









昨天以 StatFilter 分析了责任链模式,今天还以 StatFilter 来举例。
StatFilter 就是用来统计数据,用来支撑 Druid 监控的。
其实大概看一下 StatFilter 的结构,可以看到有很多 public 方法,第一个参数是 FilterChain,并且代码实现都是使用调用过滤器的同名方法,
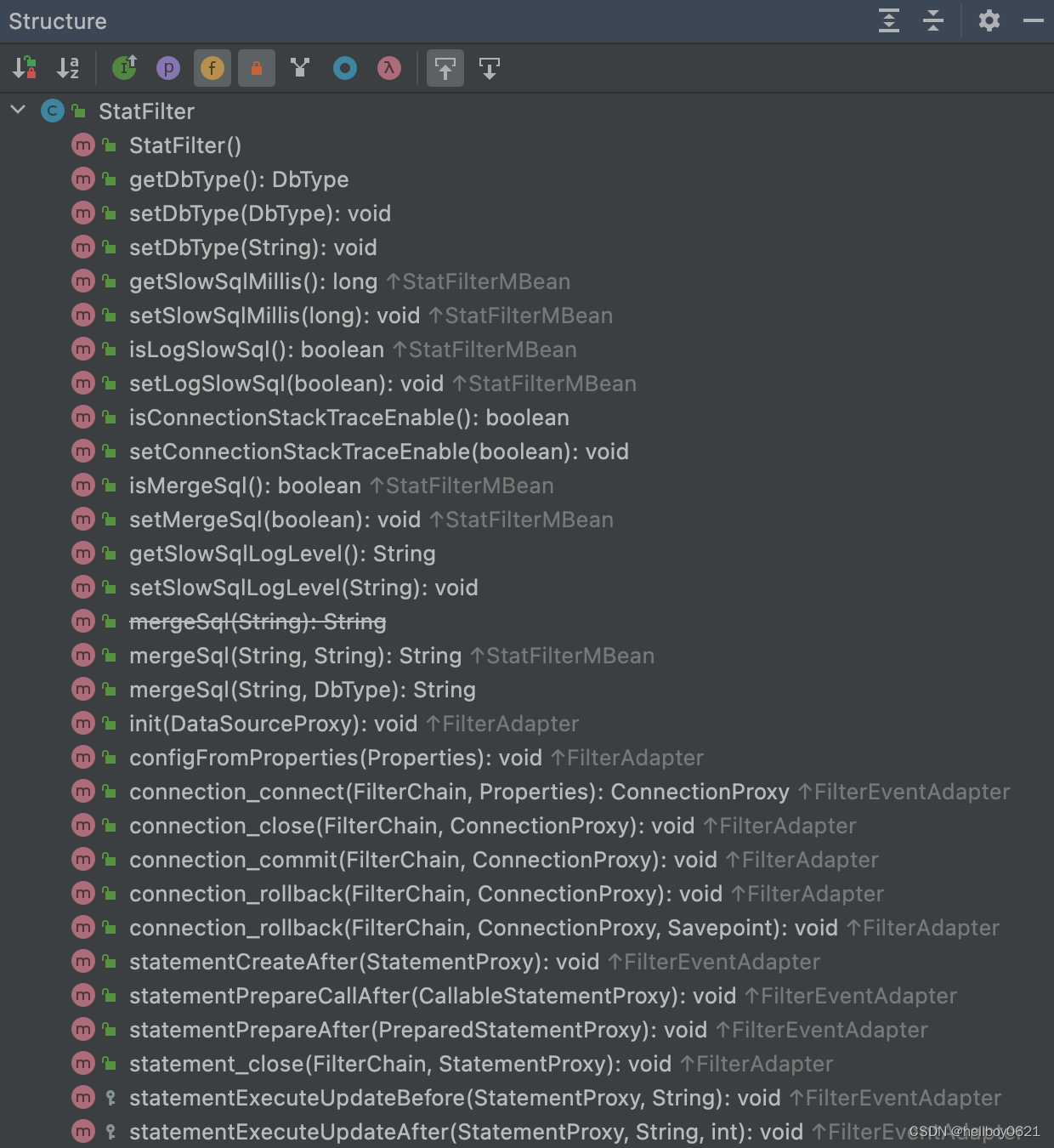
过滤方法有很多,除了昨天介绍的 dataSource_getConnection,再举个例子:
@Override
public void connection_commit(FilterChain chain, ConnectionProxy connection) throws SQLException {
// 调用过滤器链的下一个节点的 connection_commit 方法,一层层调用下去,直到最后一个
chain.connection_commit(connection);
// 从过滤器链中取出 DataSource,再从中取出 DataSourceStat
JdbcDataSourceStat dataSourceStat = chain.getDataSource().getDataSourceStat();
// 对操作计数 commitCount + 1
dataSourceStat.getConnectionStat().incrementConnectionCommitCount();
}
public void incrementConnectionCommitCount() {
commitCount.incrementAndGet();
}从上面的代码中可以看到,最终统计数据是存储在 JdbcDataSourceStat 中的。
public interface DataSourceProxy {
