







1. 记录背景
- 服务器使用小白第一次用实验室服务器跑代码,配置各种环境,遇到各种错误,怀疑人生…所幸大都解决了。
总结就是,遇到错误之后一定要多看别人解决的博客,而且要多看几篇,因为有很多可能并不适用,而且每个人电脑的环境也不太相同。 - 基础背景是已经可以连接上服务器,在服务器上配置了anaconda环境
2. 在服务器搭建虚拟环境
- 新建虚拟环境
conda create -n py3711 python=3.7.11
-n表示后面的参数是环境的名字,这里我取的是``py3711,可以指定python的版本
- 激活环境
conda activate py3711
之后从base环境(默认的环境)进入py3711环境也是这个命令
- 安装pytorch
下载cuda对应版本的pytorch,这里需要到
官网找到对应版本的命令,然后复制粘贴。
!!!一定要注意github上那个项目的pytorch版本(一般在readme或者issues的留言)我需要的pytorch版本是3.7以上,然后我的cuda是10.1(如果需要也可以安装10.1一下的版本),所以我的选择是:

- 安装其他包
pip install packegname
卸载包
pip uninstall packagename
3. pycharm连接远程服务器
-
配置完成之后项目就会自动拷贝到服务器,并且在PyCharm改动代码,服务器端也会同步。但是在服务器上改动代码,本地好像不太能同步…
-
注意这里如果是用本地PyCharm的终端运行python文件是使用的本地的解释器,如果要使用服务器的gpu,可以右键运行或者点运行的按钮。
-
还有就是在PyCharm中使用服务器进行分布式训练
4. 在服务器上进行分布式训练
找博客…
参考博客1
但是网上的教程大多都是在自己的电脑上进行多卡训练,最近实验室的卡一直有人在用,所以也不知道自己有没有配置好
参考博客2
- 在服务器端进行软链接的设置(服务器上虚拟环境中的distributed文件软链接到项目中)
- 在本地进行软链接的设置(服务器上虚拟环境中的distributed文件软链接到本地PyCharm的项目中)。这里由于感觉将远端的文件软链接到本地过于复杂,所以直接在PyCharm中进行download(右键本地项目->deployment->download from xxx@服务器地址)
- 设置launch的参数
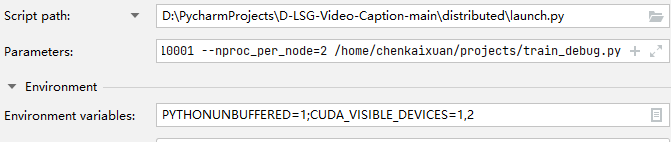
(1)脚本路径选择刚刚download的distributed里的launch.py
(2)参数填写分布式训练的参数,这里要注意执行的python文件(train.py)的路径最好写绝对路径,否则可能找不到,因为默认是当前文件(launch.py)所在路径
(3)环境可以设置可见的gpu - 注意
如果只使用1块GPU,可以在上面第一张图片里下拉设置train的参数,可见GPU等;然后点击绿色三角运行即可。
如果使用多块GPU分布式训练,则点击launch的绿色三角按钮。但是如果程序中有有关当前路径的代码(例如新建目录,向目录文件读写等)需要更改,因为当前目录已经变成了launch所在目录
更改方法
os.chdir('/home/chenkaixuan/projects/')
显示当前工作目录
path = os.getcwd()
print('present path:', path)
5. Debug
-
报错:报错不记得了,大致意思是object对象results没有key属性
定位:

解决:results是前面通过函数返回的值,在函数中定义的是dict对象,也不知道为啥就说没有key属性。由于当时PyCharm还没有实现分布式训练,所以直接把这两句注释了,不然可以看看这个results返回之后的类型和里面的值。 -
报错:不能将null赋值给results_all变量
定位


解决:因为当时对代码并不是很懂,并不明白为什么。后来经过尝试和推理发现只要用4块GPU就不会出现这个错,然后联系到上面的distributed想到可能是将所有gpu上的数据都转到results_all这个白能量上,所以当GPU数量小于4时result_multi[4]就是null, -
报错:没有Stanford CoreNLP包和model
定位:

