







数据结构之散列表
散列表(哈希表)
概念
- 散列(hashing)是一种用于以常数平均时间执行插入、删除和查找的技术。
- 散列不支持排序,所以散列表是无序的。
- 散列是一种存储结构(实质是一个数组,用于存储关键字值,关键字的存储下标就是根据关键字映射(通过散列函数也就是哈希函数)出来的位置),根据记录的存储位置与关键字之间存在对应关系(散列(哈希)函数),–也就是通过哈希函数对关键字值的处理,得出该关键字值在散列表中的存储位置
散列函数(哈希函数)
散列函数特性:
- 简单快速
- 均匀性:需要让关键字均匀分布在哈希表中
- 用于将关键字值映射到数组中的一个函数,一般的方法为关键字%表的大小
- 该函数我们需要在单元之间均匀地分配关键字,好的办法就是表的大小是素数,这将让散列函数算起来简单并且关键字分配比较均匀
- 如果关键字是字符串的时候,通常我们将字符串中的每个字符转换为ASCII码并求和,得到一个int型的数,就可以对它进行散列函数映射到哈希表中,一个更好的方法是:根据horner法则,计算一个**(32的)多项式函数**。
- 多个关键字映射到同一个数组下标或者数组单元的情况叫做冲突
常用哈希函数:
-
关键字是字符串:根据horner法则,计算一个(32的)多项式函数。
介绍:如果关键字特别长,那么散列函数计算起来会花过多的时间,而且前面的字符还会左移出最终的结果。因此这样情况下,不使用所有的字符。此时关键字的长度和性质会影响选择。例如只取奇数位置上的字符来实现散列函数。这里的思想是用计算散列函数省下来的时间来补偿由此产生的对均匀分布函数的轻微干扰
int hash(const char* key,int tablesize){
unsigned int hashval=0;
while(*key!='\0'){
hashval=(hashval<<5)+*key; //右移五次等于乘2的五次方也就是32
}
return hashval%tablesize;
}
-
直接寻址法
介绍:取关键字或关键字的某个线性函数值为散列地址,即H(key)=key或者H(key)=a*key+b(a,b为常数)。
举例:[‘A’,‘B’,‘D’,‘A’,‘C’,‘E’,‘F’,‘C’] ,求该字符数组里每个字符的出现次数(数组中只有大写字母)。
分析:我们可以知道’A’-'Z’的ASCLL码是65-90,则哈希函数可以通过直接寻址法H(key)=key-‘A’(对应定义中的a=1,b=-‘A’即65),这样针对每一个key,都可以将它的H(key)值当成数组下标放在一个长度为26的int数组中统计长度
假设字符数组为a,int数组为b。即b[a[i]-‘A’]++(i表示a数组的下标索引)。
结果
b[0]=2(代表A出现两次);b[1]=1(代表B出现一次),b[2]=2(代表C出现两次)… -
数字分析法
介绍:分析一组数据中相同位(个位,十位,百位…)的数字出现频率,如果该位数字出现结果较为集中,如果取其作为构造散列地址的依据则很容易出现哈希冲突,反之,如果该位数字出现结果较为平均,则取其作为构造散列地址的依据则不容易出现哈希冲突。
举例:某公司招聘了一些实习生,其生日分别为[19990104,20000910,20000315,20001128,20001014,19990413,19990920,20000517],对其进行hash处理。
分析
如果取8位数作为散列地址,虽然很难出现哈希冲突,但是空间浪费很大,因此考虑只取其中几位作为散列地址,即能减少空间浪费又能降低哈希冲突的可能性,观察上面8组数据,前4位集中在1999,2000,如果取前4位则很容易出现哈希冲突,而后四位分布相对分散,不容易出现哈希冲突,因此取后四位比较符合。
结果
H(19990104)=104,H(20000910)=910,H(20000315)=315… -
折叠法
介绍:折叠法是把关键字值分成自左向右分成位数相等的几部分,每一部分的位数应与散列表地址(也就是数组下标)的位数相同,只有最后一部分的位数可以短一些。把这些部分的数据叠加起来(去除进位),就可以得到关键字值的散列地址。
有两种叠加方法:
(1)移位法(shift floding):把各部分的最后一位对齐相加。
