







目录
二、Hadoop YARN(Yet Another Resource Negotiator-另一种资源协调者)
一、Hadoop Mapreduce
1、“分而治之”的思想
""" 简单来说,就是把一个复杂的问题,按照一定的规则分解为等价的小规模的若干部分,然后逐个解决,把各部分的结果整合,组成问题的最终结果。 对于mapreduce来说,代表着任务的进行分成两个阶段:Map阶段和Reduce阶段 1、Map:负责拆分 拆分的前提是这些小任务可以并行计算,彼此之间互相隔离,没有依赖关系 2、Reduce:负责合并 """ # mapreduce处理的数据类型是k,v键值对
""" 1、mapreduce优点:易于编程、扩展性好、容错率高、适合海量数据的离线处理(GB,TB,PB) 2、mapreduce缺点:实时计算性差、不能进行流式计算 流式计算特点是数据是源源不断得计算,并且数据是动态的;而MapReduce作为一个离线计算框架,主要是针对静态数据集得,数据是不能动态变化得。 """
2、mapreduce执行流程
一个完整的MapReduce程序在分布式运行时有三类:
""" 1、MRAppMaster:负责整个MR程序的过程调度及状态协调 2、MapTask:负责map阶段的整个数据处理流程 3、ReduceTask:负责reduce阶段的整个数据处理流程 """
3、阶段组成
-
一个MapReduce编程模型中只能包含一个Map阶段和一个Reduce阶段,或者只有Map阶段;
-
不能有诸如多个map阶段、多个reduce阶段的情景出现;
-
如果用户的业务逻辑非常复杂,那就只能多个MapReduce程序串行运行。
4、MapReduce数据类型
-
注意:整个MapReduce程序中,数据都是以kv键值对的形式流转的;
-
在实际编程解决各种业务问题中,需要考虑每个阶段的输入输出kv分别是什么;
-
MapReduce内置了很多默认属性,比如排序、分组等,都和数据的k有关,所以说kv的类型数据确定及其重要的
5、mapreduce执行的整体流程图
6、map阶段的执行过程
1、第一阶段:
把输入目录下文件按照一定的标准逐个进行逻辑切片,形成切片规划。
默认Split size = Block size(128M),每一个切片由一个MapTask处理。(getSplits)
2、第二阶段:
对切片中的数据按照一定的规则读取解析返回<key,value>对。
默认是按行读取数据。key是每一行的起始位置偏移量,value是本行的文本内容。(TextInputFormat)
3、第三阶段:
调用Mapper类中的map方法处理数据。
每读取解析出来的一个<key,value> ,调用一次map方法。
4、第四阶段:
