






TF-IDF余弦相似度理论
在处理文本时,由于众多无意义的词语(如的、是、有等词语)在文章中广泛出现,词频高但是对于文章的重要性并不高,因此采用TF-IDF算法。词频(TF)的计算公式为:某个词出现次数/文章总词数,逆文本频率(IDF)的计算公式为:log(语料库中的文档总数/(包含该词汇的文档数+1)),最后将TF*IDF。这样计算的话,即便一个词的词频再高,当它出现在大量文档中时,其TF-IDF也不会很高,这样方便我们检索对于该文章相对更关键的词语。

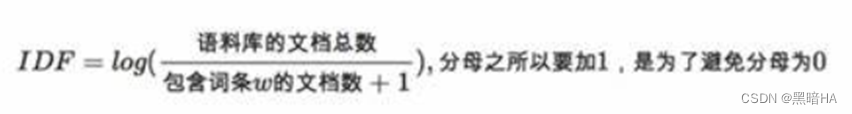
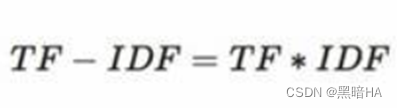
计算文本间相似度采用的方法是计算余弦相似度。具体计算方法是将不同的关键词看作是不同的维度,将关键词对应的词频看作是该维度的值,只计算问题和文本中出现过的关键词,最后通过余弦相似度公式:两向量的点乘积除以两向量模的乘积。
以此方法计算问题与所有文本的余弦相似度,其值越高说明问题与文本越相似。
词频字典的处理与余弦相似度的计算
为了计算余弦相似度,我们需要先得到所有目标文档的词频。因此,我们需要使用Tongyi-Finance-14B-Chat模型提供的分词器,并遍历所有txt文件。在处理每个txt文件时,我们需要统计所有关键词出现的次数,并使用分词器将关键词转化为token ID,用字典来保存所有token ID及其出现的次数。最后将txt文件名和token ID字典保存到csv文件中,方便后续使用。遍历完所有txt文件后,我们就得到了所有的文件所对应的词频字典,并保存到本地的csv文件中。
在计算问题文本与文档文本的余弦相似度时,我们采用加权的TF-IDF余弦相似度计算,具体公式如下。

在计算余弦相似度时,我们需要在计算词频时,需要将原文本文档的标准化字典作为分母。这样我们可以将出现数量多的对原文本处理没有重要意义的词的权重降低,而将对文章更为关键的词的权重提升,以此法得到的余弦相似度和文本相似度的关联更密切。
问题文本的处理
在处理问题文本时,我们首先获取问题及其对应实体,如果对应实体(问题中提及的公司名)为空,则不进行处理;否则就获取其对应的csv文件和txt文件。然后我们将问题文本中的空格和对应实体去掉,防止其影响文本相似度的计算,再将一些对文本相似度计算没有价值的停用词和标点符号换为空格。这步操作可以减少噪音,使分析聚焦于更有意义的文本上。这样我们按空格进行分割,就可以到了一个包含文本词汇的list列表。
得到词汇列表后,我们遍历该列表,并使用Tongyi-Finance-14B-Chat的分词器,将分词后的结果转化为字典,并获取每个单词转化后的token ID序列。最后我们遍历该token ID序列,合并所有token到一个list列表中,并创建问题词频计数器来计算统计文本中token出现的次数。
执行完上述操作后,我们遍历该问题对应的csv文件,获取其纯文本,用空格代替纯文本中的标点符号,然后用分词器处理该纯文本,获取token ID序列,并储存在list列表中。然后再用词频计数器统计文档片段中的token出现次数。最后我们计算该文档片段与问题的文本余弦相似度,将其结果储存到list列表中。
遍历完所有csv文件后,我们记录前n个余弦相似度最大的值及其对应的索引值。然后我们再创建一个list列表,将前n个余弦相似度最大的值所对应的纯文本保存在该list列表中。
最后,我们在本地保存一个csv文件,保存其问题、问题id、对应实体、csv文件名,这几项与原来的文件一致,另外还需要保存前n个余弦相似度最大的索引值、前n个余弦相似度最大的余弦相似度值、前n个余弦相似度最大的csv文件的纯文本。
只有txt文本和加权的余弦相似度并不一定能够得到答案,因此我们还需要处理表格内容。
具体处理与前面的内容相似,但是在获取文档文本时,我们不仅需要获取纯文本,还需要加入表格内容一起处理。后续的减少噪音和文档分割与前面均相似。在求文本间的余弦相似度时,我们需要使用标准的TF-IDF来求解,与前文的方法不同,目的是为了获取不同的文档片段,当上面的文本无法经过处理获取答案后,我们可以再用该方法获得的文本进行处理。处理结束后,也将前n个余弦相似度最大的文本片段保存到本地的csv文件中。
这样,我们就得到了两个csv文件,在搜索答案时共同处理,以得到更加丰富的答案。
c01-选取余弦相似度最大的前n个文本
数据加载与初始化
加载问题分类实体数据:从A02_question_classify_entity.csv文件中读取问题及其对应的实体信息。
加载标准化字典:从AD_normalized_ot.csv文件中读取标准化数据,用于后续余弦相似度计算中的归一化处理。
导入模型与分词器:使用ModelScope框架加载Tongyi-Finance-14B-Chat模型的分词器,准备对文本进行预处理。
import json
import csv
import pandas as pd
import copy
n = 30
import re
from collections import Counter
import math
pattern1 = r'截至'
pattern2 = r'\d{1,4}年\d{1,2}月\d{1,2}日'
# 获取A02文件(问题分类实体数据)
q_file_dir = '/app/intermediate/A02_question_classify_entity.csv'