(2)分界法(floding at the boudaries):沿各部分的分界来回折叠(即第偶数个加数和移位法反过来),然后对其相加。
举例:key=1234791,散列地址为2位
分析
将key分成12,34,79,1四部分
(1)移位法:12+34+79+1
(2)分界法:12+43+79+1(即第偶数个加数和移位法反过来)
结果
(1)移位法:H(1234791)=35(相加为135,去除进位1)
(2)分界法:H(1234791)=44(相加为144,去除进位1) -
平方取中法
介绍:当无法确定关键字中哪几位分布较均为时,可以求出关键字的平方值,然后按需要取平方值的中间几位作为散列地址。这是因为:平方后中间几位和关键字中每一位都有关,故不同关键字会以较高的概率产生不同的散列地址。
举例:关键字序列:{3213,3113,3212,4312}。
分析:
3213^2=10323369
3113^2=9690769
3212^2=10316944
4312^2=18593344
取平方值中间4位为散列地址(3113的平方值前面补0凑成8位)
结果
H(3213)=3233,H(3113)=6907,H(3212)=3169,H(4312)=5933
解决冲突
-
负载因子(local factor)为散列表中的元素个数与散列表的大小的比值。
- 负载因子为0.7-0.75比较合理,负载因子在哈希表中的意义就是当你这个哈希表的负载因子达到你设定的值就进行扩容为后面的存储更多数据做准备。
- java封装的数据结构也是使用的分离链接法,但是其不同的是,他不是完全的数组加链表的形式,它是当链表达到一定长度时就将链表转化为红黑树。
- java封装的哈希表的数据结构的负载因子为什么为0.75呢
- 是因为当负载因子等于1的时候也就意味着关键字均匀分布并且几乎存满了哈希表(数组的每个下标都有关键字填充)才进行扩容的情况,关键字数量多就会造成大量的哈希冲突,这也造成了数组加红黑树的情况出现的更多,而这样底层的红黑树变得更加复杂,大大降低了查询速度,这种情况就是牺牲了时间来保证空间的利用率.
- 当负载因子为0.5时,也就意味着当数组中的元素达到一半就开始扩容,虽然填充的元素少了,哈希冲突减少了,查询速度提高了,但是空间利用率降低了,原本1m的数据现在需要2m的空间存储,这就是牺牲空间来保证时间的效率
- 当负载因子为0.75,时间和空间达到了平衡,所以java封装的哈希表结构的负载因子默认为0.75.
-
分离链接法:就是一个数组加链表来解决冲突问题的,将映射到同一个数组下标的所有关键字保留在一个表中,而这个表就是链表,将同一个数组下标的所有关键字通过链表连接起来,该方法使用的比较多。分离链接散列的基本法则是使得表的大小尽量与预料的关键字个数差不多(也就是负载因子约等于1),这样也就是能够保证关键字均匀分布在散列表中,使得查找时间减少。
- 插入:插入时可以选择头插法插入链表中,如果插入重复元素,定义链表时可以选择多增加一个计数的域,来记录这个元素出现次数
- 查找:对要查找的关键字进行哈希函数的操作,得到映射的数组下标,然后在该下标指向的链表中查找指定关键字
- 删除:找到对应的数组下标,遍历链表找到要删除的关键字的节点,然后判断它的存储个数(cnt),如果大于1就让cnt-1,如果等于1就是删除该节点
- 缺点:需要指针,给新单元分配空间需要时间,导致算法的速度减慢,与此同时还需要对链表的数据结构进行实现。
//分离链接法
//定义链表
template<class T>
struct listnode{
T data;
listnode* next;
int cnt;
};
template<class T>
class hashtable{
public:
int isPrime(int num) {
if(num <= 1) {
return 0;
}
int i;
for(i = 2; i*i <= num; i++) {
if(num % i == 0) {
return 0;
}
}
return 1;
}
//找出大于tablesize最近的素数
int prime(int size){
while (!isPrime(size)) {
size++;
}
return size;
}
float loadfactor(){
return (float)count/(float)tablesize;
