









prometheus监控K8S
监控告警功能
alertmanager邮箱告警配置
首先开通SMTP服务,QQ邮箱:设置–帐号–开通POP3/SMTP服务,记住生成的密码(其它邮箱同理)

编辑prometheus的values.yaml文件,配置邮箱告警
[root@master01 prometheus]# vi prometheus/values.yaml
# 定位到alertmanager的配置文件,
alertmanagerFiles:
alertmanager.yml:
global:
resolve_timeout: 5m
# 邮箱告警配置
smtp_hello: 'prometheus'
smtp_from: 'xxx@qq.com'
smtp_smarthost: 'smtp.qq.com:465' # 其它邮箱请填写相应的host
smtp_auth_username: 'xxx@qq.com'
smtp_auth_password: 'xxxxxxxxxxxxxxxx'
smtp_require_tls: false # qq邮箱需要设定
templates:
- '/etc/config/*.tmpl' # 指定告警模板路径
receivers:
- name: email
email_configs:
- to: 'x@qq.com' #接收报警邮箱地址
headers: {"subject":'{{ template "email.header" . }}'}
html: '{{ template "email.html" . }}'
send_resolved: true # 发送报警解除邮件
route:
group_wait: 5s # 分组等待时间
group_interval: 5s # 上下两组发送告警的间隔时间
receiver: email
repeat_interval: 5m # 重复发送告警时间
inhibit_rules: # 告警抑制:当多级别规则同时生效时,只发送最高级别的告警
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname']
template_email.tmpl: |- # 告警模版
{{ define "email.header" }}
{{ if eq .Status "firing"}}[Warning]: {{ range .Alerts }}{{ .Annotations.summary }} {{ end }}{{ end }}
{{ if eq .Status "resolved"}}[Resolved]: {{ range .Alerts }}{{ .Annotations.resolve_summary }} {{ end }}{{ end }}
{{ end }}
{{ define "email.html" }}
{{ if gt (len .Alerts.Firing) 0 -}}
<font color="#FF0000"><h3>[Warning]:</h3></font>
{{ range .Alerts }}
告警级别:{{ .Labels.severity }} <br>
告警类型:{{ .Labels.alertname }} <br>
故障主机: {{ .Labels.instance }} <br>
告警主题: {{ .Annotations.summary }} <br>
告警详情: {{ .Annotations.description }} <br>
触发时间: {{ (.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }} <br>
{{- end }}
{{- end }}
{{ if gt (len .Alerts.Resolved) 0 -}}
<font color="#66CDAA"><h3>[Resolved]:</h3></font>
{{ range .Alerts }}
告警级别:{{ .Labels.severity }} <br>
告警类型:{{ .Labels.alertname }} <br>
故障主机: {{ .Labels.instance }} <br>
告警主题: {{ .Annotations.resolve_summary }} <br>
告警详情: {{ .Annotations.resolve_description }} <br>
触发时间: {{ (.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }} <br>
恢复时间: {{ (.EndsAt.Add 28800e9).Format "2006-01-02 15:04:05" }} <br>
{{- end }}
{{- end }}
{{- end }}
prometheus告警规则配置
接着配置告警规则,以“物理节点状态”为例,先在prometheus控制台测试此条告警规则,确保输出有效:up{component="node-exporter"}
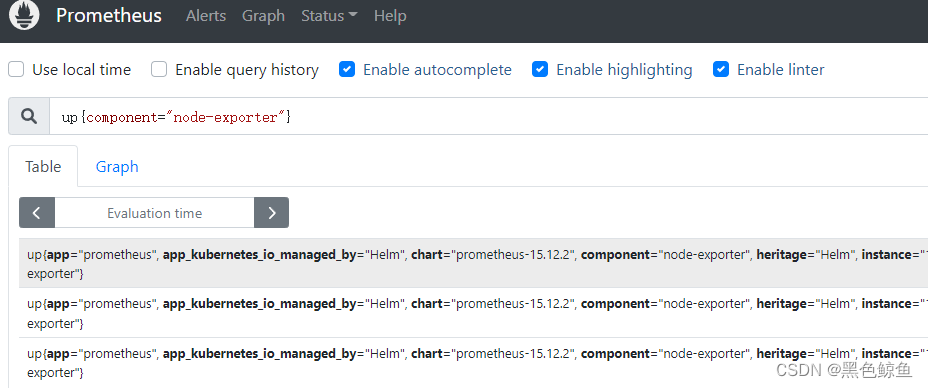
在values中配置告警规则(就在alertmanger的配置文件下方)
serverFiles:
alerting_rules.yml:
groups:
- name: 物理节点状态-监控告警
rules:
- alert: Node-up
expr: up {component="node-exporter"} == 0
for: 2s
labels:
severity: critical
annotations:
summary: "服务器{{ $labels.kubernetes_node }}已停止运行!"
description: "检测到服务器{{ $labels.kubernetes_node }}已异常停止,IP: {{ $labels.instance }},请排查!"
resolve_summary: "服务器{{ $labels.kubernetes_node }}已恢复运行!"
resolve_description: "服务器{{ $labels.kubernetes_node }}已恢复运行,IP: {{ $labels.instance }}。"
更新prometheus
编辑完成后,更新prometheus
每次增加规则中都需要upgrage,更新后pod中的“configmap-reload”容器会重载配置文件,可能需要等待几分钟
[root@master01 ]# helm upgrade prometheus -n prometheus .
查询alertmanger的配置文件是否更新(server同理):
[root@master01 prometheus]# kubectl logs -f -n prometheus prometheus-alertmanager-7757db759b-9nq9c prometheus-alertmanager

