



第一章 认识编译器
1.1 线上与线下
线上(online):在程序中,执行属于线上,即当程序被操作系统加载到内存中并被cpu开始对其进行解码并执行属于线上操作。这就好比一个工厂的生产线(CPU和内存等构成的执行环境),程序在这个生产线上开始运做。
举个栗子:当你在计算机上打开一个文字处理软件,操作系统将软件从硬盘加载到内存,然后CPU开始读取指令来显示软件的界面、处理用户的输入操作。
线下(off-line):不执行程序,仅仅只是生成可执行代码或者数据或者其他输出,但它不会去执行程序属于线下。
举个栗子:编译程序生成可执行代码的过程。这个编译过程本身没有让程序真正运行起来,只是为程序后续运行做准备。
1.2 编译器与解释器
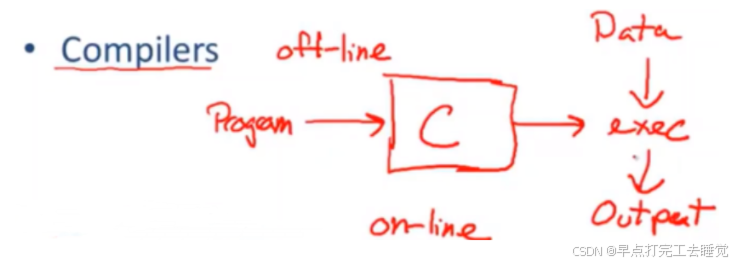
编译器
编译器属于线下,它只需要编译源代码文件然后生成可执行程序或者编译数据或者其他输出,不需要给数据。编译器不能直接执行程序,它需要编译,同时它也不会执行程序。
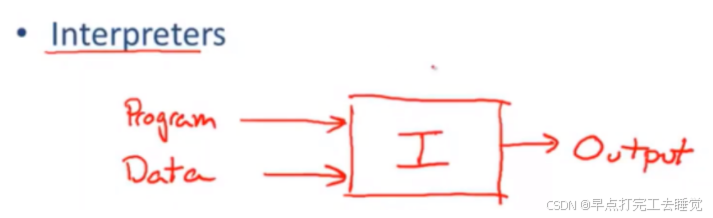
解释器
解释器属于线上,它必须输入一些数据才能执行。它通过将输入的数据或者命令进行解释并做相应处理,然后输出结果。例如python语言,一行一行的转译然后执行,不能一次性转译全部命令然后统一执行。
两者区别:
编译器:属于线下,只需要源代码就能生成可执行程序,不属于程序运行的一部分,属于生成程序的一部分。
解释器:属于线上,需要于解释器对应的指令集,他通过解析指令集然后执行,属于程序运行的一部分。
1.3 编译器的结构
-
词法分析:从左到右的顺序对源程序的字符流进行扫描,依据词法规则将其识别成单词序列。主要负责检测源程序的词法错误。(认识单词)
-
语法分析:基于词法分析得到的单词序列,依据语法规则来分析,构建对应的语法树。(明白句子结构)
-
语义分析:检查源程序的语义是否正确,负责解析变量类型是否匹配,作用域规则是否遵循等。(明白意思)
-
优化:负责对程序代码进行优化,使其更快运行,减少内存的使用。(编辑,将废话删掉)
-
代码生成:将代码转换成可执行代码或者其他语言,根据编译器的具体实现目标。(翻译成另一种语言)
1.4 三个问题
1.4.1 为什么会有那么多编程语言
科学计算--FORTRAN
科学通常应用于大型计算机主要的应用工程,也用于大科学和需要长时间运算的实验以及模拟实验上,
实现这种运算,编程语言需要满足有非常好的浮点运算的支持,简称FP,需要对数组操作有着很好的支持,因为大部分科学应用中最常见的数据类型就是有浮点数的大数组,
同时科学应用也需要并行运算,在一个大数面前最好的方式就是分治法,将一个问题拆分成许多个小问题,然后同时进行计算,在合并成一个解决方案。
商业领域--SQL
在这里你需要一些持久性的东西,这种方式必须可靠。并且你需要好的措施来生成报告,在性能上你可能需要很快的响应时间和查询时间来保证你能在需要的时候很快的取出数据并做相应的处理。
在许多现代企业中,数据是最有价值资产之一,你需要好的数据存储服务来你的数据进行分析以及处理,所以在商业领域里最常用的编程语言就是数据库语言,关系型数据库SQL。
系统编程
系统编程的重点在于如何做好对于资源的有效管理,需要在这些资源上进行细粒度的控制,防止资源的浪费。
通常在系统编程上回涉及到许多时间方面的问题,如:操作系统内核的时间轮询系统,和时间片中断线程之间的调度,还要英特尔的超时间片技术,所以你需要一些实时的限制,所以你需要能够对时间进行预判,实际上有一些设备需要在一定时间内才能作出反应。
但是在一个领域中最重要的东西,可能在另一个领域就不是那回事了,可以想象一下,如果将所有的东西都集成在一个系统址中,并且这些东西都能很好的支持,这是一件十分困难且庞大的事情,因为许多领域要求的很苛刻,你不能随意满足它们,且要求精度很高。
1.4.2 为什么会有新编程语言诞生
-
新的编程语言主要成本是培养程序员如何去使用这款编程语言。
-
广泛使用的编程语言会改变的很慢
-
很容易产生一门新的语言
-
使用新的语言来填补需求空白
-
新的编程语言将和旧的编程语言非常相似
1.4.3 什么样的编程语言是一门好语言
第二章 词法分析器
2.1 认识词法分析器
词法分析器的功能
1.分割输入串中的词素(lexeme)
2.识别出词素对应的词法单元(token class)
即将字符流转换成记号流。