按照一定的规则对Map输出的键值对进行分区partition。默认不分区,因为只有一个reducetask。
分区的数量就是reducetask运行的数量。
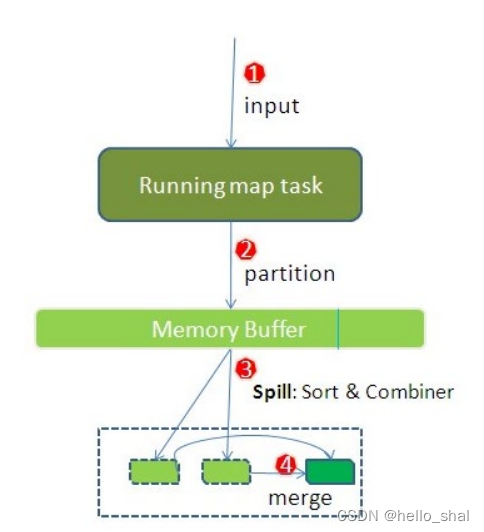
5、第五阶段:
Map输出数据写入内存缓冲区,达到比例溢出到磁盘上。溢出的时候根据key进行排序sort。默认根据key字典序排序。
6、第六阶段:
对所有溢出文件进行最终的merge,合并成为一个文件。
7、reduce的执行过程
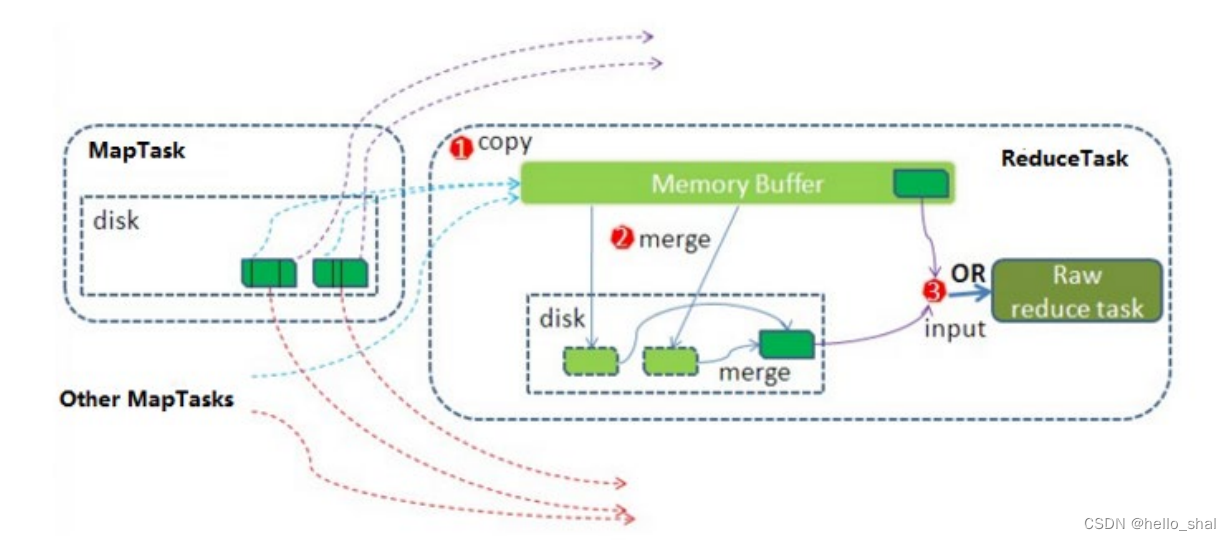
1、第一阶段:ReduceTask会主动从MapTask复制拉取属于需要自己处理的数据。
2、第二阶段:把拉取来数据,全部进行合并merge,即把分散的数据合并成一个大的数据。再对合并后的数据排序。
3、第三阶段是对排序后的键值对调用reduce方法。键相等的键值对调用一次reduce方法。最后把这些输出的键值对写入到HDFS文件中。
8、mapreduce中的shuffle机制
shuffle的本意是洗牌的意思,但是在mapreduce中更像是反过程,是将map端的无序的输出数据按照特定的规则输出到reduce端中进行处理。
一般把从Map产生输出开始到Reduce取得数据作为输入之前的过程称作shuffle
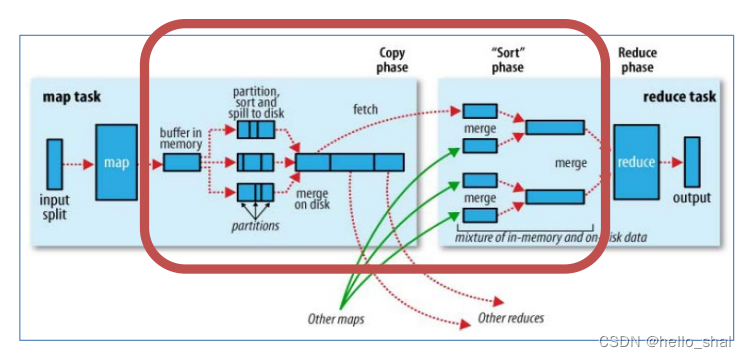
8.1Map端Shuffle
1、Collect阶段:将MapTask的结果收集输出到默认大小为100M的环形缓冲区,保存之前会对key进行分区的计算,默认Hash分区。
2、Spill阶段:当内存中的数据量达到一定的阀值的时候,就会将数据写入本地磁盘,在将数据写入磁盘之前需要对数据进行一次排序的操作,如果配置了combiner,还会将有相同分区号和key的数据进行排序。
3、Merge阶段:把所有溢出的临时文件进行一次合并操作,以确保一个MapTask最终只产生一个中间数据文件。
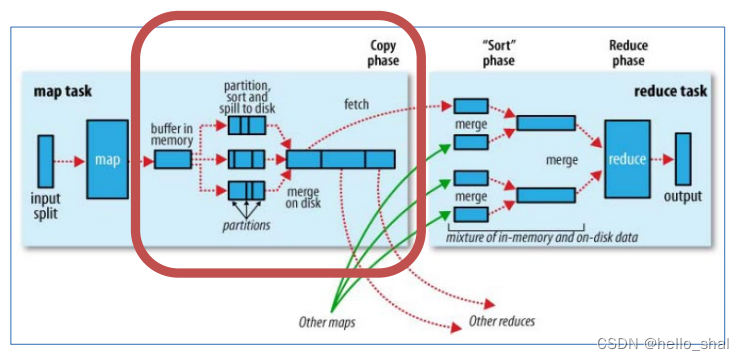
8.2Reduce端shuffle
1、Copy阶段: ReduceTask启动Fetcher线程到已经完成MapTask的节点上复制一份属于自己的数据。
2、Merge阶段:在ReduceTask远程复制数据的同时,会在后台开启两个线程对内存到本地的数据文件进行合并操作。
3、Sort阶段:在对数据进行合并的同时,会进行排序操作,由于MapTask阶段已经对数据进行了局部的排序,ReduceTask只需保证Copy的数据的最终整体有效性即可。
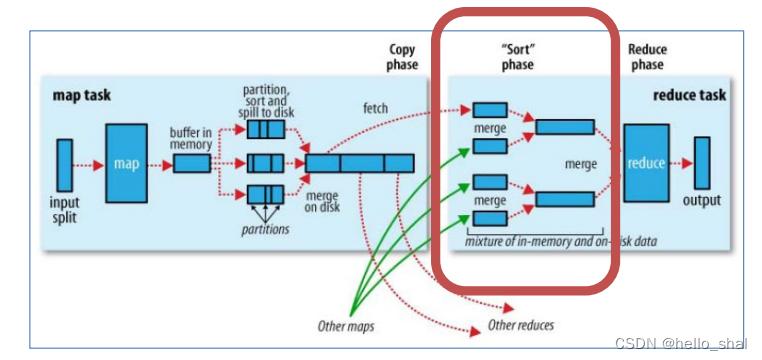
9、关于shuffle