q_file = pd.read_csv(q_file_dir,delimiter = ",",header = 0)
# 获取标准化字典,用于后续的余弦相似度计算
normalized_dir = '/app/data/AD_normalized_ot.csv'
normalized_file = pd.read_csv(normalized_dir,delimiter = ",",header = 0)
# n_list_1储存标准化字典的文件名一列,n_list_2储存标准化字典一列,
n_list_1 = list(normalized_file['文件名'])
n_list_2 = list(normalized_file['normalized'])
pdf_csv_file_dir = '/app/data/txt2csv_normalized'
# 导入模型
from modelscope import AutoModelForCausalLM, AutoTokenizer, snapshot_download
from modelscope import GenerationConfig
model_dir = '/tcdata/models/Tongyi-Finance-14B-Chat'
# 引入模型提供的分词器
tokenizer = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True)余弦相似度计算
采用加权的tf-idf余弦相似度计算
def counter_cosine_similarity(c1, c2, normalized_dict):
terms = set(c1).union(c2)
dotprod = sum(c1.get(k, 0) * c2.get(k, 0)/normalized_dict.get(k,1) for k in terms)
magA = math.sqrt(sum(c1.get(k, 0)**2/(normalized_dict.get(k,1)**2) for k in terms))
magB = math.sqrt(sum(c2.get(k, 0)**2/(normalized_dict.get(k,1)**2) for k in terms))
if magA * magB != 0:
return dotprod / (magA * magB)
else:
return 0主处理流程
创建输出CSV文件:准备一个CSV文件用于存储每个问题及其匹配度最高的n段文本信息。
循环处理每个问题:
检查问题是否有对应实体:如果问题没有对应实体(标记为"N_A"),则跳过此问题。
读取并处理文本:对于有实体的问题,读取对应公司的CSV文件中的文本,进行预处理(如去除停用词、标准化处理等)。
分词与编码:使用分词器对问题和文本进行分词,并统计词频。
计算相似度:遍历公司文件中的每一段文本,计算其与问题的余弦相似度,并存储结果。
选取Top N相似度的文本:根据相似度找出最高的n个文本,并记录相关信息到输出CSV文件中。
# 对于1000个问题通过循环来进行处理
for cyc in range(1000):
# temp_q为A02文件中当前处理的问题,temp_e为对应实体(公司名)
temp_q = q_file[cyc:cyc+1]['问题'][cyc]
temp_e = q_file[cyc:cyc+1]['对应实体'][cyc]
# 如果temp_e为N_A,说明该问题没有对应实体,则我们不进行处理
if temp_e == 'N_A':
csvwriter.writerow([q_file[cyc:cyc+1]['问题id'][cyc],
q_file[cyc:cyc+1]['问题'][cyc],
'N_A','N_A','N_A','N_A'])
continue
else:
# 如果temp_e不为N_A,则我们获取该问题对应的csv文件,并读取对应的txt文本,保存到temp_hash中
temp_csv_dir = pdf_csv_file_dir +'/' + q_file[cyc:cyc+1]['csv文件名'][cyc]
company_csv = pd.read_csv(temp_csv_dir,delimiter = ",",header = 0)
temp_hash = q_file[cyc:cyc+1]['csv文件名'][cyc][0:-8]+'.txt'
# 通过temp_hash找到该文本对应的标准化字典
normalized_id = n_list_1.index(temp_hash)
normalized_dict = eval(n_list_2[normalized_id])
# 去除掉temp_q中的所有空格和temp_e,防止其造成干扰
temp_q = temp_q.replace(' ','')
temp_q = temp_q.replace(temp_e,' ')
# 移除掉所有temp_q中的停用词,用空格替代
for word in stopword_list:
temp_q = temp_q.replace(word,' ')
# 将temp_q按空格分割成单词列表temp_q_list
temp_q_list = temp_q.split()