词法分析器从左到右扫描输入串,有时需要向右边看消除部分子串的二义性。
单词符号
-
关键字:具有固定意义的标识符。
-
标识符:表示各种名字,如变量名、数组名、过程名等
-
常数类型:一般有整型,浮点型,布尔型,字符串
-
运算符:+,-,*,/等
-
界符:空格,逗号,分号,括号,/等
词法分析器所输出的单词符号尝尝表示如下二元式<单词种类,单词符号的属性值>,即<token class, lexeme>样式 。
举个栗子:输入字符串foo=42给词法分析器
词法分析器生成<id,"foo">,<Operator,"=">,<Integral,"42">,给解释器。
2.2 举例--FORTRAN
空格无关紧要,比如 a1和a 1一样
DO 5 I =1,25 //DO表示循环,变量I 从1到25,5表示循环的标签 DO 5 I =1.25 //变量名为DO5I
所以在FORTRAN中这两个都表示变量名DO5I
原因:早期的电脑打孔机很容易不经意间添加额外的空格。所以对于他而言空格无关紧要
2.3 词法分析器设计
2.3.1 输入
词法分析器开始工作的基础就是获取源程序文本内容,通常会将这些输入的内容放置在一个专门的缓冲区当中,这个缓冲区被称作输入缓冲区。
2.3.2 预处理
具体内容:
-
去除无关符:对于很多程序而言,像空白符、跳格符、回车符以及换行符等编辑性字符,除了在文字常数里有实际意义,在其他地方基本没有什么实质作用。另外,注释部分也并非程序运行所必需的。所以预处理阶段可以把这些没有太大作用的编辑性字符以及注解部分剔除。
-
处理空白符:有些程序语言会把空白符(单个或者连续)当做符号之间的间隔,也就是界符来使用。这时预处理程序就可以把连续出现的多个空白符合成一个空白符。
必要性:先对输入的源程序文本进行预处理,往往能让后续单词符号的识别工作更加便利。
分析器对扫描缓冲区进行扫描时一般用两个指示器,一个指向当前正在识别的单词的开始位置(指向新单词的首字符),另一个用于向前搜索以寻找单词的终点。
2.3.3 单词符号的识别:超前搜索
请看下面的例子: 1.DO99K=1,10 2.IF(5.EQ.M) I=10 3.DO99K=1.10 4.IF(5)=55 语句1和2分别是DO和IF语句,它们都是以基本字开头的。语句3和4是赋值句,它们都是以用户自定义标识符开头的。 语句1、3的区别在于等号之后的第一个界符:一个为逗点,另一个为句末符。
语句2、4的主要区别在于右括号后的第一个字符:一个为字母,另一个为等号。
2.3.4 状态转换图
圆圈 -> 状态
箭头 -> 状态的转换,通常附近会标明转换条件
星号 -> 再peek一个字符
双圆圈 -> 终态
2.4 正则表达式
2.4.1 为什么引入正则表达式
1.精确地描述单词模式
2.方便处理多种单词类型
3.易于实现和修改识别规则
4.高效的识别算法与之配合
2.4.2 什么是正则表达式
单个字符:a 空串:ε (表示空字符串) 选择(或):a|b(匹配 ‘a’ 或 ‘b’) 连接:ab(匹配 ‘a’ 后跟 ‘b’)
闭包:a* (*匹配 ‘a’ 出现零次或多次)
2.4.2.1 语法糖
[c1-cn] == c1|c2|...|cn
e+ == 一个或多个e
e? == 零个或多个e
a* == a*自身,不是a的klenn闭包
e{i,j} == i到j个e的连接
. == 除'\n'外的任意字符
例如:
十进制整数型规则:或者是0;或者是以1到9开头,后面跟0个或者多个0到9:0|[1-9] [0-9]*
2.4.2.2 如何用正则表达式来描述词法规则
-
keyword 关键字: 'if' 'else' 'then'
其中'if' == 'i''f'
-
integer 整数:非空digit串
digit=[0-9]表示(一位数字)
integer=digit digit*=digit+
-
identifier 标识符:
letter =[a-zA-Z]
identifier =letter(letter|digit)*
-
whitespace 空白:
whitespace=(' ' | '\n' | '\t')+
2.4.2.3 识别任意字符串属于某一语言
1.写出所有token class 的正则表达式
Number='digit'
Keyword='if'+'else'+...
identifier=letter(letter+digit)*
OpenPar='('