}
listnode<T>* createNode(T data){
listnode<T>* list=(listnode<T>*)malloc(sizeof(listnode<T>));
list->data=data;
list->next= nullptr;
list->cnt=1;
return list;
}
hashtable(int size){
this->count=0;
this->tablesize=prime(size);
for(int i=0;i< this->tablesize;i++){
listnode<T>*list=(listnode<T>*)malloc(sizeof(listnode<T>));
list->next=NULL;
list->cnt=0;
v.push_back(list);
}
}
//散列函数(哈希函数),用于将关键字处理得到映射的数组下标,这里用了简单的哈希函数,在不同场景有不同的函数设计
int hash(T data){
return data%this->tablesize;
}
listnode<T>* findnode(listnode<T>* head,T data){
if(head!= nullptr){
listnode<T>* p=head;
while (p!= nullptr){
if(p->data==data){
return p;
}
p=p->next;
}
}
return NULL;
}
void insert(T data){
if(loadfactor()>1||loadfactor()==1){
int size= this->tablesize;
this->tablesize=prime(count*2);
for(int i=size;i< this->tablesize;i++){
listnode<T>*list=(listnode<T>*)malloc(sizeof(listnode<T>));
list->next=NULL;
list->cnt=0;
v.push_back(list);
}
}
int index= hash(data);
if(nullptr==v[index]->next){
listnode<T>* list= createNode(data);
v[index]->next=list;
} else{
listnode<T>* tail=findnode(v[index]->next,data);
if(tail==NULL){
listnode<T>* list= createNode(data);
listnode<T>* p=v[index]->next;
v[index]->next=list;
v[index]->next->next=p;
}else{
tail->cnt++;
}
}
this->count++;
}
listnode<T>* find(T data){
int index= hash(data);
listnode<T>* p=findnode(v[index]->next,data);
return p;
}
void print(){
for(int i=0;i< this->tablesize;i++){
listnode<T>* p=v[i]->next;
cout<<"索引为"<<i<<":"<<" ";
if(p== nullptr){
cout<<endl;
continue;
}
while (p!= nullptr){
for(int j=0;j<p->cnt;j++)
cout<<p->data<<" ";
p=p->next;
}
cout<<endl;
}
}
void del(T data){
int index= hash(data);
listnode<T>* tail=v[index]->next;
listnode<T>* p=v[index];
while (tail->next!= nullptr){
if(tail->data==data){
break;
}
p=tail;
tail=tail->next;
}
if(tail->data==data){
if(tail->cnt>1){
tail->cnt--;
