







Hadoop的高可用模式的搭建
Hadoop-HA搭建
- 修改hdfs-site.xml文件
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>n1,n2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.n1</name>
<value>a:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.n2</name>
<value>b:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.n1</name>
<value>a:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.n2</name>
<value>b:50070</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address.mycluster.n1</name>
<value>a:50090</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://a:8485;b:8485;c:8485/mycluster</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop/jn</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
- 修改core-hdfs.xml文件
#设置主节点
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
# 设置临时文件的存储地址
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/tmp</value>
</property>
#设置zookeeper的端口号
<property>
<name>ha.zookeeper.quorum</name>
<value>a:2181,b:2181,c:2181</value>
</property>
YARN-HA的搭建
- 配置yarn-site.xml文件
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster1</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>r1,r2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.r1</name>
<value>a</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.r2</name>
<value>b</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.r1</name>
<value>a:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.r2</name>
<value>b:8088</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>a,b,c</value>
</property>
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
手动的故障转移
- 删除每个节点上的tmp文件
- 分别启动每个节点上的journalnode进程
sbin/hadoop-daemon.sh start journalnode - 格式化其中一个namenode节点
bin/hadoop namenode -format - 启动格式化的那个节点
sbin/hadoop-daemon.sh start namenode - 另一个复制格式化的元数据
bin/namenode -bootstrapStandby,也可以直接复制格式化好的节点的tmp到相应的文件夹下 - 启动没格式化的节点
sbin/hadoop-daemon.sh start namenode - 设置节点为action状态
bin/hdfs haadmin -transitionToAction n1 - 强制切换成活跃状态
bin/hdfs haadmin -transitionToActive --forcemanual nn1
联合zookeeper实现自动故障转移
需要在hadoop的hdfs-site.xml配置文件上加上
<property>
<name>dfs.ha.automatic-failover.enabled.mycluster</name>
<value>true</value>
</property>
- 启动每个节点上的zookeeper
bin/./zkService.sh start - 在hadoop目录下格式化zkfc
bin/hdfs zkfc -formatZK - 在namenode节点上启动
sbin/hadoop-daemon.sh start zkfc - 启动hadoop
查看结果
namenode1的进程和WEIUI显示
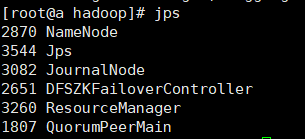

namenode2的进程和WEIUI显示
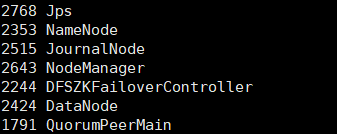

使用kill -9 进程号命令杀死namenode1(进程号就是使用jsp命令查看进程时namenode前面的一串数字)
发现namenode1无法访问

namenode2已变成活跃
















 413
413











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