2.Lexical Speicification R=所有token class 的并
R = Keyword + identifier + Number + ... = r1 + r2 + r3 + ...
3.输入字符串x1...xn,针对字符串的某个前缀,判断其是否属于L(R)
for 1 <= i <= n 检查 x1...xi 属于 L(R)
4.如果3成立,那么x1...xi就属于L(R)
注意避免二义性:
1.总是选择最大的前缀x1.....xn
比如'=='不会看成两个'='
2.对给定前缀x1...xi,匹配其对应的token class中优先级最大的那个
比如:‘if'可能属于identifier或者keyword,此时优先识别keyword
3.设定error集合,表示不属于该语言的字符串。若输入此类字符串,则报错。把error放到最后,因为可能和前面的正确的正则表达式重合,所以error优先级最低
2.5 有限状态自动机(FA)
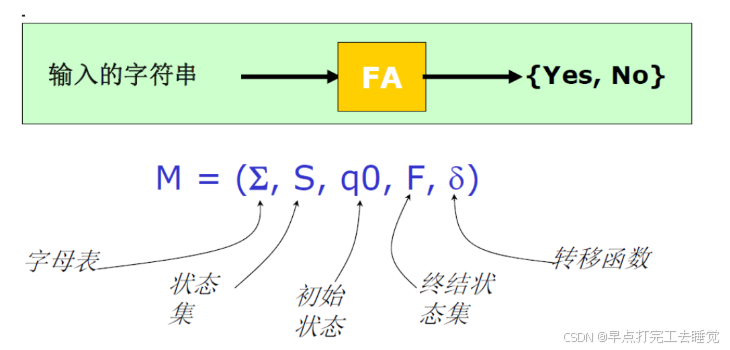
-
确定有限状态自动机 DFA
对任意的字符,最多有一个状态可以转移
-
非确定的有限状态自动机 NFA
对任意的字符,有多于一个状态可以转移
2.6 词法分析器流程
Lexical specification->Regular Expression->NFA->DFA->Table-driven Implementation of DFA
(词法规范 --> 正则表达式 --> 不确定的有穷自动机 --> 确定的有穷自动机 --> 一组查询表和一些遍历表的代码)
2.6.1 RE->NFA
e -> ε -> c -> e1 e2 e1∩e2 -> e1|e2 e1∪e2 -> e1*
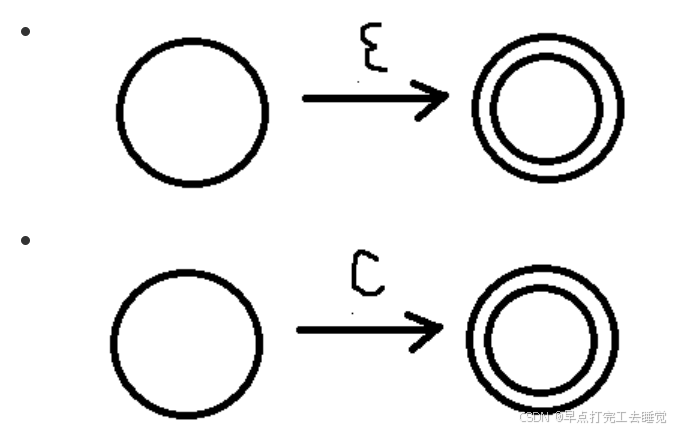
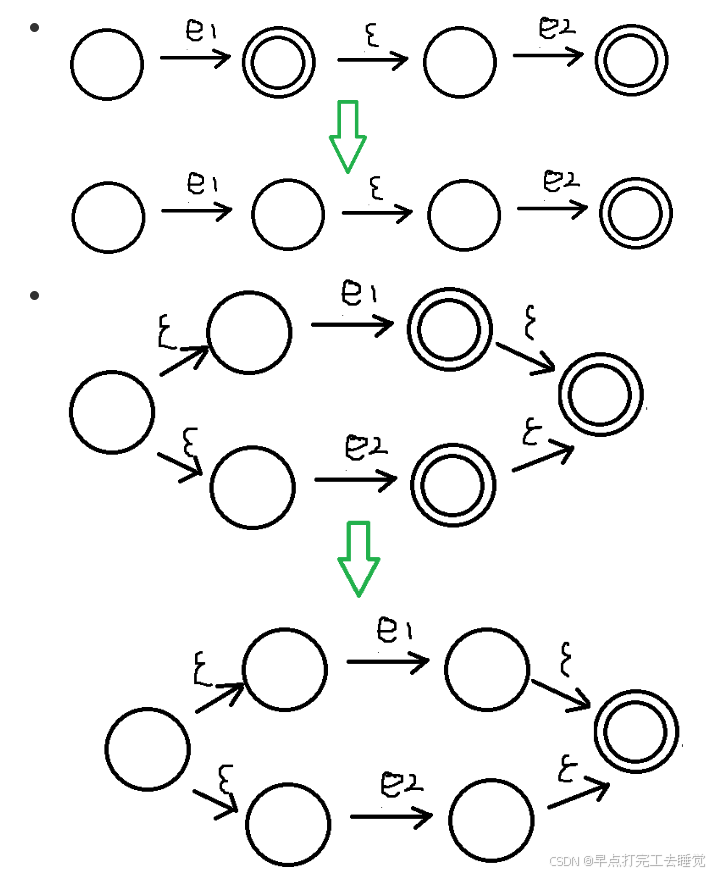
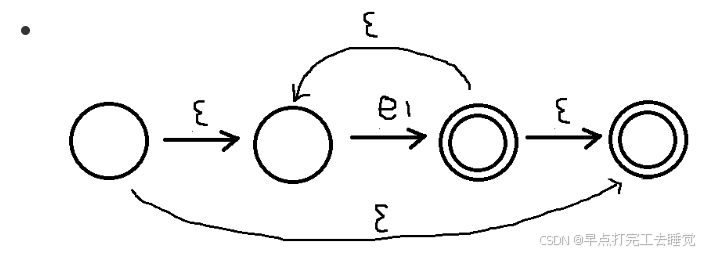
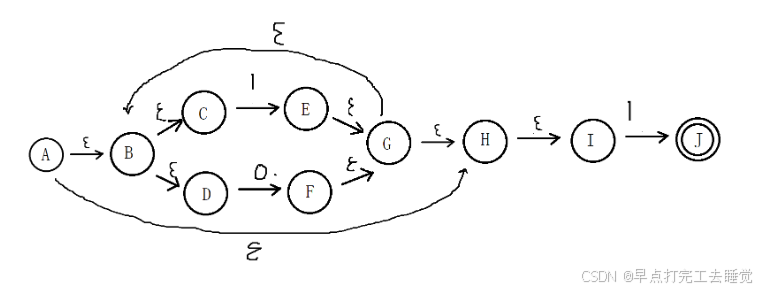
举个例子
(1+0)*1
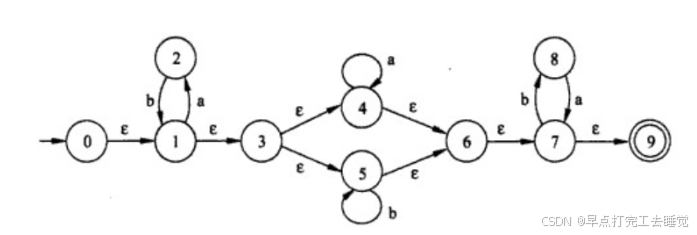
2.6.2 NFA -> DFA
子集构造法
| I | Ia | Ib |
|---|---|---|
| {0,1,3,4,5,6,7,9} | {2,4,6,7,9} | {5,6,7,8,9} |
| {2,4,6,7,9} | {4,6,7,9} | {1,3,4,5,6,7,8,9} |
| {5,6,7,8,9} | {7,9} | {5,6,7,8,9} |
| {4,6,7,9} | {4,6,7,9} | {8} |
| {1,3,4,5,6,7,8,9} | {2,4,6,7,9} | {5,6,7,8,9} |
| {7,9} | {8} | |
| {8} | {7,9} |
第一行第一列的结果是从NFA的起始节点经过任意个ε所能到达的结点集合。
Ia:集合开始经过一个a所能到达的集合,可以略过前后任意个ε
lb:集合开始经过一个b所能到达的集合,可以略过前后任意个ε
后续谁有变化拿出来进行运算,直到不出现变化。
由此可得一张表: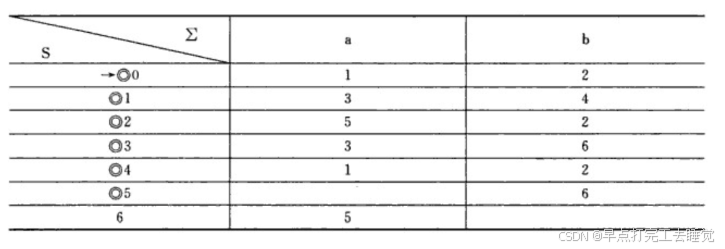
由这张表可以得到最后的DFA
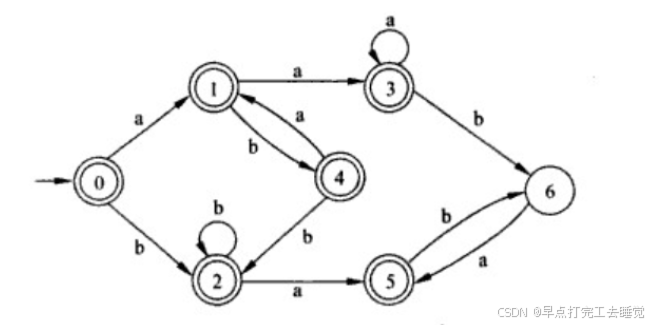
其中画成双圈是因为他的结果包含最后的终点。
2.6.3 DFA到词法分析器(最小化算法)
最小化就是寻求最小状态DFA
最小状态DFA的含义:
1.没有多余状态(死状态)
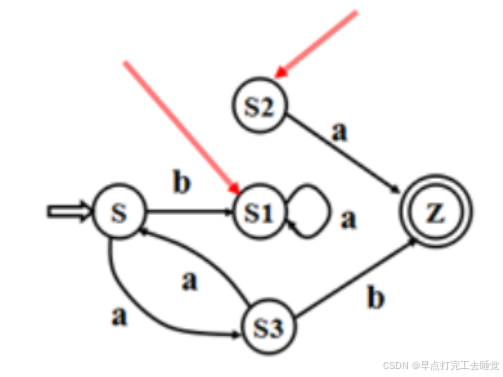
①从这个状态没有通路到达终态,例如S1
②从开始状态出发,任何输入串也不能到达的状态,例如S2
如何消除多余状态
删除
2.没有两个状态是互相等价(不可区别)
两个状态s和t的等价的条件:
兼容性(一致性)条件----同是终态或同是非终态
传播性(蔓延性)条件----对于所有输入符号,状态s和状态t必须转换到等价的状态里。
DFA的最小化—例子
第一步都是固定的。分成终态和非终态
1.将M的状态分为两个子集一个由终态k1={C,D,E,F}组成,一个由非终态k2={S,A,B}组成,
2.考察{S,A,B}是否可分.