查询server的configmap(alertmanger同理)
[root@master01 prometheus]# kubectl get configmap -n prometheus
[root@master01 prometheus]# kubectl describe configmaps -n prometheus prometheus-server

在alert控制台查看告警规则是否生效:
告警测试
关掉其中一台节点测试
可观察到Alert中,该告警规则状态由Inactive转到Pending再到Firing,而当状态转为Firing,将发送告警邮件
Pending到Firing的变化默认为1分钟,若想缩短时间,请修改value.yaml中的server.global.scrape_interval字段,如15s
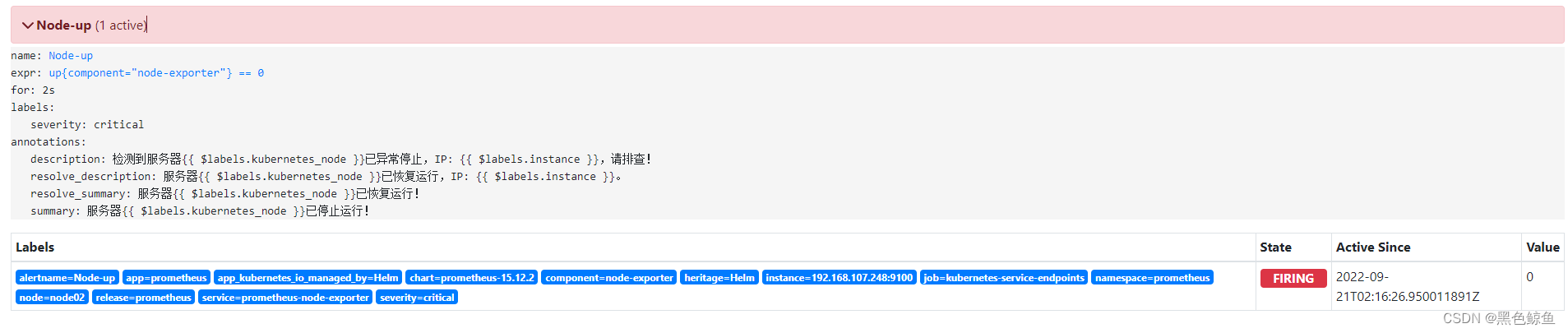
告警邮件

