







目录
1.分而治之:有一个非常大的文件,计算文件每个单词出现的次数
2.分而治之+合理分区:有两个非常大的文件,每一行存放一个字符串,统计出两个文件相同的字符串
3.Hbase 布隆过滤器:一个非常大的文件,存着一行行的url,给一个url,怎么快速查找到这个url是否在这个文件中
一.什么是Hadoop?
诞生:为了处理大数据(简单粗暴)
本质:分而治之
在我理解中是分成三大部分:存储,计算,中间协调组件
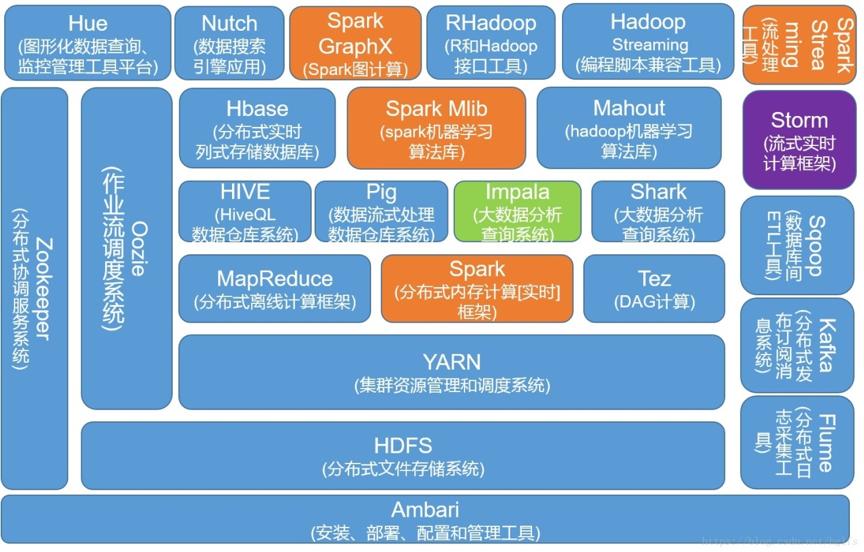
下面这张图(来自度娘)很好的画出了Hadoop的生态圈
二.Hadoop 经典问题来认识Hadoop的思想
1.分而治之:有一个非常大的文件,计算文件每个单词出现的次数
众人拾柴火焰高,面对大数据,一台机器算不过来而且性能也差,分多台机器算,是不是很像多线程的思想,如文件是1个T,那么把1个T的文件分成10个,由10台机器计算一个文件,每台机器统计出自己计算文件的单词,和单词出现的次数,算完之后,再由一台机器进行聚合,就可以得出最好的结果。
---这里用到的思想就是Hadoop的重要思想:分而治之
2.分而治之+合理分区:有两个非常大的文件,每一行存放一个字符串,统计出两个文件相同的字符串
如果用最粗暴的方法,遍历去取的话,性能会非常差,
(1)这里提出第一个想法,能否按照第一个问题的思路,
分而治之:用多台机器,或者分成多个任务来实现,答案是可以的:
我们将两个文件如:分别切成3个,那么每台机器分别拿着左边三个分区,跟右边的三个分区进行对比,分成了9个任务:A-->(A1,B1,C1),B-->(A1,B1,C1) , C-->(A1,B1,C1)。

用多台机器同时算的话,其实性能的消耗也非常大,因为每一台机器自己那部分也要跟另一个大文件做类似全表扫描的动作。
(2) 这时候我们遇到第一个问题就是:如何降低做类似全表扫描的动作
如果把相同的字符串放在相同的分区里,那么只要对应的分区做比较,不用与其他分区做比较,那么我们可以再进一步优化性能。
优化开始了:
两个大文件的字符串分别取hashcode值,然后按照分区数量取%,比如3个分区,就%3,相同的字符串的hashcode %3 得到的结果是一样的,那么就会落入同一个分区里面,那只要同个分区的相互比较即可,任务数量从9降到了3,而且性能也提升了。