因为A经过a到达C属于k1.而S经过a到达A属于k2.B经过a到达A属于k2,所以K2继续划分为{S,B},{A},
3.考察{S,B}是否可再分:
B经过b到达D属于k1.S经过b到达B属于k2,所以S,B可以划分。划分为{S},{B}
4.考察{C,D,E,F}是否可再分: 因为C,D,E,F经过a和b到达的状态都属于{C,D,E,F}=k1所以相同,所以不可再分:
5.{C,D,E,F}以{D}来代替则,因为CDEF相同,你也可以用C来代替。最小化的DFA如图,: 
2.7 实现一个简单的词法分析器
#include <iostream>
#include <stack>
#include <string>
#include <regex>
#include <vector>
using namespace std;
// 定义Token类型
enum TokenType {
IDENTIFIER, // 标识符
NUMBER, // 数字
PLUS, // 加号 +
MINUS, // 减号 -
MUL, // 乘号 *
DIV, // 除号 /
EOF_TOKEN, // 文件结束
LPAREN, // 左括号
RPAREN, // 右括号
ASSIGN // 赋值
};
//词法分析器
typedef struct Token {
TokenType type; // 记号类型
std::string value; // 记号的值
Token(TokenType t, const std::string& v) : type(t), value(v) {} // 构造函数
}Token;
class Lexer {
public:
Lexer(const std::string& input) : input(input), pos(0) {}
std::vector<Token> tokenize() {
std::vector<Token> tokens;
while (pos < input.length()) {
skipWhitespace(); // 跳过空白字符
if (pos >= input.length()) break;
char currentChar = input[pos];
if (std::isalpha(currentChar)||currentChar=='_') { // 标识符
tokens.push_back(processIdentifier());
}
else if (std::isdigit(currentChar)) { // 数字
tokens.push_back(processNumber());
}
else {
switch (currentChar) {
case '+':
tokens.push_back(Token(PLUS, "+"));
advance();
break;
case '-':
tokens.push_back(Token(MINUS, "-"));
advance();
break;
case '*':
tokens.push_back(Token(MUL, "*"));
advance();
break;
case '/':
tokens.push_back(Token(DIV, "/"));
advance();
break;
case '(':
tokens.push_back(Token(LPAREN, "("));
advance();
break;
case ')':
tokens.push_back(Token(RPAREN, ")"));
advance();
break;
case '=':
tokens.push_back(Token(ASSIGN, "="));
advance();
break;
default:
std::cerr << "Unrecognized character: " << currentChar << std::endl;
advance();
break;
}
}
}
tokens.push_back(Token(EOF_TOKEN, "EOF")); // 添加文件结束标记
return tokens;
}
private:
std::string input; // 输入字符串
size_t pos; // 当前读取位置
void advance()
{
pos++;
}
char currentChar()
{
return input[pos];
}
void skipWhitespace()
{
while (pos < input.length() && std::isspace(input[pos]))
{
advance();
}
}
Token processIdentifier() {
size_t start = pos;
static const std::regex identifierRegex("[_a-zA-Z][a-zA-Z0-9_]*");
// 移动到标识符的末尾
while (pos < input.length() && (std::isalnum(input[pos]) || input[pos] == '_')) {
advance();
}
// 提取标识符字符串
std::string value = input.substr(start, pos - start);
// 检查是否匹配标识符正则表达式
if (std::regex_match(value, identifierRegex)) {
return Token(IDENTIFIER, value); // 匹配成功,返回Token
}
else {
// 匹配失败,抛出异常或进行错误处理
throw std::runtime_error("Invalid IDENTIFIER format");
}
}
Token processNumber() {
size_t start = pos;
static const std::regex numberRegex("-?(0|[1-9][0-9]*)(\\.[0-9]+)?");
// 移动到数字的末尾
while (pos < input.length() && (std::isdigit(input[pos]) || input[pos] == '.' || input[pos] == '-')) {
advance();
}
std::string value = input.substr(start, pos - start);
if (std::regex_match(value, numberRegex)) {
return Token(NUMBER, value);
}
else {
throw std::runtime_error("Invalid number format: " + value);
}
}
};
void printTokens(const std::vector<Token>& tokens) {
for (const auto& token : tokens) {
std::cout << "Token(";
switch (token.type) {
case IDENTIFIER: std::cout << "IDENTIFIER"; break;
case NUMBER: std::cout << "NUMBER"; break;
case PLUS: std::cout << "PLUS"; break;
case MINUS: std::cout << "MINUS"; break;
case MUL: std::cout << "MUL"; break;
case DIV: std::cout << "DIV"; break;
case LPAREN:std::cout << "LPAREN"; break;
case RPAREN:std::cout << "RPAREN"; break;
case ASSIGN:std::cout << "ASSIGN"; break;
case EOF_TOKEN: std::cout << "EOF"; break;
}
std::cout << ", " << token.value << ")" << std::endl;
}
}
int main() {
std::string input = "abc 123 + _def - 45.6 * 789 /"; // 输入字符串
Lexer lexer(input); // 创建Lexer对象
std::vector<Token> tokens = lexer.tokenize(); // 生成Token列表
printTokens(tokens); // 打印Token列表
return 0;
}第三章 语法分析器
3.1 语法分析器的任务
(1)根据词法分析器提供的记号流,为语法正确的输入构造分析树。
(2)检查输入中的语法错误,并调用出错处理器进行适当处理。
3.1.1 路线图
-
数学理论:上下文无关文法(CFG)
描述语言语法规则的数学工具
-
自顶向下分析
递归下降分析算法(预测分析算法)
LL分析算法
-
自底向上分析
LR分析算法
3.1.2 文法分类
0型(任意文法),1型(上下文有关),2型(CFG),3型(正则)
3.1.3 语法错误的处理原则
3.1.3.1 源程序中可能出现的错误
-
语法错误
词法错误:非法字符或关键字、标识符拼写错误
语法错误:语法结构出错,如少分号,括号不匹配
-
语义错误
静态语义错误:编译时检查出的错误,如类型不一致,参数不匹配等
动态语义错误:程序运行时的逻辑错误,如无限递归,变量为0时作为除数等
大多数错误的诊断和恢复集中在语法分析阶段,因为大多数错误是语法错误,另一个原因是语法分析方法的准确性。
3.1.3.2 语法错误处理目标
-
清楚而准确地报告错误的出现,地点正确,不漏报,不错报,不多报
-
迅速地从每个错误中恢复过来,以便分析继续进行
-
对语法正确源程序的分析速度不应降低太多
3.2 上下文无关文法(CFG)
3.2.1 定义
上下文无关文法是一个四元组G=(N,T,P,S):
-
终结符:T
-
非终结符:N N∩T=∅
-
开始符号:S 非终结符
-
