






第一部分、K近邻算法
1.1、什么是K近邻算法
在使用k近邻法进行分类时,对新的实例,根据其k个最近邻的训练实例的类别,通过多数表决的方式进行预测。由于k近邻模型的特征空间一般是n维实数向量,所以距离的计算通常采用的是欧式距离。关键的是k值的选取,如果k值太小就意味着整体模型变得复杂,容易发生过拟合,即如果邻近的实例点恰巧是噪声,预测就会出错,极端的情况是k=1,称为最近邻算法,对于待预测点x,与x最近的点决定了x的类别。k值得增大意味着整体的模型变得简单,极端的情况是k=N,那么无论输入实例是什么,都简单地预测它属于训练集中最多的类,这样的模型过于简单。经验是,k值一般去一个比较小的值,通常采取交叉验证的方法来选取最优的k值。
1.2、近邻的距离度量表示法
因为特征空间中两个实例点的距离可以反应出两个实例点之间的相似性程度。K近邻模型的特征空间一般是n维实数向量空间,使用的距离可以使欧式距离,也是可以是其它距离,既然扯到了距离,下面就来具体阐述下都有哪些距离度量的表示法,权当扩展。
- 1. 欧氏距离,最常见的两点之间或多点之间的距离表示法,又称之为欧几里得度量,它定义于欧几里得空间中,如点 x = (x1,...,xn) 和 y = (y1,...,yn) 之间的距离为:
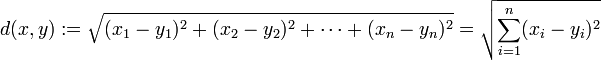
(1)二维平面上两点a(x1,y1)与b(x2,y2)间的欧氏距离:
(2)三维空间两点a(x1,y1,z1)与b(x2,y2,z2)间的欧氏距离:
(3)两个n维向量a(x11,x12,…,x1n)与 b(x21,x22,…,x2n)间的欧氏距离:
也可以用表示成向量运算的形式:
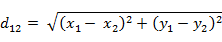
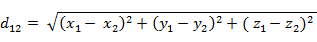
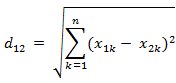
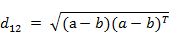
- 2. 曼哈顿距离,我们可以定义曼哈顿距离的正式意义为L1-距离或城市区块距离,也就是在欧几里得空间的固定直角坐标系上两点所形成的线段对轴产生的投影的距离总和。例如在平面上,坐标(x1, y1)的点P1与坐标(x2, y2)的点P2的曼哈顿距离为:
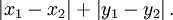 ,要注意的是,曼哈顿距离依赖座标系统的转度,而非系统在座标轴上的平移或映射。
,要注意的是,曼哈顿距离依赖座标系统的转度,而非系统在座标轴上的平移或映射。
(1)二维平面两点a(x1,y1)与b(x2,y2)间的曼哈顿距离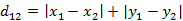 (2)两个n维向量a(x11,x12,…,x1n)与 b(x21,x22,…,x2n)间的曼哈顿距离
(2)两个n维向量a(x11,x12,…,x1n)与 b(x21,x22,…,x2n)间的曼哈顿距离
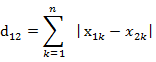
实现k近邻法时,主要考虑的问题是如何对训练数据进行快速k近邻搜索,这点在特征空间的维数大以及训练数据容量大时尤其重要。k近邻法的最简单实现是线性扫描,这时要计算输入实例与每一个训练实例的距离,当训练集很大时,计算非常耗时,这种方法是不可行的。为了提高k近邻搜索的效率,可以考虑使用特殊的结构存储训练数据,以减少计算距离的次数。具体方法有很多,这里介绍kd树方法。
第二部分、K近邻算法的实现:KD树
2.1、什么是KD树
Kd-树是K-dimension tree的缩写,是对数据点在k维空间(如二维(x,y),三维(x,y,z),k维(x1,y,z..))中划分的一种数据结构,主要应用于多维空间关键数据的搜索(如:范围搜索和最近邻搜索)。本质上说,Kd-树就是一种平衡二叉树。
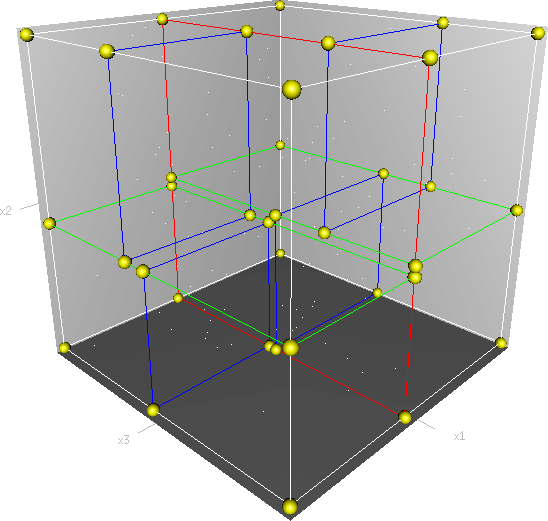
