







Oscar: Object-Semantics Aligned Pre-training for Vision-Language Tasks
1. 简介
- 发表:ECCV 2020
- 解决问题:论文主要是想解决视觉语言跨模态表示中的对齐问题
- 传统方法:传统的视觉语言对齐主要依赖于<文本,图像>这样的二元组学习对齐存在着两个问题:(1)object区域之间存在着重叠,特征不准确,导致提取的visual embedding有噪声;(2)是弱监督学习,没有较为精准的视觉语言对齐标签。
- 方法:作者考虑到目标检测的标签兼具视觉和语言特征,一方面目标的标签是语言表示,另一方面其对应着视觉中的区域,能够很好地用来指导视觉和语言的对齐。
2. 方法
2.1 数据定义
将image-text pair表示为<文本,标签,图像>的三元组 < w , q , v > <w,q,v> <w,q,v>,每张图像提取K个region。其中w表示与图像对应的文本;q表示K个目标标签的embedding;v表示K个region特征,region特征为region representation和position拼接之后接一个线性层。
2.2 语言角度
从dictionary的角度考虑q,可以设计类似bert的预训练任务,即掩码。定义discrete token sequence
h
≜
[
w
,
q
]
h\triangleq[w,q]
h≜[w,q],并使用Masked Token Loss进行训练,将15%的token替换为[mask]并进行预测

2.3 视觉角度
从模态的角度考虑,通过对比学习来强调对齐。定义
h
′
≜
[
q
,
v
]
h'\triangleq[q,v]
h′≜[q,v],sample一些“污染的”负样本:将50%的
h
′
h'
h′中的q替换成其他目标标签,之后在特征后接一个全连接层进行二分类
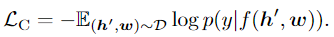

3. 实验
在一个包含650万文本-图像对的公开数据集上预训练了Oscar模型,然后在下游任务中对模型进行微调,在六个视觉语言理解及生成任务上取得目前最好的结果














 869
869











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