产生式:P,每个产生式形如A->α,其中A∈N,被称为产生式的左部,α∈(N∪T)*,被称为产生式的右部。若α=ε,则A->ε为空产生式
举个栗子:
定义简单算术表达式的上下文无关文法G3.1=(N,T,P,S)如下所示。
N={E} T={+,*,(,),–,id} S=E
P:
E → E + E (1)
E → E * E (2)
E → (E) (3)
E → –E (4)
E → id (5)
产生式的缩写形式:E->E+E | E*E | (E) | -E | id
一般用大写英文字母A、B、C表示非终结符,小写英文字母表示终结符,小写希腊字符表示任意文法符号序列。
3.2.2 推导
通过推导可以产生CFG所描述的语言。
推导就是从文法的开始符号S开始,反复使用产生式,将产生式左部的非终结符替换为右部的文法符号序列,直到得到一个终结符序列。
3.2.2.1 性质
-
对于任何α,有α=>α;即任何文法序列可以推导出它本身
-
若α=>β,β=>γ,则α=>γ;即推导具有传递性。
例如:
以3.2.1中的例子 E => E+E => (E)+(E) => id + id
E => -E => -(E) => -(E+E) => -(id+id)
3.2.2.2 形式
最左推导:在推导过程中,若每次直接推导均替换句型最左边的非终结符,则称为最左推导,由最左推导产生的句型被称为左句型。
最右推导:在推导过程中,若每次直接推导均替换句型最右边的非终结符,则称为最右推导,由最右推导产生的句型被称为右句型,也称为规范推导。
【例如】E→E+E|E∗E|(E)|−E|id,写出串 −(id+id)的推导。
最左推导:每次直接推导均替换句型中最左边的非终结符。 E⇒lm−E⇒lm−(E)⇒lm−(E+E)⇒lm−(id+E)⇒lm−(id+id)
最右推导:每次直接推导均替换句型中最右边的非终结符。 E⇒rm−E⇒rm−(E)⇒rm−(E+E)⇒rm−(E+id)⇒rm−(id+id)
3.2.3 与正则表达式之间的关系
在正则定义中不允许递归定义的,例如 A->aA|b不是一个正则定义。而上下文无关文法则没有约束。
正则表达式可以转换为上下文无关文法:对于任何一个正则表达式,都可以构造一个上下文无关文法来生成相同的语言。例如,对于正则表达式a(b|c)d,可以构造如下上下文无关文法:
-
非终结符:S(开始符号)
-
终结符:a、b、c、d
-
产生式规则:
-
s->aA
-
A->bD|cD
-
D->d
这样,这个上下文无关文法生成的语言和给定的正则表达式所表示的语言是相同的。
-
3.2.4 语法分析
给定文法G和句子S,语法分析要回答的问题:是否存在对句子S的推导
3.3 分析树与语法树
3.3.1 分析树
①根由开始符号标记
②每个叶子由一个终结符、非终结符或ε标记
③每个内部结点由一个非终结符标记
④若 A->X1x2...xn是一个产生式,则x1,x2,....,xn是标记为A的内部节点从左到右所有孩子的标记。若A->ε,则标记为A的结点可以仅由一个标记为ε的孩子。
分析树与文法和语言存在下述关系:
①每一个直接推导(或每个产生式),对应一棵仅有父子关系的子树,即产生式左部非终结符长出右部的孩子;
②分析树的叶子从左到右,构成G的一个句型。若叶子仅由标记符标记,则构成一个句子。
分析树与推导的关系:
①和推导所用的顺序无关(最左,最右,其他)
②每棵分析树都可以对应唯一的最左推导或最右推导;但每个句子(产生式)不一定只有一颗分析树,也就是说每个句子不一定只有一个最左推导或者最右推导。
举个例子:采用最左推导产生句子id+id*id
N={E} T={+,*,(,),–,id} S=E
P:
E → E + E (1)
E → E * E (2)
E → (E) (3)
E → –E (4)
E → id (5)
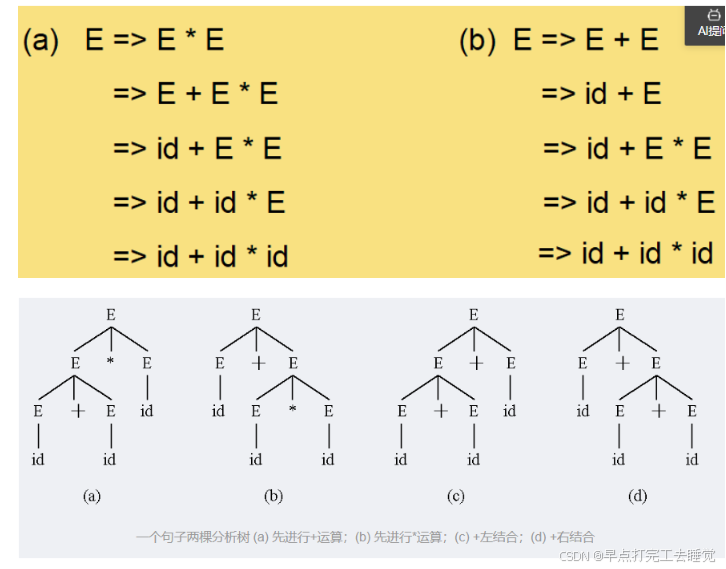
3.4 二义性与二义性的消除
3.4.1 二义性
若文法G对于同一个句子产生不止一颗分析树,则称G是二义的。
产生原因:文法中缺少对文法符号优先级和结合性的规定
一个句型有多于一颗分析树,仅与文法和句型有关,与采用的推导方法无关。
二义性会导致程序在执行过程中产生不同的结果,在程序设计中是不被允许的
3.4.2 二义性的消除
3.4.2.1 为文法符号规定优先级和结合性
E -> E+E | E*E | id | -E | (E)
变化为 :
E -> T | E + T
T -> F | T*F
F -> id | -E| (E)
此时推导变为 E => E+T => T+T*F => F +F * F=>id+id*id
3.4.2.2 消除左递归
对于任何输入串,从文法开始符号(根节点)出发,自上而下,从左到右的为输入串建立语法分析树
消除左递归:如果不消除,输入AA字符永远往下递归,到不了ε,也就是到不了终结符,无法停止。
左递归:A -> Aα|β
消除左递归:A -> βA'
A' -> αA'|ε
算术表达文法


3.4.3 提左因子
该方法用于消除回溯
提左因子也是一种文法变换,它用于产生适于自上而下分析的文法。在自上而下的分析中,当不清楚应该用非终结符A的哪个选择来替换它时,可以重写A产生式来推迟这种决定,推迟到看到足够多的输入,能帮助正确决定所需选择为止。

3.5 自顶向下分析
3.5.1 基本思想
语法分析:给定文法G和句子s,回答s是否能够从G推导出来?
从G的开始符号出发,随意推导出某个句子t,比较t和s
-
若t==s,则回答是
-
若t!=s,则回答?
3.5.2 递归下降分析法
算法基本思想
-
每个非终结符构造一个分析函数
-
用前看符号指导产生式规则的选择
3.5.3 LL(1)预测分析法
first集(包含空串)
-
定义:对于一个文法符号(可以是终结符或非终结符)X,FIRST(X)是由推导出的所有可能串的第一个终结符的集合。如果X能推导出空串ε,那么ε也属于FIRST(X)。
-
作用:在语法分析中,特别是自顶向下的语法分析(如递归下降分析法)中,FIRST集用于预测分析。它帮助确定在分析一个非终结符时,应该匹配哪些终结符作为开始。
-
计算规则

简单来说:A第一个能推出来什么
follow集(不包含空串)
-
定义:对于非终结符A,FOLLOW(A)是所有可能在某个句型中紧跟在A后面的终结符的集合。如果A是某个产生式右部的最后一个符号,并且可以推导出空串,那么FOLLOW(A)还包括紧跟在产生式左部符号后面的终结符。
-
作用:在语法分析中,FOLLOW集与FIRST集一起用于自顶向下的语法分析和自底向上的语法分析(如算符优先分析法等)。它可以帮助确定在分析一个非终结符时,哪些终结符可以在它之后出现。

-
即先看开始符,加#;
看右边A后面有东西(该东西不能==ε),First(东西)加入Follow(A),扣除ε
看右边A后面没有东西,Follow(左边)加入Follow(A)
举个栗子: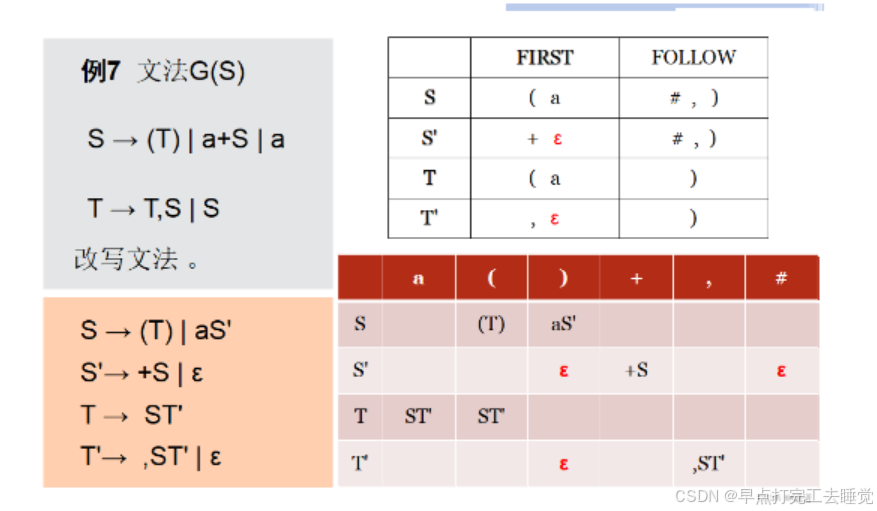
LL(1)文法
是一种不带回溯的非递归自上而下的分析法。
从左(L)向右读入程序,最左(L)推导,采用一个(1)前看符号
基本思想
表驱动的分析算法
LL(1)分析器
-
一张LL(1)分析表(预测分析表)
-
一个先进后出分析栈
-
一个控制程序(表驱动程序)
3.5.4 给出算术表达式文法求某输入串的分析过程
-
消除左递归
-
消除回溯即提取公共左因子
-
求解文法的FIRST集和FOLLOW集
-
构造LL(1)分析表
-
首先求出每个非终结符的 FIRST 和FOLLOW 集
-
然后按以下四个步骤构造分析表: ①对文法 G 的每个产生式 A → α执行 ② 和③ 步; ②对每个终结符 a ∈ FIRST(A),把 A → α 加至 M[A, a]中,其中 α 为含有首字符 a 的候选式或唯一的候选式 ③若ε ∈ FIRST(A),则对任何 b ∈ FOLLOW(A) 把 A → ε 加至 M[A, b]中 ④把所有无定义的 M[A,a]标“出错 标志”
-
-
若预测分析表 M 含有多重定义入口冲突项,则该文法不是LL(1)文法。遵从就近匹配原选定唯一候选式得到无二义的LL(1)分析表。
-
输入串分析过程:分析开始时栈底先放入一个“#”,然后再压入文法的开始符号;当分析栈中仅剩“#”,输入串指针也指向串尾的“#”时,分析成功。
3.5.5 LL1弱点
(1) 文法比较难写。因为按照人们习惯写出的文法,往往含有左递归和左因子。虽然有成熟的算法可以消除左递归和提取左因子,但改写之后的文法很难读也很难使用。同时对比分析树可以看出,改写后文法构造的分析树不直观且推导步骤增加。
(2) LL(1)文法适应范围有限,对于有些语言,往往写不出它的LL(1)文法。
3.5.6 实现一个简单的自顶向下的语法分析器
#include <iostream>
#include <stack>
#include <string>
#include <regex>
#include <vector>
using namespace std;
// 定义Token类型
enum TokenType {
IDENTIFIER, // 标识符
NUMBER, // 数字
PLUS, // 加号 +
MINUS, // 减号 -
MUL, // 乘号 *
DIV, // 除号 /
EOF_TOKEN, // 文件结束
LPAREN, // 左括号
RPAREN, // 右括号
ASSIGN // 赋值
};
//词法分析器
typedef struct Token {
TokenType type; // 记号类型
std::string value; // 记号的值
Token() {}
Token(TokenType t, const std::string& v) : type(t), value(v) {} // 构造函数
}Token;
class Lexer {
public:
Lexer(const std::string& input) : input(input), pos(0) {}
std::vector<Token> tokenize() {
std::vector<Token> tokens;
while (pos < input.length()) {
