







 本文深入探讨Swift的内存模型,包括栈和堆的使用、内存对齐的原理和重要性,以及自动引用计数(ARC)的工作机制。此外,文章详细介绍了方法调度的静态和动态调度,分析了Struct、Class、继承、协议和范型在方法调度中的不同行为,为优化Swift代码提供了宝贵见解。
本文深入探讨Swift的内存模型,包括栈和堆的使用、内存对齐的原理和重要性,以及自动引用计数(ARC)的工作机制。此外,文章详细介绍了方法调度的静态和动态调度,分析了Struct、Class、继承、协议和范型在方法调度中的不同行为,为优化Swift代码提供了宝贵见解。
前言
Apple今年推出了Swift3.0,较2.3来说,3.0是一次重大的升级。关于这次更新,在这里都可以找到,最主要的还是提高了Swift的性能,优化了Swift API的设计(命名)规范。
前段时间对之前写的一个项目ImageMaskTransition做了简单迁移,先保证能在3.0下正常运行,只用了不到30分钟。总的来说,这次迁移还是非常轻松的。但是,有一点要注意:3.0的API设计规范较2.3有了质变,建议做迁移的开发者先看下WWDC的Swift API Design Guidelines。后面有时间了,我有可能也会总结下。
内存分配
通过查看Github上Swift的源代码语言分布
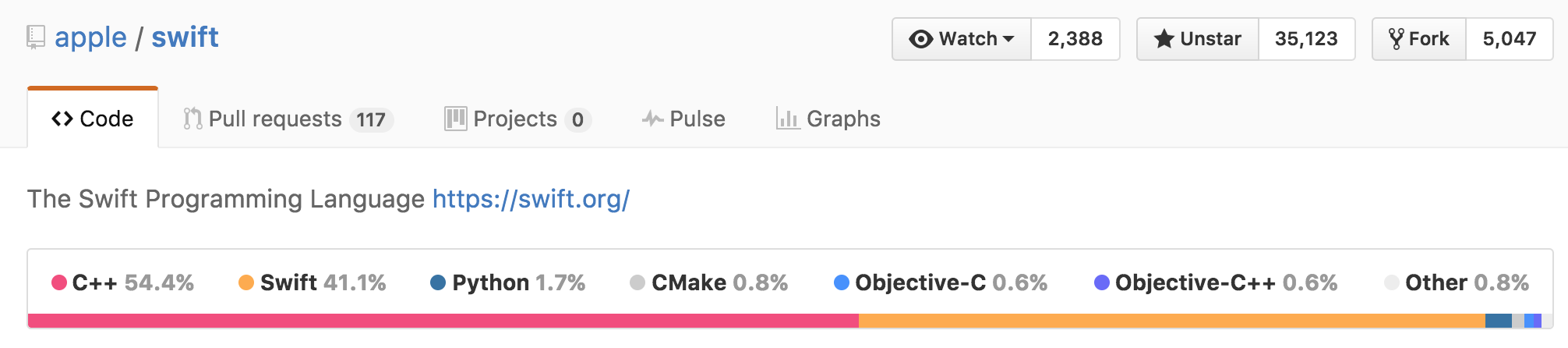
可以看到
- Swift语言是用C++写的
- Swift的核心Library是用Swift自身写的。
对于C++来说,内存区间如下
- 堆区
- 栈区
- 代码区
- 全局静态区
Swift的内存区间和C++类似。也有存储代码和全局变量的区间,这两种区间比较简单,本文更多专注于以下两个内存区间。
- Stack(栈),存储值类型的临时变量,函数调用栈,引用类型的临时变量指针
- Heap(堆),存储引用类型的实例
栈
在栈上分配和释放内存的代价是很小的,因为栈是一个简单的数据结构。通过移动栈顶的指针,就可以进行内存的创建和释放。但是,栈上创建的内存是有限的,并且往往在编译期就可以确定的。
举个很简单的例子:当一个递归函数,陷入死循环,那么最后函数调用栈会溢出。
例如,一个没有引用类型Struct的临时变量都是在栈上存储的
struct Point{
var x:Double // 8 Bytes
var y:Double // 8 bytes
}
let size = MemoryLayout<Point>.size
print(size) // 16
let point1 = Point(x:5.0,y:5.0)
let instanceSize = MemoryLayout<Point>.size(ofValue: point1)
print(instanceSize) //16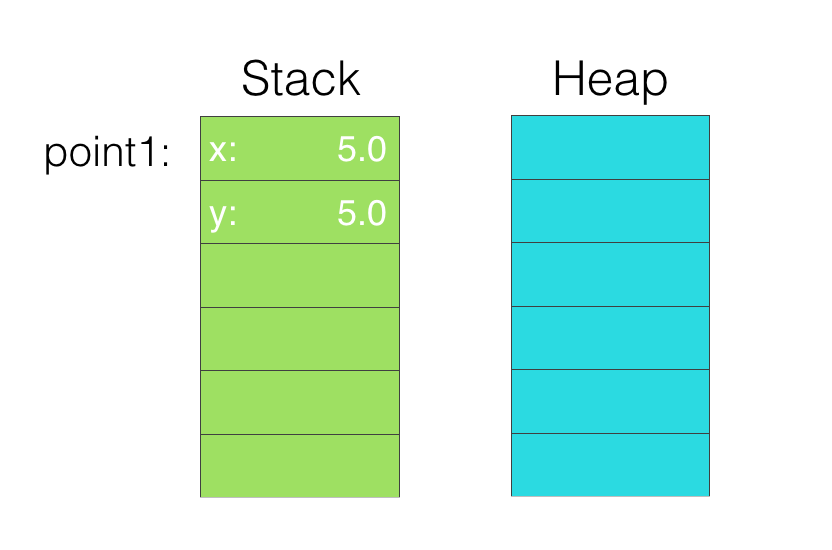
Tips: 图中的每一格都是一个Word大小,在64位处理器上,是8个字节
堆
在堆上可以动态的按需分配内存,每次在堆上分配内存的时候,需要查找堆上能提供相应大小的位置,然后返回对应位置,标记指定位置大小内存被占用。
在堆上能够动态的分配所需大小的内存,但是由于每次要查找,并且要考虑到多线程之间的线程安全问题,所以性能较栈来说低很多。
比如,我们把上文的struct改成class,
class PointClass{
var x:Double = 0.0
var y:Double = 0.0
}
let size2 = MemoryLayout<PointClass>.size
print(size2) //8
let point2 = Point(x:5.0,y:5.0)
let instanceSize = MemoryLayout<Point>.size(ofValue: point2)
print(instanceSize) 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 475
475

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