""" shuffle是mapreduce的精髓,但是正是由于shuffle机制,mapreduce的计算较为庞大,比spark和flink都要慢得多 shuffle中还大量的涉及到了从内存到磁盘之间的往复,这更加大大的增加了电脑的资源负担 """
二、Hadoop YARN(Yet Another Resource Negotiator-另一种资源协调者)
1、YARN功能与架构组件
# yarn是一个通用的资源管理和调度平台,为上层的应用提供统一的资源管理和调度,他的通用性正是他如此成功的原因。
资源管理:主要指的是集群里的计算机管理,CPU、内存等
调度平台:指的是多个程序申请资源时,如何进行资源的分配和调度
通用:在于YARN不仅仅只支持mapreduce,理论上还支持各种程序
2、YARN的官方架构图
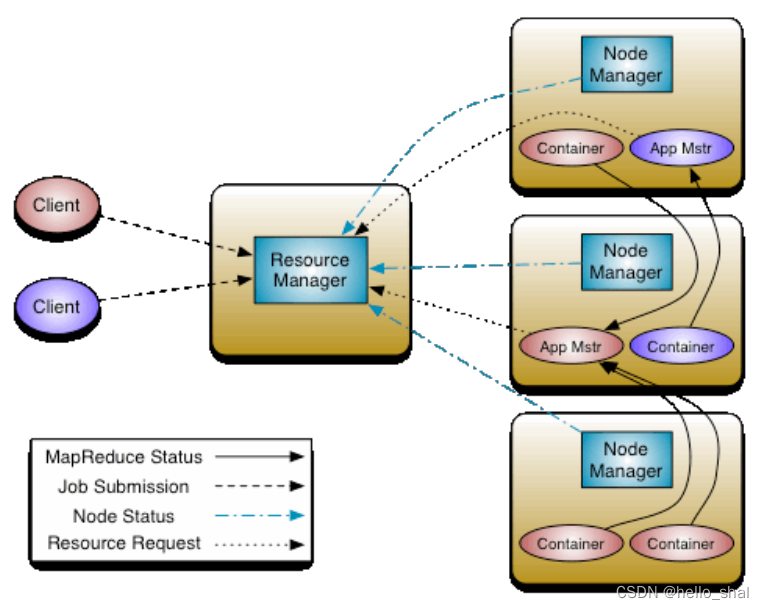
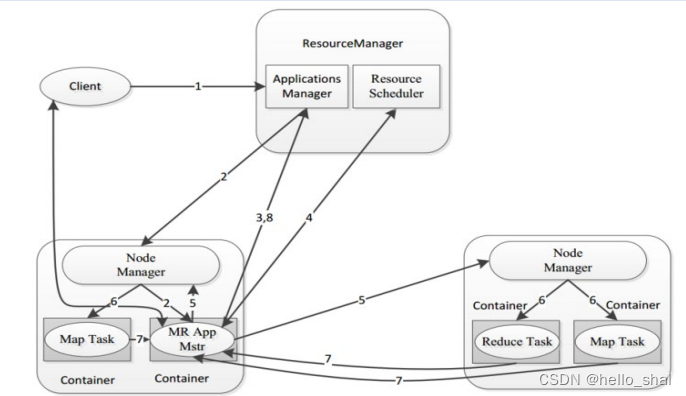
""" 其中提到了几个概念: ResourceManager:主角色,决定了所有应用程序之间的资源分配的 最终权限,类似于BOSS NodeManager:从角色,每台服务器上一个,负责本机的计算资源,根据RM命令,启动Container容器、监视容器的资源使用情况。并且向RM主角色汇报资源使用情况。--就是干活的。 AppMaster(appmstr):app层面,是应用程序的"老大",主要负责程序内部的资源申请,同时监督程序的执行情况 container:容器,指的是资源,是一个抽象的概念 client:客户端 """
3、程序提交YARN交互流程
# 首先,客户端发起请求,RM接收到请求,向NM派发任务,NM在他内部的appmaster中申请资源
3.1核心流程
-
MR作业提交 Client-->RM
-
资源的申请 MrAppMaster-->RM
-
MR作业状态汇报 Container(Map|Reduce Task)-->Container(MrAppMaster)
-
节点的状态汇报 NM-->RM
3.2整体概述
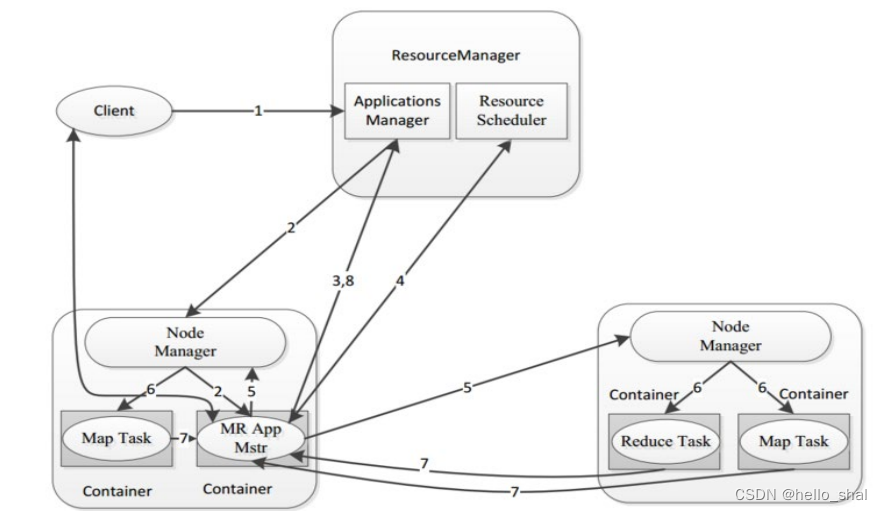
3.2.1当用户向 YARN 中提交一个应用程序后, YARN将分两个阶段运行该应用程序 。
-
第一个阶段是客户端申请资源启动运行本次程序的ApplicationMaster;
-
第二个阶段是由ApplicationMaster根据本次程序内部具体情况,为它申请资源,并监控它的整个运行过程,直到运行完成。
3.2.2MR提交YARN交互的过程
