sen3_频次'] = sent_fre[2]
print(df)
############### 按照频次,依据余弦定理计算sen1与sen2,sen1与sen3的相似度 ####################
# 余弦值越大,证明夹角越小,两个向量越相似
# 分母计算模时,刚好是2范数,
# 引入np.linalg.norm(表达式,ord = 2)
sen1_sen2_simi = (np.sum(df['sen1_频次']*df['sen2_频次']))\
/(np.linalg.norm(df['sen1_频次'], ord=2) * np.linalg.norm(df['sen2_频次'], ord=2))
sen1_sen3_simi = (np.sum(df['sen1_频次']*df['sen3_频次']))\
/(np.linalg.norm(df['sen1_频次'], ord=2) * np.linalg.norm(df['sen3_频次'], ord=2))
print('sen1与sen2的相似度', sen1_sen2_simi)
print('sen1与sen3的相似度', sen1_sen3_simi)
# 可以看出虽然sen1与sen3风马牛不相及,但相似度达到最大,只因为是按照频次计算相似度。

TF-IDF

# NLTK实现TF-IDF
# 文档数:3个
import nltk
from nltk.text import TextCollection
# 三个文档总数
sents = ['this is sentence one', 'this is sentence two', 'this is sentence three']
# 分词
sents = [nltk.word_tokenize(sent) for sent in sents]
# 放入 TextCollection
corpus = TextCollection(sents)
# 计算idf,验证公式
corpus.idf('this') # np.log(3/3)=log(一共3个文档/出现this的文档数为3)=0
corpus.idf('three') # np.log(3/1)= 1.0986122886681098
# 计算tf,idf
corpus.tf('three', nltk.word_tokenize('one two three, go')) # 1/5
corpus.tf_idf('three', nltk.word_tokenize('one two three, go')) # 1/5 * 1.0986122886681098=0.21972245773362198
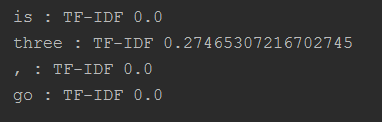
# 对于每个新句⼦
new_sentence = 'is three, go'
# 遍历一遍所有的new_sentence中的词:
for word in nltk.word_tokenize(new_sentence):
print(word, ':', 'TF-IDF', corpus.tf_idf(word, nltk.word_tokenize(new_sentence)))
# is因为在三个文档都有,所以它在新句子的重要性为0














 532
532











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









