









Python版CUDA入门学习笔记
-
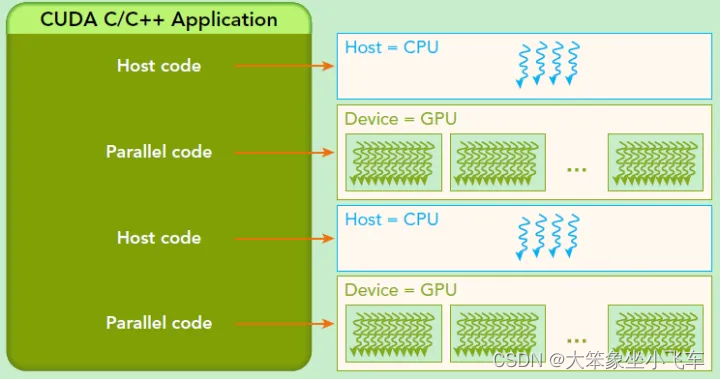
由NVIDIA公司发布,是基于CPU和GPU的异构计算架构,通过PCLe总线连接,基于GPU的并行计算引擎来完成更复杂的计算难题
-
GPU不是一个独立运行的计算平台,可以看成是CPU的协助处理器(CPU所在位置称为主机端host,而GPU所在位置为设备端device)
-
CPU负责处理逻辑复杂的串行程序,GPU重点处理数据密集型的并行计算程序
-
Numba:Python版CUDA
-
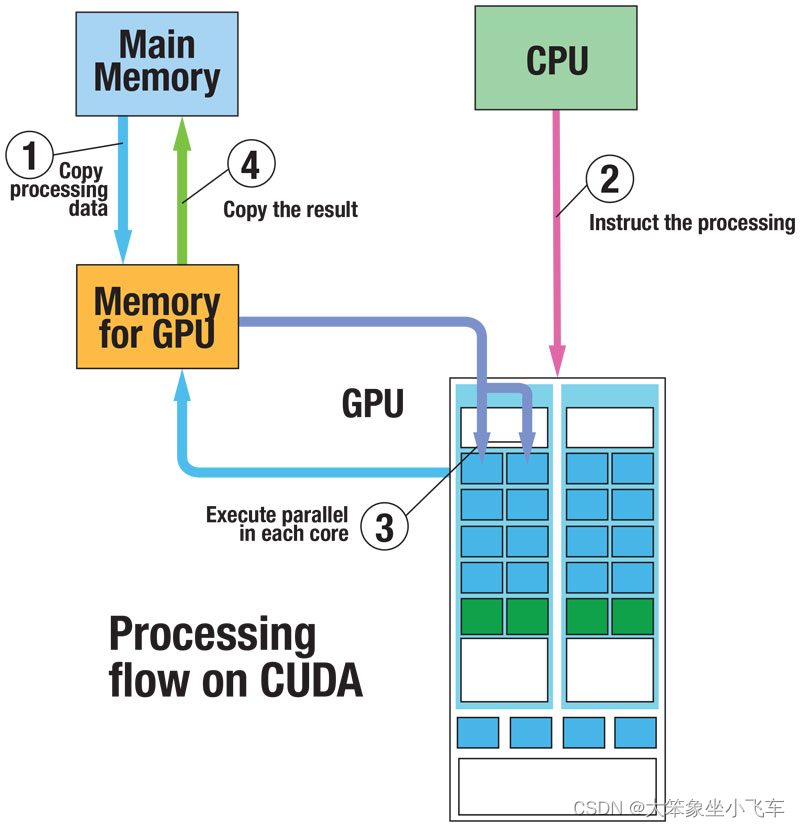
传统CPU计算流程:1、初始化,2、CPU计算,3、得到计算结果
-
在CUDA编程中,引入GPU后,计算流程编程:1、初始化,并将必要的数据拷贝到GPU设备的显存上,2、CPU调用GPU函数,启动GPU多个核心同时进行计算,3、CPU与GPU异步计算,4、将GPU计算结果拷贝回主机端,得到计算结果
-
一个名为gpu_print.py的GPU程序如下:
from numba import cuda
def cpu_print()
print("print by cpu.")
@cuda.jit
def gpu_print():
# GPU核函数
print("print by gpu.")
def main():
gpu_print[1, 2]()
cuda.synchronize()
cpu_print()
if __name__== "__main__":
main()
- 使用CUDA_VISIBLE_DEVICES=‘0’ python gpu_print.py执行这段代码
- 在GPU核函数上添加@cuda.jit装饰符,表示该函数是一个在GPU上运行的函数,GPU函数又被称作核函数
- GPU核函数的启动方式是异步。必要时需要调用cuda.synchronize()来来告知CPU等待GPU执行完核函数后再进行CPU端后续计算,此过程称为同步
- CUDA将核函数所定义的运算称为线程(thread),多个线程组成一个块(block),多个块组成网格(grid)。用blockDim.x和gridDim.x两个参数来控制block和grid的大小。thread、block、grid的索引均由0开始,某个thread在整个grid中的位置编号为:idx = cuda.threadIdx.x + cuda.blockIdx.x * cuda.blockDim.x
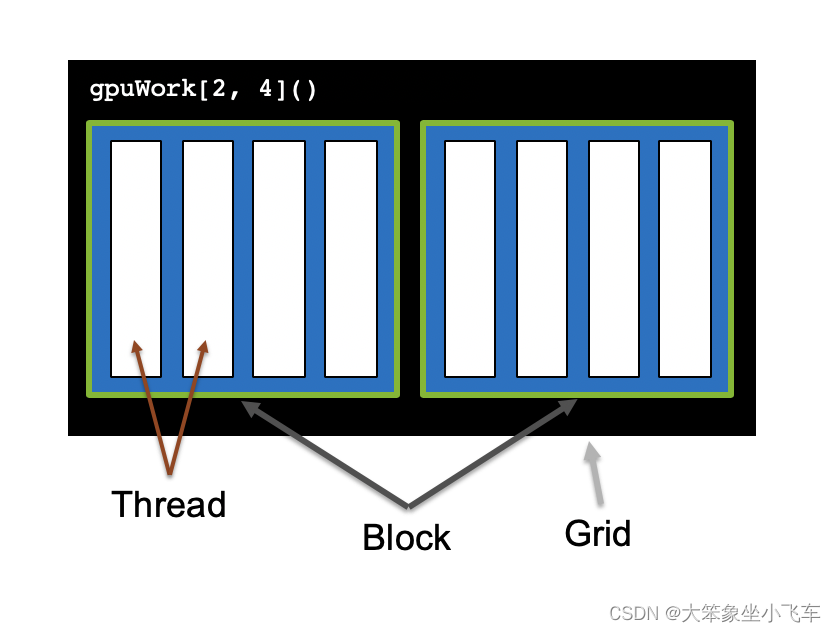
- 应用:互不依赖的CPU函数for循环非常适合放到CUDA thread里做并行计算















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