skipWhitespace(); // 跳过空白字符
if (pos >= input.length()) break;
char currentChar = input[pos];
if (std::isalpha(currentChar) || currentChar == '_') { // 标识符
tokens.push_back(processIdentifier());
}
else if (std::isdigit(currentChar) || (currentChar == '-' && (pos + 1 < input.length() && std::isdigit(input[pos + 1])))) {
tokens.push_back(processNumber());
}
else {
switch (currentChar) {
case '+':
tokens.push_back(Token(PLUS, "+"));
advance();
break;
case '-':
tokens.push_back(Token(MINUS, "-"));
advance();
break;
case '*':
tokens.push_back(Token(MUL, "*"));
advance();
break;
case '/':
tokens.push_back(Token(DIV, "/"));
advance();
break;
case '(':
tokens.push_back(Token(LPAREN, "("));
advance();
break;
case ')':
tokens.push_back(Token(RPAREN, ")"));
advance();
break;
case '=':
tokens.push_back(Token(ASSIGN, "="));
advance();
break;
default:
std::cerr << "Unrecognized character: " << currentChar << std::endl;
advance();
break;
}
}
}
tokens.push_back(Token(EOF_TOKEN, "EOF")); // 添加文件结束标记
return tokens;
}
private:
std::string input; // 输入字符串
size_t pos; // 当前读取位置
void advance()
{
pos++;
}
char currentChar()
{
return input[pos];
}
void skipWhitespace()
{
while (pos < input.length() && std::isspace(input[pos]))
{
advance();
}
}
Token processIdentifier() {
size_t start = pos;
static const std::regex identifierRegex("[_a-zA-Z][a-zA-Z0-9_]*");
// 移动到标识符的末尾
while (pos < input.length() && (std::isalnum(input[pos]) || input[pos] == '_')) {
advance();
}
// 提取标识符字符串
std::string value = input.substr(start, pos - start);
// 检查是否匹配标识符正则表达式
if (std::regex_match(value, identifierRegex)) {
return Token(IDENTIFIER, value); // 匹配成功,返回Token
}
else {
// 匹配失败,抛出异常或进行错误处理
throw std::runtime_error("Invalid IDENTIFIER format");
}
}
Token processNumber() {
size_t start = pos;
static const std::regex numberRegex("-?(0|[1-9][0-9]*)(\\.[0-9]+)?");
// 移动到数字的末尾
while (pos < input.length() && (std::isdigit(input[pos]) || input[pos] == '.' || input[pos] == '-')) {
advance();
}
std::string value = input.substr(start, pos - start);
if (std::regex_match(value, numberRegex)) {
return Token(NUMBER, value);
}
else {
throw std::runtime_error("Invalid number format: " + value);
}
}
};
void printTokens(const std::vector<Token>& tokens) {
for (const auto& token : tokens) {
std::cout << "Token(";
switch (token.type) {
case IDENTIFIER: std::cout << "IDENTIFIER"; break;
case NUMBER: std::cout << "NUMBER"; break;
case PLUS: std::cout << "PLUS"; break;
case MINUS: std::cout << "MINUS"; break;
case MUL: std::cout << "MUL"; break;
case DIV: std::cout << "DIV"; break;
case LPAREN:std::cout << "LPAREN"; break;
case RPAREN:std::cout << "RPAREN"; break;
case ASSIGN:std::cout << "ASSIGN"; break;
case EOF_TOKEN: std::cout << "EOF"; break;
}
std::cout << ", " << token.value << ")" << std::endl;
}
}
class Parser {
public:
Parser(const string& input) {
Lexer lexer(input);
tokens = lexer.tokenize();
tokenIt = tokens.begin();
lookAhead = *tokenIt++;
}
void parse() {
E();
if (lookAhead.type != EOF_TOKEN) {
throw std::invalid_argument("Unexpected token at end of input");
}
std::cout << "Parsing successful!" << std::endl;
}
private:
std::vector<Token> tokens;
std::vector<Token>::iterator tokenIt;
Token lookAhead;
void match(TokenType expected) {
if (lookAhead.type == expected) {
if (tokenIt != tokens.end()) {
lookAhead = *tokenIt++;
}
else {
lookAhead = Token(EOF_TOKEN, "EOF");
}
}
else {
throw std::invalid_argument("Unexpected token: " + lookAhead.value);
}
}
void E()
{
T();
EPrime();
}
void EPrime()
{
if (lookAhead.type == PLUS)
{
match(PLUS);
T();
EPrime();
}
else if (lookAhead.type == MINUS)
{
match(MINUS);
T();
EPrime();
}
}
void T() {
F();
TPrime();
}
void TPrime() {
if (lookAhead.type == MUL) {
match(MUL);
F();
TPrime();
}
else if (lookAhead.type == DIV) {
match(DIV);
F();
TPrime();
}
}
void F() {
if (lookAhead.type == LPAREN) {
match(LPAREN);
E();
match(RPAREN);
}
else if (lookAhead.type == NUMBER) {
match(NUMBER);
}
else {
throw std::invalid_argument("Unexpected token: " + lookAhead.value);
}
}
};
int main() {
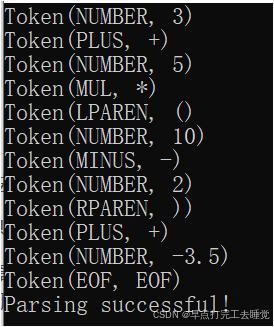
std::string input = "3 + 5 * (10 - 2) + -3.5"; // 输入字符串
Lexer lexer(input); // 创建Lexer对象
std::vector<Token> tokens = lexer.tokenize(); // 生成Token列表
printTokens(tokens); // 打印Token列表
Parser parser(input);
parser.parse();
return 0;
}
3.6 自底向上
3.6.1 LR分析
LR文法:对于一个文法,如果能够构造一张分析表,使得它的每个入口均是唯一确定的,则我们将这个文法称为LR文法。
LR(K)文法:一个文法如果能用一个每步最多向前检查k个输入符号的LR分析器进行分析,则这个文法称为LR(k)文法,一般k=0|k=1.
