







使用MapReduce实现PageRank算法
PageRank算法的介绍
PageRank是什么?
- PageRank(网页排名)是Google提出的算法,用于衡量特定网页相对于搜索引擎索引中的其他网页而言的重要程度,是 Google 对网页重要性、价值的评估。是Google创始人拉里·佩奇和谢尔盖·布林于1997年创造的。PageRank实现了将链接价值概念作为排名因素
- 扩展: PR值的提高可有效提升你的网页在Google搜索引擎中的页面排名,但并不是说PR越高则排名越靠前。有一些网站尽管PR不算高,但却较一些PR高的网站排名还要靠前。所以你应该在对网站优化的同时,也要努力提高网站的PR值。提高PR最佳和最简单的办法在于:
1. 提供有趣、有价值的网站内容,这样站长们会主动和你进行友情链接,从而提高你的外部链接值。
2. 将网站提交到各大搜索引擎,这样可显著改善你的网站在Google上的排名。
3. 可将网站添加到行业门户站点、网上论坛、留言簿等等各种允许添加网址链接的地方。
4. 与其他网站交换链接来提高链接权值。
5. 与其他网站交换链接时首先要查看对方站点是否被Google删除,或是否被Google收录,没有被Google收录的站点最好不要做连接。
方法原理
- 投票算法
作为网络搜索引擎,他们会将全网的网站全部爬取到自己的服务器进行分析。
然后分析出当前页面中到其他网站的外链(出链)
同时也有其他的网站链接到当前网站(入链) - 入链的数量
如果一个页面节点接收到的其他网页指向的入链数量越多,那么这个页面越重要 - 入链的质量
质量高的页面会通过链接向其他页面传递更多的权重
算法过程
1.首先每个网站默认的权重是一样的(十分制,百分制)
2.然后将网站的权重平分给当前网站的所有出链( 10/5 = 2)
3.如果一个网站有多个入链,就将本次所有的入链得分累加到一起(2+4+7+1+10=24分)
4.那么本次的得分会用于计算下次出链的计算(24/5=4.8)
5.重复迭代上面的过程,慢慢达到一个收敛值
6.收敛标准是衡量本次计算精度的有效方法:
6.1.超过99%的网站pr值和上次一样
6.2.所有的pr差值(本次和上次)累加求平均值不超过0.0001
7停止运算
算法公式
站在互联网的角度:只出,不入:PR会为0。
如果只入,不出:PR会很高。
所以直接访问网页: pagerank并不能百分百的表示页面价值,如果是直接访问某个网址的话,就不能像在a标签那样统计对它的点击,但是这种直接访问的方式,也会对页面价值产生影响,因此页面价值的计算不光要考虑入链出链,要考虑综合情况,要修正我们之前的计算方式。
为修正PageRank计算公式,增加阻尼系数在简单公式的基础上增加了阻尼系数(damping factor) d一般取值d=0.85。
完整PageRank计算公式如下
d:阻尼系数
M(i):指向i的页面集合,即给Pi页面做入链的其它页面集合
L(j):页面的出链数,即Mi)的某个页面的出链数
PR(pj): j页面的PR值
n:所有页面数
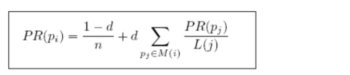
每一个给Pi页面投票(给它做入链的)的页面的页面价值除以出链数
例如有3个页面A、B、C,页面价值分别为1、2、3,出链数分别为4、5、6那么,整个公式结果就是:PR(Pi)=(1-0.85)/3+ 0.85(1/4+2/5+3/6)
前边乘以0.85的意思就是其它页面给它的投票只能起到它85%的比重*
算法的缺点
第一,没有区分站内导航链接。很多网站的首页都有很多对站内其他页面的链接,称为站内导航链接。这些链接与不同网站之间的链接相比,肯定是后者更能体现PageRank值的传递关系。
第二,没有过滤广告链接和功能链接。这些链接通常没有什么实际价值,前者链接到广告页面,后者常常链接到某个社交网站首页。
第三,对新网页不友好。一个新网页的一般入链相对较少,即使它的内容的质量很高,要成为一个高PR值的页面仍需要很长时间的推广。
针对PageRank算法的缺点,有人提出了TrustRank算法。其最初来自于2004年斯坦福大学和雅虎的一项联合研究,用来检测垃圾网站。TrustRank算法的工作原理:先人工去识别高质量的页面(即种子"页面),那么由"种子"页面指向的页面也可能是高质量页面,即其TR值也高,与“种子"页面的链接越远,页面的TR值越低。"种子"页面可选出链数较多的网页,也可选PR值较高的网站
TrustRank算法给出每个网页的TR值。将PR值与TR值结合起来,可以更准确地判断网页的重要性。
简单模型