附告警规则
部分参考自阿里云Prometheus监控报警规则
K8S组件状态
target状态
sum by (instance,job) (up)
CPU使用率
round (sum by (instance,job) (rate(process_cpu_seconds_total[2m]) * 100)) > 80
句柄数
sum by (instance,job) (process_open_fds) > 600
虚拟内存
sum by (instance,job) (round(process_virtual_memory_bytes/1024/1024)) > 4096
集群资源状态
资源限制:总CPU资源过载(超过80%)
集群 CPU 过度使用,CPU 已经过度使用无法容忍节点故障
round(sum(kube_pod_container_resource_requests{resource=“cpu”}) / sum(kube_node_status_allocatable{resource=“cpu”})*100) > 80
资源限制:总内存资源过载(超过80%)
集群内存过度使用,内存已经过度使用无法容忍节点故障
round(sum(kube_pod_container_resource_requests{resource=“memory”}) / sum(kube_node_status_allocatable{resource=“memory”})100) > 80
KubeletTooManyPods(Pod过多)
max(max(kubelet_running_pods) by(instance) * on(instance) group_left(node) kubelet_node_name) by(node) / max(kube_node_status_capacity{resource=“pods”} != 1) by(node) > 0.9
Node资源状态
CPU使用率
round((1 - avg(rate(node_cpu_seconds_total{component=“node-exporter”,mode=“idle”}[5m])) by (instance)) * 100)
内存
round((1 - (node_memory_MemAvailable_bytes / (node_memory_MemTotal_bytes))) 100)
剩余容量
(round((node_filesystem_avail_bytes{fstype=~“ext4|xfs”} / node_filesystem_size_bytes{fstype=~“ext4|xfs”}) * 100 < 30 ) and node_filesystem_readonly{fstype=~“ext4|xfs”} == 0)
预测剩余容量
( round(predict_linear(node_filesystem_avail_bytes{fstype=~“ext4|xfs”}[24h], 7246060)/1024/1024/1024) < 30 and node_filesystem_readonly{fstype=~“ext4|xfs”} == 0 )
节点磁盘的IO使用率
100-(avg(rate(node_disk_io_time_seconds_total[2m])) by(instance) 100) < 80
NodeNetworkReceiveErrs(Node网络接收错误)
sum (increase(node_network_receive_errs_total[2m])) by (instance) > 10
NodeNetworkTransmitErrs(Node网络传输错误)
sum (increase(node_network_transmit_errs_total[2m])) by (instance) > 10
入网流量带宽
持续5分钟高于100M
((sum(rate (node_network_receive_bytes_total{device!~‘tap.|veth.|br.|docker.|virbr*|lo*’}[5m])) by (instance)) /102400) > 100
出网流量带宽
((sum(rate (node_network_transmit_bytes_total{device!~‘tap.|veth.|br.|docker.|virbr*|lo*’}[5m])) by (instance))/102400) > 100
TCP_ESTABLISHED过高
node_netstat_Tcp_CurrEstab > 1000
Pod
PodCpu75(Pod的CPU使用率大于75%)
container!=“POD”, container!=“”}[2m]
{name=~“.+”}:筛选,避免重复指标
round(100*(sum(rate(container_cpu_usage_seconds_total {name=~“.+”}[2m])) by (namespace,pod) / sum(kube_pod_container_resource_limits{resource=“cpu”}) by (namespace,pod))) > 75
PodMemory75(Pod的内存使用率大于75%)
100 * sum(container_memory_working_set_bytes{name=~“.+”}) by (namespace,pod) / sum(kube_pod_container_resource_limits {resource=“memory”}) by (namespace,pod) > 75
pod_status_no_running(Pod的状态为未运行)
sum (kube_pod_status_phase{phase!=“Running”}) by (namespace,pod,phase) > 0
PodMem4GbRestart(Pod的内存大于4096MB)
(sum (container_memory_working_set_bytes{name=~“.+”})by (namespace,pod,container_name) /1024/1024) > 4096
PodRestart(Pod重启)