1.LR的含义
L:算法从左(L)向右的处理输入符号(tokens)
R:最右(L)推导,由最右推导构造分析树
数字:使用输入中的“多少个符号”来作预测分析。
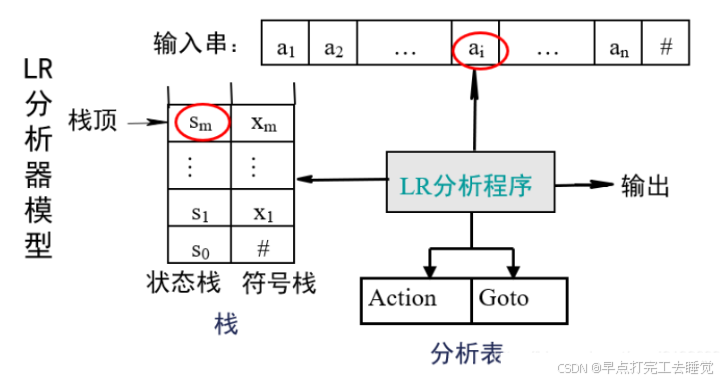
分析程序:对所有的LR分析器总控程序都是相同的。
分析表/分析函数:不同的文法分析表不同,同一个文法采用LR分析器不同时,生成的分析表也不同。分析表可以分为动作表(ACTION)和状态转换表(GOTO)两个部分,他们都可以用二维数组表示。
Action:终结符
Goto:非终结符
分析栈:包括文法符号站和对应的状态栈,先进后出。
Action[Sm,Ai];当前状态Sm面对输入符号Ai时采取的动作: (1)移进---sj (2)归约---rj (3)接受---accept (4)报错---error/出错
2.与LL分析法相比较
相同点:都是表驱动
不同点:
| - | LL | LR |
|---|---|---|
| 表内元素 | 文法规则 | 移进、规约 |
| 表格的纵列 | 非终结符 | 状态 |
| 状态转移 | 否 | goto |
3.解释名词
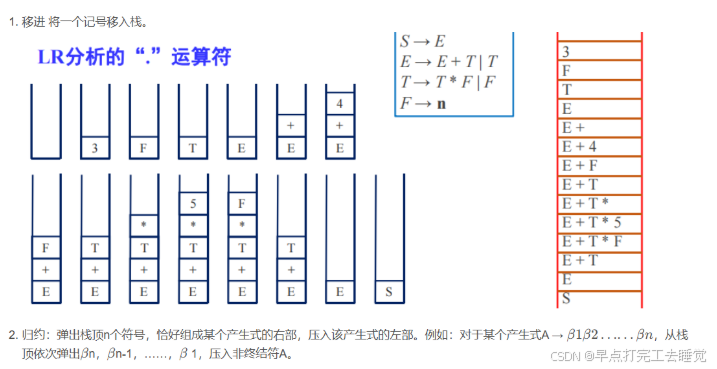
(1)移进
-
定义:自底向上的语法分析过程中,移进操作是指将输入串的下一个符号移入到分析栈中。
-
作用:通过不断地输入符号,逐步构建语法结构
-
示例:输入串"a+b"和一个分析栈。在分析开始时,分析栈为空。首先执行移进操作,将“a"移入分析栈,此时分析栈变为"a"。
点记号:为了方便标记语法分析器已经读入了多少输入,我们可以引入一个点记号.
E + 3 . * 4 .之前的代表已经读入的
(2) 规约
-
定义:是指当分析栈顶的符号序列形成了某个产生式的右部时,将这些符号替换为产生式的左部非终结符。
-
作用:通过规约,可以从输入串的终结符逐步构建出非终结符,最终确定输入串是否符合给定的文法。
-
示例:

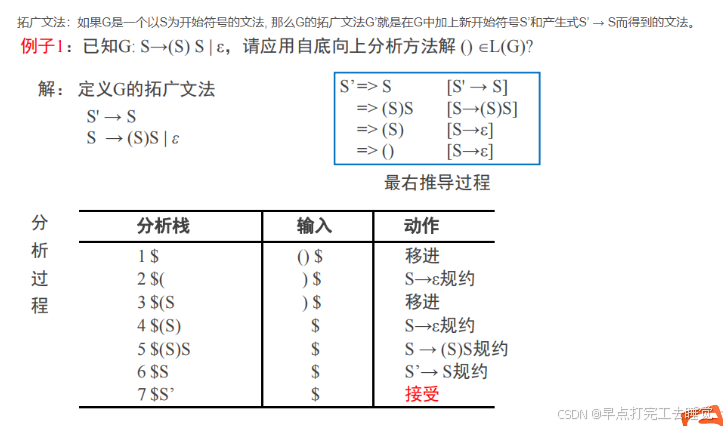
4.LR分析的简单示例与基本思想
(1)写出分析
不难发现LR分析是最右推导。
(2)构建分析栈
5.LR分析法的一般形式

举个栗子:
3.6.2 LR(0)
1.LR(0)的项(构建有穷自动机的状态)
-
定义:一个文法G的LR(0)项是G的一个产生式,同时加上它右部体中某处的点。
-
例如:A->XYZ的项包括:
A->.XYZ
A->X.YZ
A->XY.Z
A->XYZ.
A->ε的项包括:A->.