站在A的角度:A将自己的PR值分给B和D,但是自己都是又接收到C的PR值
其他三个由此推理
如果我们不设置权重并且四个网站的初始PR值都是1,那么第一轮过后,四个网站的PR值,分别变成

代码的实现流程
数据信息

假设这是一串网页,第一个是后面的入链,后面的是第一个的出链
假设每个网页的初始PR都是1
假设我们规定只要一个网站的前一个PR值和后一个PR值的差小于0.001,也就是精确到百分位就算其收敛
第一计数类
这个类是专门用来计数的,计算达到收敛标准的数,也可以计算总网页数,但是这个因为只有四个网页我就没有计算数量。而是直接写了出来
public class Count {
static int count = 0;
public int getCount() {
return count;
}
public void setCount(int count) {
this.count = count;
}
}
自定义类,来解决存储每一行数据
Arrays.copyOfRange(str, 1, str.length)方法是从下标为1的元素到最后复制数组str
StringUtils.join(nearbyNodeName, separater)是在数组的每一个元素中间插入指定分割符
import org.apache.commons.lang.StringUtils;
import java.util.Arrays;
public class Node {
private double pr;
private String[] nearbyNodeName;
private static final char separater = '\t';
//判断是否有出链
public boolean havingNode() {
return (nearbyNodeName != null && nearbyNodeName.length > 0);
}
//重写toString方法
@Override
public String toString() {
StringBuffer sb = new StringBuffer();
sb.append(pr);
//如果有出链
if (havingNode()) {
sb.append(separater);
sb.append(StringUtils.join(nearbyNodeName, separater));
}
return sb.toString();
}
/**
* 如果不是第一次读取,那么就会有pr值,数据的可能是
* A 1.0
* A 1.0 B C
* A 1.0 B
*/
public static Node getNode(String line) throws Exception {
String[] str = StringUtils.split(line, separater);
//如果数组的长度小于1.不符合上面的任何一种情况,所以报错
if (str.length < 1) {
throw new Exception("data error");
}
Node node = new Node();
node.setPr(Double.parseDouble(str[0]));
node.setNearbyNodeName(Arrays.copyOfRange(str, 1, str.length));
return node;
}
/**
* 如果是第一次读取,那么情况和上面的差不多,就是没有pr值,在这里,我们给其默认值为1
*
* @return
*/
public static Node getNode(String pr, String line) throws Exception {
return getNode(pr + separater + line);
}
public double getPr() {
return pr;
}
public void setPr(double pr) {
this.pr = pr;
}
public String[] getNearbyNodeName() {
return nearbyNodeName;
}
public void setNearbyNodeName(String[] nearbyNodeName) {
this.nearbyNodeName = nearbyNodeName;
}
public char getSeparater() {
return separater;
}
}
Mapper阶段
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class MapTest extends Mapper<Text, Text, Text, Text> {
/**
* 数据可能是:<A,B C> <A,1 B C> <A,C>
*
* @param key
* @param value
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(Text key, Text value, Context context) throws IOException, InterruptedException {
try {
//投票页面
String page = key.toString();
//被投票页面
String line = value.toString();
Node node = null;
//这是第一次运行,pr值是默认值1
if (context.getConfiguration().getInt("runCount", 1) == 1) {
node = Node.getNode("1", line);
} else {
node = Node.getNode(line);
}
//写出投票关系
context.write(key, new Text(node.toString()));
//计算投票页面给每个被投票页面的权重
//先判断是否有出链
if (node.havingNode()) {
//有出链,将其pr值平方给出链