# 定义temp_q_tokens列表,用于保存分词后的token
temp_q_tokens = list()
# 遍历问题单词列表temp_q_list,使用分词器对每个单词进行分词和编码,转化为token
for word in temp_q_list:
temp_q_tokens_add = tokenizer(word)
temp_q_tokens_add = temp_q_tokens_add['input_ids']
for word_add in temp_q_tokens_add:
temp_q_tokens.append(word_add)
# C_temp_q_tokens是词频计数器,用于计算每个token出现次数
C_temp_q_tokens = Counter(temp_q_tokens)
# list_sim用于存储各文本的的余弦相似度
list_sim = list()
for cyc2 in range(len(company_csv)):
temp_sim = 0
temp_file_piece = ''
if company_csv[cyc2:cyc2+1]['纯文本'][cyc2] != '':
temp_file_piece = company_csv[cyc2:cyc2+1]['纯文本'][cyc2]
for bd in bd_list:
temp_file_piece = temp_file_piece.replace(bd,' ')
temp_s_tokens = tokenizer(temp_file_piece)
temp_s_tokens = temp_s_tokens['input_ids']
C_temp_s_tokens = Counter(temp_s_tokens)
C_temp_s_tokens['220'] = 0
# 如果前文定义的temp_q_tokens这个token列表为空,则余弦相似度为0,否则,计算余弦相似度
if temp_q_tokens == '':
temp_sim = 0
else:
temp_sim = counter_cosine_similarity(C_temp_q_tokens,C_temp_s_tokens,normalized_dict)
list_sim.append(temp_sim)
# 找到相似度最大的的前n个文本
t = copy.deepcopy(list_sim)
# max_number存储余弦相似度,max_index存储对应索引
max_number = []
max_index = []
for _ in range(n):
number = max(t)
index = t.index(number)
t[index] = 0
max_number.append(number)
max_index.append(index)
t = []
# temp_file_pieces_list存储要保存到文件的各项信息
temp_file_pieces_list = list()
for index in max_index:
temp_dict = {}
if company_csv[index:index+1]['纯文本'][index] == company_csv[index:index+1]['纯文本'][index]:
temp_dict['text'] = company_csv[index:index+1]['纯文本'][index]
temp_file_pieces_list.append(temp_dict)
# 将对应的片段放入文件
csvwriter.writerow([q_file[cyc:cyc+1]['问题id'][cyc],
q_file[cyc:cyc+1]['问题'][cyc],
temp_e,q_file[cyc:cyc+1]['csv文件名'][cyc],max_index,max_number,temp_file_pieces_list])
g.close() c02
数据加载与初始化
加载问题分类实体数据:从A02_question_classify_entity.csv文件中读取问题及其对应的实体信息。
加载标准化字典:从AD_normalized_ot.csv文件中读取标准化数据,用于后续余弦相似度计算中的归一化处理。
导入模型与分词器:使用ModelScope框架加载Tongyi-Finance-14B-Chat模型的分词器,准备对文本进行预处理。
import json
import csv
import pandas as pd
import copy
import re
from collections import Counter
import math
# n指找到前n个余弦相似度最大的片段,cap是限制用于计算相似度的词频上限
n = 30
cap = 4
pattern1 = r'截至'
pattern2 = r'\d{1,4}年\d{1,2}月\d{1,2}日'
q_file_dir = '/app/intermediate/A02_question_classify_entity.csv'
q_file = pd.read_csv(q_file_dir,delimiter = ",",header = 0)
pdf_csv_file_dir = '/app/data/pdf_analysised'