JdbcDataSourceStat getDataSourceStat();
...前面我们分析了那么长时间的 DruidDataSource 类就是 DataSourceProxy 接口的实现类之一。
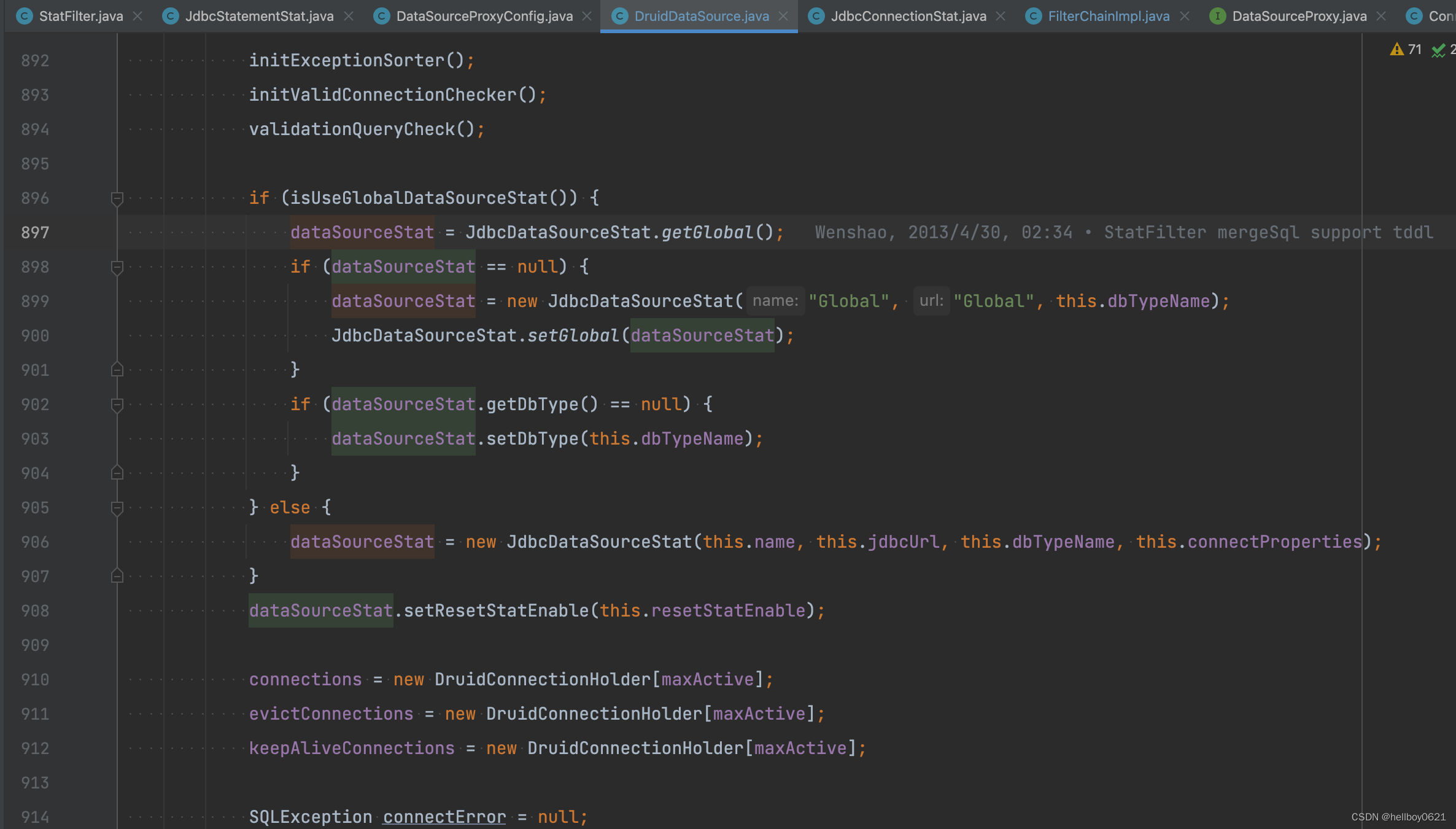
可以看到给 dataSourceStat 赋值的操作有3处,并且代码行数差的不多:
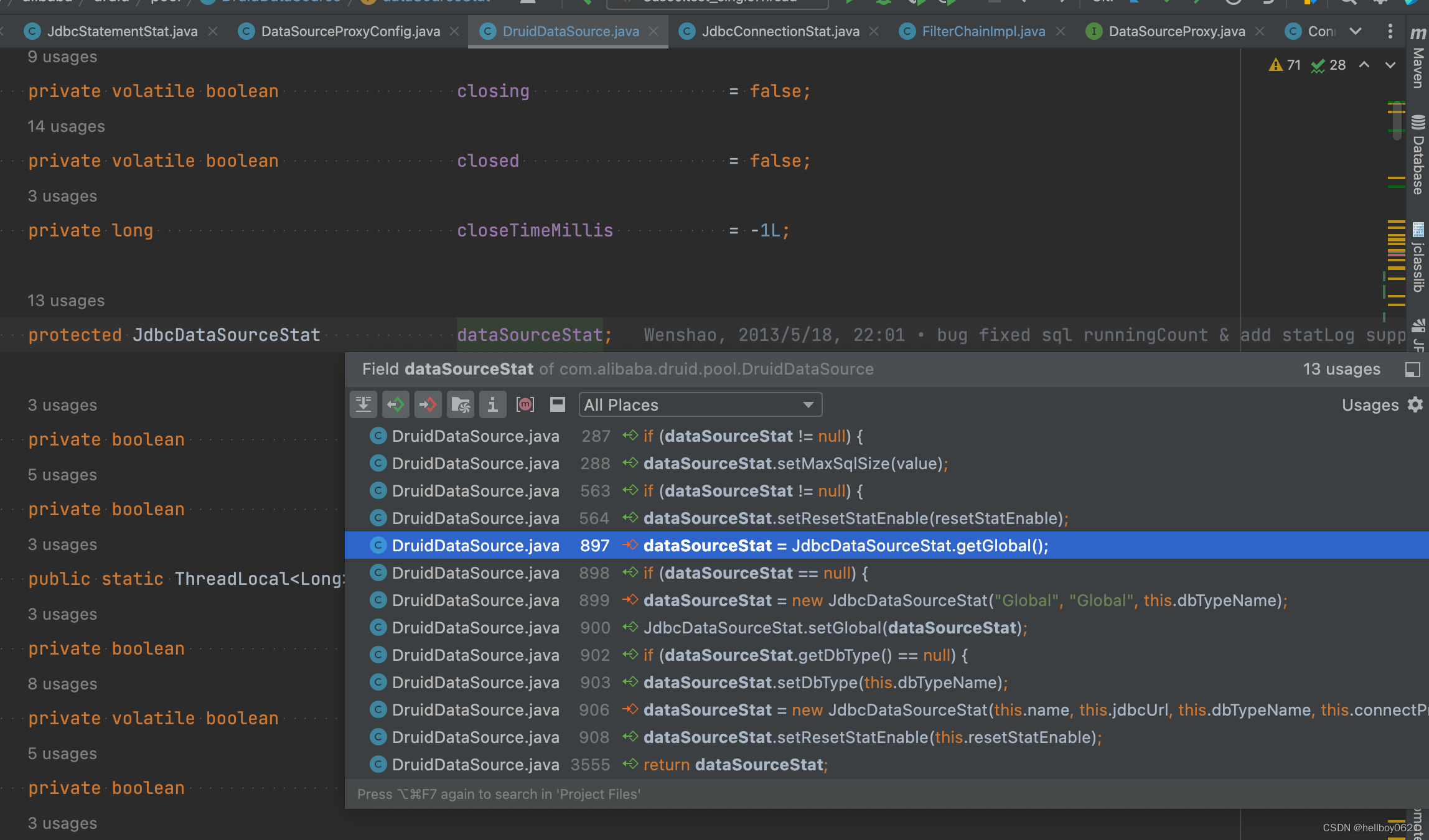
这不又回到了 init 方法中了吗?
统计数据都是怎么保存到呢,到 JdbcDataSourceStat 类中一探究竟:
public class JdbcDataSourceStat implements JdbcDataSourceStatMBean {
private final static Log LOG = LogFactory.getLog(JdbcDataSourceStat.class);
private final String name;
private final String url;
private String dbType;
private final JdbcConnectionStat connectionStat = new JdbcConnectionStat();
private final JdbcResultSetStat resultSetStat = new JdbcResultSetStat();
private final JdbcStatementStat statementStat = new JdbcStatementStat();
private int maxSqlSize = 1000;
private ReentrantReadWriteLock lock = new ReentrantReadWriteLock();
private final LinkedHashMap<String, JdbcSqlStat> sqlStatMap;
private final AtomicLong skipSqlCount = new AtomicLong();
private final Histogram connectionHoldHistogram = new Histogram(new long[] { //
//
1, 10, 100, 1000, 10 * 1000, //
100 * 1000, 1000 * 1000
//
});
private final ConcurrentMap<Long, JdbcConnectionStat.Entry> connections = new ConcurrentHashMap<Long, JdbcConnectionStat.Entry>(
16,
0.75f,
1);
private final AtomicLong clobOpenCount = new AtomicLong();
private final AtomicLong blobOpenCount = new AtomicLong();
private final AtomicLong keepAliveCheckCount = new AtomicLong();
private boolean resetStatEnable = true;
private static JdbcDataSourceStat global;
...这里面定义的属性分了几大类:
- 像 JdbcConnectionStat、JdbcResultSetStat、JdbcStatementStat 又封装了一层针对特定场景的对象;
- AtomicLong 类型的原子类,用于统计次数;
- ...
