






本次选取泰坦尼克号的数据,利用python进行抽样分布描述,主要是提供实现代码,具体的理论知识不会过多涉及。(注:是否服从T分布不是进行t检验~)
字段说明:
Age:年龄,指登船者的年龄。
Fare:价格,指船票价格。
Embark:登船的港口。
需要验证的是:
1、验证数据是否服从正态分布?
2、验证数据是否服从T分布?
3、验证数据是否服从卡方分布?
我们选取年龄作为例子进行数据验证。
import pandas as pd
import numpy as np
path = 'D:\\数据\\data\\data.xlsx'
data = pd.read_excel(path)
# 按照港口分类,计算数据的统计量
embark = data.groupby(['Embarked'])
embark_basic = data.groupby(['Embarked']).agg(['count','min','max','median','mean','var','std'])
age_basic = embark_basic['Age']
fare_basic = embark_basic['Fare']
age_basic
fare_basic

1、 先验证价格年龄是否服从正态分布。
# 画出年龄的图像
import seaborn as sns
sns.set_palette("hls") #设置所有图的颜色,使用hls色彩空间
sns.distplot(data['Age'],color="r",bins=10,kde=True)
plt.title('Age')
plt.xlim(-10,80)
plt.grid(True)
plt.show()

#分别用kstest、shapiro、normaltest来验证分布系数
from scipy import stats
ks_test = stats.kstest(data['Age'], 'norm')
shapiro_test = stats.shapiro(data['Age'])
normaltest_test = stats.normaltest(data['Age'],axis=0)
print('ks_test:',ks_test)
print('shapiro_test:',shapiro_test)
print('normaltest_test:',normaltest_test)

由检验结果知,p <0.05,所以拒绝原假设,认为数据不服从正态分布。
# 绘制拟合正态分布曲线
age = data['Age']
plt.figure() #创建画纸
age.plot(kind = 'kde') #原始数据的分布,kde为概率密度曲线
M_S = stats.norm.fit(age) #返回一个数组,age的平均值[0]及标准差[1]
normalDistribution = stats.norm(M_S[0], M_S[1]) # 绘制拟合的正态分布图M_S[0]为平均值 M_S[1]为标准差
x = np.linspace(normalDistribution.ppf(0.01), normalDistribution.ppf(0.99), 100) #创建等差数列
plt.plot(x, normalDistribution.pdf(x), c='orange')
plt.xlabel('Age about Titanic')
plt.title('Age on NormalDistribution', size=20)
plt.legend(['age', 'NormDistribution'])
| 方法名 | 全称 | 功能 |
|---|---|---|
| rvs | Random Variates of given type | 对随机变量进行随机取值,通过size参数指定输出数组的大小 |
| Probability Density Function | 随机变量的概率密度函数,即知道 x 求 f(x) | |
| cdf | Cumulative Distribution Function | 随机变量的累积分布函数,它是概率密度函数的积分,即知道x 求p = F(x) |
| sf | Survival function | 随机变量的生存函数,它的值是1-cdf(t) |
| ppf | Percent point function | 累积分布函数的反函数,即知道 p = F(x) 反求 x |
| stat | statistics | 计算随机变量的期望值和方差 |
| fit | fit | 对一组随机取样进行拟合,找出最适合取样数据的概率密度函数的系数 |

2、 验证是否服从T分布?
ks = stats.t.fit(age)
df = ks[0]
loc = ks[1]
scale = ks[2]
ks2 = stats.t.rvs(df=df, loc=loc, scale=scale, size=len(age))
stats.ks_2samp(age, ks2)

由检验结果知,p <0.05,所以拒绝原假设,认为数据不服从T分布
# 绘制拟合的T分布图
plt.figure()
age.plot(kind = 'kde')
TDistribution = stats.t(ks[0], ks[1],ks[2])
x = np.linspace(TDistribution.ppf(0.01), TDistribution.ppf(0.99), 100)
plt.plot(x, TDistribution.pdf(x), c='orange')
plt.xlabel('age about Titanic')
plt.title('age on TDistribution', size=20)
plt.legend(['age', 'TDistribution'])

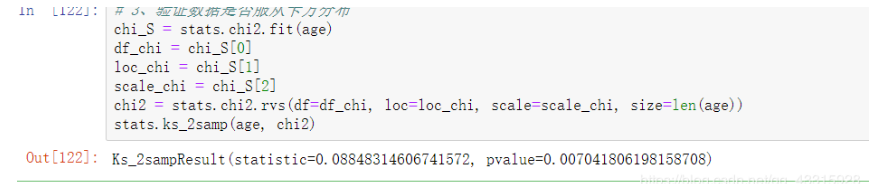
3、验证数据是否服从卡方分布
chi_S = stats.chi2.fit(age)
df_chi = chi_S[0]
loc_chi = chi_S[1]
scale_chi = chi_S[2]
chi2 = stats.chi2.rvs(df=df_chi, loc=loc_chi, scale=scale_chi, size=len(age))
stats.ks_2samp(age, chi2)
# 对数据进行卡方拟合
plt.figure()
age.plot(kind = 'kde')
chiDistribution = stats.chi2(chi_S[0], chi_S[1],chi_S[2]) # 绘制拟合的正态分布图
x = np.linspace(chiDistribution.ppf(0.01), chiDistribution.ppf(0.99), 100)
plt.plot(x, chiDistribution.pdf(x), c='orange')
plt.xlabel('age about Titanic')
plt.title('age on chi-square_Distribution', size=20)
plt.legend(['age', 'chi-square_Distribution'])
















 3718
3718











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









