







Spark---RDD的分区和shuffle
简单简绍
分区的作用
RDD使用分区来分布式并行处理数据,并且要做到尽量少的在不同的Executor之间使用网络交换数据,所以当使用RDD读取数据的时候,会尽量的在物理上靠近数据源,比如说在读取Cassandra或者HDFS 中数据的时候,会尽量的保持RDD的分区和数据源的分区数,分区模式等——对应
分区和Shuffle的关系
分区的主要作用是用来实现并行计算,本质上和Shuffle没什么关系,但是往往在进行数据处理的时候,例如reduceByKey,groupByKey 等聚合操作,需要把Key相同的Value拉取到一起进行计算,这个时候因为这些Key相同的Value可能会坐落于不同的分区,于是理解分区才能理解shuffle的根本原理
Spark中的Shufle操作的特点
只有Key-Value型的RDD才会有Shuffle 操作,例如 RDD[ (K,V)],但是有一个特例,就是repartition算子可以对任何数据类型 Shuffle
早期版本Spark 的Shuffle算法是Hash base shuffle ,后来改为Sort base shuffle ,更适合大吞吐量的场景
RDD的分区操作
查看分区操作
rdd.partitions.size

在创建RDD的时候指定分区
//本地集合
val rdd1 = sc.parallelize(Seq(1,2,3,4,5),2)
println("rdd1的分区数:"+rdd1.partitions.size)
//数据集
val rdd2 = sc.textFile("resource/data.csv")
println("rdd2的分区数:"+rdd2.partitions.size)
分区的增加和删除
//1、创建SparkConf
val conf = new SparkConf().setMaster("local[6]").setAppName("spark_context")
//2、创建SparkContext
val sc = new SparkContext(conf)
val rdd1 = sc.parallelize(Seq(2, 4, 1, 5, 7, 3),2)
//设置分区数,分区数可大可小
rdd1.repartition(4).partitions.size
val rdd2 = sc.parallelize(Seq(("a", 89), ("c", 90), ("b", 87)),3)
//减少分区,不能设置比先前的多
rdd2.coalesce(1).partitions.size
Shuffle的原理
Spark 的Shuffle 发展大致有两个阶段: Hash base shuffle 和 Sort base shuffle
Hash base shuffle

大致的原理是分桶,假设Reducer的个数为R,那么每个Mapper有R个桶,按照Key 的 Hash将数据映射到不同的桶中, Reduce找到每一个Mapper中对应自己的桶拉取数据.
假设Mapper的个数为M,整个集群的文件数量是M*R ,如果有1,000个Mapper和Reducer,则会生成1.000,000个文件,这个量非常大了.
过多的文件会导致文件系统打开过多的文件描述符,占用系统资源.所以这种方式并不适合大规模数据的处理,只适合中等规模和小规模的数据处理,在 Spark 1.2版本中废弃了这种方式.
Sort base shuffle

- 对于Sort base shuffle来说,每个Map侧的分区只有一个输出文件,Reduce侧的Task 来拉取,大致流程如下
1.Map侧将数据全部放入一个叫做AppendOnlyMap 的组件中,同时可以在这个特殊的数据结构中做聚合操作
⒉然后通过一个类似于 MergeSort 的排序算法TimSort对AppendOnlyMap 底层的 Array排序先按照Partition ID排序,后按照 Key的 HashCode排序
3.最终每个 Map Task生成一个输出文件,Reduce Task来拉取自己对应的数据 - 从上面可以得到结论, Sort base
shuffle确实可以大幅度减少所产生的中间文件,从而能够更好的应对大吞吐量的场景,在Spark1.2以后,已经默认采用这种方式. - 但是需要大家知道的是,Spark的Shuffle算法并不只是这一种,即使是在最新版本,也有三种Shuffle算法,这三种算法对每个Map都只产生一个临时文件,但是产生文件的方式不同,一种是类似Hash的方式。一种是刚才所说的Sort,一种是对Sort的一种优化(使用 Unsafe API直接申请堆外内存)
RDD的缓存
RDD缓存的意义
减少shuffle
减少其他的算子执行
缓存算子生成的结果
还可以减少容错
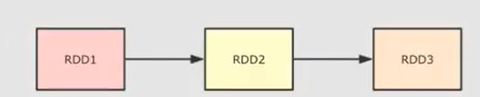
上图,RDD3是通过RDD2获得的,RDD2是通过RDD1获得的,如果RDD3出错的话,就要重新来,但是如果RDD2已经缓存过了,那么就可以直接从RDD2开始,跳过RDD1
RDD缓存的API