# 导入模型
from modelscope import AutoModelForCausalLM, AutoTokenizer, snapshot_download
from modelscope import GenerationConfig
model_dir = '/tcdata/models/Tongyi-Finance-14B-Chat'
# 引入模型提供的分词器
tokenizer = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True)余弦相似度计算
采用余弦相似度计算来找到最相近的文本
def counter_cosine_similarity(c1, c2):
terms = set(c1).union(c2)
dotprod = sum(c1.get(k, 0) * c2.get(k, 0) for k in terms)
magA = math.sqrt(sum(c1.get(k, 0)**2 for k in terms))
magB = math.sqrt(sum(c2.get(k, 0)**2 for k in terms))
if magA * magB != 0:
return dotprod / (magA * magB)
else:
return 0主处理流程
文本预处理
对每一个问题执行以下操作:
移除问题中的停用词、特定模式的字符串(如“截至”和日期格式),以及对应实体名称,以减少噪声。
使用分词器将问题转换为token序列。
统计token的词频,但对词频进行上限限制(cap),以防高频词过度影响相似度计算。
计算相似度
遍历每个公司报告文档中的文本和表格内容,同样进行分词和词频统计,并计算与问题文本的余弦相似度。
将相似度值存入列表,用于后续排序。
选择最相关片段
从相似度列表中选出最高的n个值及其索引。
根据这些索引,从原始文档中提取相应的文本和表格内容,组织成字典形式存储。
输出结果
将问题ID、问题内容、对应实体、文件名、相关片段的索引、相似度以及片段内容写入CSV文件。
g = open('/app/intermediate/AB01_question_with_related_text_rp.csv', 'w', newline='', encoding = 'utf-8-sig')
csvwriter = csv.writer(g)
csvwriter.writerow(['问题id','问题','对应实体','csv文件名','top_n_pages_index','top_n_pages_similarity','top_n_pages'])
# 定义停用词列表,在后续文本中去掉停用词信息
stopword_list = ['根据','招股意见书','招股意向书','报告期内','截至','千元','万元','哪里','哪些','哪个','分别','知道',"什么",'是否','分别','多少','为','?','是','和',
'的','我','想','元','。','?',',','怎样','谁','以及','了','在','哪','对']
bd_list = [',','.','?','。',',','[',']']
print('C02_Started')
# 对于1000个问题通过循环来进行处理
for cyc in range(1000):
# temp_q为A02文件中当前处理的问题,temp_e为对应实体(公司名)
temp_q = q_file[cyc:cyc+1]['问题'][cyc]
# 使用正则表达式移除掉temp_q中的“截至”和日期信息
str1_list = re.findall(pattern1,temp_q)
str2_list = re.findall(pattern2,temp_q)
temp_e = q_file[cyc:cyc+1]['对应实体'][cyc]
# 如果temp_e为N_A,说明该问题没有对应实体,则我们不进行处理
if temp_e == 'N_A':
csvwriter.writerow([q_file[cyc:cyc+1]['问题id'][cyc],
q_file[cyc:cyc+1]['问题'][cyc],
'N_A','N_A','N_A','N_A'])
continue
else:
# 如果temp_e不为N_A,则我们获取该问题对应的csv文件
temp_csv_dir = pdf_csv_file_dir +'/' + q_file[cyc:cyc+1]['csv文件名'][cyc]
company_csv = pd.read_csv(temp_csv_dir,delimiter = ",",header = 0)
# 去除掉temp_q中的空格信息
temp_q = temp_q.replace(' ','')
# 去除截至与日期,使得匹配更有针对性
for word in str1_list:
temp_q = temp_q.replace(word,'')
for word in str2_list:
temp_q = temp_q.replace(word,'')
# 去除掉temp_q中的temp_e,防止其造成干扰
temp_q = temp_q.replace(temp_e,' ')
# 去除掉temp_q中的停用词
for word in stopword_list:
temp_q = temp_q.replace(word,' ')
