









GroupingComparator
在hadoop的mapreduce编程模型中,当在map端处理完成输出key-value对时,reduce端只会将key相同的到同一个reduce函数中去执行。但是,当使用java对象为key时,如何判断Java对象是同一个key呢,这时候就需要GroupingComparator,利用该类中的compare方法,根据自己的需求,设定key相同的条件,从而放入同一个reduce方法中处理。
GroupingComparator分组(辅助排序)
对Reduce阶段的数据根据某一个或几个字段进行分组。
分组排序步骤:
(1)自定义类继承WritableComparator
(2)重写compare()方法,根据自己的需求,设置比较业务,返回0,则表示两个对象是设置为相同的key
ublic class GroupComparator extends WritableComparator{
WritableComparator:
public GroupComparator() {
//以使用hadoop中的GroupingComparator对其进行分组,先要定义一个类继承
super(TextPair.class,true);
}
@Override
public int compare(WritableComparable a, WritableComparable b) {
//根据自己的需求,设置比较业务,返回0,则表示两个对象是设置为相同的key
TextPair t1 = (TextPair) a;
TextPair t2 = (TextPair) b;
return t1.getFirst().compareTo(t2.getFirst());
}
}
分组排序案例
数据
order001,u001,小米6,1999.9,2
order001,u001,雀巢咖啡,99.0,2
order001,u001,安慕希,250.0,2
order001,u001,经典红双喜,200.0,4
order001,u001,防水电脑包,400.0,2
order002,u002,小米手环,199.0,3
order002,u002,榴莲,15.0,10
order002,u002,苹果,4.5,20
order002,u002,肥皂,10.0,40
需求:
需要求出每一个订单中成交金额最大的三笔
本质:求分组TOPN
实现思路:
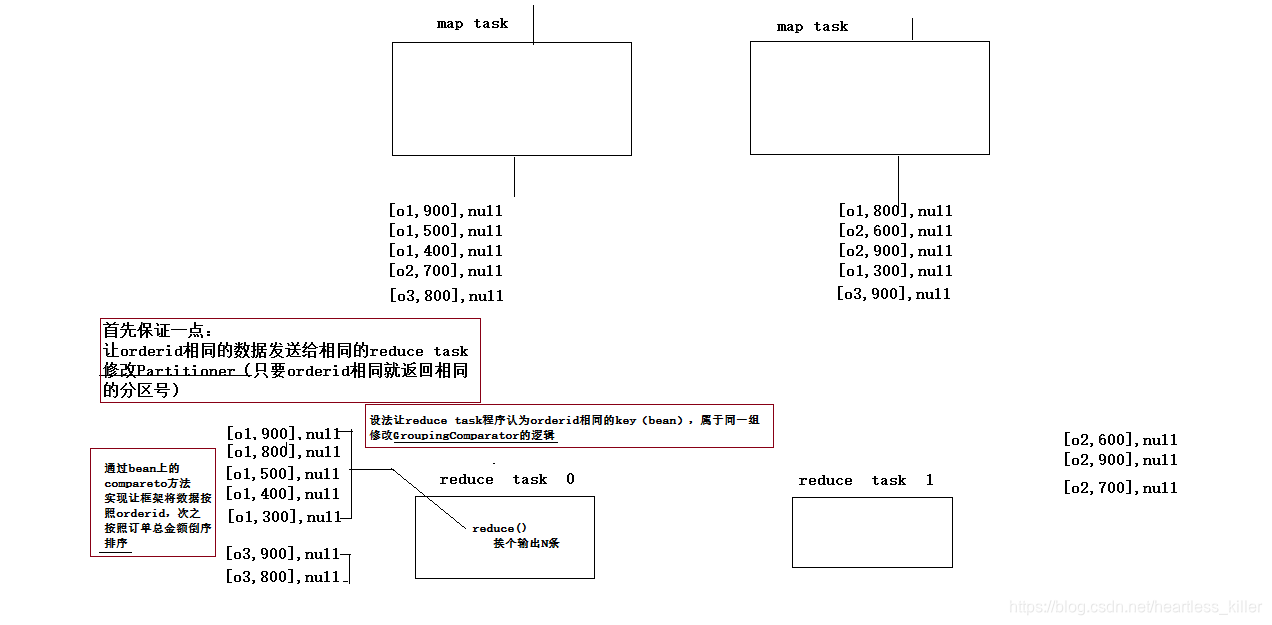
1.设置一个java对象来存订单数据,设置为OrderBean,然后为其实现可序列化接口和比较器接口,所以实现 WritableComparable<>接口,然后数据的比较规则是:先比总金额,如果相同,再比商品名称。
2重写数据分发规则Partitioner,根据OrderId进行分发。
3map: 读取数据切分字段,封装数据到一个bean中作为key传输,key要按照成交金额比大小
4reduce:在reduce方法中输出每组数据的前N条即可,但是如果要实现该需求,要求OrderId相同的要被看作一个key,到同一个reduce函数中去执行,如果要实现该需求,则需要GroupingComparator重写判断key相同的规则。
5自定义GroupingComparator,订单id相同的看作一个key。
图
代码展示:
设置OrderBean
设置一个java对象来存订单数据,设置为OrderBean,然后为其实现可序列化接口和比较器接口,所以实现 WritableComparable<>接口,然后数据的比较规则是:先比总金额,如果相同,再比商品名称。
package cn.edu360.mr.order.topn.grouping;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.io.Serializable;
import org.apache.hadoop.io.WritableComparable;
public class OrderBean implements WritableComparable<OrderBean>{
private String orderId;
private String userId;
private String pdtName;
private float price;
private int number;
private float amountFee;
public void set(String orderId, String userId, String pdtName, float price, int number) {
this.orderId = orderId;
this.userId = userId;
this.pdtName = pdtName;
this.price = price;
this.number = number;
this.amountFee = price * number;
}
public String getOrderId() {
return orderId;
}
public void setOrderId(String orderId) {
this.orderId = orderId;
}
public String getUserId() {
return userId;
}
public void setUserId(String userId) {
this.userId = userId;
}
public String getPdtName() {
return pdtName;
}
public void setPdtName(String pdtName) {
this.pdtName = pdtName;
}
public float getPrice() {
return price;
}
public void setPrice(float price) {
this.price = price;
}
public int getNumber() {
return number;
}
public void setNumber(int number) {
this.number = number;
}
public float getAmountFee() {
return amountFee;
}
public void setAmountFee(float amountFee) {
this.amountFee = amountFee;
}
@Override
public String toString() {
return this.orderId + "," + this.userId + "," + this.pdtName + "," + this.price + "," + this.number + ","
+ this.amountFee;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(this.orderId);
out.writeUTF(this.userId);
out.writeUTF(this.pdtName);
out.writeFloat(this.price);
out.writeInt(this.number);
}
@Override
public void readFields(DataInput in) throws IOException {
this.orderId = in.readUTF();
this.userId = in.readUTF();
this.pdtName = in.readUTF();
this.price = in.readFloat();
this.number = in.readInt();
this.amountFee = this.price * this.number;
}
// 比较规则:先比总金额,如果相同,再比商品名称
@Override
public int compareTo(OrderBean o) {