double outPr = node.getPr() / node.getNearbyNodeName().length;
for (String nearbyNodeName : node.getNearbyNodeName()) {
//循环其的每一个出链,并且将其输出
context.write(new Text(nearbyNodeName), new Text(String.valueOf(outPr)));
}
} else {
context.write(key, new Text(String.valueOf(node.getPr())));
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
Reduce阶段
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class RedTest extends Reducer<Text, Text, Text, Text> {
/**
* 这里的数据类型可能有如下几种
* A,1 B C
* A,0.5
* A,0.5
* 第一种是他的页面关系
* 第二三种是这个页面被赋予的pr
*
* @param key
* @param values
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
try {
Node orinode = null;
double sum = 0.0;
//先判断数据是哪一种
for (Text v : values) {
Node node = Node.getNode(v.toString());
//如果有临近的链,那么就是第一种数据
if (node.havingNode()) {
orinode = node;
} else {
sum += node.getPr();
}
}
//求出新的pr值
double newPr = (1 - 0.85) / 4 + 0.85 * (sum/orinode.getNearbyNodeName().length);
//求差值,因为是差值所以可以换成绝对值,好比较
double diff = Math.abs(orinode.getPr() - newPr);
//将新的pr值赋给node
orinode.setPr(newPr);
System.out.println();
//如果差值控制在百分位代表稳定
if (diff < 0.001) {
//计算已经收敛的数量
Count.count = Count.count+1;
}
context.write(key, new Text(orinode.toString()));
System.out.println(key+"的pr值:"+orinode.getPr());
} catch (Exception e) {
e.printStackTrace();
}
}
}
Driver阶段
首先我们使用的读取方式是kv,也就是按照第一个分割符将一行数据分成俩部分,第一部分是k,第二部分是v
conf.setInt("runCount", runCount);是在configuration也就是MapReduce程序里面定义了一个全局变量runCount
**
在读取数据的时候,我们只有第一次读取的数据是给的,其他的时候都是读取自己上一次输出的数据
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class DriTest {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
int runCount = 0;
while (true) {
runCount++;
conf.setInt("runCount", runCount);
Job job = Job.getInstance(conf);
job.setJarByClass(DriTest.class);
job.setMapperClass(MapTest.class);
job.setReducerClass(RedTest.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
/** 设置采用KeyValueTextInputFormat来读取数据封装kv对送到mapper的map方法会根据tab分割数据,把分割后的第一个数据当做key,其它当做value*/
job.setInputFormatClass(KeyValueTextInputFormat.class);
Path path = null;
Path out = null;
if (runCount == 1) {
//第一次运行
path = new Path("D:\\MP\\PageRank\\input");
} else {
path = new Path("D:\\MP\\PageRank\\output" + (runCount - 1));
}
FileInputFormat.setInputPaths(job, path);
out = new Path("D:\\MP\\PageRank\\output" + runCount);
if (out.getFileSystem(conf).exists(out)) {
out.getFileSystem(conf).delete(out, true);
}
FileOutputFormat.setOutputPath(job, out);
boolean b = job.waitForCompletion(true);
if (b) {
if (Count.count >= 4) {
break;
}
}
}
}
}
结果
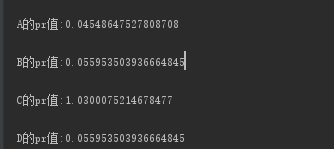















 933
933











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