首先必须搞清楚的是,k-d树是一种空间划分树,说白了,就是把整个空间划分为特定的几个部分,然后在特定空间的部分内进行相关搜索操作。想像一个三维(多维有点为难你的想象力了)空间,kd树按照一定的划分规则把这个三维空间划分了多个空间,如下图所示:
2.2、KD树的构建
kd树构建的伪代码如下图所示:
Kd-树是一个二叉树,每个节点表示的是一个空间范围。下表表示的是Kd-树中每个节点中主要包含的数据结构。
Range域表示的是节点包含的空间范围。
Node-data域就是数据集中的某一个n维数据点。分割超面是通过数据点Node-Data并垂直于轴split的平面,分割超面将整个空间分割成两个子空间。
令split域的值为i,如果空间Range中某个数据点的第i维数据小于Node-Data[i],那么,它就属于该节点空间的左子空间,否则就属于右子空间。
Left,Right域分别表示由左子空间和右子空间空的数据点构成的Kd-树。
|
域名
|
数据类型
|
描述
|
|
Node-data
|
数据矢量
|
数据集中某个数据点,是n维矢量(这里也就是k维)
|
|
Range
|
空间矢量
|
该节点所代表的空间范围
|
|
split
|
整数
|
垂直于分割超平面的方向轴序号
|
|
Left
|
k-d树
|
由位于该节点分割超平面左子空间内所有数据点所构成的k-d树
|
|
Right
|
k-d树
|
由位于该节点分割超平面右子空间内所有数据点所构成的k-d树
|
|
parent
|
k-d树
|
父节点
|
构建k-d树的算法实现
算法:构建k-d树(createKDTree)
输入:数据点集Data-set 和 其所在的空间Range
输出:Kd,类型为k-d tree
1、If Data-set为空,则返回空的k-d tree
2、调用节点生成程序:
(1)确定split域:对于所有描述子数据(特征矢量),统计它们在每个维上的数据方差。以SURF特征为例,描述子为64维,可计算64个方差。挑选出最大值,对应的维就是split域的值。数据方差大表明沿该坐标轴方向上的数据分散得比较开,在这个方向上进行数据分割有较好的分辨率;
(2)确定Node-data域:数据点集Data-set按其第split域的值排序。位于正中间的那个数据点被选为Node-data。此时新的Data-set' = Data-set\Node-data(除去其中Node-data这一点)。
3、dataleft = {d属于Data-set' && d[split] ≤ Node-data[split]} Left_Range = {Range && dataleft}
把剩下的点分离,左边的是split坐标轴上的值比 Node-data[split]小的点
dataright = {d属于Data-set' && d[split] > Node-data[split]} Right_Range = {Range && dataright}
右边的是split坐标轴上的值比 Node-data[split]大的点
4.、left = 由(dataleft,Left_Range)建立的k-d tree,即递归调用createKDTree(dataleft,Left_Range)。并设置left的parent域为Kd;
right = 由(dataright,Right_Range)建立的k-d tree,即调用createKDTree(dataright,Right_Range)。并设置right的parent域为Kd。
再举一个简单直观的实例来介绍k-d树构建算法。假设有6个二维数据点{(2,3),(5,4),(9,6),(4,7),(8,1),(7,2)},数据点位于二维空间内,如下图所示。为了能有效的找到最近邻,k-d树采用分而治之的思想,即将整个空间划分为几个小部分,首先,粗黑线将空间一分为二,然后在两个子空间中,细黑直线又将整个空间划分为四部分,最后虚黑直线将这四部分进一步划分。
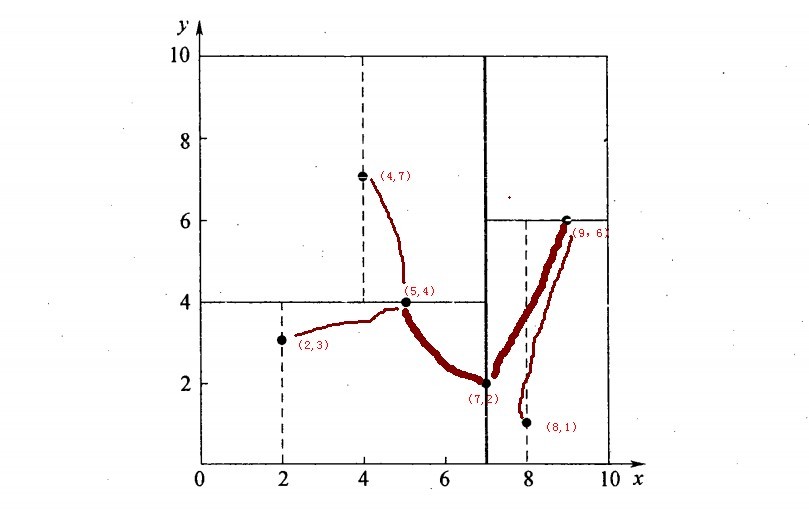