return this.orderId.compareTo(o.getOrderId())==0?Float.compare(o.getAmountFee(), this.getAmountFee()):this.orderId.compareTo(o.getOrderId());
}
}
package cn.edu360.mr.order.topn.grouping;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Partitioner;
public class OrderIdPartitioner extends Partitioner<OrderBean, NullWritable>{
@Override
public int getPartition(OrderBean key, NullWritable value, int numPartitions) {
// 按照订单中的orderid来分发数据
return (key.getOrderId().hashCode() & Integer.MAX_VALUE) % numPartitions;
}
}
自定义Partitioner
重写数据分发规则Partitioner,根据OrderId进行分发。
package cn.edu360.mr.order.topn.grouping;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Partitioner;
public class OrderIdPartitioner extends Partitioner<OrderBean, NullWritable>{
@Override
public int getPartition(OrderBean key, NullWritable value, int numPartitions) {
// 按照订单中的orderid来分发数据
return (key.getOrderId().hashCode() & Integer.MAX_VALUE) % numPartitions; //numPartitions就是reduce的数量
}
}
MapReduce程序
map: 读取数据切分字段,封装数据到一个bean中作为key传输,key要按照成交金额比大小
reduce:在reduce方法中输出每组数据的前N条即可,但是如果要实现该需求,要求OrderId相同的要被看作一个key,到同一个reduce函数中去执行,如果要实现该需求,则需要GroupingComparator重写判断key相同的规则。
package cn.edu360.mr.order.topn.grouping;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class OrderTopn {
public static class OrderTopnMapper extends Mapper<LongWritable, Text, OrderBean, NullWritable>{
OrderBean orderBean = new OrderBean();
NullWritable v = NullWritable.get();
@Override
protected void map(LongWritable key, Text value,
Mapper<LongWritable, Text, OrderBean, NullWritable>.Context context)
throws IOException, InterruptedException {
String[] fields = value.toString().split(",");
orderBean.set(fields[0], fields[1], fields[2], Float.parseFloat(fields[3]), Integer.parseInt(fields[4]));
context.write(orderBean,v);
}
}
public static class OrderTopnReducer extends Reducer< OrderBean, NullWritable, OrderBean, NullWritable>{
/**
* 虽然reduce方法中的参数key只有一个,但是只要迭代器迭代一次,key中的值就会变
*/
@Override
protected void reduce(OrderBean key, Iterable<NullWritable> values,
Reducer<OrderBean, NullWritable, OrderBean, NullWritable>.Context context)
throws IOException, InterruptedException {
int i=0;
for (NullWritable v : values) {
context.write(key, v);
if(++i==3) return;
}
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration(); // 默认只加载core-default.xml core-site.xml
conf.setInt("order.top.n", 2);
Job job = Job.getInstance(conf);
job.setJarByClass(OrderTopn.class);
job.setMapperClass(OrderTopnMapper.class);
job.setReducerClass(OrderTopnReducer.class);
job.setPartitionerClass(OrderIdPartitioner.class);
job.setGroupingComparatorClass(OrderIdGroupingComparator.class);
job.setNumReduceTasks(2);
job.setMapOutputKeyClass(OrderBean.class);
job.setMapOutputValueClass(NullWritable.class);
job.setOutputKeyClass(OrderBean.class);
job.setOutputValueClass(NullWritable.class);
FileInputFormat.setInputPaths(job, new Path("F:\\mrdata\\order\\input"));
FileOutputFormat.setOutputPath(job, new Path("F:\\mrdata\\order\\out-3"));
job.waitForCompletion(true);
}
}
自定义GroupingComparator
自定义GroupingComparator,订单id相同的看作一个key。
package cn.edu360.mr.order.topn.grouping;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
public class OrderIdGroupingComparator extends WritableComparator{
public OrderIdGroupingComparator() { // 用于告知方法,需要对什么类进行操作。
super(OrderBean.class,true);
}
@Override
public int compare(WritableComparable a, WritableComparable b) { //相同的OrderId认为是一个key。
OrderBean o1 = (OrderBean) a;
OrderBean o2 = (OrderBean) b;
return o1.getOrderId().compareTo(o2.getOrderId());
}














 759
759











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