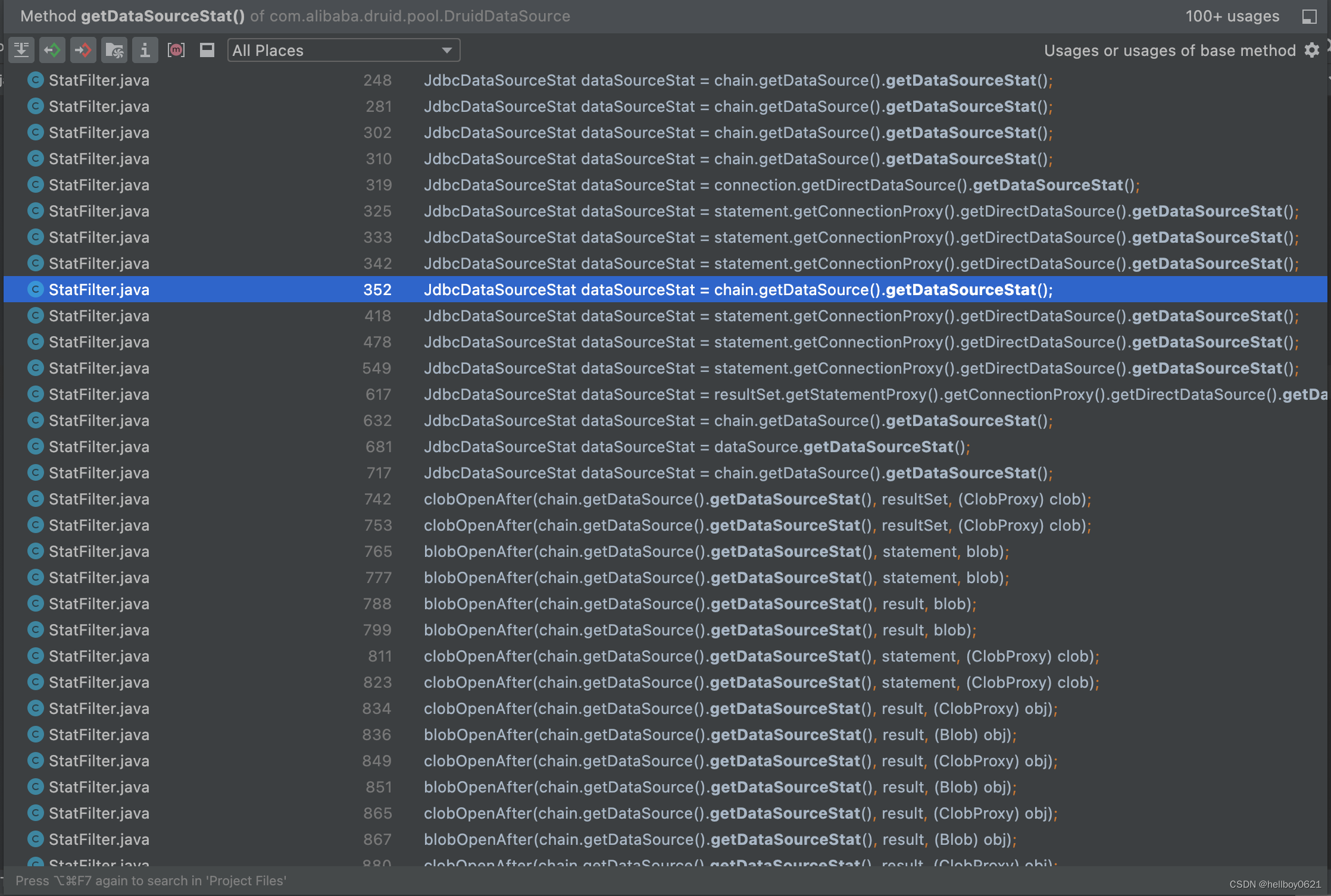
最后再搜索一下 DruidDataSource#getDataSourceStat() 方法被调用的地方,大部分是在 StatFilter 中被调用时更新统计数据使用的。















 4903
4903











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