6个二维数据点{(2,3),(5,4),(9,6),(4,7),(8,1),(7,2)}构建kd树的具体步骤为:
- 确定:split域=x。具体是:6个数据点在x,y维度上的数据方差分别为39,28.63,所以在x轴上方差更大,故split域值为x;
- 确定:Node-data = (7,2)。具体是:根据x维上的值将数据排序,6个数据的中值(所谓中值,即中间大小的值)为7,所以Node-data域位数据点(7,2)。这样,该节点的分割超平面就是通过(7,2)并垂直于:split=x轴的直线x=7;
- 确定:左子空间和右子空间。具体是:分割超平面x=7将整个空间分为两部分:x<=7的部分为左子空间,包含3个节点={(2,3),(5,4),(4,7)};另一部分为右子空间,包含2个节点={(9,6),(8,1)};
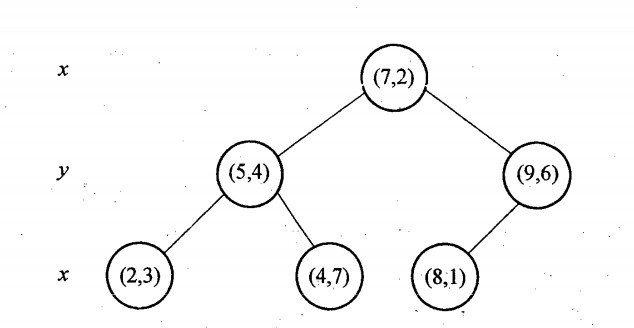
与此同时,经过对上面所示的空间划分之后,我们可以看出,点(7,2)可以为根结点,从根结点出发的两条红粗斜线指向的(5,4)和(9,6)则为根结点的左右子结点,而(2,3),(4,7)则为(5,4)的左右孩子(通过两条细红斜线相连),最后,(8,1)为(9,6)的左孩子(通过细红斜线相连)。如此,便形成了下面这样一棵k-d树:
k-d树的数据结构

针对上表给出的kd树的数据结构,转化成具体代码如下所示(注,本文以下代码分析基于Rob Hess维护的sift库):
- /** a node in a k-d tree */
- struct kd_node
- {
- int ki; /**< partition key index *///关键点直方图方差最大向量系列位置
- double kv; /**< partition key value *///直方图方差最大向量系列中最中间模值
- int leaf; /**< 1 if node is a leaf, 0 otherwise */
- struct feature* features; /**< features at this node */
- int n; /**< number of features */
- struct kd_node* kd_left; /**< left child */
- struct kd_node* kd_right; /**< right child */
- };
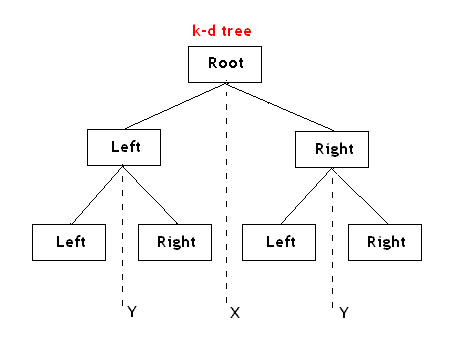
也就是说,如之前所述,kd树中,kd代表k-dimension,每个节点即为一个k维的点。每个非叶节点可以想象为一个分割超平面,用垂直于坐标轴的超平面将空间分为两个部分,这样递归的从根节点不停的划分,直到没有实例为止。经典的构造k-d tree的规则如下:
- 随着树的深度增加,循环的选取坐标轴,作为分割超平面的法向量。对于3-d tree来说,根节点选取x轴,根节点的孩子选取y轴,根节点的孙子选取z轴,根节点的曾孙子选取x轴,这样循环下去。
- 每次均为所有对应实例的中位数的实例作为切分点,切分点作为父节点,左右两侧为划分的作为左右两子树。
对于n个实例的k维数据来说,建立kd-tree的时间复杂度为O(k*n*logn)。
以下是构建k-d树的代码:
- struct kd_node* kdtree_build( struct feature* features, int n )
- {
- struct kd_node* kd_root;
- if( ! features || n <= 0 )
- {
- fprintf( stderr, "Warning: kdtree_build(): no features, %s, line %d\n",
- __FILE__, __LINE__ );
- return NULL;
- }
- //初始化
- kd_root = kd_node_init( features, n ); //n--number of features,initinalize root of tree.