RDD缓存的级别

cache和persist的作用是一样的,但是persist可以设置存储级别
存储级别

如何选择存储级别
Spark 的存储级别的选择,核心问题是在memory内存使用率和CPU效率之间进行权衡。建议按下面的过程进行存储级别的选择:
如果您的 RDD适合于默认存储级别(MEMORY_ONLY), leave them that way。这是CPU效率最高的选项,允许RDD 上的操作尽可能快地运行.
如果不是,试着使用MEMORY_ONLY_SER 和 selecting a fast serialization library 以使对象更加节省空间,但仍然能够快速访问。(Java和Scala)
不要溢出到磁盘.除非计算您的数据集的函数是昂贵的,或者它们过滤大量的数据。否则,重新计算分区可能与从磁盘读取分区一样快.
如果需要快速故障恢复,请使用复制的存储级别(例如,如果使用Spark 来服务来自网络应用程序的请求)。All 存储级别通过重新计算丢失的数据来提供完整的容错能力,但复制的数据可让您继续在RDD上运行任务,而无需等待重新计算一个丢失的分区.
Checkpoint
特点
Checkpoint的主要作用是斩断RDD的依赖链,并且将数据存储在可靠的存储引擎中,例如支持分布式存储和副本机制的 HDFS
- 什么是斩断依赖链
1.斩断依赖链是一个非常重要的操作,接下来以HDFS 的 NameNode的原理来举例说明
2.HDFS 的 NameNode 中主要职责就是维护两个文件,一个叫做edits ,另外一个叫做fsimage . edits 中主要存 放EditLog,FsImage保存了当前系统中所有目录和文件的信息.这个 FsImage 其实就是一个Checkpoint.
HDFS的 NameNode维护这两个文件的主要过程是,首先,会由fsimage 文件记录当前系统某个时间点的完整数据,自此之后的数据并不是时刻写入fsimage ,而是将操作记录存储在edits文件中.其次,在一定的触发条件下, edits 会将自身合并进入fsimage .最后生成新的fsimage 文件, edits重置,从新记录这次 fsimage 以后的操作日志.
3.如果不合并edits进入 fsimage会怎样?会导致 edits中记录的日志过长,容易出错.
4.所以当Spark 的一个Job执行流程过长的时候,也需要这样的一个斩断依赖链的过程,使得接下来的计算轻装上阵.
和Cache的区别
Cache 可以把RDD计算出来然后放在内存中,但是RDD的依赖链(相当于NameNode 中的Edits 日志)是不能丢掉的,因为这种缓存是不可靠的,如果出现了一些错误(例如Executor 宕机),这个RDD的容错就只能通过回溯依赖链,重放计算出来.
但是Checkpoint把结果保存在HDFS这类存储中,就是可靠的了,所以可以斩断依赖,如果出错了,则通过复制 HDFS中的文件来实现容错.
- 所以他们的区别主要在以下两点
Checkpoint可以保存数据到HDFS 这类可靠的存储上, Persist 和 Cache只能保存在本地的磁盘和内存中
Checkpoint可以斩断 RDD的依赖链,而 Persist和l Cache不行
因为CheckpointRDD没有向上的依赖链,所以程序结束后依然存在,不会被删除.而Cache 和 persist 会住程序结束后立刻被清除.
Checkpoint的使用
















 2073
2073











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