count--;
return;
}
p->next=tail->next;
delete tail;
count--;
}
return;
}
private:
int count;
vector<listnode<T>*>v;
int tablesize;
};
-
开放定址法:该算法的结构就只有一个数组。如果有哈希冲突发生,那么就尝试选择其他的单元,直到找到空单元就进行插入。函数F是冲突解决的办法。对于开放定址法来说,负载因子应该低于0.5(只要表足够大,这样总能够找到一个空单元才能解决冲突),而该方法的删除操作建议是懒惰删除,也就是删除对应的值,但是数组的长度不会变。开放地址法也分为三个方法:
- 线性探测法:通过哈希函数,找到关键字对应的数组下标,如果该单元非空,则我们进行向后查找(也就是在这个数组下标的后面进行查找空单元),如果达到数组的最后一个单元都没找到空单元就返回到数组的第一个单元(也就是数组下标为0)再进行向后查找;如果该单元是空单元,则直接进行插入。如果表可以多于一半被填满,线性探测就不是好方法,如果元素较少使用线性探测法,如果数据量大就不建议使用
- 平方探测法:是用来消除线性探测中一次聚集问题的冲突解决方法,平方探测法就是冲突函数为二次函数的探测方法,流行的选择是F(i)=i2(i为冲突次数),通过哈希函数,找到关键字对应的数组下标,如果该单元是空的就插入,如果该单元非空,则该单元的冲突次数+1也就是i=1,通过F(i)计算得到向后移动的单元,所以算出等于1就向后移动一单元,如果所处的单元还是非空,则冲突次数再次+1,然后再向后移动F(i)位,i为2则移动四个单元(移动的单元不是从所处的单元在移动4位,而是从原本的单元也就是开始通过哈希函数计算出来的单元开始移动四位),如此递推下去,直到找到空的单元,如果达到最后一单元,则从数组下标0重新开始。
- 双散列:双散列的意思是映射数组下标时,使用两个散列函数进行计算映射位置,对于双散列,流行的一种选择是F(i)=i*hash2(X),hash2(X)为第二个哈希函数,i为探测次数,也就是当我插入时,通过第一个哈希函数计算出映射的数组下标,如果该单元是空单元,就直接插入,如果非空,则通过第二哈希函数计算向后移动的位数,比方说,当我插入映射到数组下标8的位置,但是下标为8的单元非空,则需要向后移动,而此时i为1,然后通过哈希2计算出移动位置,如果移动后的单元还是非空,则此时i等于2,计算出移动位数后,需要重新回到数组下标8进行移动,直到找到空单元为止。哈希2函数的选取很重要,如果选择的不好则将会是灾难性的,像hash2(X)=R-(X mod R)这种函数会比较好,R的选择需要根据情况设定,然后保证表的大小为素数很重要
-
再散列:对于使用平方探测的开放定址法,如果表的元素填的太满,性能则会大大降低,则我们就新建立一个原来的散列表的两倍大小的散列表(并且使用一个相关的新散列函数),然后扫描原始的散列表,通过新的散列函数计算每个已经插入在原表中的数据的新的映射下标并将其插入新表之中,双散列建立的时机可以实时根据负载因子决定,当负载因子到达指定值就进行再散列操作。
//开放定址法
class hashtable{
public:
bool isprime(int n){
if(n<=1)
return false;
for(int i=2;i*i<n;i++){
if(n%i==0){
return false;
}
}
return true;
}
int prime(int size){
while (!isprime(size)){
size++;
}
return size;
}
hashtable(int size){
this->tablesize= prime(size);
for(int i=0;i<tablesize;i++){
v.push_back(NULL);
}
}
//线性探测法
int hash1(int key){
int index=key%tablesize;
int cnt=0;
while (v[index]!=NULL){
if(cnt>1){
cout<<"没有空余的位置插入"<<endl;
return -1;
}
if(index==tablesize-1){
cnt++;
index=0;
continue;
}
index++;
}