解决:pycocotools文件夹下有一个get_stanford_models.sh没有执行。一般来说项目里的sh文件都是需要先执行的。
执行命令:
sh XXX.sh
# sh /home/chenkaixuan/projects/caption-eval/get_stanford_models.sh
又遇到错如下:
checkdir: cannot create extraction directory: pycocoevalcap/spice/lib
No such file or directory
原因:脚本文件中执行unzip xxx dir时,若dir不存在没有权限新建文件夹
解决:手动建立目录
-
报错:FileNotFoundError: [Errno 2] No such file or directory: ‘java’: ‘java’
定位:

原因:coco在执行 ptbtokenizer.py 时,需要调用 stanford-corenlp-3.4.1.jar 包,使用java进行运算,如果机器上没有装java环境时,就会报错参考链接
解决:安装java环境参考链接
小插曲:基本上都是需要在.bach_profile中更改环境变量,但是我的目录下没有这个文件,只有.profile文件,看了很多博客发现应该是系统的原因,所以直接在.profile中更改即可参考链接 -
报错:cuda out of memory.try to …
原因:内存不够
解决:batch size减小,128->64 -
报错:OSError: [Errno 28] No space left on device
原因:在进行IO读写的时候,内存不够,是不是程序写了很多数据(是的)

解决:发现在每一轮训练结束都会将模型的参数保存下来(一共有60轮),而模型的参数大概有一个g,磁盘不够。所以改为每10轮保存一次
6. 查看tensorboard
程序终于完整地执行了,但是!!!结果和论文不太一样,查了6、7个点,估计是因为我把batch size 调小了,而这个模型也是在batch siez=128时的参数,总之要想达到论文里的指标,还得调参数…
于是我想看看tensorboard上面的图是不是和论文中的一致,然后找博客如何在本地查看服务器上的tensorboard
-
建立隧道
打开MobaXterm,点击上方Tunneling—>New SSH Tunnel

-
配置tensorboard端口和服务器相关信息,并打开隧道
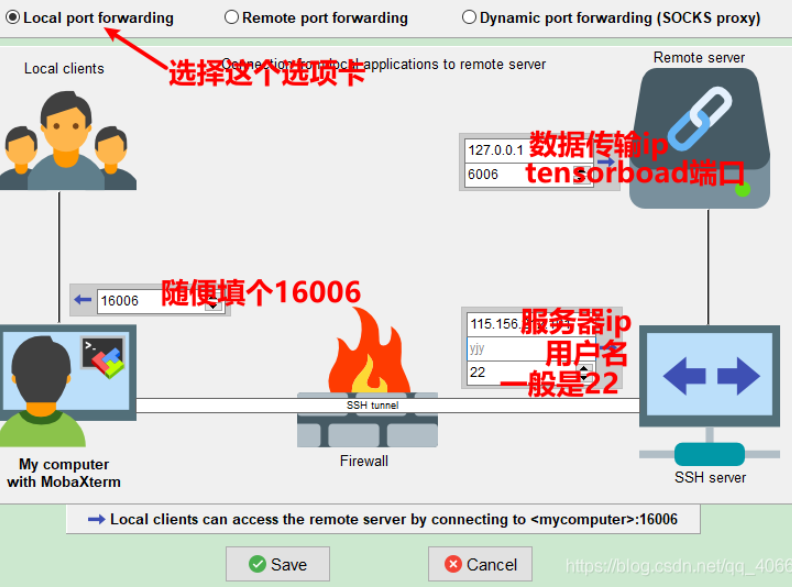
点击Start

-
输入命令:
tensorboard --logdir=/home/.../your projects/runs --host=127.0.0.1
- 打开浏览器,输入地址:数据ip:本地端口号,即
127.0.0.1:16006
参考链接1
参考链接2
注意:这里由于服务器给出了一个127.0.01:6006的链接,然后6006和16006太像了,所以我在本地输入127.0.01:6006显示被拒绝。














 1372
1372











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