# 将temp_q按空格分割成单词列表temp_q_list
temp_q_list = temp_q.split()
# 定义temp_q_tokens列表,用于保存分词后的token
temp_q_tokens = list()
# 遍历问题单词列表temp_q_list,使用分词器对每个单词进行分词和编码,转化为token
for word in temp_q_list:
temp_q_tokens_add = tokenizer(word)
temp_q_tokens_add = temp_q_tokens_add['input_ids']
for word_add in temp_q_tokens_add:
temp_q_tokens.append(word_add)
# 计算每个token出现次数
C_temp_q_tokens = Counter(temp_q_tokens)
# list_sim用于存储余弦相似度
list_sim = list()
for cyc2 in range(len(company_csv)):
temp_sim = 0
temp_file_piece = ''
if company_csv[cyc2:cyc2+1]['纯文本'][cyc2] == company_csv[cyc2:cyc2+1]['纯文本'][cyc2]:
temp_file_piece = company_csv[cyc2:cyc2+1]['纯文本'][cyc2]
if company_csv[cyc2:cyc2+1]['表格'][cyc2] == company_csv[cyc2:cyc2+1]['表格'][cyc2]:
temp_file_piece = temp_file_piece + company_csv[cyc2:cyc2+1]['表格'][cyc2].replace('None'," ")
for bd in bd_list:
temp_file_piece = temp_file_piece.replace(bd,' ')
temp_s_tokens = tokenizer(temp_file_piece)
temp_s_tokens = temp_s_tokens['input_ids']
C_temp_s_tokens = Counter(temp_s_tokens)
C_temp_s_tokens['220'] = 0
# 如果词频数量大于cap,将其设为cap,防止词频次数过大影响结果
for token in C_temp_s_tokens:
if C_temp_s_tokens[token] >= cap:
C_temp_s_tokens[token] = cap
# 如果token列表为空,则余弦相似度为0,否则,计算余弦相似度
if temp_q_tokens == '':
temp_sim = 0
else:
temp_sim = counter_cosine_similarity(C_temp_q_tokens,C_temp_s_tokens)
list_sim.append(temp_sim)
# 找到相似度最大的的前n个文本
t = copy.deepcopy(list_sim)
# max_number存储余弦相似度,max_index存储对应索引
max_number = []
max_index = []
for _ in range(n):
number = max(t)
index = t.index(number)
t[index] = 0
max_number.append(number)
max_index.append(index)
t = []
# temp_file_pieces_list存储要保存到文件的各项信息
temp_file_pieces_list = list()
for index in max_index:
temp_dict = {}
if company_csv[index:index+1]['纯文本'][index] == company_csv[index:index+1]['纯文本'][index]:
temp_dict['text'] = company_csv[index:index+1]['纯文本'][index]
if company_csv[index:index+1]['表格'][index] == company_csv[index:index+1]['表格'][index]:
temp_dict['table'] = company_csv[index:index+1]['表格'][index].replace('None'," ")
temp_file_pieces_list.append(temp_dict)
# 将对应的片段放入文件
csvwriter.writerow([q_file[cyc:cyc+1]['问题id'][cyc],
q_file[cyc:cyc+1]['问题'][cyc],
temp_e,q_file[cyc:cyc+1]['csv文件名'][cyc],max_index,max_number,temp_file_pieces_list])
g.close() 














 741
741

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