return index;
}
//平方探测法
int hash2(int key){
int index=key%tablesize;
int cnt=0,n=0,i=0;
while (v[index]!=NULL){
if(i>1){
cout<<"没有空余的位置插入"<<endl;
return -1;
}
cnt++;
cnt*=cnt;
index=index+cnt-n;
n=cnt;
if(index>tablesize-1){
i++;
index=index-tablesize;
}
}
return index;
}
float localfactor(){
return (float)count/(float)tablesize;
}
void insert(int key){
if(localfactor()>0.5||localfactor()==0.5){
int size=tablesize*2;
for(int i=tablesize;i<size;i++){
v.push_back(NULL);
}
tablesize=size;
}
int index=hash2(key);
if(index!=-1){
v[index]=key;
count++;
}
}
int find(int key){
int index=key%tablesize;
int size=tablesize;
for(int i=index;i<=size+index;i++){
if(v[i]==key){
return i;
}
if(i==tablesize-1){
size=0;
i=0;
}
}
cout<<"为找到"<<endl;
return -1;
}
void del(int key){
int index=find(key);
if(index!=-1){
count--;
v[index]=NULL;
}
return;
}
void print(){
for(int i=0;i<tablesize;i++){
cout<<"索引为"<<i<<": "<<v[i]<<endl;
}
}
private:
int count;
vector<int>v;
int tablesize;
};
-
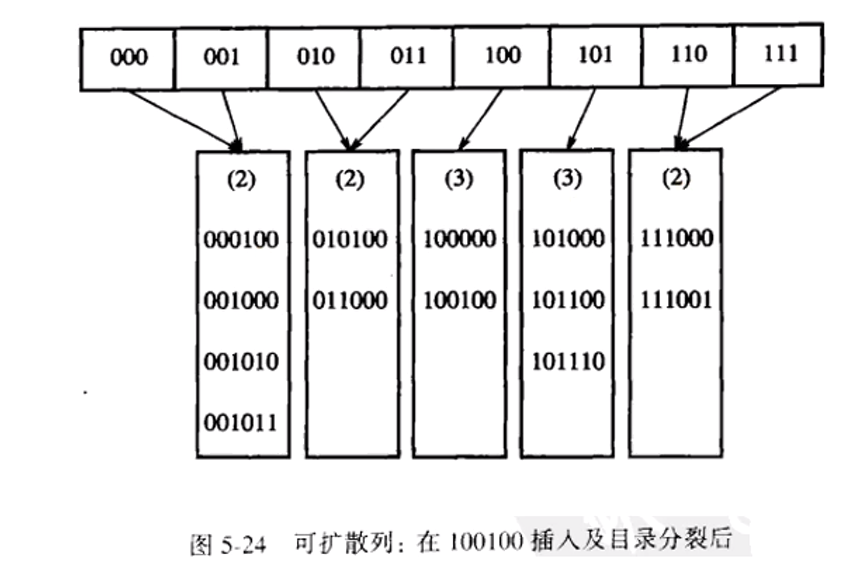
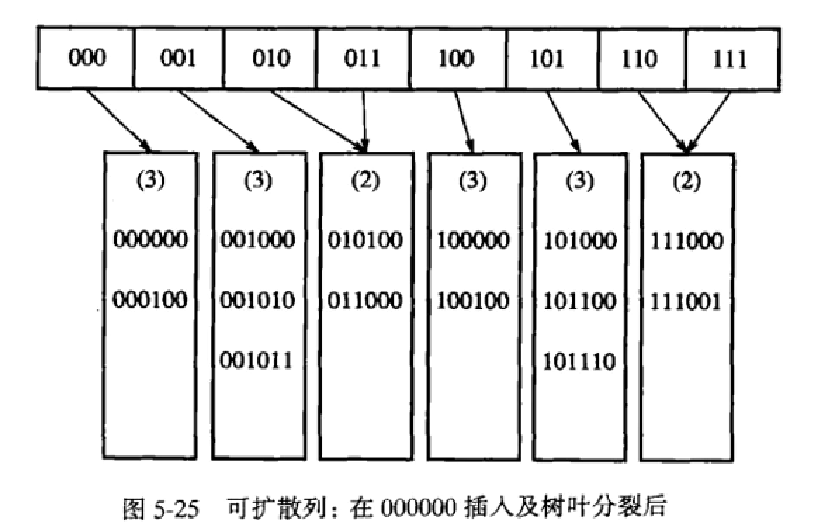
可扩散列:当处理数据量太大以至于装不进主存的情况下,此时主要考虑是检索数据所需的磁盘存取次数,而可扩散列,它允许用两次磁盘访问就能够执行一次查找操作,插入操作也是很少的磁盘访问。可扩散列有点类似于B树的结构。可扩散列无法存在重复关键字
- 在可扩散列中,我们用D表示根所使用的比特数(也称其为目录),目录的所存的元素个数为2D,dL为树叶节点中的元素共有的最高位位数,因此dL应该小于等于D
- D就是用来区分存储节点的位置的依据,例如我们的数据由前俩个比特进行区分,则该结构的节点应该能够存储4个元素,然后dL应该等于2,因为数据需要根据前两位跟目录的元素进行匹对来存储到对应的节点,因此它的共有最高位应该为2,如图5-23
- 如果插入数据时,节点元素已经满了,我们就需要进行分裂节点来存储,例如上述讲的图5-23当D=2时,我们插入100100时,发现10为根节点的叶子节点元素已经满了,就分裂该叶子节点,分裂完发现根节点也满了则需要对根节点分裂,因此根节点分裂后应该以3比特进行将数据分开存储,因为23等于8,因此根节点分裂后为8个元素(如图5-24),但是叶子节点只有5个,因此有一些根节点跟其他根节点共用一个叶子节点,直到再次插入让它们共用的节点,才进行更改根节点指向(如图5-25)。

尾言
完整版笔记也就是数据结构与算法专栏完整版可到我的博客进行查看,或者在github库中自取(包含源代码)
- 博客1: codebooks.xyz
- 博客2:moonfordream.github.io
- github项目地址:Data-Structure-and-Algorithms


















 1241
1241

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