""" 第1步:用户通过客户端向YARN中ResourceManager提交应用程序(比如hadoop jar提交MR程序); 第2步:ResourceManager为该应用程序分配第一个Container(容器),并与对应的NodeManager通信,要求它在这个Container中启动这个应用程序的ApplicationMaster。 第3步:ApplicationMaster启动成功之后,首先向ResourceManager注册并保持通信,这样用户可以直接通过ResourceManage查看应用程序的运行状态(处理了百分之几); 第4步:AM为本次程序内部的各个Task任务向RM申请资源,并监控它的运行状态; 第5步:一旦 ApplicationMaster 申请到资源后,便与对应的 NodeManager 通信,要求它启动任务。 第6步:NodeManager 为任务设置好运行环境后,将任务启动命令写到一个脚本中,并通过运行该脚本启动任务。 第7步:各个任务通过某个 RPC 协议向 ApplicationMaster 汇报自己的状态和进度,以让 ApplicationMaster 随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务。在应用程序运行过程中,用户可随时通过RPC 向 ApplicationMaster 查询应用程序的当前运行状态。 第8步:应用程序运行完成后,ApplicationMaster 向 ResourceManager 注销并关闭自己。 """
4、YARN调度策略、
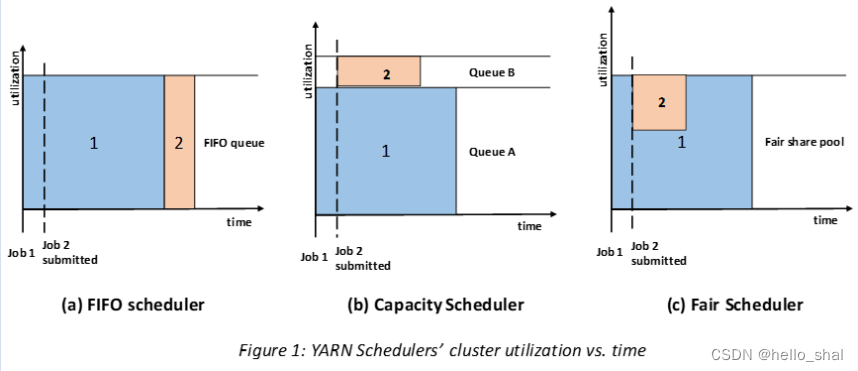
""" 1、FIFO(first in first out)先进先出的策略 不考虑优先级和范围,严格按照先进先出的原则,所以只适合用在负荷较小的集群,在使用大型共享集群时,效率较低。 FIFO Scheduler拥有一个控制全局的队列queue,默认queue名称为default,该调度器会获取当前集群上所有的资源信息作用于这个全局的queue。 好处是无需配置,易于执行 2、Capacity Scheduler(容量调度器) Capacity Scheduler容量调度是Apache Hadoop3.x默认调度策略。该策略允许多个组织共享整个集群资源,每个组织可以获得集群的一部分计算能力。通过为每个组织分配专门的队列,然后再为每个队列分配一定的集群资源,这样整个集群就可以通过设置多个队列的方式给多个组织提供服务了。 Capacity可以理解成一个个的资源队列,这个资源队列是用户自己去分配的。队列内部又可以垂直划分,这样一个组织内部的多个成员就可以共享这个队列资源了,在一个队列内部,资源的调度是采用的是先进先出(FIFO)策略。 Capacity Scheduler调度器以队列为单位划分资源。