- expand_kd_node_subtree( kd_root ); //kd tree expand
- return kd_root;
- }
上面的涉及初始化操作的两个函数kd_node_init,及expand_kd_node_subtree代码分别如下所示
- static struct kd_node* kd_node_init( struct feature* features, int n )
- { //n--number of features
- struct kd_node* kd_node;
- kd_node = (struct kd_node*)(malloc( sizeof( struct kd_node ) ));
- memset( kd_node, 0, sizeof( struct kd_node ) ); //0填充
- kd_node->ki = -1; //???????
- kd_node->features = features;
- kd_node->n = n;
- return kd_node;
- }
- static void expand_kd_node_subtree( struct kd_node* kd_node )
- {
- /* base case: leaf node */
- if( kd_node->n == 1 || kd_node->n == 0 )
- { //叶节点 //伪叶节点
- kd_node->leaf = 1;
- return;
- }
- assign_part_key( kd_node ); //get ki,kv
- partition_features( kd_node ); //creat left and right children,特征点ki位置左树比右树模值小,kv作为分界模值
- //kd_node中关键点已经排序,在ki维度上 比kd_node值小的 大的分开 并给kd_left kd_right赋值 为各自集合中的中位数
- if( kd_node->kd_left )
- expand_kd_node_subtree( kd_node->kd_left );
- if( kd_node->kd_right )
- expand_kd_node_subtree( kd_node->kd_right );
- }
构建完kd树之后,如今进行最近邻搜索呢?从下面的动态gif图中,你是否能看出些许端倪呢?

k-d树算法可以分为两大部分,除了上部分有关k-d树本身这种数据结构建立的算法,另一部分是在建立的k-d树上各种诸如插入,删除,查找(最邻近查找)等操作涉及的算法。下面,咱们依次来看kd树的插入、删除、查找操作。
2.5、KD树的最近邻搜索算法
现实生活中有许多问题需要在多维数据的快速分析和快速搜索,对于这个问题最常用的方法是所谓的kd树。在k-d树中进行数据的查找也是特征匹配的重要环节,其目的是检索在k-d树中与查询点距离最近的数据点。在一个N维的笛卡儿空间在两个点之间的距离是由下述公式确定:
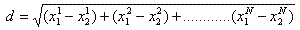
2.5.1、k-d树查询算法的伪代码
k-d树查询算法的伪代码如下所示:
- 算法:k-d树最邻近查找
- 输入:Kd, //k-d tree类型
- target //查询数据点
- 输出:nearest, //最邻近数据点
- dist //最邻近数据点和查询点间的距离
- 1. If Kd为NULL,则设dist为infinite并返回
- 2. //进行二叉查找,生成搜索路径
- Kd_point = &Kd; //Kd-point中保存k-d tree根节点地址
- nearest = Kd_point -> Node-data; //初始化最近邻点
- while(Kd_point)
- push(Kd_point)到search_path中; //search_path是一个堆栈结构,存储着搜索路径节点指针
- If Dist(nearest,target) > Dist(Kd_point -> Node-data,target)