-
格式是:已识别的·期望识别的,前面是已处理的,后面是待输入的 非终结符、终结符均可状态转移
形如 A→ · α 的项目称为初始项目; 形如 A→α · 的项目称为归约项目(完整项目); 形如 A→ · Bβ 的项目称为待约项目(基本项目) B∈N; 形如 A→α · aβ 的项目称为移进项目(基本项目) a∈T
2.LR(0)的项目闭包(构建有穷自动机的状态)
设I是文法G的一个LR(0)项目集合,I的项目闭包CLOSURE(I)定义如下:
(1)I ⊆ CLOSURE(I)。 (2)若项目A ->α · Bβ ∈ CLOSURE(I),且 B -> η 是G的产生式,则项目B -> ·η ∈ CLOSURE(I)。(有几条闭包几条,可以一直往后闭包) (3)CLOSURE(I)仅包含上述两条规则确定的LR(0)项目。
3.LR(0)有穷自动机的构建
(1)LR(0)项->NFA->DFA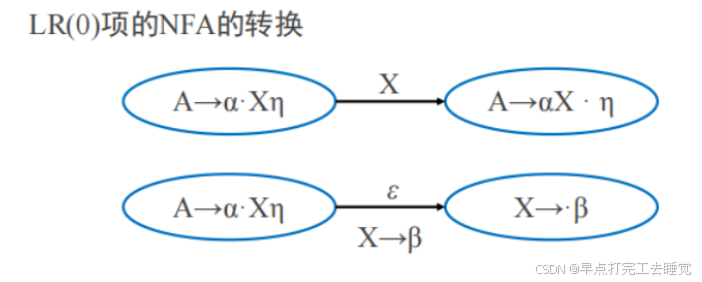
(2)举个例子
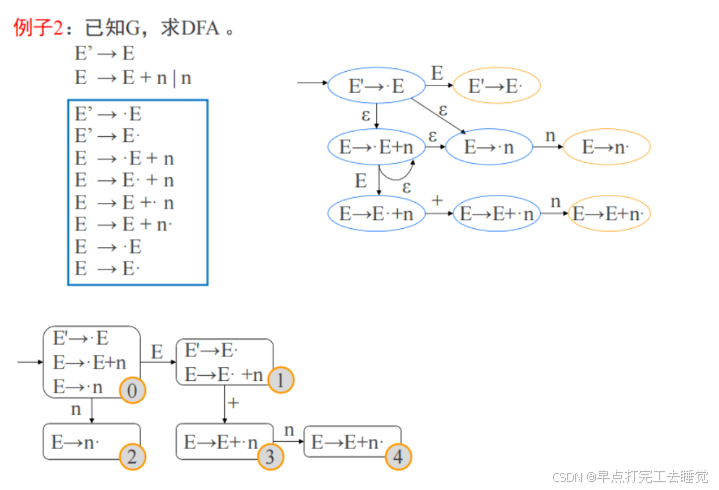
4.LR(0)的分析表
(1)规定:纵列是状态,action里是终结符。
goto是非终结符,s表示shift移进(到某状态)。
r表示reduce规约(用第几条规则),goto表示去到第几个状态。 DFA当中,第一条文法的规约是遇到终结符acc。
规约项目用相应规则规约,遇到任意字符都规约。
待约项目goto其他状态;待移进项目吃入字符移进。
(2)举个栗子

分析过程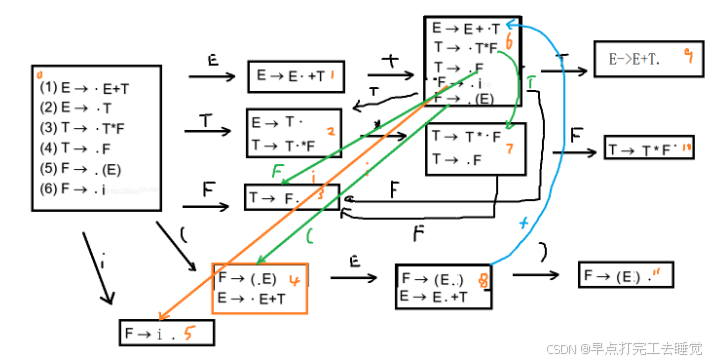
分析表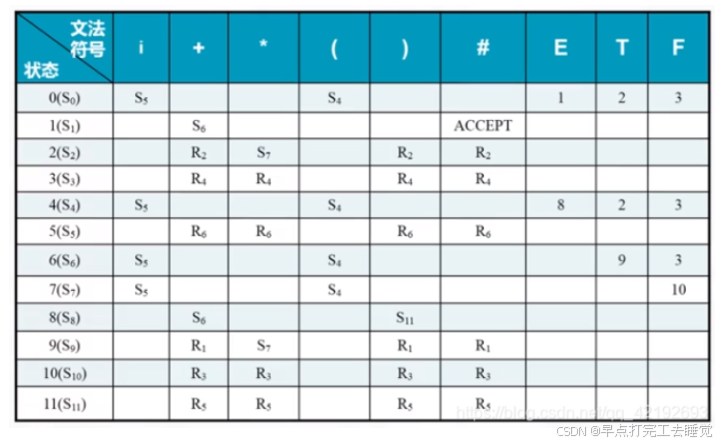
分析栈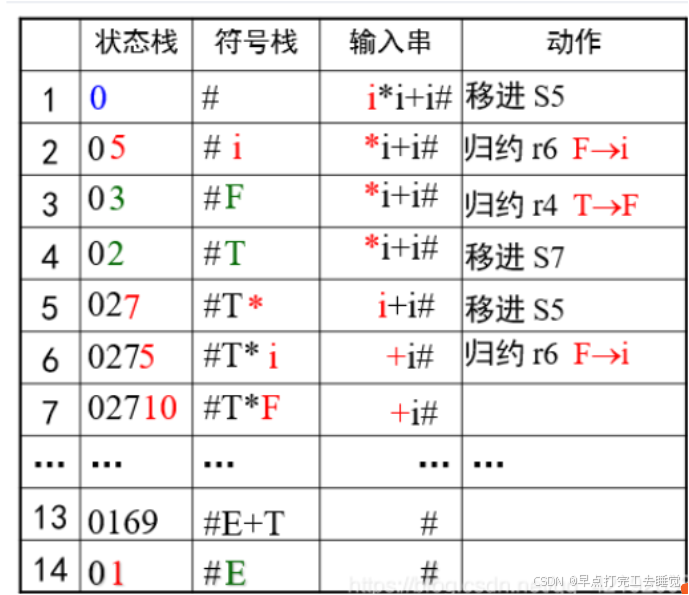
分析 i*i+i //r3:按照第三条文法归约 //这里先不要关分析表从哪里来,之后会有,,, 1:栈顶0,符号i——查表——S5(移进S5,i) 2:栈顶5,符号*——查表——R6(归约:弹栈5,i,压栈:(0,F)=3,F)//0-符号栈中的栈顶状态,F归约符号 3:栈顶3,符号*——查表——R4(归约:弹栈3,F,压栈:(0,T)=2,T) 4:栈顶2,符号*——查表——S7(移进S7,*) 5:栈顶7,符号i——查表——S5(移进S5,i) 6:栈顶5,符号+——查表——R6(归约:弹栈5,i,压栈:(7,F)=10,F)
5.LR算法
举个栗子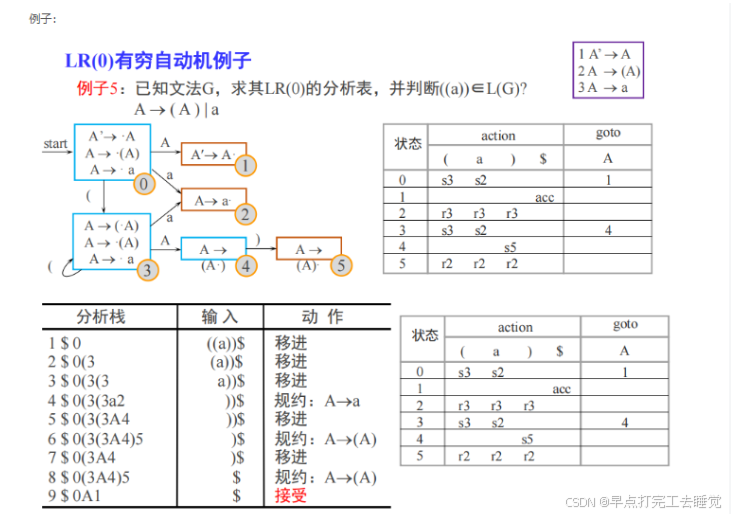

















 3819
3819

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