简单通俗点来说,就是一个个队列有独立的资源,队列的结构和资源是可以进行配置的。 capacity scheduler的优势 ·层次化的队列设计(Hierarchical Queues) 层次化的管理,可以更容易、更合理分配和限制资源的使用。 ·容量保证(Capacity Guarantees) 每个队列上都可以设置一个资源的占比,保证每个队列都不会占用整个集群的资源。 ·安全(Security) 每个队列有严格的访问控制。用户只能向自己的队列里面提交任务,而且不能修改或者访问其他队列的任务。 ·弹性分配(Elasticity) 空闲的资源可以被分配给任何队列。 当多个队列出现争用的时候,则会按照权重比例进行平衡。 3、Fair Scheduler(公平调度器) Fair Scheduler叫做公平调度,提供了YARN应用程序公平地共享大型集群中资源的另一种方式。使所有应用在平均情况下随着时间的流逝可以获得相等的资源份额。 Fair Scheduler设计目标是为所有的应用分配公平的资源(对公平的定义通过参数来设置)。 公平调度可以在多个队列间工作,允许资源共享和抢占。 此处的公平在理解上可以理解为后面提交的任务占用上一个提交的任务的一半的资源,在上一个任务结束后,后一个任务占用全部的上一个的资源 fair scheduler的优势 1、分层队列:队列可以按层次结构排列以划分资源,并可以配置权重以按特定比例共享集群。 2、基于用户或组的队列映射:可以根据提交任务的用户名或组来分配队列。如果任务指定了一个队列,则在该队列中提交任务。 3、资源抢占:根据应用的配置,抢占和分配资源可以是友好的或是强制的。默认不启用资源抢占。 4、保证最小配额:可以设置队列最小资源,允许将保证的最小份额分配给队列,保证用户可以启动任务。当队列不能满足最小资源时,可以从其它队列抢占。当队列资源使用不完时,可以给其它队列使用。这对于确保某些用户、组或生产应用始终获得足够的资源。 5、允许资源共享:即当一个应用运行时,如果其它队列没有任务执行,则可以使用其它队列,当其它队列有应用需要资源时再将占用的队列释放出来。所有的应用都从资源队列中分配资源。 6、默认不限制每个队列和用户可以同时运行应用的数量。可以配置来限制队列和用户并行执行的应用数量。限制并行执行应用数量不会导致任务提交失败,超出的应用会在队列中等待。 """
其中,apache版本的yarn默认使用的是容量调度器
如果需要使用其他的调度器,可以在yarn-site.xml中的yarn.resourcemanager.scheduler.class进行配置。















 2105
2105











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