---这里用到的思想就是Hadoop的重要思想:分而治之+合理分区
3.Hbase 布隆过滤器:一个非常大的文件,存着一行行的url,给一个url,怎么快速查找到这个url是否在这个文件中
快速快速快速!!!!!
(1) 能想到快的就是计数排序吧!
就是把url转化为数组的下标,通过下标取值是很快的,时间复杂度是O(n),但是计数排序是以空间换时间,它的缺陷有三个:
1.数组的长度不好确定
2.会造成空间的极大浪费
3.数组的类型不能确定
那我们能不能在这个解题思路上进行优化呢?比如可以确定下长度,类型,因为是超大的文件,如果能将数组的长度降低更好。
(2)解决长度:比如我们假设建立数组的长度为10000,那我们可以将这个文件的url求hashcode,然后%10000,将得到的值作为数组的索引;
解决类型:因为我们是想要找这个url在不在,所以对于目标文件的url得到的索引对应的值我们只要放0,1,0代表该索引对应的url是不存在的,1代表该索引对应的url是存在的,那么数组的类型就可以设置为byte类型;
以上的思路举个例子:
比如,想查找的url为:"https://blog.csdn.net/weixin_43850845?spm=1011.2124.3001.5343",假如在文件中存在这个url,那这个url取完hashcode 再%10000得到5,假设数组为 find[5]=1,那么我们直接查数组find[5]是否等于1,就知道在文件中是否存在目标url。
写到这里,大家应该发现了bug,如果文件中有另外个url hashcode取完%后也是等于5,那不就是有误判了么?
(3)hash算法没有绝对完美的 ,是 存在hash冲突的问题,数组长度越小冲突也就越大,没有完美的算法,那我们可以把误判率降到最低,最好是能接近于0。
解决方案:
多设计几个hash算法:
每一个url存数的时候 需要经过多个hash算法计算之后才能进行存储
比如:"https://blog.csdn.net/weixin_43850845?spm=1011.2124.3001.5343",用5个hash算法
hashcode01%10000=5;
hashcode02%10000=8;
hashcode03%10000=10;
hashcode04%10000=12;
hashcode05%10000=20;
那我们判断url是否存在,那我们只要求find[5],find[8],find[10],find[12],find[20]都等于1,代表存在,存在有一个或以上为0,则代表不存在。
但是!!! 仍然存在误判(因为仍然有可能存在另外一个url满足上述的值):
总结以上:
误判因素:
1.数组的长度 m 数组长度越长 误判率越低
2.hashCode的算法的个数 k 算法的个数越多 误判率越低的
3.数据量 数据量越小 误判率越低
那是否是把数组长度取到最长,hash算法全部都来一遍??这样子做,性能也会非常差,太多hash算法也是很耗性能,那hash算法到底取多少个的时候,性能又好,误判率又能足够低??
有的!!人类的脑袋真的太聪明了,False positives 概率推导(算法是我的弱项,所以我直接拿结果,乖乖做一个在前人栽树下乘凉的后人吧~~~)
即当k=0.7(m/n) 时,误判率最低,m数组长度,n是数据量
假如:m=100000 n=10000
那么 k=7 则只需要设计7个hash算法 误判率最低
但是误判一定存在 , 接近0
--整个思路就是布隆过滤器的大致思路,而布隆过滤器也是hbase的一个查询算法
三.Hadoop 进阶历史
1.总有高手能实现别人的论文理论
在没有Hadoop之前,很多搜索引擎公司都会遇到相同的问题,谷歌处理这些问题有对应的方案,但没有将代码开源,而是以论文的形式发表:
(1)如何存储日益增长的数据?---2003年,Google发布Google File System论文,简写为GFS,分布式文件存储系统
(2)如何对大数据进行计算?--2004年公布的 MapReduce论文,论文描述了大数据的分布式计算方式
(3)如何对大数据进行快速查询?--2006年,bigTable
而Doung cutting 看了这三篇论文后用java实现了,分别对应的是:
(1)GFS---->HDFS 分布式文件存储系统
(2)MapReduce-----> MapReduce 分布式计算
(3)bigTable ----->Hbase NoSql数据库
具体的论文地址和资源可以看下这位大佬的博客: https://blog.csdn.net/zhongqi2513/article/details/88708723















 766
766











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