- nearest = Kd_point -> Node-data; //更新最近邻点
- Min_dist = Dist(Kd_point,target); //更新最近邻点与查询点间的距离 ***/
- s = Kd_point -> split; //确定待分割的方向
- If target[s] <= Kd_point -> Node-data[s] //进行二叉查找
- Kd_point = Kd_point -> left;
- else
- Kd_point = Kd_point ->right;
- End while
- 3. //回溯查找
- while(search_path != NULL)
- back_point = 从search_path取出一个节点指针; //从search_path堆栈弹栈
- s = back_point -> split; //确定分割方向
- If Dist(target[s],back_point -> Node-data[s]) < Max_dist //判断还需进入的子空间
- If target[s] <= back_point -> Node-data[s]
- Kd_point = back_point -> right; //如果target位于左子空间,就应进入右子空间
- else
- Kd_point = back_point -> left; //如果target位于右子空间,就应进入左子空间
- 将Kd_point压入search_path堆栈;
- If Dist(nearest,target) > Dist(Kd_Point -> Node-data,target)
- nearest = Kd_point -> Node-data; //更新最近邻点
- Min_dist = Dist(Kd_point -> Node-data,target); //更新最近邻点与查询点间的距离的
- End while
读者来信点评@yhxyhxyhx,在“将Kd_point压入search_path堆栈;”这行代码后,应该是调到步骤2再往下走二分搜索的逻辑一直到叶结点,我写了一个递归版本的二维kd tree的搜索函数你对比的看看:
- void innerGetClosest(NODE* pNode, PT point, PT& res, int& nMinDis)
- {
- if (NULL == pNode)
- return;
- int nCurDis = abs(point.x - pNode->pt.x) + abs(point.y - pNode->pt.y);
- if (nMinDis < 0 || nCurDis < nMinDis)
- {
- nMinDis = nCurDis;
- res = pNode->pt;
- }
- if (pNode->splitX && point.x <= pNode->pt.x || !pNode->splitX && point.y <= pNode->pt.y)
- innerGetClosest(pNode->pLft, point, res, nMinDis);
- else
- innerGetClosest(pNode->pRgt, point, res, nMinDis);
- int rang = pNode->splitX ? abs(point.x - pNode->pt.x) : abs(point.y - pNode->pt.y);
- if (rang > nMinDis)
- return;
- NODE* pGoInto = pNode->pLft;
- if (pNode->splitX && point.x > pNode->pt.x || !pNode->splitX && point.y > pNode->pt.y)
- pGoInto = pNode->pRgt;
- innerGetClosest(pGoInto, point, res, nMinDis);