{pod!~“aws-load-balancer-controller.*”}
sum (round(increase (kube_pod_container_status_restarts_total[5m]))) by (namespace,pod) > 0
KubePodCrashLooping(Pod出现循环崩溃)
rate(kube_pod_container_status_restarts_total{app_kubernetes_io_name=“kube-state-metrics”}[15m]) * 60 * 5 > 0
KubePodNotReady(Pod未准备好)
sum by (namespace, pod) (max by(namespace, pod) (kube_pod_status_phase{app_kubernetes_io_name=“kube-state-metrics”, phase=~“Pending|Unknown”}) * on(namespace, pod) group_left(owner_kind) max by(namespace, pod, owner_kind) (kube_pod_owner{owner_kind!=“Job”})) > 0
KubeContainerWaiting(容器等待)
sum by (namespace, pod, container) (kube_pod_container_status_waiting{app_kubernetes_io_name=“kube-state-metrics”}) > 0
Deployment
KubeDeploymentGenerationMismatch(出现部署集版本不匹配)
kube_deployment_status_observed_generation{app_kubernetes_io_name=“kube-state-metrics”} != kube_deployment_metadata_generation{app_kubernetes_io_name=“kube-state-metrics”}
KubeDeploymentReplicasMismatch(出现部署集副本不匹配)
( kube_deployment_spec_replicas{app_kubernetes_io_name=“kube-state-metrics”} != kube_deployment_status_replicas_available{app_kubernetes_io_name=“kube-state-metrics”} ) and ( changes(kube_deployment_status_replicas_updated{app_kubernetes_io_name=“kube-state-metrics”}[5m]) == 0 )
检测到部署集有更新
sum by (namespace, deployment) (changes(kube_deployment_status_observed_generation{app_kubernetes_io_name=“kube-state-metrics”}[5m])) > 0
StatefulSet
KubeStatefulSetGenerationMismatch(状态集版本不匹配)
kube_statefulset_status_observed_generation{app_kubernetes_io_name=“kube-state-metrics”} != kube_statefulset_metadata_generation{app_kubernetes_io_name=“kube-state-metrics”}
KubeStatefulSetReplicasMismatch(状态集副本不匹配)
( kube_statefulset_status_replicas_ready{app_kubernetes_io_name=“kube-state-metrics”} != kube_statefulset_status_replicas{app_kubernetes_io_name=“kube-state-metrics”} ) and ( changes(kube_statefulset_status_replicas_updated{app_kubernetes_io_name=“kube-state-metrics”}[5m]) == 0 )
检测到状态集有更新
sum by (namespace, statefulset) (changes(kube_statefulset_status_observed_generation{app_kubernetes_io_name=“kube-state-metrics”}[5m]))
PV&PVC
KubePersistentVolumeFillingUp(块存储PVC容量即将不足)
sum by (namespace,persistentvolumeclaim) (round(kubelet_volume_stats_available_bytes / kubelet_volume_stats_capacity_bytes*100)) < 20
KubePersistentVolumeErrors(PV容量出错)
sum by (persistentvolume) (kube_persistentvolume_status_phase{phase=~“Failed|Pending”,app_kubernetes_io_name=“kube-state-metrics”}) > 0
KubePersistentVolumeFillingUp(PVC空间耗尽预测)
通过PVC资源使用6小时变化率预测 接下来4天的磁盘使用率
(kubelet_volume_stats_available_bytes / kubelet_volume_stats_capacity_bytes ) < 0.4 and predict_linear(kubelet_volume_stats_available_bytes[6h], 4 * 24















 2663
2663











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