- }
下面,以两个简单的实例(例子来自图像局部不变特性特征与描述一书)来描述最邻近查找的基本思路。
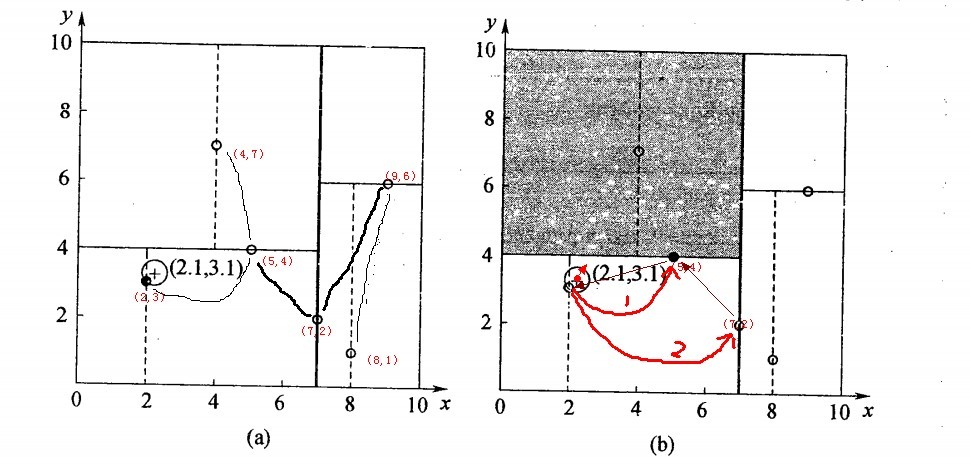
2.5.2、举例:查询点(2.1,3.1)
星号表示要查询的点(2.1,3.1)。通过二叉搜索,顺着搜索路径很快就能找到最邻近的近似点,也就是叶子节点(2,3)。而找到的叶子节点并不一定就是最邻近的,最邻近肯定距离查询点更近,应该位于以查询点为圆心且通过叶子节点的圆域内。为了找到真正的最近邻,还需要进行相关的‘回溯'操作。也就是说,算法首先沿搜索路径反向查找是否有距离查询点更近的数据点。
以查询(2.1,3.1)为例:
- 二叉树搜索:先从(7,2)点开始进行二叉查找,然后到达(5,4),最后到达(2,3),此时搜索路径中的节点为<(7,2),(5,4),(2,3)>,首先以(2,3)作为当前最近邻点,计算其到查询点(2.1,3.1)的距离为0.1414,
- 回溯查找:在得到(2,3)为查询点的最近点之后,回溯到其父节点(5,4),并判断在该父节点的其他子节点空间中是否有距离查询点更近的数据点。以(2.1,3.1)为圆心,以0.1414为半径画圆,如下图所示。发现该圆并不和超平面y = 4交割,因此不用进入(5,4)节点右子空间中(图中灰色区域)去搜索;
- 最后,再回溯到(7,2),以(2.1,3.1)为圆心,以0.1414为半径的圆更不会与x = 7超平面交割,因此不用进入(7,2)右子空间进行查找。至此,搜索路径中的节点已经全部回溯完,结束整个搜索,返回最近邻点(2,3),最近距离为0.1414。
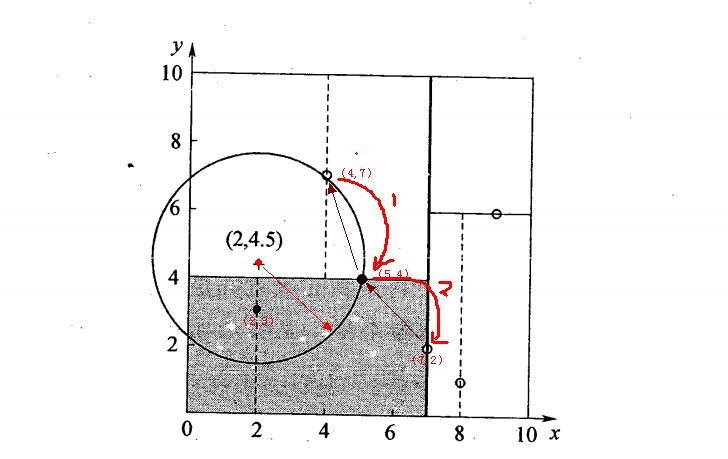
2.5.3、举例:查询点(2,4.5)
一个复杂点了例子如查找点为(2,4.5),具体步骤依次如下:
- 同样先进行二叉查找,先从(7,2)查找到(5,4)节点,在进行查找时是由y = 4为分割超平面的,由于查找点为y值为4.5,因此进入右子空间查找到(4,7),形成搜索路径<(7,2),(5,4),(4,7)>,但(4,7)与目标查找点的距离为3.202,而(5,4)与查找点之间的距离为3.041,所以(5,4)为查询点的最近点;
- 以(2,4.5)为圆心,以3.041为半径作圆,如下图所示。可见该圆和y = 4超平面交割,所以需要进入(5,4)左子空间进行查找,也就是将(2,3)节点加入搜索路径中得<(7,2),(2,3)>;于是接着搜索至(2,3)叶子节点,(2,3)距离(2,4.5)比(5,4)要近,所以最近邻点更新为(2,3),最近距离更新为1.5;
- 回溯查找至(5,4),直到最后回溯到根结点(7,2)的时候,以(2,4.5)为圆心1.5为半径作圆,并不和x = 7分割超平面交割,如下图所示。至此,搜索路径回溯完,返回最近邻点(2,3),最近距离1.5。
上述两次实例表明,当查询点的邻域与分割超平面两侧空间交割时,需要查找另一侧子空间,导致检索过程复杂,效率下降。
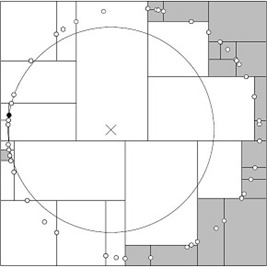
研究表明N个节点的K维k-d树搜索过程时间复杂度为:tworst=O(kN1-1/k)。
同时,以上为了介绍方便,讨论的是二维或三维情形。但在实际的应用中,如SIFT特征矢量128维,SURF特征矢量64维,维度都比较大,直接利用k-d树快速检索(维数不超过20)的性能急剧下降,几乎接近贪婪线性扫描。假设数据集的维数为D,一般来说要求数据的规模N满足N»2D,才能达到高效的搜索。所以这就引出了一系列对k-d树算法的改进:BBF算法,和一系列M树、VP树、MVP树等高维空间索引树(下文2.6节kd树近邻搜索算法的改进:BBF算法,与球树、M树、VP树、MVP树),参考http://blog.csdn.net/v_JULY_v/article/details/8203674。















 983
983











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









